文章目录
- 前言
- 简单介绍哈希表,哈希结构
- 什么时候用哈希表
- unordered_map操作
- likou第一题 两数之和
- unordered_set 实现
- 总结
前言
- 今天重新打开力扣,看到以前的签到题两数之和,以前的方法是双指针暴力解法,偶然看到了哈希表的方法,让我想起了iOS的字典,也顺带学习了哈希表的使用,我这里仅仅限于自己用来写算法题,作以记录
简单介绍哈希表,哈希结构
- 哈希表也叫散列表
- 哈希表是一个数据结构
- 散列表是数组结构
- 它是用来:可以根据一个key值来直接访问数据,因此查找速度快
- 说到访问数据,在最基本的几个数据结构中,数组肯定是查询效率是最高的。因为它可以直接通过数组下标来访问数据
- 其实哈希表的本质上就是一个数组,它之所以叫哈希表,只能说它的底层实现是用到了数组,稍微加工,自立门户成了哈希表
- 对于C++ 中的哈希表是unordered_set 和 unordered_map 而不是set 和 map
什么时候用哈希表
- 一般哈希表都是用来快速判断一个元素是否出现在集合里。
unordered_map操作
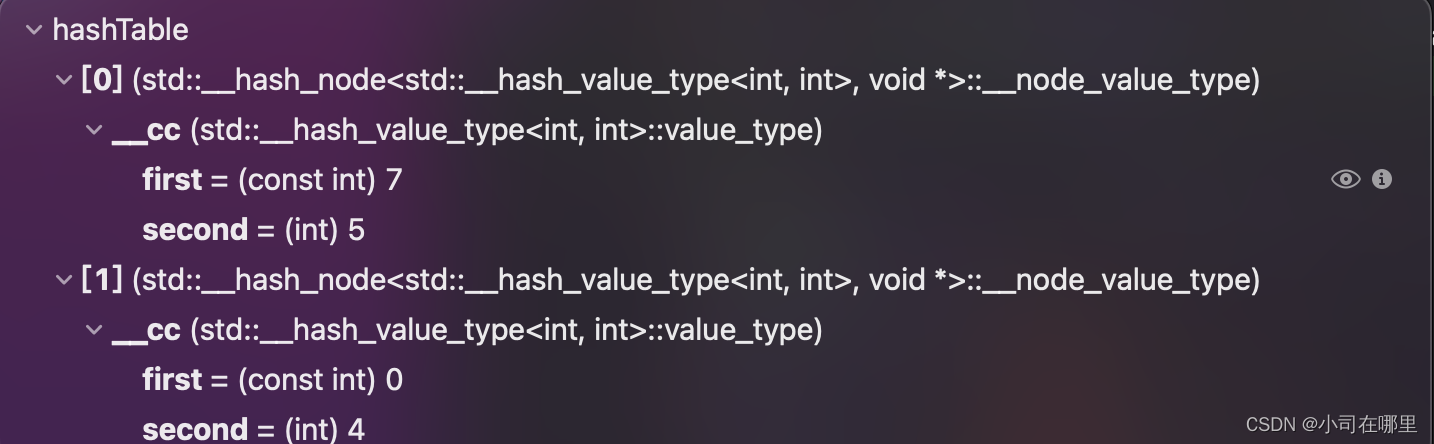
std::unordered_map<int, int> hashTable;hashTable[0] = 4;hashTable[7] = 5;
- 遍历
-
- 对于哈希表的每一个元素,我们需要通过箭头语法来访问元素内部,结构如下
-
- 可以看到内部元素的key需要用
hashTable -> frist访问
-
- value则是
hashTable -> second
for (auto i = hashTable.begin(); i != hashTable.end(); i++) {std::cout << i -> second << "\n";}
- 查询1
-
-
- 对于查询在这里特别说一下,刚开始以为是查询里面的value,其实查询的对应的key,这和我学的字典,之前的数组区别很大
-
- 查询一
hashTable.find(x) != hashTable.end(), 这=这句话的意思是在hashTable里面进行元素访问,如果访问x并没有到哈希表结束则找到了该元素,否则查找元素的失败x是对应的key而不是value,
if (hashTable.find(7) != hashTable.end()) {std:: cout << "找到" << "\n";} else {std::cout << "查找元素失败" << "\n";}
- 查询2
hash.count(x) -
- hash.count(x) , 该方法返回的是 0 和 1,对应的BOOL值就是否和正确
if (hashTable.count(4) == 1) {} else {std::cout << "查找元素失败";}
- 删除元素
hashTable.erase(x);x 同样是key
if (hashTable.find(7) != hashTable.end()) {hashTable.erase(7);std:: cout << "找到并删除" << "\n";} else {std::cout << "查找元素失败" << "\n";}
- 删除全部键值对,不是删除表。
- 删除完之后表还是存在的,只是键值对全部没了。和销毁栈不一样
hashTable.clear();
likou第一题 两数之和
- 今天刚好学到了就用这个思路写一下第一题,题目很简单,暴力事件复杂度在n平方,不值得
- 哈希的时间复杂度低了很多。空间也就是多开了一个表
- 这个题哈希表的思路就是在数组外开一个哈希表,遍历数组的同时在哈希表里找target减去数组当前元素的值,找到的话就返回,否则将数组当前下标作为value,元素内容作为key存入哈希,一旦找到就return
- 思路很简单
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int, int> hashTable;for (int i = 0; i < nums.size(); i++) {auto self = hashTable.find(target - nums[i]);if (self != hashTable.end()) {return {self->second, i};}hashTable[nums[i]] = i;}return {};}
};
- 哈希提交结果

