title: Day76-Netty
date: 2021-07-23 18:03:30
author: Liu_zimo
NIO基础
non-blocking io 非阻塞io
三大组件
通道(Channel)、缓冲区(Buffer)、选择器(Selector)
Channel & Buffer
channel有点类似stream,它就是读写数据的双向通道,可以从channel将数据读入buffer,可以将buffer的数据写入channel,而之前的stream要么是输入,要么是输出,channel比stream更底层
常见的Channel有:
- FileChannel:文件数据传输管道
- DatagramChannel:UDP网络数据传输管道
- SocketChannel:TCP数据传输管道(客户端服务器都能用)
- ServiceSocketChannel:TCP数据传输管道(专用服务器)
Buffer则用来缓存读写数据,常见的Buffer有
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
Selector
- 多线程版设计
graph1[thread] --> 2[socket1]
3[thread] --> 4[socket2]
5[thread] --> 6[socket3]
-
多线程版缺点
-
内存占用高
-
线程上下文切换成本高
只适合连接少数的场景
-
- 线程池版设计
graph1[thread] --> 2[socket1]
1 --> 3[socket2]
4[thread] --> 5[socket3]
4 --> 6[socket4]
- 线程池版缺点
- 阻塞模式下,线程仅能处理一个socket连接
- 仅适合短连接场景
- selector版设计
selector的作用就是配合一个线程来管理多个channel,获取这些channel上发生的事件,这些channel工作在非阻塞模式下,不会让线程吊死在一个channel上。适合连接数特别多,但流量低的场景(low traffic)
graph
1[thread] --> 2[selector]
2 --> 3[channel]
2 --> 4[channel]
2 --> 5[channel]
调用selector的 select()会阻塞直到channel 发生了读写就绪事件,这些事件发生,select方法就会返回这些事件交给thread来处理
ByteBuffer
有一普通文本文件data.txt,内容为:1234567890abcd
使用FileChannel来读取文件内容
package com.zimo.netty;
import lombok.extern.slf4j.Slf4j;
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/*** 测试类* @author Liu_zimo* @version v1.0 by 2021/7/28 11:00:39*/
@Slf4j
public class TestByteBuffer {public static void main(String[] args) {// FileChannel// 1.输入输出流 2.RandomAccessFiletry (FileChannel channel = new FileInputStream("data.txt").getChannel()) {// 准备缓冲区ByteBuffer buffer = ByteBuffer.allocate(10);while (true){// 从channel读取数据,向buffer写int read = channel.read(buffer);log.debug("读取到的子节{}", read);if (read == -1) break; // 没有内容了buffer.flip(); // 切换到读模式// 打印buffer的内容while (buffer.hasRemaining()){ // 是否还有剩余未读数据byte b = buffer.get();log.debug("实际子节{}", (char)b);}buffer.clear(); // 切换为写模式}} catch (IOException e) {e.printStackTrace();}}
}
ByteBuffer正确使用姿势
- 向buffer写入数据,例如调用
channel.read(buffer) - 调用flip()切换读模式
- 从buffer读取数据,例如调用
buffer.get() - 调用
clear()或者compact()切换至写模式 - 重复1-4步骤
ByteBuffer结构
ByteBuffer有以下重要属性
- capacity:容量
- position:读写指针
- limit:读写限制

ByteBuffer常见方法
- 分配空间:可以使用allocate方法为ByteBuffer 分配空间,其它buffer类也有该方法
- Java堆内存(java.nio.HeapByteBuffer)
ByteBuffer buf = ByteBuffer.allocate(16)(读写效率低,受到GC的影响2) - 直接内存(java.nio.DirectByteBuffer)
ByteBuffer buf = ByteBuffer.allocateDirect(16)(读写效率高,少一次拷贝,不会受GC影响)
- Java堆内存(java.nio.HeapByteBuffer)
- 向buffer写入数据
- 调用channel的read方法
int readByte = channel.read(buf);
- 调用buffer自己的put方法
buf.put((byte)127)
- 调用channel的read方法
- 从buffer读取数据
- 调用channel的write方法
int writeBytes = channel.write(buf) - 调用buffer自己的get方法
byte b = buf.get() - get方法会让position读指针向后走,如果想重复读取数据
- 可以调用rewind方法将position重新置为0
- 或者调用get(int index)方法获取索引index的内容,它不会移动读指针
- 调用channel的write方法
- mark & reset
- mark:标记当前Position位置
- reset:跳转到mark标记的位置
字符串与ByteBuffer互转
package com.zimo.netty;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
/*** ByteBuffer与String互转* @author Liu_zimo* @version v1.0 by 2021/7/28 15:23:49*/
public class TestStringExchangeByteBuffer {public static void main(String[] args) {stringToByteBuffer(); // java.nio.HeapByteBuffer[pos=5 lim=16 cap=16]charsetToByteBuffer(); // java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]warpToByteBuffer(); // java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]byteBufferToString(); // hello}// 1.String.getBytes()public static void stringToByteBuffer(){// 字符串转为ByteBufferByteBuffer buffer = ByteBuffer.allocate(16);// 写模式buffer.put("hello".getBytes());System.out.println(buffer);}// 2.Charsetpublic static void charsetToByteBuffer(){// 自动转换为读模式ByteBuffer buffer = StandardCharsets.UTF_8.encode("hello");System.out.println(buffer);}// 3.wrappublic static void warpToByteBuffer(){// 自动转换为读模式ByteBuffer buffer = ByteBuffer.wrap("hello".getBytes());System.out.println(buffer);}public static void byteBufferToString(){String s = StandardCharsets.UTF_8.decode(StandardCharsets.UTF_8.encode("hello")).toString();System.out.println(s);}
