一、串行搜集器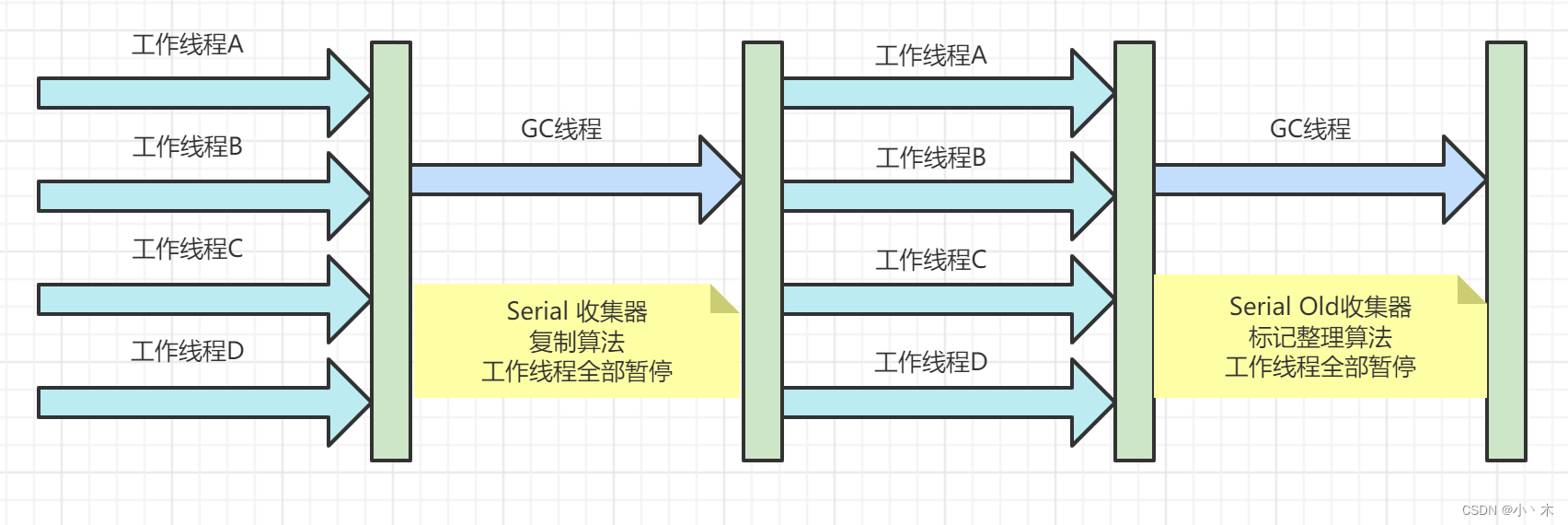
-
Serial收集器
- 同一时间只有一个CPU执行垃圾回收,此时应用程序暂停,直到垃圾回收完成;
- 最古老的搜集器,最稳定;
- 单线程没有线程间交互,回收效率高;
- 当回收的内存很大时会造成长时间停顿;
- 新生代使用复制算法、老年代使用标记-压缩算法;
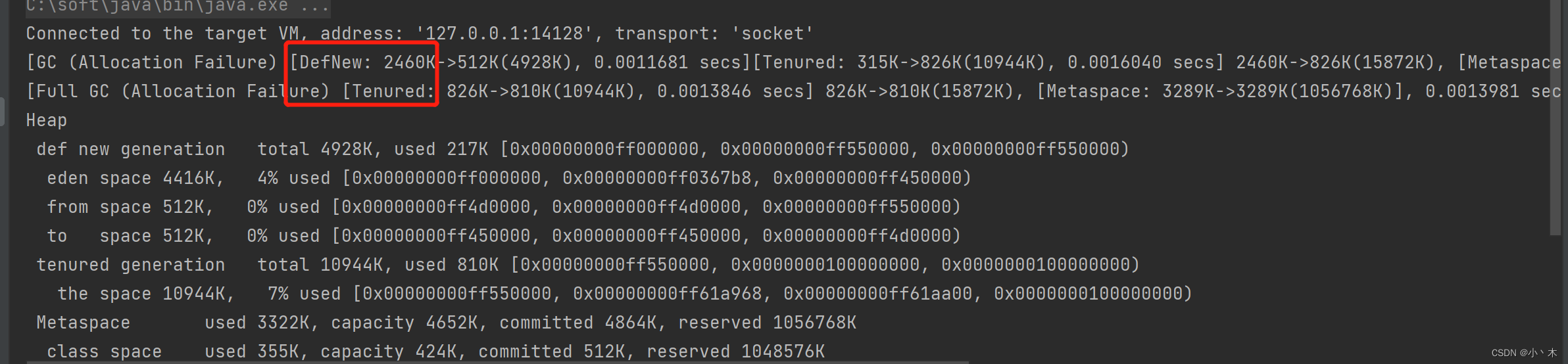
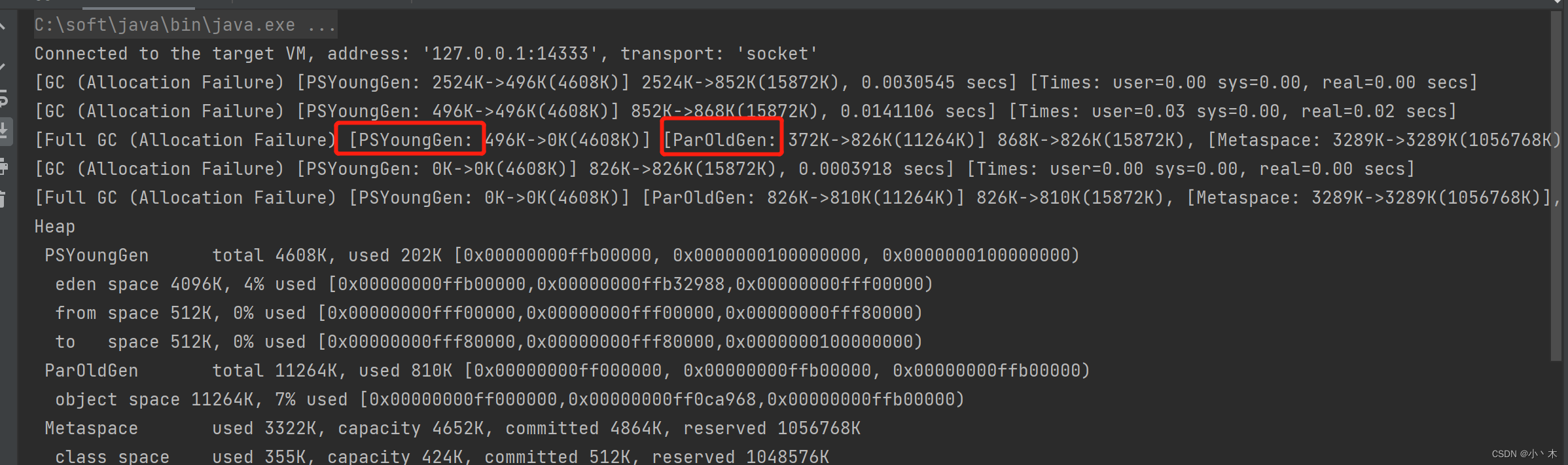
- 配置:-XX:+UseSerialGC,新生代使用Serial、老年代使用Serial Old,日志如下;
二、并行搜集器
-
ParNew收集器
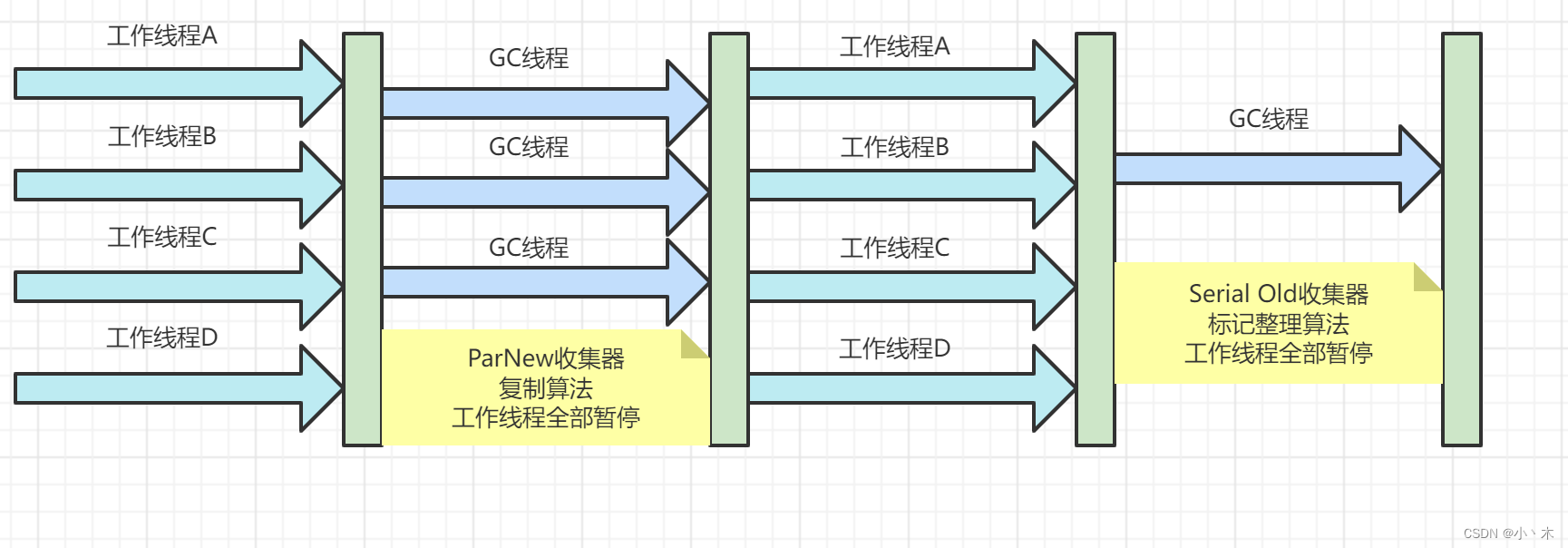
- ParNew是Serial的多线程版本;
- 新生代垃圾收集器,回收算法、策略、控制参数与Serial完全一致;
- 使用复制算法;
- 除Serial以外,唯一可以和CMS配合使用的;