- 暴力结果

- 对比之下哈希的速度快了很多
unordered_set 基础操作
- unordered_set 和上面介绍的unordered_map的底层都是哈希结构的实现,unordered_map不会进行去重,unordered_set 则会进行去重,二者都不会进行排序
- set 和 map的底层的实现是红黑树,相比于unordered_set 和上面介绍的unordered_map 的空间复杂度略微升高,这里我找了2篇博客介绍了它们的区别
- unordered_set 和set区别
- unordered_map 和 map的区别
std:: unordered_set<int> hashSet;hashSet.insert(1);hashSet.insert(5);hashSet.insert(3);hashSet.insert(2);hashSet.insert(3);hashSet.insert(3);hashSet.insert(4);for (auto e : hashSet){std:: cout << e << "\n";e++;}
std:: set <int> s;s.insert(3);s.insert(1);s.insert(8);s.insert(2);s.insert(5);s.insert(5);s.insert(5);auto it = s.begin();while (it != s.end()){std:: cout << *it << " ";it++;}std:: cout << std :: endl;}
unordered_set 实现

- 思路:只要出现重复的元素就返回false,一层循环数组元素,在数组外创建一个set,对比数组元素在set中一旦找到该元素,即说明在之前数组也出现了该元素,找不到就存入set。
- 这个思路和两层循环查找是一样的,高效率就是在于它利用的封装好的哈希结构,所谓速度很快。
class Solution {
public:bool containsDuplicate(vector<int>& nums) {unordered_set<int> s;for (int x: nums) {if (s.find(x) != s.end()) {return true;}s.insert(x);}return false;}
};
总结
- 对于unordered_set 和上面介绍的unordered_map 底层是哈希结构的实现,但map 和 set则是红黑树底层的实现,如果在写题的时候可以用到想到哈希结构的特点就可以使用 unordered_set 和 unordered_map
- 这里只是简单的记录一下哈希思想,对于c++的散列表没有深入了解
- 简单的记录,并没有深入了解哈希这个结构,对于C++ Java这些语言都有封装好的库,相对于C语言方便许多,C语言可以数组模拟哈希,但实在是太麻烦了
- 就我所知iOS 的底层也有接触到哈希表,以后了解