}
Scattering Reads
分散读取,有一个文本文件3parts.txt
public static void main(String[] args) { try (FileChannel channel = new RandomAccessFile("data.txt", "r").getChannel()) {ByteBuffer buffer = ByteBuffer.allocate(4);ByteBuffer buffer1 = ByteBuffer.allocate(5);ByteBuffer buffer2 = ByteBuffer.allocate(6);channel.read(new ByteBuffer[]{buffer,buffer1,buffer2});buffer.flip();buffer1.flip();buffer2.flip();while (buffer.hasRemaining()){System.out.println((char) buffer.get());}while (buffer1.hasRemaining()){System.out.println((char)buffer1.get());}while (buffer2.hasRemaining()){System.out.println((char)buffer2.get());}} catch (IOException e) {e.printStackTrace();}
}
GetheringWrites
集中写入到文本test.txt
public static void main(String[] args) {ByteBuffer buffer = StandardCharsets.UTF_8.encode("hello ");ByteBuffer buffer1 = ByteBuffer.wrap("zimo".getBytes());ByteBuffer buffer2 = ByteBuffer.wrap("!".getBytes());try (FileChannel channel = new RandomAccessFile("test.txt", "rw").getChannel()) {channel.write(new ByteBuffer[]{buffer,buffer1,buffer2});} catch (IOException e) {}
}
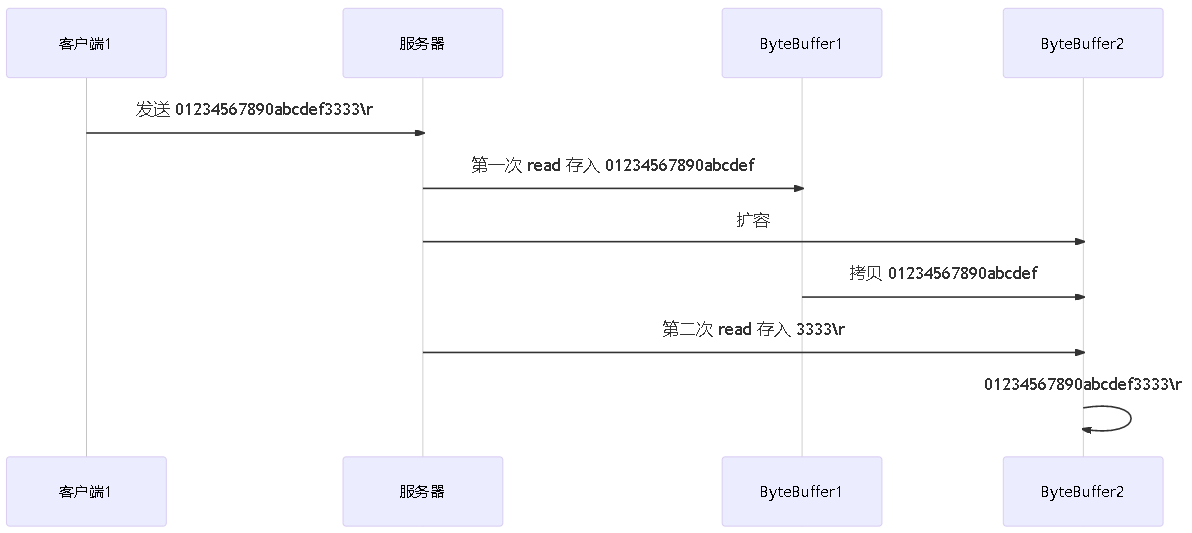
网络上有多条数据发送给服务端,数据之间使用\n进行分隔,但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为:
Hello,word\nI'm zhagnsan\nHow are you?\n
变成下面两个byteBuffer(黏包,半包)
Hello,word\nI'm zhagnsan\nHow are you?\n
- 需求:将错乱的数据恢复成原始的按\n分隔的数据
package com.zimo.netty;import java.nio.ByteBuffer;/** * 恢复错乱的数据 * * @author Liu_zimo * @version v1.0 by 2021/7/28 16:06:01 */public class TestByteBufferExam { public static void main(String[] args) { ByteBuffer buffer = ByteBuffer.allocate(32); buffer.put("Hello,word\nI'm zhagnsan\nHo".getBytes()); split(buffer); buffer.put("w are you?\n".getBytes()); split(buffer); } private static void split(ByteBuffer buffer) { buffer.flip(); for (int i = 0; i < buffer.limit(); i++) { // 找到一条完整的消息 if (buffer.get(i) == '\n') { int lenth = i + 1 - buffer.position(); // 把这条完整消息存入新的bytebuffer ByteBuffer target = ByteBuffer.allocate(lenth); // 从buffer读,写入target for (int j = 0; j < lenth; j++) { target.put(buffer.get()); } target.flip(); while (target.hasRemaining()){ System.out.print((char) target.get()); } } } buffer.compact(); }}
文件编程
FileChannel
- **注意:**FileChannel只能工作在阻塞模式下
获取
不能直接打开FileChannel,必须通过FileInputStream、FileOutputStream或者RandomAccessFile 来获取FileChannel,它们都有getChannel方法
- 通过FilelnputStream获取的channel只能读
- 通过FileOutputStream获取的channel只能写
- 通过RandomAccessFile是否能读写根据构造RandomAccessFile时的读写模式决定
读取
会从channel读取数据填充ByteBuffer,返回值表示读到了多少字节,-1表示到达了文件的末尾
int readBytes = channel.read(buffer);
写入
ByteBuffer buffer = ...;buffer.put(...); // 存入数据buffer.flip(); // 切换读模式while(buffer.hasRemaining()){ channel.write(buffer);}
- 在while中调用channel.write是因为write方法并不能保证一次将buffer中的内容全部写入channel
关闭
channel必须关闭,不过调用了FileInputStream、FileOutputStream或者RandomAccessFile的close方法会间接地调用channel的close方法
位置
- 获取当前位置:
long pos = channel.position(); - 设置当前位置:
channel.position(long newPos); - 设置当前位置时,如果设置为文件的末尾
- 这是读取返回-1
- 这时写入,会追加内容,但是要注意如果position超过文件末尾,再写入时在新内容和原末尾直接会有空洞(00)
大小
使用size方法获取文件的大小
强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用force(true)方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
两个Channel传输数据
public static void main(String[] args) { try ( FileChannel from = new FileInputStream("data.txt").getChannel(); FileChannel to = new FileOutputStream("to.txt").getChannel(); ) { // 效率高,底层利用操作系统的零拷贝进行优化,传输上限2G long size = from.size(); // left:剩余多少子节,传输大于2G的数据 for (long left = size; left > 0;) { left -= from.transferTo(size-left, left, to); } } catch (IOException e) { e.printStackTrace(); } }
Path
jdk7引入了Path和 Paths类
- Path用来表示文件路径
- Paths是工具类,用来获取Path实例
// 相对路径 使用user.dir 环境变量来定位1.txtPath path = Paths.get("1.txt");// 绝对路径 代表了 d:\1.txtPath path = Paths.get("d:\\1.txt");// 绝对路径 代表了 d:/1.txtPath path = Paths.get("d:/1.txt");// 代表了 d:\data\projectPath path = Paths.get("d:\data","project");
- 当前路径:
. - 上级路径:
..
