echarts 图表导出PDF[带滚动条]/图片导出PDF
- 效果展示
- 提出问题
- 思考问题
- 解决问题
- 导出PDF 里面的页头中文乱码问题
- 参数说明
效果展示
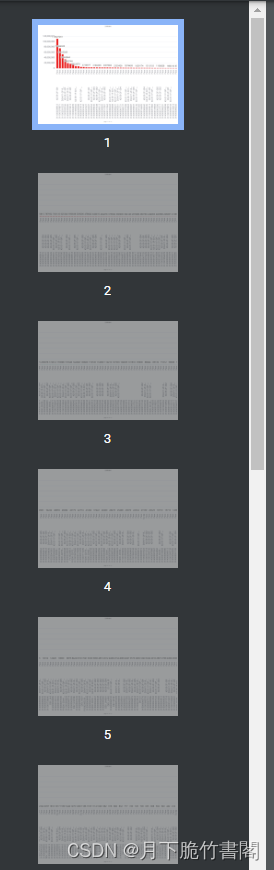
提出问题
在开发过程中,有需求是将展示出来的echarts图表导出为pdf
原本我的滚动条是使用echarts图表进行的滚动,但通过了解后得知,echarts图表如果带滚动条,他只能导出当前页的,因为滚动条以外的是还没有加载,无法导出.
如下图所示:
思考问题
后面通过思考和百度过后得知,可以以一种新的思想去解决:放弃echarts的滚动条,
使用div的滚动条,让echarts图表完全的显示出来
如下图所示:

解决问题
解决这个问题:如何将已经展示出来的完全的图表分页导出PDF
通过了解后,需要下载jspdf和html2canvas(由于echarts是由canvas标签承载的,所以需要下载html2canvas)
- 下载插件命令:
npm install jspdf
npm install html2canvas - .vue文件中引入插件
import html2Canvas from "html2canvas";
import jsPDF from "jspdf"; - 使用!!
- html
<div style="height: 100%; padding-top: 40px"><div class="title">{{ title }}</div><Tooltip content="导出PDF" placement="top-start" class="download"><icon custom="iconfont icon-pdfdayin" @click="exportPDF" /></Tooltip><div class="workbook-temp" ref="workbookTempRef"><div :style="tempStyle" ref="exportContent"><componentref="componentRef":is="barLineScatter":ispreview="true":visib="visib":chartData="chartData":mark="mark"/></div></div>
</div>
- JS
this.$refs.componentRef.myChart.getDom().getElementsByTagName("canvas")[0]说明:
echarts实体获取对应dom标签
//导出PDF
async exportPDF() {//echarts 图表的canvas标签const canvas = this.$refs.componentRef.myChart.getDom().getElementsByTagName("canvas")[0];//由于我这里是动态的图表,所以使用逻辑判断:l:横向;p:纵向const direction = this.chartData.yAxis[0]?.type == "value" ? "l" : "p";const filename = '文件名称.pdf';const title = "echarts图表名称";this.domToPdf(canvas, filename, direction, title);
},
domToPdf(dom, filename, direction, title) {//使导出的图表从最头开始document.documentElement.scrollTop = 0;document.body.scrollTop = 0;html2Canvas(dom, {allowTaint: true,useCORS: true,}).then((canvas) => {//创建实体和设定字体颜色let pdf = new jsPDF("landscape", "pt");pdf.setFontSize(8);pdf.setTextColor("#767676");pdf.setFont("simhei");//用于获取 HTML5 <canvas> 元素的 2D 渲染上下文对象let ctx = canvas.getContext("2d");ctx.canvas.willReadFrequently = true;//PDF 的宽高(-20 和-30 是为了PDF 周边留白)let pdfWidth = pdf.internal.pageSize.getWidth() - 20;let pdfHeight = pdf.internal.pageSize.getHeight() - 30;//echarts图表 的全部宽高let contentWidth = canvas.width;let contentHeight = canvas.height;//PDF高宽比let bi = pdfHeight / pdfWidth;//图片宽 等比例缩小let imgWidth = direction == "p" ? contentWidth : contentHeight / bi; // A4 页面宽度//图片高 等比例缩小let imgHeight = direction == "l" ? contentHeight : contentWidth * bi;// 获取内容宽高与PDF宽高let contentRadio = Math.max(contentWidth / pdfWidth, contentHeight / pdfHeight); //如果小于1 说明导出的图表宽高小于PDF宽高 图要全部图表宽高if (contentRadio <= 