- -XX:ParallelGCThreads=n:可用于垃圾回收的最大线程数;
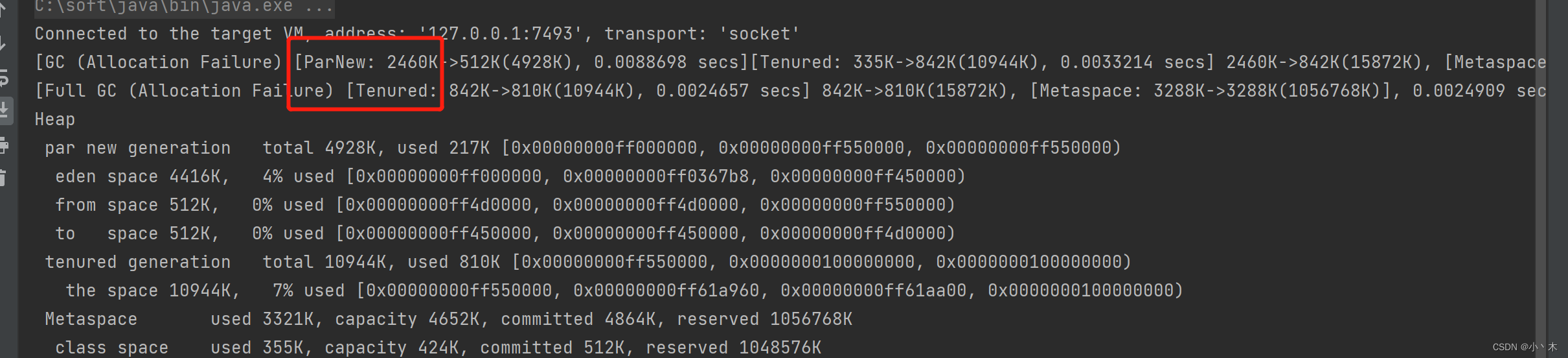
- 配置:-XX:+UseParNewGC,年轻代使用ParNew、老年代使用Serial Old(这个组合JVM官方不推荐,后续可能会移除),日志如下:
-
Parallel Scavenge收集器(吞吐量优先收集器)
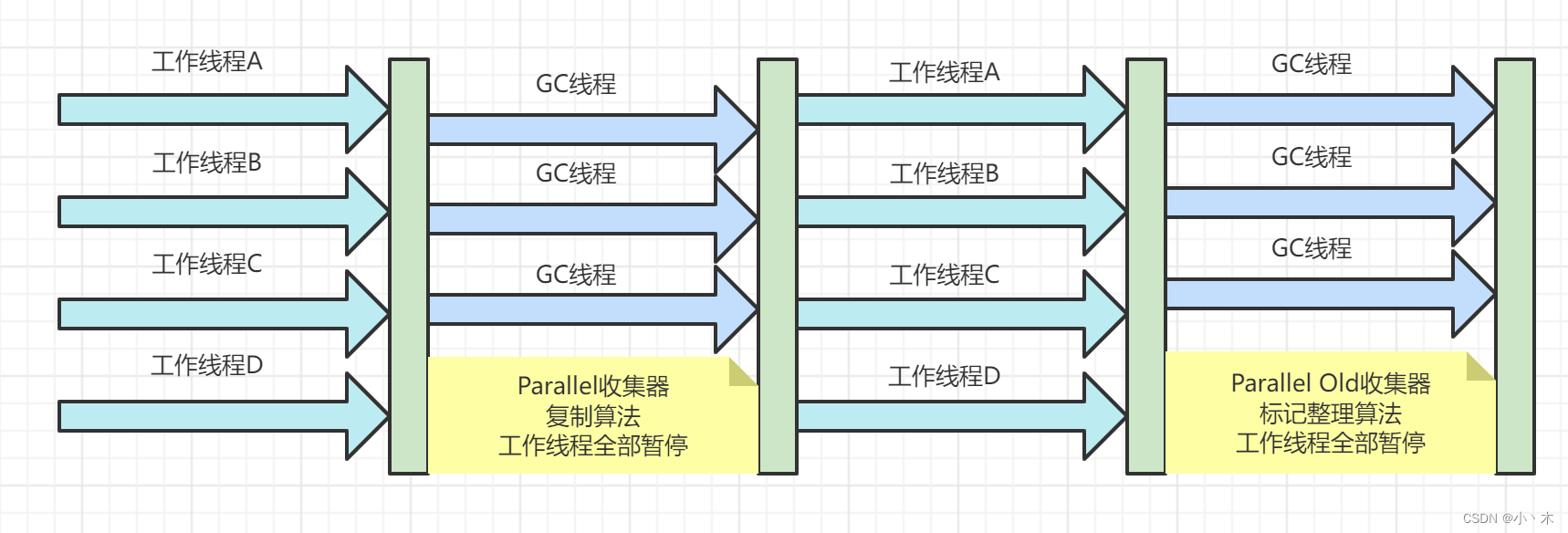
- 新生代收集器、采用复制算法、并行;
- 与其他收集器相比更关注吞吐量:吞吐量 = 工作线程所占时间 / (工作线程所占时间 + 垃圾回收所占时间);
- 自适应调节:虚拟机会收集运行性能信息,动态调整垃圾回收停顿时间,和最大吞吐量;
- -XX:MaxGCPauseMills=n:垃圾回收最大停顿时间(毫秒),设置之后虚拟机会尽量保证回收时间不超过设定值;
- -XX:GCTimeRatio=n:0~100整数,表示期望GC的时间不超过程序运行时间的1/(1+n),默认99;
- -XX:+UseParallelGC或-XX:+UseParallelOldGC可相互激活;
