Relational Database Management System
关系型数据库系统通过表来表示关系
当前主要使用两种类型的数据库:关系型数据库、非关系型数据库,我们主要学习主流的关系
型数据库
所谓的关系型数据库RDBMS,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据
查看数据库排名:DB-Engines Ranking - popularity ranking of database management systems
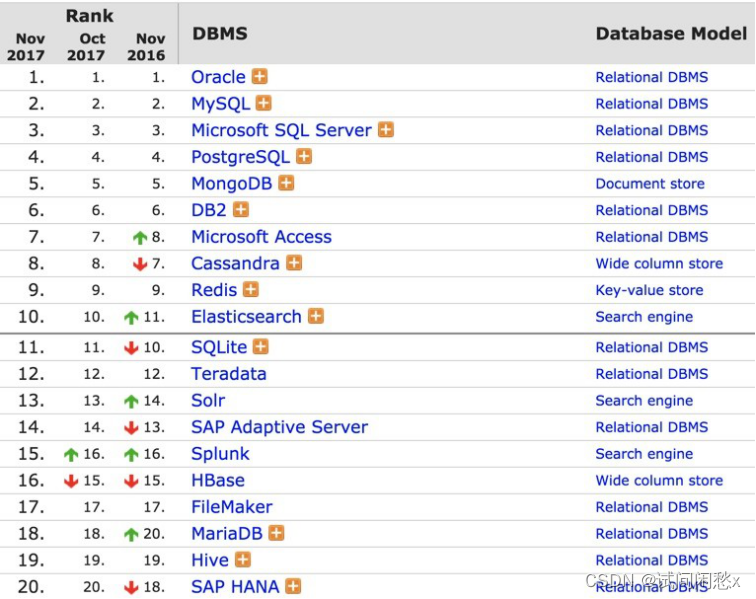 关系型数据库的主要产品:
关系型数据库的主要产品:
oracle:在以前的大型项目中使用,银行,电信等项目mysql:web时代使用最广泛的关系型数据库
ms sql server:在微软的项目中使用sqlite:轻量级数据库,主要应用在移动平台
关系型数据库核心元素
数据行(一条记录) 数据列(字段)
数据表(数据行的集合)
数据库(数据表的集合,一个数据库中能够有 n 多个数据表)
SQL
Structured Query Language
结构化查询语言
在数据库中进行操作的语言,称为sql,结构化查询语言,当前关系型数据库都支持使用sql语言进行操作,也就是说可以通过 sql 操作 oracle,sql server,mysql,sqlite 等等所有的关系型的数据库
sql语言主要分为:
DQL:数据查询语言,用于对数据进行查询,如select DML:数据操作语言,对数据进行增加、修改、删除,如insert、udpate、delete TPL:事务处理语言,对事务进行处理,包括begin transaction、commit、rollback DCL:数据控制语言,进行授权与权限回收,如grant、revoke DDL:数据定义语言,进行数据库、表的管理等,如create、drop CCL:指针控制语言,通过控制指针完成表的操作,如declare cursor
对于测试工程师来讲,重点是数据的查询,需要熟练编写DQL,其它语言如TPL、DCL、CCL 了解即可
SQL 是一门特殊的语言,专门用来操作关系数据库不区分大小写
数据类型与约束
为了更加准确的存储数据,保证数据的正确有效,需要合理的使用数据类型和约束来限制数据的存储。
常用数据类型
整数:int,有符号范围(-2147483648 ~2147483647),无符号范围(0 ~ 4294967295)
小数:decimal,如decimal(5,2)表示共存5位数,小数占2位,整数占3位
字符串:varchar,范围(0~65533),如varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符
日期时间: datetime,范围(1000-01-01 00:00:00 ~ 9999-12-31 23:59:59),如'2020-01-01
12:29:59'
约束
主键(primary key):物理上存储的顺序
非空(not null):此字段不允许填写空值
惟一(unique):此字段的值不允许重复
默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准
外键(foreign key):维护两个表之间的关联关系
此时会显示备份的进度,达到100%后,备份完成,点击关闭即可,此时文件已经保存到前面指定的位置
恢复
新创建一个数据库,名字随便起,字符集和排序规则必须和之前备份的数据库一致
双击打开刚才创建的数据库,鼠标右键点击此数据库,点击运行SQL文件
在弹出的窗口中,点击选择文件的按钮,如下图
在弹出的窗口中,选中之前备份的文件,点击打开按钮
点击开始按钮
等待运行完成,关闭即可,此时数据已经恢复到新的数据库中了
数据表操作
创建表
| create table 表名( 字段名 类型 约束, 字段名 类型 约束 ... ) |
例:创建学生表,字段要求如下:
姓名(长度为10), 年龄,身高(保留小数点2位)
| create table students( id int unsigned primary key auto_increment, name varchar(20), age int unsigned, height decimal(5,2) ) |
删除表
| 格式一:drop table 表名 | |
| 格式二:drop table if exists 表名 |
例:删除学生表
| drop table students 或 drop table if exists students |
数据操作-增删改查
简单查询
| select * from 表名例:查询所有学生数据 select * from students |
添加数据
添加一行数据
格式一:所有字段设置值,值的顺序与表中字段的顺序对应
