前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

现在,广大年轻人到了一定年纪,一定会引来父母的念叨
不是让相亲就是让结婚的,与其父母念叨,不如自己找一个
到时候问起来,就说再接触呢~~
今天我们就来用python看看相亲网都有哪些优质妹子吧~

环境开发:
-
Python 3.8
-
Pycharm
模块使用:
-
import parsel --> pip install parsel
-
import requests --> pip install requests
-
import csv
-
import re
如果安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
-
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
-
点击齿轮, 选择add
-
添加python安装路径
pycharm如何安装插件?
-
选择file(文件) >>> setting(设置) >>> Plugins(插件)
-
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
-
选择相应的插件点击 install(安装) 即可
-
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
基本思路流程:
一. 数据来源分析:
-
明确需求:
采集数据是什么 —> 资料数据 <静态网页>
都是在网页源代码里面
只要获取到所有 ID 就可以 采集所有数据信息
就有所有 小姐姐 详情页url ID
二. 代码实现步骤:
发送请求 获取数据 解析数据 保存数据
获取所有详情页ID:
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据
开发者工具 —> response
-
解析数据, 提取我们想要数据内容
详情页ID —> UID
获取详情页资料信息
-
发送请求, 模拟浏览器对于url地址发送请求
资料详情页url地址
-
获取数据, 获取服务器返回响应数据
网页源代码
-
解析数据, 提取我们想要数据内容
基本资料信息
-
保存数据, 把数据内容保存本地
-
基本资料信息保存csv表格
-
照片数据, 保存本地文件夹
-
代码展示
导入模块
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入csv
import csv
# 导入正则
import re
f = open('data.csv', mode='a', encoding='utf-8', newline='')
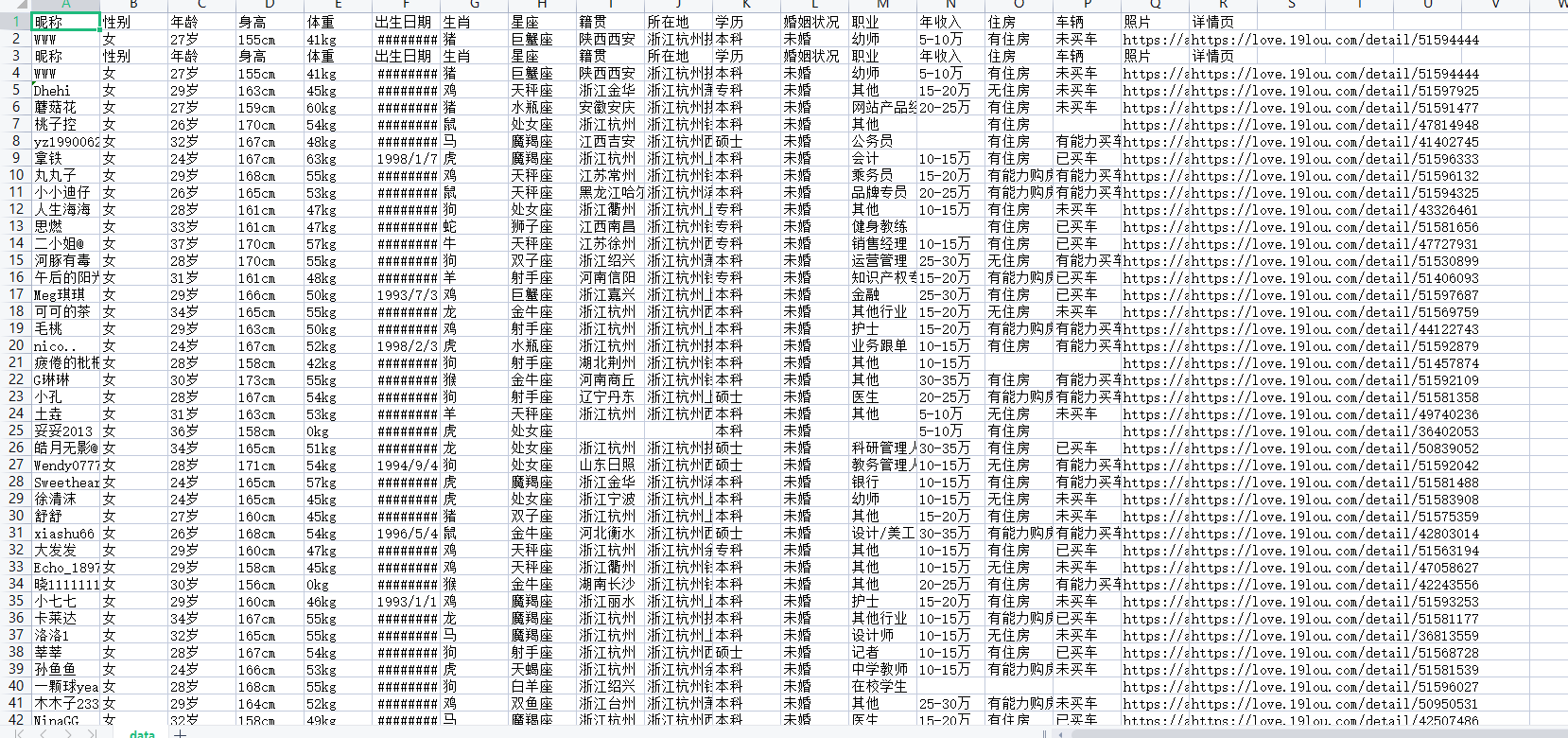
csv_writer = csv.DictWriter(f, fieldnames=['昵称','性别','年龄','身高','体重','出生日期','生肖','星座','籍贯','所在地','学历','婚姻状况','职业','年收入','住房','车辆','照片','详情页',])
csv_writer.writeheader()
“”"
1. 发送请求, 模拟浏览器对于url地址发送请求
-
模拟浏览器 headers 请求头
可以在开发者工具里面复制粘贴的
防止被反爬
-
<Response [200]> 响应对象
200状态码 表示请求成功
“”"
for page in range(1, 11):
请求链接

