1、编码表与字符集的区别
比如,unicode是字符集(万国码),但计算机如何存储编码(几个字节存储),这时候要用到编码规则(UTF-8)
举例:
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
utf-8中文3个字节,英文1个字节。gbk中文2个字节,英文1个字节。
2、ASCII扩展码字符和GBK混合写入文件
使用Java IO流同时将欧元符€和汉字写入文件。
FileOutputStream out = new FileOutputStream("E:/tmp/character.txt");
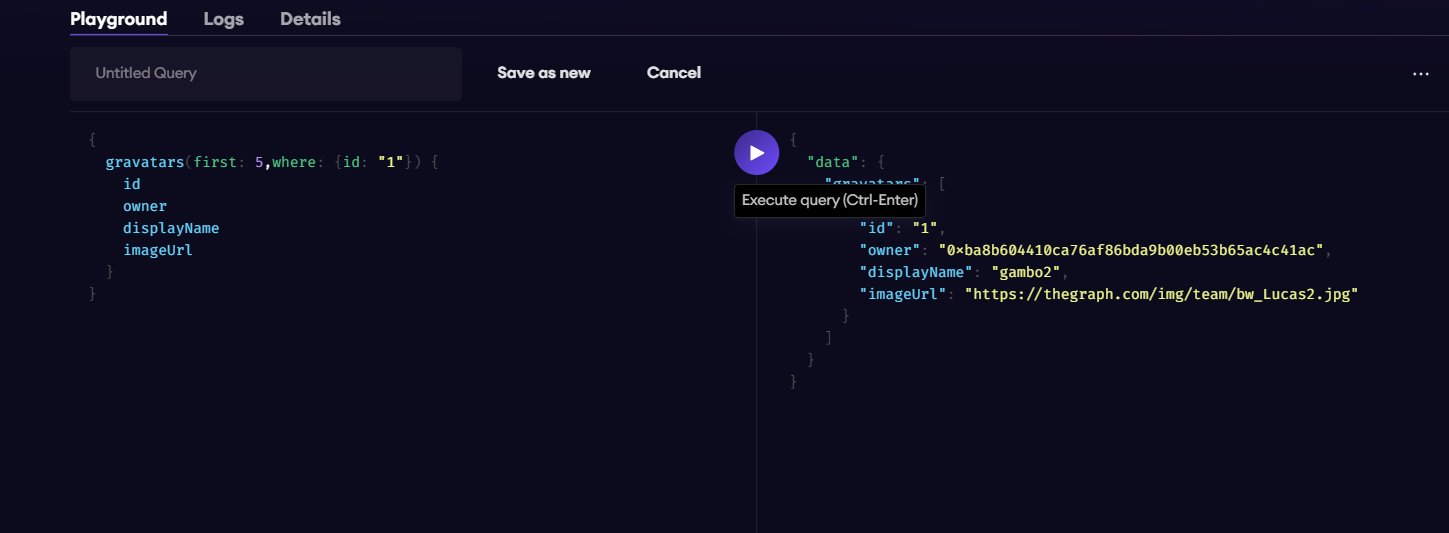
out.write("你好啊".getBytes("GBK"));
// 不能以这种方式写
// out.write("€".getBytes("GBK"));
out.write(128);
out.close();将文件传到linux上之后,执行命令cat test1.txt|od -c,€会显示成200(od表示使用八进制显示),此时说明是正确的
3、Java中关于ASCII扩展码字符的处理
char c = 251; // 扩展ASCII码中字符√的编码
System.out.println(c); // û// 扩展ASCII不是国际标准,编码为251的字符,就不是√,而是û。而√对应的unicode编码是8730,输出8730才能得到√
System.out.println((int)'√'); // 8730
System.out.println((char)8730); // √// 输出扩展ASCII码中字符€的unicode编码
System.out.println((int)'€');
System.out.println((char)8364);注意:java中使用unicode字符表示字符串时,是十六进制,如下代码所示。
System.out.println("\u20AC"); // €的unicode码的十六进制针对扩展的ASCII码,不同的国家有不同的字符集,所以它并不是国际标准。
参考链接:
字符编码中ASCII、Unicode和UTF-8的区别 - 风行风中 - 博客园
ANSI是什么编码?_imxiangzi的专栏-CSDN博客_ansi编码