Files
- 检查文件是否存在:
File.exists(Paths.get("hello/data.txt")); - 创建一级目录:
Files.createDirectory(Paths.get("hello/aa"))- 如果目录已存在,会抛异常FileAlreadyExistsException
- 不能一次创建多级目录,否则会抛异常NoSuchFileException
- 创建多级目录:
Files.createDirectory(Paths.get("hello/aa/bb/cc")) - 拷贝文件:
Files.copy(Paths.get("aa/src.txt"), Paths.get("aa/dest.txt"))- 如果目录已存在,会抛异常FileAlreadyExistsException
- 如果希望用source覆盖掉target,需要用StandardCopyOption来控制
Files.copy(Paths.get("aa/src.txt"), Paths.get("aa/dest.txt"), StandardCopyOption.REPLACE_EXISTING);
- 移动文件:
Files.move(Paths.get("aa/src.txt"), Paths.get("aa/dest.txt"), StandardCopyOption.ATOMIC_MOVE);StandardCopyOption.ATOMIC_MOVE保证文件移动的原子性
- 删除文件:
Files.delete(Paths.get("aa/target.txt"))- 如果文件不存在,会抛异常NoSuchFileException
- 删除目录:
Files.delete(Paths.get("aa/bb"))- 如果目录还有内容,会抛异常DirectoryNotEmptyException
- 遍历目录文件:
package com.zimo.netty;import java.io.File;import java.io.IOException;import java.nio.file.*;import java.nio.file.attribute.BasicFileAttributes;import java.util.concurrent.atomic.AtomicInteger;/** * 遍历文件树 * @author Liu_zimo * @version v1.0 by 2021/7/28 17:33:51 */public class TestFilesWalkFileTree { public static void main(String[] args) throws IOException { AtomicInteger dirCount = new AtomicInteger(); AtomicInteger fileCount = new AtomicInteger(); Files.walkFileTree(Paths.get("F:/a"), new SimpleFileVisitor<Path>(){ @Override public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException { System.out.println("****" + dir); dirCount.incrementAndGet(); return super.preVisitDirectory(dir, attrs); } @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { System.out.println(file); fileCount.incrementAndGet(); return super.visitFile(file, attrs); } }); System.out.println("dir " + dirCount); System.out.println("file " + fileCount); // 删除多级路径文件 Files.walkFileTree(Paths.get("F:/a"), new SimpleFileVisitor<Path>(){ @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { Files.delete(file); return super.visitFile(file, attrs); } @Override public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { Files.delete(dir); return super.postVisitDirectory(dir, exc); } }); }}
- 拷贝多文件目录
package com.zimo.netty;import java.io.IOException;import java.nio.file.Files;import java.nio.file.Paths;/** * 多级文件拷贝 * @author Liu_zimo * @version v1.0 by 2021/7/28 17:52:17 */public class TestFileCopy { public static void main(String[] args) throws IOException { String src = "F:\\a"; String dest = "F:\\b"; Files.walk(Paths.get(src)).forEach(path -> { try { String replace = path.toString().replace(src, dest); if (Files.isDirectory(path)) { // 目录 Files.createDirectory(Paths.get(replace) ); }else if (Files.isRegularFile(path)){ Files.copy(path, Paths.get(replace)); } } catch (IOException e) { e.printStackTrace(); } }); }}
网络编程
阻塞VS非阻塞
-
阻塞
- 在没有数据可读时,包括数据复制过程中,线程必须阻塞等待,不会占用cpu,但线程相当于闲置
- 32位jvm一个线程320k,64位jvm一个线程1024k,为了减少线程数,需要采用线程池技术
- 但即便用了线程池,如果有很多连接建立,但长时间inactive,会阻塞线程池中所有线程
-
非阻塞
- 在某个Channel没有可读事件时,线程不必阻塞,它可以去处理其它有可读事件的Channel
- 数据复制过程中,线程实际还是阻塞的(AIO改进的地方)
- 写数据时,线程只是等待数据写入Channel即可,无需等Channel通过网络把数据发送出去
-
客户端
public class Client { public static void main(String[] args) throws IOException { SocketChannel sc = SocketChannel.open(); sc.connect(new InetSocketAddress("127.0.0.1", 10086)); }}
- 阻塞 - 服务端
public class Server { public static void main(String[] args) throws IOException { // 使用nio来理解阻塞模式 ByteBuffer buffer = ByteBuffer.allocate(16); // 1.创建了服务器 ServerSocketChannel ssc = ServerSocketChannel.open(); // 2.绑定监听端口 ssc.bind(new InetSocketAddress(10086)); // 3.连接集合 List<SocketChannel> channels = new ArrayList<>(); while (true){ // 4.accent 建立与客户端连接,SocketChannel用来与客户端之间通信 SocketChannel sc = ssc.accept(); // 阻塞等待连接 channels.add(sc); // 5.接收客户端发送的数据 for (SocketChannel channel : channels) { channel.read(buffer); // 阻塞方法 buffer.flip(); while (buffer.hasRemaining()) { System.out.print((char) buffer.get()); } buffer.clear(); } } }}
- 非阻塞 - 服务端
public static void main(String[] args) throws IOException { // 使用nio来理解阻塞模式 ByteBuffer buffer = ByteBuffer.allocate(16); // 1.创建了服务器 ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); // 设置为非阻塞模式,主要影响accept // 2.绑定监听端口 ssc.bind(new InetSocketAddress(10086)); // 3.连接集合 List<SocketChannel> channels = new ArrayList<>(); while (true){ // 4.accent 建立与客户端连接,SocketChannel用来与客户端之间通信 SocketChannel sc = ssc.accept(); // 非阻塞,线程继续往下执行,如果没有连接为null if (sc != null){ sc.configureBlocking(false); // 非阻塞,主要影响read channels.add(sc); // 5.接收客户端发送的数据 for (SocketChannel channel : channels) { int read = channel.read(buffer);// 非阻塞 if (read <= 0) { continue; } buffer.flip(); while (buffer.hasRemaining()) { System.out.print((char) buffer.get()); } buffer.clear(); } } }}
- Selector - 服务端
- 事件触发
- accept:有连接时触发
- connect:客户端事件,在建立连接后触发
- read:可读事件
- write:可写事件
- 事件触发
