前言:本篇主要偏向图像分类实战部分,使用MMclassification工具进行代码应用,最后对水果分类进行实战演示,本次环境和代码配置部分省略,具体内容建议参考前一篇文章:计算机视觉框架OpenMMLab开源学习(二):图像分类
计算机视觉框架OpenMMLab开源学习(三):图像分类实战
一、安装OpenMMLab v2.0
Step 1. Install MMCV
mim install "mmcv>=2.0.0rc0"
Step 2. Install MMClassification and MMDetection
mim install "mmcls>=1.0.0rc0" "mmdet>=3.0.0rc0"
代码模版讲解:
model = dict(type='ImageClassifier', # 分类器类型backbone=dict(type='ResNet', # 主干网络类型depth=50, # 主干网网络深度, ResNet 一般有18, 34, 50, 101, 152 可以选择num_stages=4, # 主干网络状态(stages)的数目,这些状态产生的特征图作为后续的 head 的输入。out_indices=(3, ), # 输出的特征图输出索引。越远离输入图像,索引越大frozen_stages=-1, # 网络微调时,冻结网络的stage(训练时不执行反相传播算法),若num_stages=4,backbone包含stem 与 4 个 stages。frozen_stages为-1时,不冻结网络; 为0时,冻结 stem; 为1时,冻结 stem 和 stage1; 为4时,冻结整个backbonestyle='pytorch'), # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积。neck=dict(type='GlobalAveragePooling'), # 颈网络类型head=dict(type='LinearClsHead', # 线性分类头,num_classes=1000, # 输出类别数,这与数据集的类别数一致in_channels=2048, # 输入通道数,这与 neck 的输出通道一致loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # 损失函数配置信息topk=(1, 5), # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率))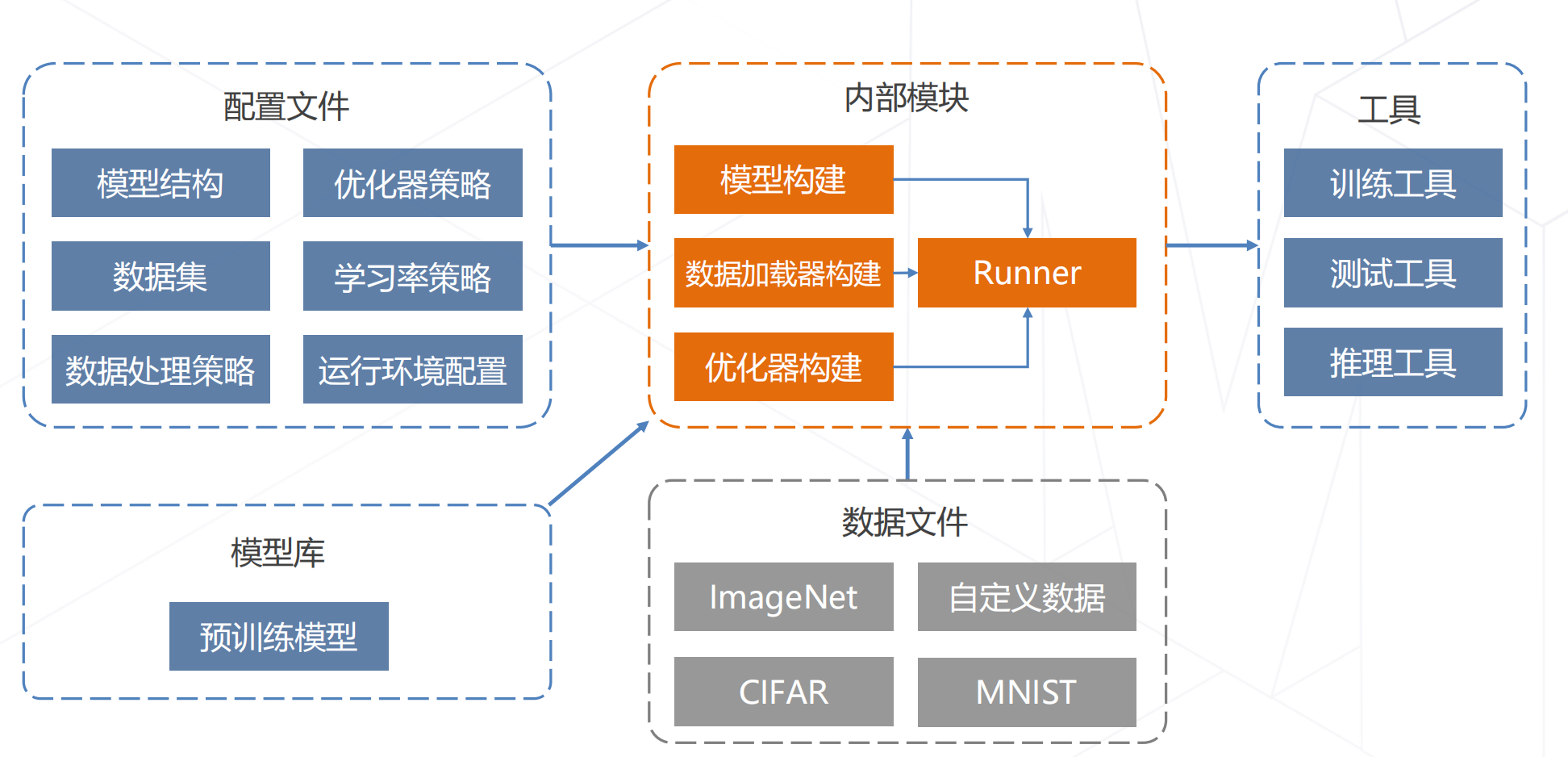 二、Pytorch图像分类任务
二、Pytorch图像分类任务
本次任务训练数据为FashionMNIST,完整代码如下:
# https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.htmlimport torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor# Training## Construct Dataset and Dataloader
training_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),
)
test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),
)batch_size = 64train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)## Define model
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsdevice = "cuda" if torch.cuda.is_available() else "cpu"
model = NeuralNetwork().to(device)## Define loss function and Optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)## Inner loop for training
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)model.train()for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device)# Compute prediction errorpred = model(X)loss = loss_fn(pred, y)# Backpropagationoptimizer.zero_grad()loss.backward()optimizer.step()# Output Logsif batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")## Inner loop for test
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")## Launch training / test loops#
epochs = 5
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Done!")## Saving Modelstorch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")# Deployment## Loading Models
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))# Predict new imagesclasses = ["T-shirt/top","Trouser","Pullover","Dress","Coat","Sandal","Shirt","Sneaker","Bag","Ankle boot",
]model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():pred = model(x)predicted, actual = classes[pred[0].argmax(0)], classes[y]print(f'Predicted: "{predicted}", Actual: "{actual}"')三、利用MMClassification提供的预训练模型推理:
安装环境:
pip install openmim, mmengine
mim install mmcv-full mmclsInference using high-level API
from mmcls.apis import init_model, inference_modelmodel = init_model('mobilenet-v2_8xb32_in1k.py', 'mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth', device='cuda:0')
load checkpoint from local path: mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth
result = inference_model(model, 'banana.png')
result
{'pred_label': 954, 'pred_score': 0.9999284744262695, 'pred_class': 'banana'}