-
Parallel Old收集器
- Parallel Scavenge 的老年代版本;
- 与Parallel Scavenge配合使用。
三、并发收集器
-
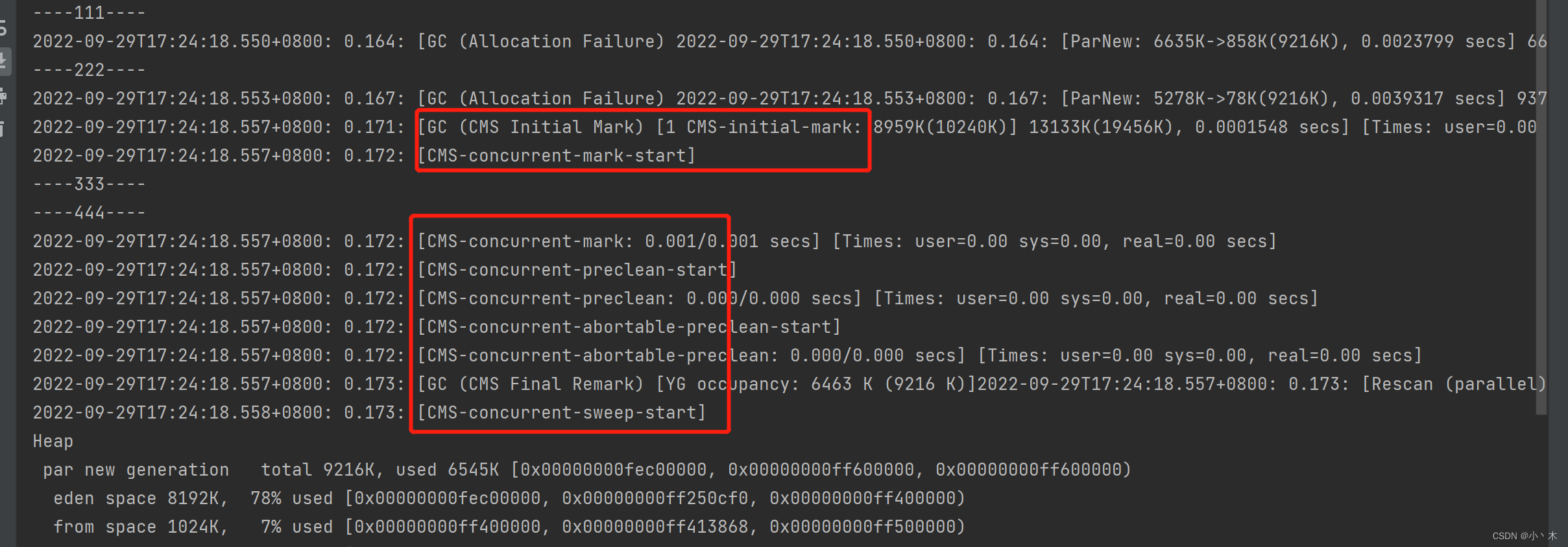
CMS收集器(Concurrent Mark Sweep:并发标记清除)
- 关注回收时间,期望获取最短回收时间;
- 老年代收集器,年轻代使用ParNew,标记清除算法,并发回收垃圾,会造成内存碎片,且无法完全清理垃圾(并发时工作线程也在产生垃圾);
- 由于并发,GC时工作线程也在工作,所以不能整理内存空间(改变对象存储位置),只能使用标记清除算法;
- 使用串行收集器做后备(当剩余内存不足以支撑工作线程并发运行时,引起concurrent mode failure并使用串行收集器执行一次GC);
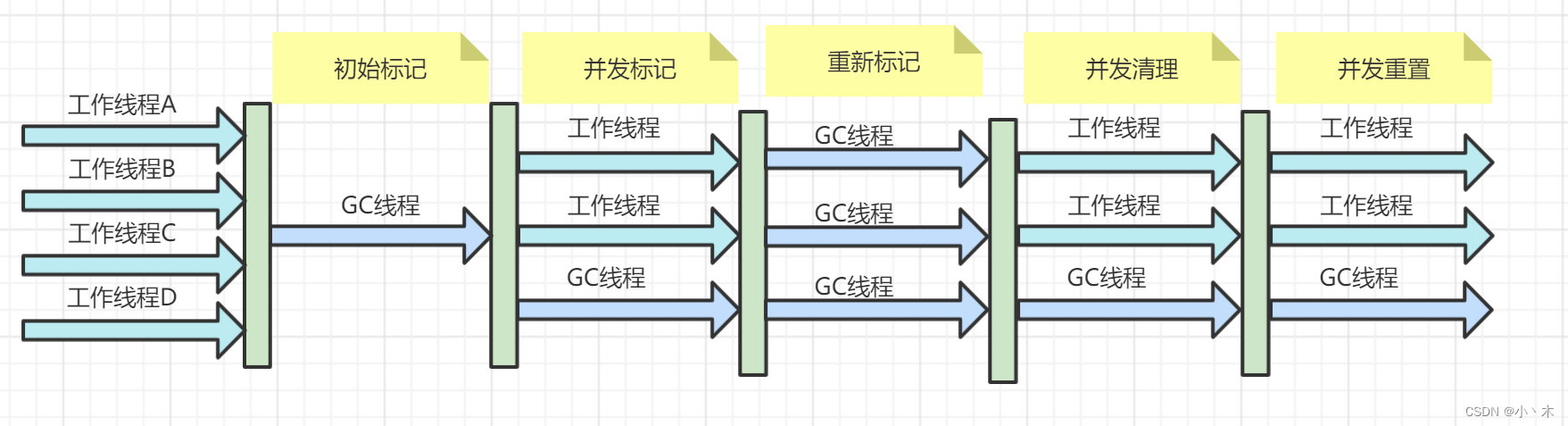
- 回收过程:
- 初始标记:标记根节点直接关联到的对象,速度快;