public static void main(String[] args) throws IOException { // 1.创建selector,管理多个channel Selector selector = Selector.open(); ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); // 2.建立selector和channel的联系(注册),SelectionKey事件发生后,通过他可以知道是哪个channel的事件 SelectionKey sscKey = ssc.register(selector, 0, null); // key只关注accept事件 sscKey.interestOps(SelectionKey.OP_ACCEPT); ssc.bind(new InetSocketAddress(10086)); while(true){ // 3.selector方法,没有事件发生,线程阻塞,有事件,线程才会恢复运行 selector.select(); // select在未处理时,不会阻塞,要么处理要么取消 // 4.处理事件,SelectionKey内部包含了所有发生的事件 Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); while (iterator.hasNext()){ SelectionKey key = iterator.next(); // 处理完事件,要移除事件,否则下次再处理key找不到对应事件,会有问题 iterator.remove(); // 5.区分事件类型 if (key.isAcceptable()){ // accept事件 ServerSocketChannel channel = (ServerSocketChannel) key.channel(); SocketChannel sc = channel.accept(); sc.configureBlocking(false); // 设置非阻塞 SelectionKey scKey = sc.register(selector, 0, null); scKey.interestOps(SelectionKey.OP_READ); }else if (key.isReadable()){ // read事件 try { SocketChannel channel = (SocketChannel) key.channel(); ByteBuffer buffer = ByteBuffer.allocate(16); int read = channel.read(buffer); // -1正常断开 if (read == -1){ key.cancel(); }else { buffer.flip(); System.out.print(Charset.defaultCharset().decode(buffer)); } } catch (IOException e) { e.printStackTrace(); key.cancel(); // 客户端断开,因此需要将key取消。反注册 } } } }}
- 处理read事件时,要移除处理完的事件
- 若客户端断开时read返回-1,强制断开时抛出异常,要取消掉事件
处理消息边界
- 固定消息长度,数据包大小一样,服务器按照预定长度读取,缺点是浪费带宽
- 按分隔符拆分,缺点是效率低
- TLV格式,即Type类型,Length长度,Value数据,类型和长度知道的情况下,就可以合理分配buffer,缺点是buffer需要提前分配,如果内容过大,则影响server吞吐量

ByteBuffer大小分配
- 每个channel都需要记录可能被切分的消息,因为ByteBuffer不是线程安全的,因此需要为每个channel维护—个独立的ByteBuffer
- ByteBuffer不能太大,比如一个ByteBuffer 1Mb的话,要支持百万连接就要1Tb内存,因此需要设计大小可变的 ByteBuffer
- 一种思路是首先分配一个较小的buffer,例如4k,如果发现数据不够,再分配8k的 buffer,将4kbuffer内容拷贝至8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现
- 另一种思路是用多个数组组成buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
多线程优化
现在都是多核cpu,设计时要充分考虑别让cpu的力量被白白浪费
分两组选择器
- 单线程配一个选择器,专门处理accept事件
- 创建cpu核心数的线程,每个线程配一个选择器,轮流处理read事件
package com.zimo.netty.server;import lombok.extern.slf4j.Slf4j;import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.channels.*;import java.nio.charset.Charset;import java.util.Iterator;import java.util.concurrent.ConcurrentLinkedQueue;import java.util.concurrent.atomic.AtomicInteger;/** * 多线程 * * @author Liu_zimo * @version v1.0 by 2021/7/28 18:04:34 */@Slf4jpublic class ThreadsServer { public static void main(String[] args) throws IOException { Thread.currentThread().setName("boss"); ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); // 设置为非阻塞模式,主要影响accept Selector boss = Selector.open(); SelectionKey bossKey = ssc.register(boss, 0, null); bossKey.interestOps(SelectionKey.OP_ACCEPT); ssc.bind(new InetSocketAddress(10086)); // 1.创建固定数量的worker并初始化 Woker[] wokers = new Woker[Runtime.getRuntime().availableProcessors()]; for (int i = 0; i < wokers.length; i++) { wokers[i] = new Woker("worker-" + i); } AtomicInteger index = new AtomicInteger(); while (true){ boss.select(); Iterator<SelectionKey> iter = boss.selectedKeys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); iter.remove(); if (key.isAcceptable()){ SocketChannel sc = ssc.accept(); sc.configureBlocking(false); log.debug("connected...{}", sc.getRemoteAddress()); // 2.关联selector round robin wokers[index.getAndIncrement() % wokers.length].register(sc);// sc.register(woker.selector, SelectionKey.OP_READ, null); } } } } static class Woker implements Runnable{ private Thread thread; private Selector selector; private String name; private volatile boolean start = false; // 还未初始化 private ConcurrentLinkedQueue<Runnable> queue = new ConcurrentLinkedQueue<>(); public Woker(String name) { this.name = name; } // 初始化线程和selector public void register(SocketChannel sc) throws IOException { if (start) return; this.thread = new Thread(this, name); this.thread.start(); this.selector = Selector.open(); this.start = true; // 像队列添加任务 queue.add(()->{ try { sc.register(selector, SelectionKey.OP_READ, null); } catch (ClosedChannelException e) { e.printStackTrace(); } }); selector.wakeup(); // 唤醒select方法 } @Override public void run() { while (true){ try { this.selector.select(); Runnable task = queue.poll(); if (task != null) { task.run(); } Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); while (iter.hasNext()){ SelectionKey key = iter.next(); iter.remove(); if (key.isReadable()) { ByteBuffer buffer = ByteBuffer.allocate(16); SocketChannel channel = (SocketChannel)key.channel(); channel.read(buffer); buffer.flip(); System.out.println(Charset.defaultCharset().decode(buffer)); } } } catch (IOException e) { e.printStackTrace(); } } } }}
如何拿到cpu个数
Runtime.getRuntime().availableProcessors()如果工作在docker容器下,因为容器不是物理隔离的,会拿到物理cpu个数,而不是容器申请时的个数- 这个问题直到 jdk 10才修复,使用jvm参数UseContainerSupport配置,默认开启
NIO vs BIO
- stream不会自动缓冲数据,channel会利用系统提供的发送缓冲区、接收缓冲区(更为底层)
- stream仅支持阻塞APl,channel同时支持阻塞、非阻塞API,网络channel可配合selector实现多路复用
- 二者均为全双工,即读写可以同时进行
IO模型
同步阻塞、同步非阻塞、同步多路复用、异步阻塞(没有此情况)、异步非阻塞
- 同步:线程自己去获取结果(一个线程)
- 异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)
当调用一次channel.read或stream.read后,会切换至操作系统内核态来完成真正数据读取,而读取又分为两个阶段,分别为:等待数据阶段、复制数据阶段

阻塞IO、非阻塞IO、多路复用、信号驱动、异步IO