说明:主键列是自动增长,插入时需要占位,通常使用0或者 default 或者 null 来占位,插入成功后以实际数据为准
| insert into 表名 values(...) |
例:插入一个学生,设置所有字段的信息
| insert into students values(0,'亚瑟',22,177.56) |
格式二:部分字段设置值,值的顺序与给出的字段顺序对应
| insert into 表名(字段1,...) values(值1,...) |
例:插入一个学生,只设置姓名
| insert into students(name) values('老夫子') |
添加多行数据
方式一:写多条insert语句,语句之间用英文分号隔开
| insert into students(name) values('老夫子2'); insert into students(name) values('老夫子3'); insert into students values(0,'亚瑟2',23,167.56) |
方式二:写一条insert语句,设置多条数据,数据之间用英文逗号隔开
| 格式一:insert into 表名 values(...),(...)... 例:插入多个学生,设置所有字段的信息 insert into students values(0,'亚瑟3',23,167.56),(0,'亚瑟4',23,167.56) |
修改
| 格式:update 表名 set 列1=值1,列2=值2... where 条件 |
例:修改id为5的学生数据,姓名改为 狄仁杰,年龄改为 20
| update students set name='狄仁杰',age=20 where id=5 |
删除
例:删除id为6的学生数据
| 格式:delete from 表名 where 条件 |
逻辑删除:对于重要的数据,不能轻易执行delete语句进行删除,一旦删除,数据无法恢复,这时可以进行逻辑删除。
1、给表添加字段,代表数据是否删除,一般起名isdelete,0代表未删除,1代表删除,默认值为0
2、当要删除某条数据时,只需要设置这条数据的isdelete字段为1
3、以后在查询数据时,只查询出isdelete为0的数据
| delete from students where id=6 |
数据操作-查询
创建数据表
| drop table if exists students; create table students ( studentNo varchar(10) primary key, name varchar(10), sex varchar(1), hometown varchar(20), age tinyint(4), class varchar(10), card varchar(20) ) |
准备数据
| insert into students values ('001', '王昭君', '女', '北京', '20', '1班', '340322199001247654'), ('002', '诸葛亮', '男', '上海', '18', '2班', '340322199002242354'), ('003', '张飞', '男', '南京', '24', '3班', '340322199003247654'), ('004', '白起', '男', '安徽', '22', '4班', '340322199005247654'), ('005', '大乔', '女', '天津', '19', '3班', '340322199004247654'), ('006', '孙尚香', '女', '河北', '18', '1班', '340322199006247654'), ('007', '百里玄策', '男', '山西', '20', '2班', '340322199007247654'), ('008', '小乔', '女', '河南', '15', '3班', null), ('009', '百里守约', '男', '湖南', '21', '1班', ''), ('010', '妲己', '女', '广东', '26', '2班', '340322199607247654'), ('011', '李白', '男', '北京', '30', '4班', '340322199005267754'), ('012', '孙膑', '男', '新疆', '26', '3班', '340322199000297655') |
查询所有字段
| select * from 表名 例: select * from students |
查询指定字段
在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中
| select 列1,列2,... from 表名 |
消除重复行