- 并发标记:便利标记所有存活对象,耗时较长,GC线程与工作线程并发工作,无需停顿,但会降低吞吐量,是程序变慢;
- 重新标记:修正并发标记中由于工作线程同时工作产生的对象变更,该过程比初始标记耗时长一点,但是远小于并发标记耗时;
- 并发清理:清理死亡对象,无需整理空间,所以该阶段也可与工作线程并发运行。
- -XX:CMSInitiatingOccupancyFraction=70:设置触发GC的阈值,老年代使用率超过70%执行GC;
- -XX:CMSFullGCsBeforeCompaction=2:设置进行2次FullGC之后进行碎片整理;
- -XX:ParallelCMSThreads:设置CMS的线程数量;
- -XX:+UseConcMarkSweepGC;
/*** @author xiaomu* @title: JVMTest* @description: JVM测试类* @date 2022/8/1014:15*/
public class JVMTest extends ClassLoader{public static final int _1MB = 1024 * 1024;public static void main(String[] args) {byte[] b1 = new byte[4 * _1MB];System.out.println("----111----");byte[] b2 = new byte[4 * _1MB];System.out.println("----222----");byte[] b3 = new byte[4 * _1MB];System.out.println("----333----");byte[] b4 = new byte[2 * _1MB];System.out.println("----444----");}
}
-
G1搜集器
-
内存划分:
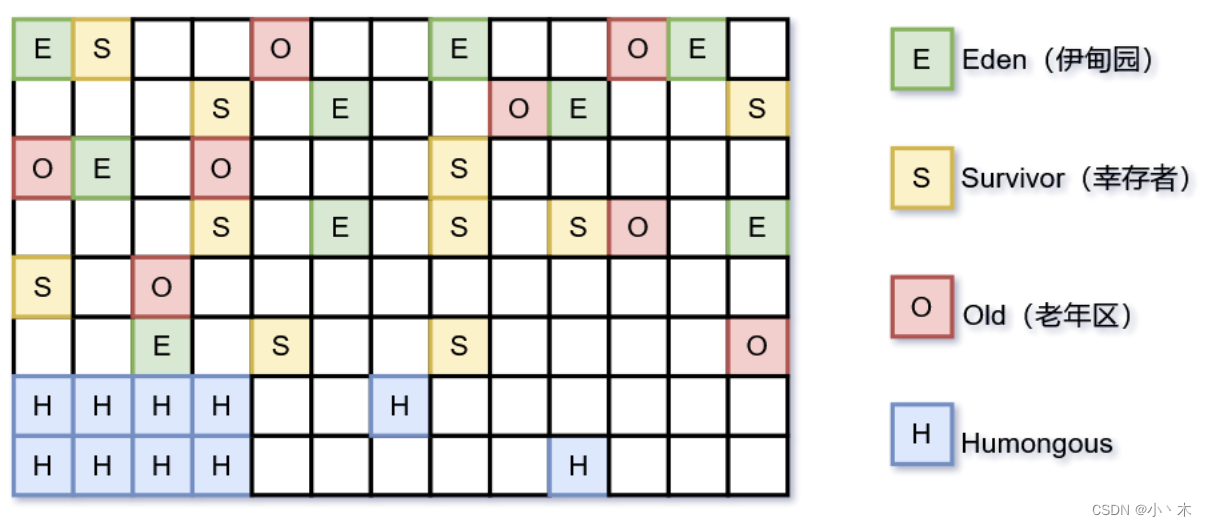
- G1也使用分代的思想,但不再将年轻代、老年代分为固定大小的区域,而是将连续的java堆分为约2048个大小相等的分区(Region),每个Region根据需要扮演eden、survivor、old区域(每个Region同一时间只能扮演一个角色);