零拷贝问题
- 传统IO问题
传统的IO将一个文件通过socket写出
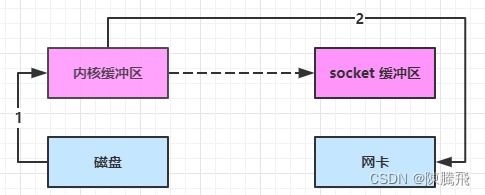
File f = new File("helloword/data.txt");RandomAccessFile file = new RandomAccessFile(f,"r");byte[] buf = new byte[(int) f.length()];file.read(buf);Socket socket = ...;socket.getOutputStream().write(buf);
内部工作流程如下:

-
Java本身不具备IO读写能力,因此read方法调用后,要从Java程序的用户态切换至内核态,去调用操作系统的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用DMA来实现文件读,期间也不会使用cpu
DMA也可以理解为硬件单元,用来解放cpu完成文件IO
-
从内核态切换回用户态,将数据从内核缓冲区读入用户缓存区(即byte[] buf),这期间cpu会参与拷贝,无法利用DMA
-
调用write方法,这时将数据从用户缓冲区(byte[] buf)写入socket缓冲区,cpu会参与拷贝
-
接下来要向网卡写数据,这项能力Java又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用DMA将socket缓冲区的数据写入网卡,不会使用cpu
由此可见中间环节较多,Java的IO实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了3次,这个操作比较重量级
- 数据拷贝了共4次
NIO优化
通过DirectByteBuf
- ByteBuffer.allocate(10) HeapByteBuffer:使用的还是Java内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer:使用的是操作系统内存,Java也可以访问

大部分步骤与优化前相同,唯一一点:Java可以使用DirectByteBuffer将堆外内存映射到jvm内存种来直接访问使用
- 这个内存块不受jvm垃圾回收影响,因此内存地址固定,有助于IO读写
- Java种的DirectByteBuf对象仅维护了此内存的虚引用,内存回收分成两部分
- DirectByteBuf对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化(底层采用了Linux2.1后提供的sendFile方法),Java中对应着两个channel调用transferTo/transferFrom方法拷贝数据

- java调用transferTo方法后,要从Java程序的用户态切换至内核态,使用DMA将数据读入内核缓冲区,不会使用CPU
- 数据从内核缓冲区传输到socket缓冲区,cpu会参与拷贝
- 最后使用DMA将socket缓冲区的数据写入网卡,不会使用cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了3次
进一步优化(Linux2.4)

- java调用transferTo方法后,要从Java程序的用户态切换至内核态,使用DMA将数据读入内核缓冲区,不会使用CPU
- 只会将一些offset和length信息拷入socket缓冲区,几乎无消耗
- 使用DMA将socket缓冲区的数据写入网卡,不会使用cpu
整个过程仅只发生了一次用户态和内核态的切换,数据拷贝了2次。所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到jvm内存中,零拷贝的优点有:
- 更少的用户态与内核态的切换
- 不利用cpu计算,减少cpu缓存伪共享
- 零拷贝适合小文件传输
AIO
AIO用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统提供支持
- Windows系统通过IOCP实现了真正的异步IO
- Linux系统异步IO在2.6版本引入,但其底层实现还是用多路复用模拟了异步IO,性能没有优势
public static void main(String[] args){ try(AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("aa.txt"), StandardOpenOption.READ)){ ByteBuffer buf = ByteBuffer.allocate(16); channel.read(buf, 0, buf, new CompletionHandler<Integer, ByteBuffer>(){ @Override public void completed(Integer result, ByteBuffer attachment){ attachment.flip(); System.out.println(Charset.defaultCharset().decode(buffer)); } @Override public void failed(Throwable exc, ByteBuffer attachment){ exc.printStackTrace(); } }) }}
Netty入门
概述
- 什么是netty
- Netty是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端
Netty的优势
- Netty vs NIO,工作量大,bug多
- 需要自己构建协议
- 解决TCP传输问题,如黏包、半包
- epoll空轮询导致CPU100%
- 对API进行增强,使之更易使用,如FastThreadLocal => ThreadLocal,ByteBuf => ByteBuffer
- Netty vs 其他网络应用框架
- Mina由apache维护,将来3.x版本可能会有较大重构,破坏API向下兼容性,Netty的开发迭代更迅速,API更简洁、文档更优秀
- 久经考验,16年,Netty版本
- 2.x 2004
- 3.x 2008
- 4.x 2013
- 5.x 已废弃(没有明显的性能提升,维护成本高)
Hello Netty
- 引入依赖
<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.39.Final</version></dependency>
- 服务端代码
package com.zimo.netty.hello;import io.netty.bootstrap.ServerBootstrap;import io.netty.channel.ChannelHandlerContext;import io.netty.channel.ChannelInboundHandlerAdapter;import io.netty.channel.ChannelInitializer;import io.netty.channel.nio.NioEventLoopGroup;import io.netty.channel.socket.nio.NioServerSocketChannel;import io.netty.channel.socket.nio.NioSocketChannel;import io.netty.handler.codec.string.StringDecoder;/** * netty server * @author Liu_zimo * @version v1.0 by 2021/8/3 16:13:36 */public class HelloServer { public static void main(String[] args) { // 1.服务器端启动器,负责组装netty组件,启动服务器 new ServerBootstrap() // 2.加入多个事件组EventLoop(selector, thread) .group(new NioEventLoopGroup()) // 3.选择服务器ServerSocketChannel实现 .channel(NioServerSocketChannel.class) // 4.决定了child能执行哪些操作(handler) .childHandler( // 5.代表和客户端进行数据读写的通道channel new ChannelInitializer<NioSocketChannel>() { @Override // 连接建立后。初始化,负责添加别的handler protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { // 添加具体handler nioSocketChannel.pipeline().addLast(new StringDecoder()); // 加入节码,将ByteBuf转换为String nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter(){ // 自定义handler @Override // 读事件 public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { System.out.println(msg); // 打印上一步转换好的字符串 } }); } }) // 6.绑定监听端口 .bind(10086); }}
- 客户端代码
package com.zimo.netty.hello;import io.netty.bootstrap.Bootstrap;import io.netty.channel.ChannelInitializer;import io.netty.channel.nio.NioEventLoopGroup;import io.netty.channel.socket.nio.NioSocketChannel;import io.netty.handler.codec.string.StringEncoder;import java.net.InetSocketAddress;/** * netty client * @author Liu_zimo * @version v1.0 by 2021/8/3 16:26:59 */public class HelloClient { public static void main(String[] args) throws InterruptedException { // 1.启动器 new Bootstrap() // 2.添加EventLoop .group(new NioEventLoopGroup()) // 3.选择客户端的channel实现 .channel(NioSocketChannel.class) // 4.添加处理器 .handler(new ChannelInitializer<NioSocketChannel>() { @Override // 建立连接后调用 protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { nioSocketChannel.pipeline().addLast(new StringEncoder()); // 编码 } }) // 5.连接到服务器 .connect(new InetSocketAddress("localhost", 10086)) // 异步非阻塞 .sync() // 阻塞方法,直到建立连接,也可以使用addListener()方法实现异步调用 .channel() // 代表连接对象 // 6.向服务器发送数据 .writeAndFlush("hello netty!"); }}