在select后面列前使用distinct可以消除重复的行
| select distinct 列1,... from 表名; 例: select distinct sex from students; |
条件
使用where子句对表中的数据筛选,符号条件的数据会出现在结果集中语法如下:
| select 字段1,字段2... from 表名 where 条件; 例: select * from students where id=1; |
where后面支持多种运算符,进行条件的处理比较运算
逻辑运算模糊查询范围查询空判断
比较运算符
等于: =
大于: >
大于等于: >=
小于: <
小于等于: <=
不等于: != 或 <>
例1:查询小乔的年龄
| select age from students where name='小乔' |
例2:查询20岁以下的学生
| select * from students where age<20 |
例3:查询家乡不在北京的学生
| select * from students where hometown!='北京' |
逻辑运算符
and or not
例1:查询年龄小于20的女同学
| select * from students where age<20 and sex='女' |
模糊查询
like
%表示任意多个任意字符
_表示一个任意字符
例1:查询姓名含白的学生
| select * from students where name like '%白%' |
范围查询
in表示在一个非连续的范围内
例1:查询家乡是北京或上海或广东的学生
| select * from students where hometown in('北京','上海','广东') |
between ... and ...表示在一个连续的范围内
例2:查询年龄为18至20的学生
select * from students where age between 18 and 20
空判断
注意:null与''是不同的判空is null
例1:查询没有填写身份证的学生
| select * from students where card is null |
判非空is not null
例2:查询填写了身份证的学生
| select * from students where card is not null |
排序
为了方便查看数据,可以对数据进行排序语法:
| select * from 表名 order by 列1 asc|desc,列2 asc|desc,... |
将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推默认按照列值从小到大排列
asc从小到大排列,即升序desc从大到小排序,即降序
例1:查询所有学生信息,按年龄从小到大排序
| select * from students order by age |
例2:查询所有学生信息,按年龄从大到小排序,年龄相同时,再按学号从小到大排序
| select * from students order by age desc,studentNo |
聚合函数
为了快速得到统计数据,经常会用到如下5个聚合函数count(*)表示计算总行数,括号中写星与列名,结果是相同的聚合函数不能在 where 中使用
例1:查询学生总数
| select count(*) from students; |
max(列)表示求此列的最大值
min(列)表示求此列的最小值例
sum(列)表示求此列的和
avg(列)表示求此列的平均值
分组
按照字段分组,表示此字段相同的数据会被放到一个组中
分组后,分组的依据列会显示在结果集中,其他列不会显示在结果集中可以对分组后的数据进行统计,做聚合运算语法:
| select 列1,列2,聚合... from 表名 group by 列1,列2... |
例1:查询各种性别的人数
| select sex,count(*) from students group by sex |
例2:查询各种年龄的人数
| select age,count(*) from students group by age |
分组后的数据筛选
语法:
| select 列1,列2,聚合... from 表名 group by 列1,列2,列3... having 列1,...聚合... |
having后面的条件运算符与where的相同
对比where与having
where是对from后面指定的表进行数据筛选,属于对原始数据的筛选having是对group by的结果进行筛选
获取部分行
当数据量过大时,在一页中查看数据是一件非常麻烦的事情语法
| select * from 表名 limit start,count |
从start开始,获取count条数据
start索引从0开始