- 使用特殊的Region:Humongous存储大对象(查过一个Region内存一半的为大对象),当一个对象超过一个Region内存,则使用连续的Region存储,Humongous区作为老年代看待;
- 同一区的Region不需要连续;
-
回收算法:
- 停顿时间模型:G1尽量避免回收全区域,每次回收整数个Region,因此可预测回收所需停顿时间;
- 价值:回收时间少,回收内存多价值越高;
- G1会根据Region的价值大小在后台维护一个列表,每次根据设定的停顿时间,优先处理价值大的区域;
- 整体使用标记整理算法,局部使用标记复制算法。
-
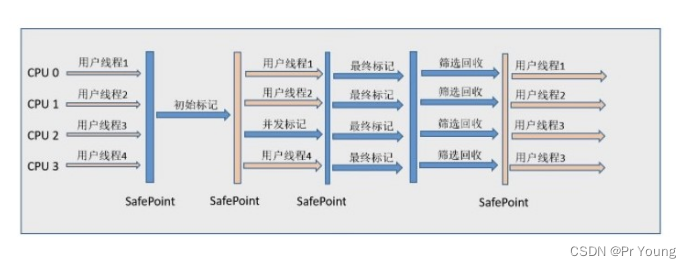
回收过程:
- 初始标记:仅标记根节点直接关联对象,并修改TAMS指针值,使下一阶段工作线程并发时可以正常分配内存,程序停顿,耗时短;
- 并发标记:扫描全堆,对所有对象进行可达性分析,完成之后会重新处理STAB在并发时有引用变动的对象,与用户线程并发,耗时长;
- 最终标记:处理表发标记留下的少了STAB记录,程序停顿,耗时短;
- 筛选回收:更新Region统计数据,对Region通过成本(耗时)和价值排序,根据用户期望的停顿时间选择任意多个Region,将选择回收的Region中存活对象移到空Region中,清空就Region,涉及存活对象移动,需暂停工作线程;
-
参数
- -XX:+UseG1GC:使用G1;
- -XX:G1HeapRegionSize:设置 Region 大小(范围 1~32M,且为 2 的 N 次幂);
- -XX:MaxGCPauseMillis:最大收集停顿时间(默认 200 毫秒)。
-
四、总结
- Serial:串行、单线程、最稳定、最古老,适用于单核,或对停顿时间没要求;
- ParNew:并行,年轻代收集器,CMS默认搭配的年轻代收集器;
- Parallel:并行,jdk1.8默认使用的收集器,注重吞吐量,适用于多核,服务器资源稀缺;
- CMS:并发,存在内存碎片,且无法完全清理,适用于程序需要及时响应;
- G1:可控的停顿时间,着手解决吞吐量与停顿时间间的矛盾,期望在可控的停顿时间内最大限度的提高吞吐量,jdk9之后默认使用G1。