概念理解:
- channel可以理解为数据的通道
- msg理解为流动的数据,最开始输入的是ByteBuf,经过pipeline(流水线)的加工,变成其他类型对象
- handler理解为数据的处理工序
- 工序有多道,合在一起就算pipeline,pipeline负责发布事件(读,读取完成…)传播给每个handler,每个handler对自己感兴趣的事件进行处理
- handler分为inbound和outbound两类(入站和出战)
- eventLoop理解为处理数据的工人
- 工人可以管理多个channel和io操作,工人负责某个channel绑定在一起
- 工人既可以执行IO操作,也可以进行任务处理,每个工人有任务队列(普通任务、定时任务),队列里可以堆放多个channel的等待处理任务
- 工人按照pipeline顺序,依次按照handler规划处理数据,每道工序指定不同的工人
组件
EventLoop
EventLoop本质是一个单线程执行器(同时维护了一个Selector),里面有run方法处理Channel上源源不断的IO事件
- 继承关系比较复杂
- 一条线是继承自j.u.c.ScheduledExecutorService因此包含了线程池中所有的方法
- 另一条线是继承自netty自己的OrderedEventExecutor
EventLoopGroup是一组EventLoop,Channel一般会调用EventLoopGroup的register方法来绑定其中一个EventLoop,后续这个Channel上的IO事件都有此EventLoop来处理(保证了io事件处理时的线程安全)
- 继承自netty的EventExecutorGroup
public static void main(String[] args) { // 1.创建事件循环组 EventLoopGroup group = new NioEventLoopGroup(2); // io事件、普通任务、定时任务// EventLoopGroup group = new DefaultEventLoopGroup(); // 普通任务、定时任务 // 2.获取下一个事件循环对象 group.next(); // 3.执行普通任务 group.next().submit(()->{ System.out.println(Thread.currentThread().getName() + ": ok"); }); group.next().execute(()->{ System.out.println(Thread.currentThread().getName() + ": ok"); }); // 4.定时执行任务 group.next().scheduleAtFixedRate(()->{ System.out.println(Thread.currentThread().getName() + ": ok"); }, 0, 1, TimeUnit.SECONDS); // 定时任务,开始任务时间,时间间隔,时间单位 }
handler执行中如何换人
- 关键代码
io.netty.channel.AbstractChannelHandlerContext#invokeChannelRead()
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) { final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next); // 下一个handler的事件循环是否与当前的事件循环是同一个线程 EventExecutor executor = next.executor(); // 返回下一个handler的eventloop // 是否直接调用 if (executor.inEventLoop()) { // 当前handler中的线程,是否和eventLoop是同一个线程 next.invokeChannelRead(m); } else { // 不是,将要执行的代码作为任务提交给下一个事件循环处理(换人) executor.execute(new Runnable() { public void run() { next.invokeChannelRead(m); } }); }}
Channel
channel的主要作用
- close()可以用来关闭channel
- closeFuture()用来处理channel的关闭
- sync方法作用是同步等待channel关闭
- 而addListener方法是异步等待channel关闭
- pipeline()方法添加处理器
- write()方法将数据写入
- writeAndFlush()方法将数据写入并刷出

要点:
- 单线程无法异步提高效率,必须配合多线程、多核cpu才能发挥异步的优势
- 异步并没有缩短响应时间,反而有所增加(提高的是吞吐量)
- 合理进行任务拆分,也是利用异步的关键
Future & Promise
在异步处理时,经常用到这两个接口
首先说明netty中的Future与jdk中的Future同名,但是是两个接口,netty的Future继承自jdk的Future,而Promise有对netty Future进行扩展
- jdk Future只能同步等待任务结束(成功、失败)才能得到结果
- netty Future可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束
- netty Promise不仅有netty Future的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
| 功能/名称 | JDK Future | Netty Future | Netty Promise |
|---|---|---|---|
| cancel | 取消任务 | - | - |
| isCanceled | 任务是否取消 | - | - |
| idDone | 任务是否完成,不能区分成失败 | - | - |
| get | 获取任务结果,阻塞等待 | - | - |
| getNow | - | 获取任务结果,非阻塞,还未产生结果时返回null | - |
| await | - | 等待任务结束,如果任务失败,不会抛异常,而是通过isSuccess判断 | - |
| sync | - | 等待任务结束,如果任务失败,抛出异常(不获取结果) | - |
| isSuccess | - | 获取失败信息,非阻塞,如果没有失败,返回null | - |
| cause | - | 获取失败信息,非阻塞,如果没有失败,返回null | - |
| addLinstener | - | 添加回调,异步接收结果 | - |
| setSuccess | - | - | 设置成功结束 |
| setFailure | - | - | 设置失败结果 |
- JDK Future
public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService service = Executors.newFixedThreadPool(2); Future<Integer> submit = service.submit(new Callable<Integer>() { @Override public Integer call() throws Exception { return 20; } }); System.out.println(submit.get().toString());}
- Netty Future
public static void main(String[] args) throws ExecutionException, InterruptedException { NioEventLoopGroup group = new NioEventLoopGroup(); EventLoop eventLoop = group.next(); Future<Integer> submit = eventLoop.submit(new Callable<Integer>() { @Override public Integer call() throws Exception { return 10; } }); submit.addListener(new GenericFutureListener<Future<? super Integer>>() { @Override public void operationComplete(Future<? super Integer> future) throws Exception { System.out.println(future.getNow()); } });}
- Netty Promise
public static void main(String[] args) throws ExecutionException, InterruptedException { // 1.准备EventLoop对象 NioEventLoopGroup group = new NioEventLoopGroup(); // 2.可以主动创建一个promise,结果容器 DefaultPromise<Integer> promise = new DefaultPromise<>(group.next()); new Thread(()->{ // 3.任意线程执行计算,向promise填充结果 promise.setSuccess(100); }).start(); System.out.println(promise.get());}
Handler & Pipeline
ChannelHandler用来处理Channel上的各种事件,分为入站、出站两种。所有ChannelHandler被连成—串,就是Pipeline
- 入站处理器通常是ChannellnboundHandlerAdapter的子类,主要用来读取客户端数据,写回结果
- 出站处理器通常是ChannelOutboundHandlerAdapter的子类,主要对写回结果进行加工
打个比喻,每个Channel是一个产品的加工车间,Pipeline是车间中的流水线,ChannelHandler就是流水线上的各道工序,而后面要讲的ByteBuf是原材料,经过很多工序的加工:先经过一道道入站工序,再经过一道道出站工序最终变成产品
