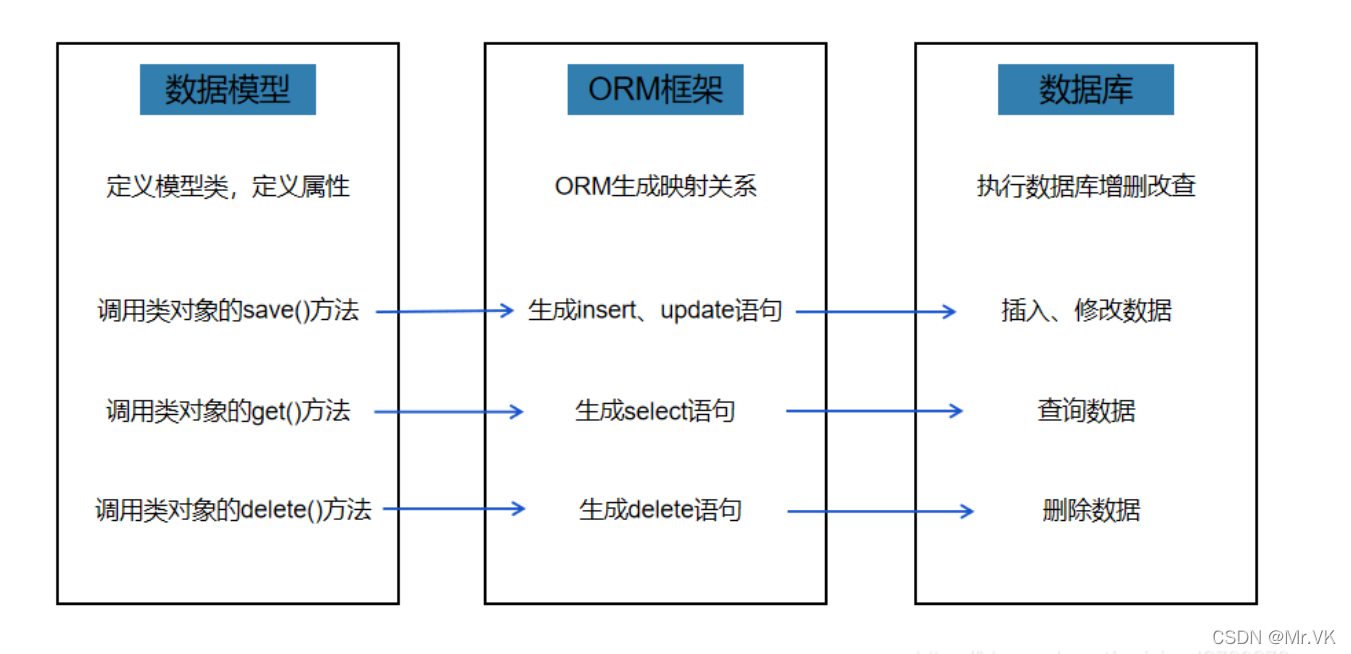
使用了Flask-SQLAlchemy作为ORM框架,来更方便的对数据库进行读写,增删改查是数据库的基本操作,今天这一章节就在对原先的后端做兼容MySQL改造的同时,也对“删、改、查”做一个详细的讲解。
模型定义
上一章节在models.py中定义了Devices模型,现在将它放在app.py中,代码如下:
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import text, DateTime, Numericapp = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = "mysql+pymysql://root:root@127.0.0.1:3306/ops?charset=utf8"
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)class Devices(db.Model):__tablename__ = 'devices'id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment="自增主键")ip = db.Column(db.String(16), nullable=False, comment="IP地址")hostname = db.Column(db.String(128), nullable=False, comment="主机名")idc = db.Column(db.String(32), comment="机房")row = db.Column(db.String(8), comment="机柜行")column = db.Column(db.String(8), comment="机柜列")vendor = db.Column(db.String(16), comment="厂商")model = db.Column(db.String(16), comment="型号")role = db.Column(db.String(8), comment="角色")created_at = db.Column(db.DateTime(), nullable=False, server_default=text('NOW()'), comment="创建时间")if __name__ == "__main__":app.run(host="127.0.0.1", port=5000, debug=True)以上示例代码中为了突出本章节重点内容,暂时省略掉了之前的权限认证部分。
有的朋友可能会有疑问,为什么不能将Devices放在models.py中,然后在app.py中将其import进来,这是因为,目前路由函数和app变量以及db变量的定义都写在app.py中,而Devices类又需要用到db变量,这样会造成app.py和models.py文件的循环引用。
关于如何合理规划数据库模型与路由函数以及app变量的挂载,我们会在后续的Flask工厂化内容中详细讲解。
Python字典与模型转换
上一章节中提到,通过模型进行添加数据记录的方法如下:
device = Devices(ip="10.0.0.1", hostname="BJ-R01-C01-N9K-00-00-01", idc="Beijing", row="R01", column="C01", vendor="Cisco", model="Nexus9000", role="CSW")
db.session.add(device)
db.session.commit()Devices是数据模型(表结构),将其实例化就可以得到一个device对象,相当于是数据库中的一行记录。
那么现在路由函数如下:
@app.route("/cmdb/add", methods=["POST"])
def add():data = request.get_json()device = Devices(ip=data.get("ip"), hostname=data.get("hostname"), idc=data.get("idc"), row=data.get("row"), column=data.get("column"), verdor=data.get("vendor"), model=data.get("model"), role=data.get("role"))db.session.add(device)db.session.commit()return {"status_code": HTTPStatus.OK}上述路由函数中通过一个个指定属性值的方式来对Devices记录进行初始化,显然这样做不太优雅,我们可以在Devices类中增加一个方法来实现字典类型到Devices模型的转换,如下:
class Devices(db.Model):__tablename__ = 'devices'...@classmethoddef to_model(cls, **kwargs):device = Devices() # 实例化一个device对象columns = [c.name for c in cls.__table__.columns] # 获取Devices模型定义的所有列属性的名字for k, v in kwargs.items(): # 遍历传入kwargs的键值if k in columns: # 如果键包含在列名中,则为该device对象赋加对应的属性值setattr(device, k, v)return device上述代码在Devices类中新增了一个类方法,类方法的主要功能就是将kwargs转换为device对象,具体逻辑已通过注释给出。
类方法是用在该方法只与类本身有关联,而与类的实例无关的时候。
通俗的说就是类方法的第一个参数是cls,表示类本身,而实例方法的第一个参数是self表示类的实例;这里的cls和self都可以重命名,并没有强制要求。
关于类方法和实例方法这里不做过多解释,大家可以通过这一章节的示例代码仔细体会,也可以下来自行多做研究。
这里使用了一个Python中的小技巧——列表推导式,其实也可以简单的理解为就是将循环写在了一行里面,比如:
columns = [c.name for c in cls.__table__.columns]
# 等价于
columns = []
for c in cls.__table__.columns:columns.append(c.name)对应的还有字典推导式,在后面的代码中会有示例。
在有了这个类方法后,路由函数就可以大大简化,如下:
@app.route("/cmdb/add", methods=["POST"])
def add():data = request.get_json()device = Devices.to_model(**data)db.session.add(device)db.session.commit()return {"status_code": HTTPStatus.OK}通过Postman发起请求结果如下图:

模型与Python字典转换
既然在增加数据时需要将字典转换成ORM模型,那么在查询数据时同样也需要将ORM模型转换为字典,方便对其进行后续的操作。
新增使用Flask-SQLAlchemy进行查询所有设备记录的路由函数,代码如下:
@app.route("/cmdb/get")
def get():""" 查询CMDB """devices = Devices.query.all()res = []for device in devices:res.append({"id": device.id, "ip": device.ip, "hostname": device.hostname, "idc": device.idc, "row": device.row, "column": device.column, "vendor": device.vendor, "model": device.model, "role": device.role})return jsonify({"status_code": HTTPStatus.OK, "data": res})在查询数据时先通过model.query获取到对数据表的操作句柄,之后再使用额外的查询条件对数据进行过滤查询,上述代码中直接使用了all()方法,来获取数据表的所有记录。
通过ORM模型查询到的记录都是模型的实例对象,而接口返回数据时,无法对实例对象做JSON序列化处理,所以需要将其手动转换为字典后再返回;但上述代码中的转换逻辑过于繁琐,可以通过在ORM模型类中增加一个方法来实现模型对象与Python字典的互相转换,代码如下:
class Devices(db.Model):__tablename__ = 'devices'...def to_dict(self):return {c.name: getattr(self, c.name) for c in self.__table__.columns}上述代码中增加了一个实例方法来实现转换功能,大家可以思考一下为什么模型转字典用的是实例方法,而字典转模型用的是类方法?