例1:查询前3行学生信息
| select * from students limit 0,3 |
分页
已知:每页显示m条数据,求:显示第n页的数据
| select * from students limit (n-1)*m,m |
求总页数
查询总条数p1
使用p1除以m得到p2 如果整除则p2为总数页
如果不整除则p2+1为总页数
连接查询
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
等值连接查询:查询的结果为两个表匹配到的数据
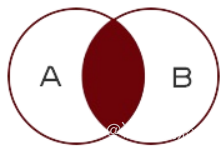
左连接查询:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null填充

右连接查询:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用null填充

等值连接
方式一
| select * from 表1,表2 where 表1.列=表2.列 |
方式二(又称内连接)
| select * from 表1 inner join 表2 on 表1.列=表2.列 |
例1:查询学生信息及学生的成绩
| select * from students stu, scores sc where stu.studentNo = sc.studentNo select * from students stu inner join scores sc on stu.studentNo = sc.studentNo |
例2:查询课程信息及课程的成绩
| select * from courses cs, scores sc where cs.courseNo = sc.courseNo select * from courses cs inner join scores sc on cs.courseNo = sc.courseNo |
例3:查询学生信息及学生的课程对应的成绩
| elect * from students stu, courses cs, scores sc where stu.studentNo = sc.studentno and cs.courseNo = sc.courseNo select * from students stu inner join scores sc on stu.studentNo = sc.studentNo inner join courses cs on cs.courseNo = sc.courseNo |
例4:查询男生中最高成绩,要求显示姓名、课程名、成绩
| select stu.name, cs.name, sc.score from students stu, scores sc, courses cs where stu.studentNo = sc.studentNo and sc.courseNo = cs.courseNo and stu.sex = '男' order by sc.score desc limit 1 |
左连接
| select * from 表1 left join 表2 on 表1.列=表2.列 |
例1:查询所有学生的成绩,包括没有成绩的学生
| select * from students stu left join scores sc on stu.studentNo = sc.studentNo |
例2:查询所有学生的成绩,包括没有成绩的学生,需要显示课程名
| select * from students stu left join scores sc on stu.studentNo = sc.studentNo left join courses cs on cs.courseNo = sc.courseNo |
右连接
| select * from 表1 right join 表2 on 表1.列=表2.列 |
例1:查询所有课程的成绩,包括没有成绩的课程
| select * from scores sc right join courses cs on cs.courseNo = sc.courseNo |
例2:查询所有课程的成绩,包括没有成绩的课程,包括学生信息
| select * from scores sc right join courses cs on cs.courseNo = sc.courseNo left join students stu on stu.studentNo = sc.studentNo |
自关联
设计省信息的表结构provinces id
ptitle
设计市信息的表结构citys id
ctitle proid
citys表的proid表示城市所属的省,对应着provinces表的id值
问题:能不能将两个表合成一张表呢?