public static void main(String[] args) { new ServerBootstrap() .group(new NioEventLoopGroup()) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { // 1.通过channel拿到pipeline ChannelPipeline pipeline = nioSocketChannel.pipeline(); // 2.添加处理器 head -> hi1...hin -> tail 1...n pipeline.addLast("hi1", new ChannelInboundHandlerAdapter(){ @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { System.out.println(msg.toString()); super.channelRead(ctx, msg); nioSocketChannel.writeAndFlush(ctx.alloc().buffer().writeBytes("server..".getBytes())); // 使用ctx代表当前,而nioSocketChannel则是从head/tail开始 // ctx.writeAndFlush(ctx.alloc().buffer().writeBytes("server..".getBytes())); } }); // 3.出栈处理(先进后出)head <- ho1...hon <- tail n...1 pipeline.addLast("ho1", new ChannelOutboundHandlerAdapter(){ @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { System.out.println(msg.toString()); super.write(ctx, msg, promise); } }); } }) .bind(8080);}

ByteBuf
是对字节数据的封装
- 创建:
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
public static void main(String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(); // 不指定容量默认256 System.out.println(buffer); StringBuilder sb = new StringBuilder(); for (int i = 0; i < 300; i++) { sb.append("a"); } buffer.writeBytes(sb.toString().getBytes()); // 超过容量会自动扩容 System.out.println(buffer);}
-
直接内存 vs 堆内存
-
可以使用下面的代码来创建池化基于堆的ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10); -
也可以使用下面的代码来创建池化基于直接内存的ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10); -
直接内存创建和消费的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
-
直接内存对GC压力小,因为这部分内存不受JVM垃圾回收的管理,但也要注意及时主动释放
-
-
池化 vs 非池化
池化的最大意义在于可以重用ByteBuf,优点有
- 没有池化,则每次都得创建新的ByteBuf实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加GC压力
- 有了池化,则可以重用池中的ByteBuf实例,并且采用了与jemalloc类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
-Dio.netty.allocator.type={unpooled|pooled}- 4.1以后,非Android平台默认启用池化实现,Android平台启用非池化实现
- 4.1之前,池化功能还不成熟,默认是非池化实现
-
组成
ByteBuf由4部分组成,最开始读写指针都在0位置,有独立的读写指针,不需要切换读写模式

-
写入
方法列表,只列出重点方法
方法签名2 含义 备注 writeBoolean(boolean value) 写入boolean值 用一字节01|00代表true|false writeByte(int value) 写入byte值 writeShort(int value) 写入short值 writeInt(int value) 写入int值 Big Endian,即0x250,写入后00 00 02 50 writeIntLE(int value) 写入int值 Little Endian,即0x250,写入后50 02 00 00 writeLong(long value) 写入long值 writeChar(int value) 写入char值 writeFloat(float value) 写入float值 writeDouble(double value) 写入double值 writeBytes(ByteBuf src) 写入netty的ByteBuf writeBytes(byte[] src) 写入bytep[] writeBytes(ByteBuffer src) 写入nio的ByteBuffer int writeCharSequence(CharSequence squence, Charset charset) 写入字符串 注意:
- 这些方法的未指明返回值的,其返回值都是ByteBuf,意味着可以链式调用
- 网络传输,默认习惯是Big Endian
-
扩容
再写入一个int整数时,容量不够了(初始容量设为10),这是会触发扩容
buffer.writeInt(100);- 扩容规则
- 如果写入后数据大小未超过512,则选择下一个16的整数倍,例如写入后大小为12,则扩容后capacity是16
- 如果写入后数据大小超过512,则选择下一个2n,例如写入后大小为513,则扩容后capacity是210=1024(2^9=512已经不够了)
- 扩容不能超过max capacity会报错
- 扩容规则
-
读取
读过的内容,就属于废弃部分了,再读只能读那些尚未读取的部分,如果需要重复读取int整数5,可以在read前先做个标记mark,需要时,重置到标记位reset,还有则是采用get方法,但该方法不会改变指针位置
-
retain & release
由于Netty中有堆外内存的ByteBuf实现,堆外内存最好是手动来释放,而不是等GC垃圾回收
- UnpooledHeapByteBuf使用的是JVM内存,只需等待GC回收内存即可
- UnpooledDirectByteBuf使用的是直接内存,需要特殊方法来回收内存
- PooledByteBuf和它的子类使用了池化机制,需要更复杂的规则来回收内存
- 回收内存的源码实现,关注下面方法的不同实现:
protected abstract void deallocate()
- 回收内存的源码实现,关注下面方法的不同实现:
Netty这里采用了引用技术法控制回收内存,每个ByteBuf都实现了ReferenceCounted接口
- 每个ByteBuf对象的初始计数为1
- 调用release方法计数减1,如果计数为0,ByteBuf内存被回收
- 调用retain方法计数加1,表示调用者没用完之前,其他handler即使调用了release也不会造成回收
- 当计数为0时,底层内存会被回收,这时即使ByteBuf对象还在,其各个方法均无法正常使用
谁来释放release,pipeline一般需要传递ByteBuf给下一个handler,如果在handler的finally中release,就失去了传递性
基本规则是,谁是最后使用者,谁负责release。
-
slice
【零拷贝】体现之一,对原始ByteBuf进行切片成多个ByteBuf,切片后的ByteBuf并没有发生内存复制,还是使用原始ByteBuf的内存,切片后的ByteBuf独立维护read,write指针
public static void main(String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10); buffer.writeBytes(new byte[]{'a','b','c','d','e','f','g','h','i','j'}); // 在切片过程中,没有发生数据复制,最大容量不能超过切片的数量 ByteBuf f1 = buffer.slice(0, 5); // abcde ByteBuf f2 = buffer.slice(5, 5); // fghij // 修改切片值,原有数据也会发生改变 f1.setByte(0, 'b'); System.out.println(buffer); // bbcedfghij // 释放原有内存,切片无法使用 buffer.release(); System.out.println(f1); // error}
-
duplicate
【零拷贝】体现之一,就好比截取了原始ByteBuf所有内容,并且没有max capacity的限制,也是与原始ByteBuf使用同一块底层内存,只是读写指针是独立的
-
copy
会将底层内存数据进行深拷贝,因此无论读写,都与原始ByteBuf无关
public static void main(String[] args) { ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(); buf1.writeBytes(new byte[]{1,2,3,4,5}); ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(); buf2.writeBytes(new byte[]{6,7,8,9,10}); // 传统方案 ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(); buffer.writeBytes(buf1).writeBytes(buf2); // CompositeByteBuf CompositeByteBuf bufs = ByteBufAllocator.DEFAULT.compositeBuffer(); bufs.addComponents(true, buf1, buf2);}
-
Unpooled
Unpooled是一个工具类,类如其名,提供了非池化的ByteBuf创建、组合、复制等操作
这里只介绍跟【零拷贝】相关的wrappedBuffer方法,可以用来包装ByteBuf
public static void main(String[] args) { ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(); buf1.writeBytes(new byte[]{1,2,3,4,5}); ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(); buf2.writeBytes(new byte[]{6,7,8,9,10}); // 当包装ByteBuf个数超过一个时,底层使用CompositeBuf ByteBuf buffer = Unpooled.wrappedBuffer(buf1, buf2); System.out.println(ByteBufUtil.prettyHexDump(buffer))}