这里还用到了前文提到的字典推导式,同样字典推导式也可以理解为将字典的循环代码写到了一行,如下:
{c.name: getattr(self, c.name) for c in self.__table__.columns}
# 等价于
res = {}
for c in self.__table__.columns:res[c.name] = getattr(self, c.name)现在有了模型到字典的转换方法之后,查询的路由函数简化如下:
@app.route("/cmdb/get")
def get():""" 查询CMDB """res = [d.to_dict() for d in Devices.query.all()]return jsonify({"status_code": HTTPStatus.OK, "data": res})通过Postman发起请求结果如下图:

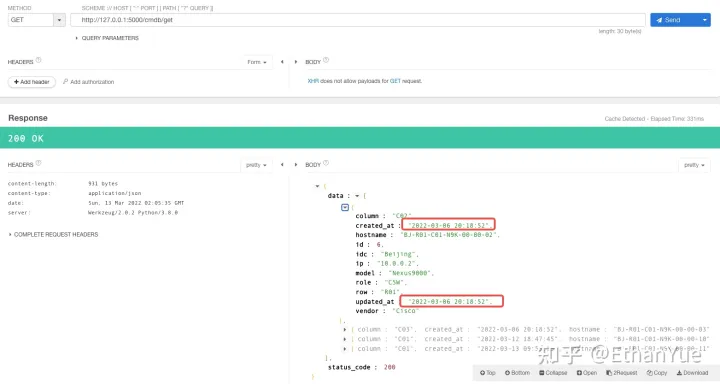
从查询结果可以看出,已经可以顺利查询出所有记录,但红框处的时间却不是比较易读的时间格式,这是因为在进行模型到字典转化的过程中,并没有对时间类型做单独处理,所以现在修改Device.to_dict()方法如下:
from sqlalchemy import DateTime, Numeric
class Device(db.Model):...def to_dict(self):res = {}for col in self.__table__.columns:if isinstance(col.type, DateTime): # 判断类型是否为DateTimeif not getattr(self, col.name): # 判断实例中该字段是否有值value = ""else: # 进行格式转换value = getattr(self, col.name).strftime("%Y-%m-%d %H:%M:%S")elif isinstance(col.type, Numeric): # 判断类型是否为Numericvalue = float(getattr(self, col.name)) # 进行格式转换else: # 剩余的直接取值value = getattr(self, col.name)res[col.name] = valuereturn res修改后,通过Postman发起请求结果如下图:
查询分页
ORM的查询有非常多的过滤方法和功能,文章中无法一一对其进行列举,只列举几个常用的供大家参考,如下:
# 查询所有设备
Devices.query.all()# 查询有多少台设备
Devices.query.count()# 查询第1个设备
Devices.query.first()
Devices.query.get(1) # 根据id查询# 查询id为4的设备[3种方式]
Devices.query.get(4)
Devices.query.filter_by(id=4).all() # 简单查询 使用关键字实参的形式来设置字段名
Devices.query.filter(Devices.id == 4).all() # 复杂查询 使用恒等式等其他形式来设置条件# 查询主机名结尾字符为g的所有设备[开始 / 包含]
Devices.query.filter(Devices.hostname.endswith("g")).all()
Devices.query.filter(Devices.hostname.startswith("w")).all()
Devices.query.filter(Devices.hostname.contains("n")).all()
Devices.query.filter(Devices.hostname.like("%n%g")).all() # 模糊查询# 查询对应厂商和设备类型所有设备
from sqlalchemy import and_
Devices.query.filter(and_(Devices.model == "Cisco", Devices.vendor == "Nexus9000")).all()# 所有设备按id从大到小排序, 取前5个
Devices.query.order_by(Devices.id.desc()).limit(5).all()# 分页查询, 查询第2页的数据, 每页10个,
pn = Devices.query.paginate(2, 10)
# pn.items 获取该页的数据 pn.total 获取总共有多少条数据# 动态条件查询
filters = {Devices.id >=15, Device.hostname!=''} 可以在filters中添加或减少条件
Devices.query.filter(*filters).all()删除和修改
删除和修改的功能相对来说较为简单,无非是在进行操作之前先通过查询条件将数据过滤出来,然后再进行删除或修改操作,具体实现大家可以看完整重构后的代码。
完整代码
import os
import time
from http import HTTPStatus
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import text, DateTime, Numericapp = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = "mysql+pymysql://root:root@127.0.0.1:3306/ops?charset=utf8"