1) {imgWidth = contentWidth;imgHeight = contentHeight;}const radioTmp = Math.min(pdfWidth / imgWidth, pdfHeight / imgHeight);// 页面偏移let positionX = 0;let positionY = 0;//高和宽一共有多少let iLength = Math.ceil(contentHeight / imgHeight);let jLength = Math.ceil(contentWidth / imgWidth);for (let i = 0; i < iLength; i++) {positionX = 0;positionY = i * imgHeight;for (let j = 0; j < jLength; j++) {//获取截图所需图片的数据:(位置x,位置y,图片宽,图片高)let imageData = ctx.getImageData(positionX, positionY, imgWidth, imgHeight);//将 ImageData 转换为 base64 格式的图片数据let base64Img = this.getImageDataDataURL(imageData);// 添加页眉(头部居中)pdf.text(`${title}`, pdf.internal.pageSize.width / 2, 10, "center");//图片(图片base64码,图片类型,起始横轴,起始纵轴,等比缩放宽,等比缩放高)pdf.addImage(base64Img, "JPEG", 10, 20, imgWidth * radioTmp, imgHeight * radioTmp);//添加页尾(page 页数 of 总页数)(页尾居中)pdf.text("page " + (i * jLength + j + 1) + " of " + iLength * jLength,pdf.internal.pageSize.width / 2,pdf.internal.pageSize.height - 10,"center");//如果不是最后一页,新增一个PDF页if (!(i == iLength - 1 && j == jLength - 1)) pdf.addPage();//x轴移动j+1 个图片宽度positionX = (j + 1) * imgWidth;}}// 下载操作pdf.save(filename);});},// 将 ImageData 转换为 base64 格式的图片数据getImageDataDataURL(imageData) {let canvasTemp = document.createElement("canvas");canvasTemp.width = imageData.width;canvasTemp.height = imageData.height;canvasTemp.getContext("2d").putImageData(imageData, 0, 0);return canvasTemp.toDataURL("image/png");},
导出PDF 里面的页头中文乱码问题
1.在C:\Windows\Fonts路径中查找黑体常规字体
2.打开此网站将字体转base64码

3.将文件复制到项目中
4.引入
import "@/assets/js/simhei-normal.js";
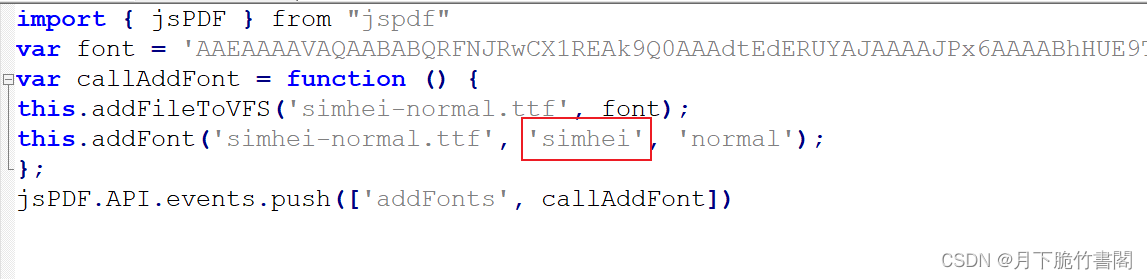
5.设定黑体常规字体
pdf.setFont("simhei");
名称是simhei-normal.js中设定的名字
参数说明
-
html2Canvas参数说明
allowTaint:否允许跨域图片绘制
backgroundColor:指定截图背景颜色
canvas:指定截图结果输出的Canvas元素,如果不指定,则会创建一个新的Canvas元素
foreignObjectRendering:指定是否使用ForeignObject绘制,默认为false,使用ForeignObject可以支持复杂的CSS样式和布局,但是在一些浏览器中可能存在性能问题。
height:指定截图的高度,如果不指定,则使用自动计算的高度。
ignoreElements:指定忽略哪些DOM元素,可以是选择器表达式、DOM元素数组、或者函数。使用选择器表达式时,可以使用逗号分隔多个选择器;使用函数时,参数为当前DOM节点,返回值为true时会被忽略。
letterRendering:指定是否开启字形渲染,默认为false。如果设置为true,可能会导致较慢的渲染速度。
logging:指定是否显示日志信息,默认为false,如果设置为true,则会在控制台输出日志信息。
proxy:指定代理地址,如果需要跨域截图,则需要指定代理地址,否则会被浏览器拦截。
scale:指定截图的缩放比例,默认为1,可以设置为其他值来提高图像质量,但会导致截图时间增加。
useCORS:指定是否使用跨域资源共享(CORS)获取图像,默认为false。
width:指定截图的宽度,如果不指定,则使用自动计算的宽度。 -
addImage
pdf.addImage(pageData, "JPEG", 0, 0, imgWidth, imgHeight)- 图象数据
- 图象格式:JPEG PNG GIF WEBP BMP
- X:PDF 左上角x坐标轴
- y:PDF 左上角Y坐标轴
- width:图象在PDF文档中显示的宽度
- height:图象在PDF文档中显示的高度
- 图象别名
- 压缩方式:NONE:不压缩 FAST 快速压缩