思考:观察两张表发现,citys表比provinces表多一个列proid,其它列的类型都是一样的
意义:存储的都是地区信息,而且每种信息的数据量有限,没必要增加一个新表,或者将来还要存储区、乡镇信息,都增加新表的开销太大
答案:定义表areas,结构如下
id atitle pid
因为省没有所属的省份,所以可以填写为null
城市所属的省份pid,填写省所对应的编号id
这就是自关联,表中的某一列,关联了这个表中的另外一列,但是它们的业务逻辑含义是不一样的,城市信息的pid引用的是省信息的id
在这个表中,结构不变,可以添加区县、乡镇街道、村社区等信息准备数据:
例1:查询一共有多少个省
| select count(*) from areas where pid is null; |
例1:查询河南省的所有城市
| select * from areas as p inner join areas as c on c.pid=p.aid where p.atitle='河北省'; |
例2:查询郑州市的所有区县
| select * from areas as c inner join areas as a on a.pid=c.aid where c.atitle='郑州市'; |
例3:查询河南省的所有区县
| select * from areas as p left join areas as c on c.pid=p.aid left join areas as a on a.pid=c.aid where p.atitle='河南省' |
子查询
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句
主查询
主要查询的对象,第一条 select 语句
主查询和子查询的关系
子查询是嵌入到主查询中
子查询是辅助主查询的,要么充当条件,要么充当数据源子查询是可以独立存在的语句,是一条完整的 select 语句
子查询分类
标量子查询: 子查询返回的结果是一个数据(一行一列) 列子查询: 返回的结果是一列(一列多行)
行子查询: 返回的结果是一行(一行多列) 表级子查询: 返回的结果是多行多列
标量子查询
例1:查询班级学生的平均年龄
| 查询班级学生平均年龄 select avg(age) from students 查询大于平均年龄的学生 select * from students where age > 21.4167 select * from students where age > (select avg(age) from students); |
列级子查询
例3:查询18岁的学生的成绩,要求显示成绩
| 学生表中查询18岁的学生的学号 select studentNo from students where age=18 成绩表中根据学号查询成绩 select * from scores where studentNo in ('002','006') select * from scores where studentNo in (select studentNo from students where age=18) |
行级子查询
例4:查询男生中年龄最大的学生信息
| select * from students where sex='男' and age=(select max(age) from students) select * from students where (sex,age)=('男',30) select * from students where (sex,age) = (select sex,age from students where sex='男' o rder by age desc limit 1) |
表级子查询
例5:查询数据库和系统测试的课程成绩
| select * from scores s inner join (select * from courses where name in ('数据库','系统测试')) c on s.courseNo = c.courseNo |
子查询中特定关键字使用
in 范围
格式: 主查询 where 条件 in (列子查询) any | some 任意一个
格式: 主查询 where 列 = any (列子查询)
在条件查询的结果中匹配任意一个即可,等价于 in
all
格式: 主查询 where 列 = all(列子查询) : 等于里面所有格式: 主查询 where 列 <>all(列子查询) : 不等一其中所有
| select * from students where age in (select age from students where age between 18 and 20) |
准备数据
create table goods(
id int unsigned primary key auto_increment, name varchar(150),
cate varchar(40), brand_name varchar(40),
price decimal(10,3) default 0, is_show bit default 1, is_saleoff bit default 0
);
insert into goods values(0,'r510vc 15.6英寸笔记本','笔记本','华硕','3399',default,default
);
insert into goods values(0,'y400n 14.0英寸笔记本电脑','笔记本','联想','4999',default,defa ult);
insert into goods values(0,'g150th 15.6英寸游戏本','游戏本','雷神','8499',default,default
);
insert into goods values(0,'x550cc 15.6英寸笔记本','笔记本','华硕','2799',default,default
);
insert into goods values(0,'x240 超极本','超级本','联想','4999',default,default);
insert into goods values(0,'u330p 13.3英寸超极本','超级本','联想','4299',default,default)
;
insert into goods values(0,'svp13226scb 触控超极本','超级本','索尼','7999',default,defaul t);
insert into goods values(0,'ipad mini 7.9英寸平板电脑','平板电脑','苹果','1998',default,d efault);
insert into goods values(0,'ipad air 9.7英寸平板电脑','平板电脑','苹果','3388',default,de fault);