# 伪装模拟headers = {# User-Agent 用户代理, 表示浏览器基本信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}
发送请求
response = requests.get(url=url, headers=headers)print(response)
“”"
2. 获取数据, 获取服务器返回响应数据
开发者工具 —> response
response.json() 获取响应json数据, 字典数据类型
3. 解析数据, 提取我们想要数据内容
详情页ID —> UID
因为得到数据: 字典数据类型
所以解析数据: 键值对取值 —> 根据冒号左边的内容[键], 提取冒号右边的内容[值]
“”"
# for循环遍历, 把列表里面元素一个一个提取出来for index in response.json()['data']['items']:# https://love.19lou.com/detail/51593564 format 字符串格式化方法link = f'https://love.19lou.com/detail/{index["uid"]}'
“”"
4. 发送请求, 模拟浏览器对于url地址发送请求
资料详情页url地址
5. 获取数据, 获取服务器返回响应数据
网页源代码
response.text 获取响应文本数据, 返回字符串数据类型
response.json() 获取响应json数据, 字典数据类型
“”"
html_data = requests.get(url=link, headers=headers).text
“”"
6. 解析数据, 提取我们想要数据内容
基本资料信息
css选择器: 根据标签属性内容提取数据
xpath: 根据标签节点提取数据
re正则
- 会找数据所对应标签是那个
- 选择复制就可以了
“”"
# 把获取下来 html字符串数据<html_data>, 转成可解析对象selector = parsel.Selector(html_data)name = selector.css('.username::text').get()info_list = selector.css('.info-tag::text').getall()# . 表示调用方法属性gender = info_list[0].split(':')[-1]age = info_list[1].split(':')[-1]height = info_list[2].split(':')[-1]date = info_list[-1].split(':')[-1]# 判断info_list元素个数 当元素个数4个 说明没有体重一栏if len(info_list) == 4:weight = '0kg'else:weight = info_list[3].split(':')[-1]info_list_1 = selector.css('.basic-item span::text').getall()[2:]zodiac = info_list_1[0].split(':')[-1]constellation = info_list_1[1].split(':')[-1]nativePlace = info_list_1[2].split(':')[-1]location = info_list_1[3].split(':')[-1]edu = info_list_1[4].split(':')[-1]maritalStatus = info_list_1[5].split(':')[-1]job = info_list_1[6].split(':')[-1]money = info_list_1[7].split(':')[-1]house = info_list_1[8].split(':')[-1]car = info_list_1[9].split(':')[-1]img_url = selector.css('.page .left-detail .abstract .avatar img::attr(src)').get()# 把获取下来的数据 保存字典里面 字典数据容器dit = {'昵称': name,'性别': gender,'年龄': age,'身高': height,'体重': weight,'出生日期': date,'生肖': zodiac,'星座': constellation,'籍贯': nativePlace,'所在地': location,'学历': edu,'婚姻状况': maritalStatus,'职业': job,'年收入': money,'住房': house,'车辆': car,'照片': img_url,'详情页': link,}csv_writer.writerow(dit)new_name = re.sub(r'[\/"*?<>|]', '', name)
保存图片, 获取图片二进制数据
img_content = requests.get(url=img_url, headers=headers).contentwith open('data\\' + new_name + '.jpg', mode='wb') as img:img.write(img_content)print(dit)
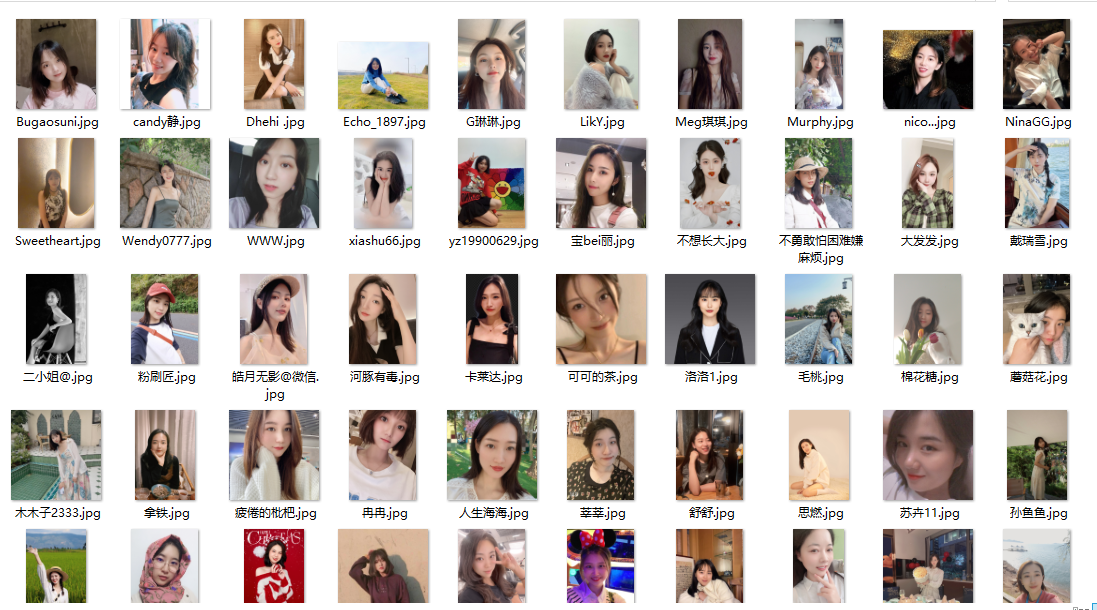
效果展示:

推荐往期文章
🎯 博主所有文章素材、解答、源码、教程领取处:点击
对python感兴趣的小伙伴也可以看一下博主其他相关文章哦~
python小介绍:
python是什么?工作前景如何?怎么算有基础?爬数据违法嘛?。。
python数据分析前景:
用python分析“数据分析”到底值不值得学习,以及学完之后大概能拿到多少工资
python基础自测题:
Python 800 道习题 (°ー°〃) 测试你学废了嘛
最后推荐一套Python视频给大家,希望对大家有所帮助:
全套教程!你和大佬只有一步之遥【python教程】
尾语
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝




![[附源码]Python计算机毕业设计Django大学生考勤管理系统论文](https://img-blog.csdnimg.cn/fc66071795244d90a0887e0d4b1404ae.png)