from mmcls.apis import show_result_pyplotshow_result_pyplot(model, 'banana.png', result)
PyTorch codes under the hood
Let write some raw PyTorch codes to do the same thing.
These are actual codes wrapped in high-level APIs.
construct an ImageClassifier
Note: current implementation only allow configs of backbone, neck and classification head instead of Python objects.
from mmcls.models import ImageClassifierclassifier = ImageClassifier(backbone=dict(type='MobileNetV2', widen_factor=1.0),neck=dict(type='GlobalAveragePooling'),head=dict(type='LinearClsHead',num_classes=1000,in_channels=1280) )
Load trained parameters
import torchckpt = torch.load('mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth')
classifier.load_state_dict(ckpt['state_dict'])
Construct data preprocessing pipeline
Important: A models work only if image preprocessing pipelines is correct.
from mmcls.datasets.pipelines import Composetest_pipeline = Compose([dict(type='LoadImageFromFile'),dict(type='Resize', size=(256, -1), backend='pillow'),dict(type='CenterCrop', crop_size=224),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']) ])
data = dict(img_info=dict(filename='banana.png'), img_prefix=None) data = test_pipeline(data) data
{'img_metas': DataContainer({'filename': 'banana.png', 'ori_filename': 'banana.png', 'ori_shape': (403, 393, 3), 'img_shape': (224, 224, 3), 'img_norm_cfg': {'mean': array([123.675, 116.28 , 103.53 ], dtype=float32), 'std': array([58.395, 57.12 , 57.375], dtype=float32), 'to_rgb': True}}),'img': tensor([[[ 0.3309, 0.2967, 0.3138, ..., 2.0263, 2.0092, 1.9920],[ 0.3481, 0.3309, 0.2282, ..., 2.0263, 2.0092, 1.9920],[ 0.2796, 0.2967, 0.2967, ..., 1.9920, 2.0263, 1.9749],...,[ 0.1939, 0.1768, 0.2282, ..., 0.3994, 0.3309, 0.3823],[ 0.1426, 0.1254, 0.2111, ..., 0.5878, 0.5364, 0.5536],[-0.0116, -0.0801, 0.1597, ..., 0.5707, 0.5536, 0.5364]],[[ 0.3803, 0.3803, 0.3803, ..., 2.1660, 2.1485, 2.1134],[ 0.4153, 0.4153, 0.3102, ..., 2.1835, 2.1310, 2.1134],[ 0.3452, 0.3803, 0.3803, ..., 2.1134, 2.1485, 2.1134],...,[ 0.2752, 0.2577, 0.3102, ..., 0.5028, 0.4328, 0.4328],[ 0.2227, 0.1877, 0.3102, ..., 0.6604, 0.6254, 0.5728],[ 0.0301, -0.0049, 0.2402, ..., 0.6604, 0.6254, 0.5728]],[[ 0.5485, 0.5485, 0.5485, ..., 2.3437, 2.3263, 2.2914],[ 0.5834, 0.5834, 0.4788, ..., 2.3611, 2.3088, 2.2914],[ 0.5136, 0.5485, 0.5485, ..., 2.3088, 2.3437, 2.3088],...,[ 0.4091, 0.3916, 0.4439, ..., 0.5834, 0.5136, 0.5311],[ 0.3568, 0.3045, 0.4265, ..., 0.7576, 0.7228, 0.7054],[ 0.1651, 0.1128, 0.3742, ..., 0.7576, 0.7402, 0.7054]]])}
equivalent in torchvision
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, Normalize, ToTensortv_transform = Compose([Resize(256), CenterCrop(224), ToTensor(),Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])image = Image.open('banana.png').convert('RGB')
tv_data = tv_transform(image)
Forward through the model
## IMPORTANT: set the classifier to eval mode classifier.eval()imgs = data['img'].unsqueeze(0) imgs = tv_data.unsqueeze(0)with torch.no_grad():# class probabilitiesprob = classifier.forward_test(imgs)[0]# featuresfeat = classifier.extract_feat(imgs, stage='neck')[0]print(len(prob)) print(prob.argmax().item()) print(feat.shape)
1000 954 torch.Size([1, 1280])
3.使用MMClassificaiton完整进行水果分类实战:
数据集下载:
GitHub - TommyZihao/MMClassification_Tutorials: Jupyter notebook tutorials for MMClassificationJupyter notebook tutorials for MMClassification. Contribute to TommyZihao/MMClassification_Tutorials development by creating an account on GitHub.https://github.com/TommyZihao/MMClassification_Tutorials
代码框架:

def main():model = build_classifier(cfg.model)model.init_weights()datasets = [build_dataset(cfg.data.train)]train_model(model,datasets,cfg,distributed=distributed,validate=(not args.no_validate),timestamp=timestamp,device=cfg.device,meta=meta)
mmcls/apis/train_model.pydef train_model(model,dataset,cfg):data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]optimizer = build_optimizer(model, cfg.optimizer)runner = build_runner(cfg.runner,default_args=dict(model=model,optimizer=optimizer))runner.register_training_hooks(cfg.lr_config,optimizer_config,cfg.checkpoint_config,cfg.log_config,cfg.get('momentum_config', None),custom_hooks_config=cfg.get('custom_hooks', None))runner.run(data_loaders, cfg.workflow)
mmcv/runner/epoch_based_runner.pyclass EpochBasedRunner(BaseRunner):def run_iter(self, data_batch: Any, train_mode: bool, **kwargs) -> None:if train_mode:outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)else:outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)self.outputs = outputsdef train(self, data_loader, **kwargs):self.model.train()self.data_loader = data_loaderfor i, data_batch in enumerate(self.data_loader):self.run_iter(data_batch, train_mode=True, **kwargs)self.call_hook('after_train_iter')
mmcls/models/classifiers/base.pyclass BaseClassifier(BaseModule, metaclass=ABCMeta):def forward(self, img, return_loss=True, **kwargs):"""Calls either forward_train or forward_test depending on whetherreturn_loss=True.Note this setting will change the expected inputs. When`return_loss=True`, img and img_meta are single-nested (i.e. Tensor andList[dict]), and when `resturn_loss=False`, img and img_meta should bedouble nested (i.e. List[Tensor], List[List[dict]]), with the outerlist indicating test time augmentations."""if return_loss:return self.forward_train(img, **kwargs)else:return self.forward_test(img, **kwargs)def train_step(self, data, optimizer=None, **kwargs):losses = self(**data)loss, log_vars = self._parse_losses(losses)outputs = dict(loss=loss, log_vars=log_vars, num_samples=len(data['img'].data))return outputs
mmcls/models/classifiers/image.pyclass ImageClassifier(BaseClassifier):def __init__(self,backbone,neck=None,head=None,pretrained=None,train_cfg=None,init_cfg=None):super(ImageClassifier, self).__init__(init_cfg)if pretrained is not None:self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)self.backbone = build_backbone(backbone)if neck is not None:self.neck = build_neck(neck)if head is not None:self.head = build_head(head)def extract_feat(self, img):x = self.backbone(img)if self.with_neck:x = self.neck(x)return xdef forward_train(self, img, gt_label, **kwargs):x = self.extract_feat(img)losses = dict()loss = self.head.forward_train(x, gt_label)losses.update(loss)return losses
mmcv/runner/hooks/optimizer.pyclass OptimizerHook(Hook):def after_train_iter(self, runner):runner.optimizer.zero_grad()runner.outputs['loss'].backward()runner.optimizer.step()总结:本篇主要偏向图像分类实战部分,使用MMclassification工具进行代码应用,熟悉其框架应用,为后续处理不同场景下分类问题提供帮助。
本文参考:GitHub - wangruohui/sjtu-openmmlab-tutorial


![[OS笔记]文件管理1](https://img-blog.csdnimg.cn/8fb5de53e81146bda5da79758cd98eaf.png)