insert into goods values(0,'ipad mini 配备 retina 显示屏','平板电脑','苹果','2788',defaul t,default);
insert into goods values(0,'ideacentre c340 20英寸一体电脑 ','台式机','联想','3499',defau lt,default);
insert into goods values(0,'vostro 3800-r1206 台式电脑','台式机','戴尔','2899',default,d efault);
insert into goods values(0,'imac me086ch/a 21.5英寸一体电脑','台式机','苹果','9188',defau lt,default);
insert into goods values(0,'at7-7414lp 台式电脑 linux )','台式机','宏碁','3699',default, default);
insert into goods values(0,'z220sff f4f06pa工作站','服务器/工作站','惠普','4288',default, default);
insert into goods values(0,'poweredge ii服务器','服务器/工作站','戴尔','5388',default,def ault);
insert into goods values(0,'mac pro专业级台式电脑','服务器/工作站','苹果','28888',default
,default);
insert into goods values(0,'hmz-t3w 头戴显示设备','笔记本配件','索尼','6999',default,defa ult);
查询演练
求所有电脑产品的平均价格,并且保留两位小数
| select round(avg(price),2) as avg_price from goods; |
查询所有价格大于平均价格的商品,并且按价格降序排序
| select id,name,price from goods where price > (select round(avg(price),2) as avg_price from goods) order by price desc; |
数据分表
创建“商品分类”表
| create table if not exists goods_cates( cate_id int unsigned primary key auto_increment, cate_name varchar(40) ); |
查询goods表的所有记录,并且按"类别"分组
| select cate from goods group by cate; |
将分组结果写入到goods_cates数据表
| insert into goods_cates (cate_name) select cate from goods group by cate; |
通过goods_cates数据表来更新goods表
| update goods as g inner join goods_cates as c on g.cate = c.cate_name set cate = cate_id; |
通过create...select来创建数据表并且同时写入记录,一步到位
| create table goods_brands ( brand_id int unsigned primary key auto_increment, brand_name varchar(40)) select brand_name from goods group by brand_name; |
通过goods_brands数据表来更新goods数据表
| update goods as g inner join goods_brands as b on g.brand_name = b.brand_name set g.brand_name = b.brand_id; |
查看 goods 的数据表结构,会发现 cate 和 brand_name对应的类型为 varchar 但是存储的都是字符串
修改数据表结构,把cate字段改为cate_id且类型为int unsigned,把brand_name字段改为brand_id且类型为int unsigned
分别在 good_scates 和 goods_brands表中插入记录
| insert into goods_cates(cate_name) values ('路由器'),('交换机'),('网卡'); insert into goods_brands(brand_name) values ('海尔'),('清华同方'),('神舟'); |
在 goods 数据表中写入任意记录
| insert into goods (name,cate_id,brand_id,price) values('LaserJet Pro P1606dn 黑白激光打印机','12','4','1849'); |
查询所有商品的详细信息 (通过左右链接来做)
| select * from goods left join goods_cates on goods.cate_id=goods_cates.id inner join goods_brands on goods.brand_id=goods_brands.id |
显示没有商品的品牌(通过右链接+子查询来做) -- 右链接
| select * from goods right join goods_brands on goods.brand_id =goods_brands.id |
-- 子查询
| select * from goods_brands where id not in (select DISTINCT brand_id from goods) |
备份
以管理员身份运行cmd程序
运行mysqldump命令
| cd C:\Program Files (x86)\MySQL\MySQL Server 5.1\bin mysqldump –uroot –p 数据库名 > ceshi.sql # 按提示输入mysql的密码 |
恢复
先创建新的数据库
| mysql -uroot –p 新数据库名 < ceshi.sql |
内置函数
字符串函数
拼接字符串concat(str1,str2...)
| select concat(12,34,'ab'); |
案例:体现类似"王昭君的家乡是北京"的功能.
包含字符个数length(str)
| select length('abc'); |
案例:查找班级里边名字为两个字的所有学生信息
截取字符串
left(str,len)返回字符串str的左端len个字符right(str,len)返回字符串str的右端len个字符
substring(str,pos,len)返回字符串str的位置pos起len个字符
| select substring('abc123',2,3); |
案例:实现王昭君叫王某某,张飞叫张某某的功能.