也可用来包装普通子节数组,底层也不会有拷贝操作
ByteBuf优势
- 池化 - 可以重用池中ByteBuf实例,更节约内存,减少内存溢出的可能
- 读写指针分离,不需要像ByteBuffer一样切换读写模式
- 可以自动扩容
- 支持链式调用,使用更流畅
- 很多地方体现零拷贝,例如slice、duplicate、CompositeByteBuf
双向通信
读和写的误解
最初的认识,以为只有在netty,nio这样的多路复用IO模型时,读写才不会相互阻塞,才可以实现高效的双向通信,但实际上,Java Socket是全双工的:在任意时刻,线路上存在A到B和B到A的双向信号传输。即使是阻塞IO,读和写是可以同时进行的,只要分别采用读线程和写线程即可,读不会阻塞写、写也不会阻塞读
Netty进阶
滑动窗口

- TCP以一个段为单位,每发送一个段就需要进行一次确认应答(ack)处理,但如果这么做,缺点就算包的往返实际越长,性能就越差
- 为了解决此问题,引入了窗口概念,窗口大小决定了无需等待应答可以继续发送的数据最大值
- 窗口实际就起到一个缓冲区的作用,同时也能起到流量控制的作用
- 窗口内的数据才允许被发送,当应答未到达之前,窗口必须停止滑动
- 如果数据ack回来了,窗口就可以向前滑动
- 接收方也会维护一个窗口,只有落在窗口内数据才能被允许接收
粘包和半包
粘包现象
- 现象:发送abc、def,接收abcdef
- 原因
- 应用层:接收方ByteBuf设置太大(Netty默认1024)
- 滑动窗口:假设发送方256bytes表示一个完整报文,但由于接收方处理不及时且窗口大小足够大,这256bytes字节就会缓冲在接收方的滑动窗口中,当滑动窗口中缓冲了多个报文,就会黏包
- Nagle算法:会造成黏包
- 解决方案:
- 短链接,客户端发送完,断开连接,消息边界,从连接建立到连接断开,无法解决半包问题
- 定长消息解码器,与客户端约定子节大小,FixedLengthFrameDecoder(10)
- 分隔符消息解码器(回车+换行):LineBasedFrameDecoder(最大长度)、(自定义分隔符):DelimiterBasedFrameDecoder(最大长度,指定分隔符)
- LTC消息解码器(基于长度字段):LangthFieldBasedFrameDecoder(最大长度,长度字段偏移量,长度字段的长度,长度字段为基准还有间隔几个字节才是内容,从头剥离几个字节)
public static void main(String[] args) { EmbeddedChannel channel = new EmbeddedChannel( new LengthFieldBasedFrameDecoder(1024,0,4,1,4), new LoggingHandler(LogLevel.DEBUG) ); // 4个字节的内容长度,实际内容 ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(); send(buffer, "hello, world"); send(buffer, "hi!"); channel.writeInbound(buffer);}private static void send(ByteBuf buffer, String content) { byte[] bytes = content.getBytes(); buffer.writeInt(bytes.length); buffer.writeByte(1); buffer.writeBytes(bytes);}
半包现象
- 现象:发送abcdef,接收abc、def
- 原因:
- 应用层:接收方ByteBuf小于实际发送数据量
- 滑动窗口:假设接收方的窗口只剩了128bytes,发送方的报文大小是256bytes,这时放不下了,只能先发送前128bytes,等待ack后才能发送剩余部分,这就造成了半包
- MSS限制:当发送的数据超过MSS限制后,会将数据切分发送,就会造成半包
本质是因为TCP是流式协议,消息无边界
协议设计与解析
自定义协议要素:
- 魔数,用来在第一时间判定是否是无效数据包
- 版本号,可以支持协议的升级
- 序列化算法,消息正文到底采用那种序列化反序列化方式,可以由此扩展,例如:json、protobuf、hessian、jdk
- 指令类型,是登录、注册、单聊、群聊…跟业务相关
- 请求序号,为了双工通信,提供异步能力
- 正文长度
- 消息正文
@Sharable:netty线程安全
连接假死
- 原因
- 网络设备出现故障,例如网卡,机房等,底层的TCP连接已经断开了,但应用程序没有感知到,仍然占用着资源
- 公网网络不稳定,出现丢包。如果连续出现丢包,这时现象就是客户端数据发不出去,服务端也一直收不到数据,就这么一直耗着
- 应用程序线程阻塞,无法进行读取数据
- 问题
- 假死的连接占用的资源不能自动释放
- 向假死的连接发送数据,得到的反馈是发送超时
源码剖析
启动剖析
- 传统NIO流程
// 1.netty中使用NioEvnetLoopGroup(简称nio boss线程)来封装线程和selectorSelector selector = Selector.open();// 2.创建NioServerSocketChannel,同时会初始化它关联的handler,以及为原生ssc存储configNioServerSocketChannel attachment = new NioServerSocketChannel();// 3.创建NioServerSocketChannel时,创建了Java原生的ServerSocketChannelServerSocketChannel serverSocketChannel = ServerSocketChannel.open(); // 1serverSocketChannel.configureBlocking(false);// 4.启动nio boss线程执行接下来操作// 5.注册(仅关联selector和NioServerSocketChannel),未关注事件SelectionKey selectionKey = serverSocketChannel.register(selector, 0, attachment); // 2// 6.head -> 初始化器 -> ServerBootstrapAcceptor -> tail,初始化器是一次性的,只为添加acceptor// 7.绑定端口serverSocketChannel.bind(new InetSocketAddress(8080)); // 3// 8.触发channel active事件,在head中关注op_accept事件selectionKey.interestOps(SelectionKey.OP_ACCEPT); // 4
- Netty中启动流程
new ServerBootstrap() .group(new NioEventLoopGroup()) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>(){ @Override protected void initChannel(NioSocketChannel ch){ ch.pipeline().addLast(new LoggingHandler()); } }).bind(8080);/* 1.bind() -> doBind() -> initAndRegister() 对应传统NIO的 1、2 1.1 init: * 创建NioServerSocketChannel【main-thread】 * 添加NioServerSocketChannel的初始化handler【main-thread】 * 初始化handler等待调用【nio-thread】 1.2 register:切换线程 * 启动 nio boss线程 【main-thread】 * 原生ssc注册至selector未关注事件 【nio-thread】 * 执行NioServerSocketChannel初始化handler 【nio-thread】 2.regFuture等待回调doBind0(): * 原生ServerSocketChannel绑定端口【nio-thread】 * 触发NioServerSocketChannel active事件【nio-thread】*/
NioEventLoop
- NioEventLoop重要组成:selector、线程、任务队列
- NioEventLoop即会处理io事件,也会处理普通任务和定时任务
- **selector何时创建:**在构造方法调用时创建
- **selector为何又两个selector成员:**一个原始(基于Set实现),一个netty优化后的(基于数组实现),为了遍历key时提高性能
- **nio线程在何时启动:**当首次调用execute方法时,通过状态位控制线程只会启动一次
- **提交普通任务会不会结束select阻塞:**会阻塞,但是在提交任务时会被唤醒
- **wakeup方法中的代码如何理解:**只有其他线程提交任务,才会调用selector的wakeup
- **wakeenUp变量的作用是什么:**原子变量,如果多个线程都提交任务,只需唤醒一次即可,避免wakeup被频繁调用
- **每次循环时,什么时候会进入SelectStrategy.SELECT分支:**当没有任务时,才会进入该分支,当有任务时会调用selectNow方法,顺便拿到IO事件
- **何时会select阻塞,阻塞多久:**没有定时任务时阻塞,当有任务、事件、超时时间(1s+0.5ms)截至
- **nio空轮询bug在哪里体现,如何解决:**计数法空轮询数量超过指定次数,重新创建一个selector,替换掉旧的selector(JDK在Linux环境下的selector导致的bug)
- **ioRatio控制什么,设置为100有何作用:**控制处理IO事件所占用时间的比例50%。设置为100,执行完IO任务后,会将所有普通任务执行完
- **selectedKeys优化是怎么回事:**netty使用数组替换传统Nio中的Set方式,提高遍历效率
- **在哪区分不同事件类型:**processSelectedKey()中实现
accept流程
- 传统NIO流程:
- selector.select()阻塞直到事件发生
- 遍历处理selectedKeys
- 拿到一个key,判断事件类型是否为accept
- 创建SocketChannel,设置非阻塞
- 将SocketChannel注册至selector
- 关注selectionKey的read事件
- Netty流程:
- 1、2、3在EventLoop中实现了
- processSelectedKey() -> unsafe.read()
- 4 -> doReadMessage():创建了NioSocketChannel
- 5 -> doRegister():sc.register(eventLoop选择器,0,NioSocketChannel),调用NioSocketChannel上的初始化器
- 6 -> pipeline() -> doBeginRead()
read流程
- selector.select()阻塞直到事件发生
- 遍历处理selectedKeys
- 拿到一个key,判断事件类型是否为read
- 读取操作