去除空格
ltrim(str)返回删除了左空格的字符串str rtrim(str)返回删除了右空格的字符串str
| select ltrim(' bar '); |
大小写转换,函数如下lower(str) upper(str)
select lower('aBcD');
数学函数
求四舍五入值round(n,d),n表示原数,d表示小数位置,默认为0
select round(1.6);
求x的y次幂pow(x,y)
| select pow(2,3); |
获取圆周率PI()
| select PI(); |
随机数rand(),值为0-1.0的浮点数
| select rand(); |
日期时间函数
当前日期current_date()
| select current_date(); |
当前时间current_time()
| select current_time(); |
当前日期时间now()
| select now(); |
日期格式化date_format(date,format)
参数format可选值如下
| %Y 获取年,返回完整年份 %y 获取年,返回简写年份 %m 获取月,返回月份 %d 获取日,返回天值 %H 获取时,返回24进制的小时数 %h 获取时,返回12进制的小时数 %i 获取分,返回分钟数 %s 获取秒,返回秒数 |
例:将使用-拼接的日期转换为使用空格拼接
| select date_format('2016-12-21','%Y %m %d'); |
流程控制
case语法:等值判断
说明:当值等于某个比较值的时候,对应的结果会被返回;如果所有的比较值都不相等则返回
else的结果;如果没有else并且所有比较值都不相等则返回null
| case 值 when 比较值1 then 结果1 when 比较值2 then 结果2 ... else 结果 end 例: select case 1 when 1 then 'one' when 2 then 'two' else 'zero' end as result; |
案例:做出一个女同学称为美女,男同学称为帅哥的小功能
自定义函数
创建
语法如下
| delimiter $$ create function 函数名称(参数列表) returns 返回类型 begin sql语句end $$ delimiter ; |
说明:delimiter用于设置分割符,默认为分号
在“sql语句”部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前需要指定其它符号作为分割符,此处使用//,也可以使用其它字符
存储过程
存储过程,也翻译为存储程序,是一条或者多条SQL语句的集合
创建
语法如下
| delimiter $$ create function 函数名称(参数列表) returns 返回类型 begin sql语句end $$ delimiter ; |
说明:delimiter用于设置分割符,默认为分号
在“sql语句”部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前需要指定其它符号作为分割符,此处使用//,也可以使用其它字符
示例
要求:创建查询过程,查询学生信息
step1:设置分割符
| delimiter $$ |
step2:创建存储过程
| create function my_trim(str varchar(100)) returns varchar(100) begin return ltrim(rtrim(str)); end $$ |
step3:还原分割符
| delimiter ; |
调用
语法如下
| call 存储过程(参数列表); 调用存储过程proc_stu call proc_stu(); |
存储过程和函数都是为了可重复的执行操作数据库的 sql 语句的集合.
存储过程和函数都是一次编译,就会被缓存起来,下次使用就直接命中缓存中已经编译好的 sql,
不需要重复编译
减少网络交互,减少网络访问流量
视图
对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦
解决:定义视图
视图本质就是对查询的封装定义视图,建议以v_开头
| create view 视图名称 as select语句; |
例:创建视图,查询学生对应的成绩信息
| create view v_stu_score_course as select stu.*,cs.courseNo,cs.name courseName,sc.score from students stu inner join scores sc on stu.studentNo = sc.studentNo inner join courses cs on cs.courseNo = sc.courseNo |
查看视图:查看表会将所有的视图也列出来
| show tables; |
删除视图
drop view 视图名称; 例:
drop view v_stu_score_course;
使用:视图的用途就是查询
| select * from v_stu_score_course; |
事务
为什么要有事务
事务广泛的运用于订单系统、银行系统等多种场景
例如:A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
- 检查A的账户余额>500元;
- A 账户中扣除500元;
- B 账户中增加500元;
正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后, 系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执 行,要么都不执行。所以,应该把他们看成一个事务。事务是数据库维护数据一致性的单位, 在每个事务结束时,都能保持数据一致性
事务命令
要求:表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引擎查看表的创建语句,可以看到engine=innodb
| show create table students; |
修改数据的命令会触发事务,包括insert、update、delete
开启事务,命令如下:
开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中
| begin; |
提交事务,命令如下
将缓存中的数据变更维护到物理表中
| commit; |
回滚事务,命令如下:
放弃缓存中变更的数据
| rollback; |
提交
为了演示效果,需要打开两个命令行窗口,使用同一个数据库,操作同一张表
step1:连接
命令行1:查询学生信息
| select * from students; |
step2:增加数据
命令行2:开启事务,插入数据
| begin; insert into students(studentNo,name) values ('013','我是新来的'); |
命令行2:查询数据,此时有新增的数据
| select * from students; |
step3:查询
命令行1:查询数据,发现并没有新增的数据
| select * from students; |
step4:提交
命令行2:完成提交
| commit; |
step5:查询
命令行1:查询,发现有新增的数据
回滚
为了演示效果,需要打开两个命令行窗口,使用同一个数据库,操作同一张表
step1:连接
step2:增加数据
命令行2:开启事务,插入数据
| begin; insert into students(studentNo,name) values ('014','又来一个'); |
命令行2:查询数据,此时有新增的数据
| select * from students; |
step3:查询
命令行1:查询数据,发现并没有新增的数据
| select * from students; |
step4:回滚
命令行2:完成回滚
| rollback; |
step5:查询
命令行1:查询数据,发现没有新增的数据
索引
思考:在图书馆中是如何找到一本书的?
一般的应用系统对比数据库的读写比例在10:1左右,而且插入操作和更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重
当数据库中数据量很大时,查找数据会变得很慢优化方案:索引
语法
查看索引
| show index from 表名; |
创建索引
方式一:建表时创建索引
| create table create_index( id int primary key, name varchar(10) unique, age int, key (age) ); |
方式二:对于已经存在的表,添加索引
| 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致字段类型如果不是字符串,可以不填写长度部分 create index 索引名称 on 表名(字段名称(长度)) 例: create index age_index on create_index(age); create index name_index on create_index(name(10)); |
删除索引:
| drop index 索引名称 on 表名; |
示例
导入测试表test_index
| 右键点击某个数据库->运行sql文件->选择test_index.sql->点击开始 |
查询
开启运行时间监测:
| set profiling=1; |
查找第1万条数据test10000
| select * from test_index where title='test10000'; |
查看执行的时间:
| show profiles; |
为表title_index的title列创建索引:
| create index title_index on test_index(title(10)); |
执行查询语句:
| select * from test_index where title='test10000'; |
再次查看执行的时间
| select * from test_index where title='test10000'; |
缺点
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE 和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
但是,在互联网应用中,查询的语句远远大于增删改的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引
外键foreign key
如果一个实体的某个字段指向另一个实体的主键,就称为外键。被指向的实体,称之为主实体
(主表),也叫父实体(父表)。负责指向的实体,称之为从实体(从表),也叫子实体(子表)
对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并报错
语法
查看外键
| show create table 表名 |
设置外键约束
在实际开发中,很少会使用到外键约束,会极大的降低表更新的效率
使用root登录,修改mysql数据库的user表使用password()函数进行密码加密 注意修改完成后需要刷新权限
| use mysql; update user set password=password('新密码') where user='用户名'; 例: update user set password=password('123') where user='root'; 刷新权限:flush privileges; |
忘记 root 账户密码怎么办
1、配置mysql登录时不需要密码,修改配置文件
Centos中:配置文件位置为/data/server/mysql/my.cnf
Windows中:配置文件位置为C:\Program Files (x86)\MySQL\MySQL Server 5.1\my.ini
修改,找到mysqld,在它的下一行,添加skip-grant-tables
| [mysqld] skip-grant-tables |
2、重启mysql,免密码登录,修改mysql数据库的user表
| use mysql; update user set password=password('新密码') where user='用户名'; 例: update user set password=password('123') where user='root'; 刷新权限:flush privileges; |
3、还原配置文件,把刚才添加的skip-grant-tables删除,重启