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)class Devices(db.Model):__tablename__ = 'devices'id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment="自增主键")ip = db.Column(db.String(16), nullable=False, comment="IP地址")hostname = db.Column(db.String(128), nullable=False, comment="主机名")idc = db.Column(db.String(32), comment="机房")row = db.Column(db.String(8), comment="机柜行")column = db.Column(db.String(8), comment="机柜列")vendor = db.Column(db.String(16), comment="厂商")model = db.Column(db.String(16), comment="型号")role = db.Column(db.String(8), comment="角色")created_at = db.Column(db.DateTime(), nullable=False, server_default=text('NOW()'), comment="创建时间")updated_at = db.Column(db.DateTime(), nullable=False, server_default=text('NOW()'), server_onupdate=text('NOW()'), comment="修改时间")def to_dict(self):res = {}for col in self.__table__.columns:if isinstance(col.type, DateTime):if not getattr(self, col.name):value = ""else:value = getattr(self, col.name).strftime("%Y-%m-%d %H:%M:%S")elif isinstance(col.type, Numeric):value = float(getattr(self, col.name))else:value = getattr(self, col.name)res[col.name] = valuereturn res@classmethoddef to_model(cls, **kwargs):device = Devices()columns = [c.name for c in cls.__table__.columns]for k, v in kwargs.items():if k in columns:setattr(device, k, v)return device@app.route("/cmdb/get")
def get():""" 查询CMDB """page_size = request.args.get("pageSize", 10)page = request.args.get("page", 1)devices = Devices.query.paginate(page, page_size)res = [d.to_dict() for d in devices.items]return jsonify({"status_code": HTTPStatus.OK, "data": res, "total": devices.total})@app.route("/cmdb/add", methods=["POST"])
def add():data = request.get_json()device = Devices.to_model(**data)db.session.add(device)db.session.commit()return jsonify({"status_code": HTTPStatus.OK, "data": device.to_dict()})@app.route("/cmdb/update", methods=["POST"])
def update():data = request.get_json()Devices.query.filter_by(id=data.pop("id")).update(data)db.session.commit()return jsonify({"status_code": HTTPStatus.OK})@app.route("/cmdb/delete", methods=["POST"])
def delete():data = request.get_json()Devices.query.filter_by(id=data.get("id")).delete()db.session.commit()return jsonify({"status_code": HTTPStatus.OK})if __name__ == "__main__":app.run(host="127.0.0.1", port=5000, debug=True)【总结】
目前为止,已经对ORM框架有了初步的认识,并且在我们的后端应用中集成了Flask-SQLAlchemy插件,完成了资产数据增删改查的改造,重构过程中也涉及到了一些Python进阶的知识点,希望大家可以在阅读的过程中仔细体会。
这次只是一个基本的重构,关于路由函数接收的参数和异常的处理也并没有做到很完善,大家可以先自己尝试修改,在下一章节中,我会新增一个端口表,来丰富资产数据,并且讲解ORM的关联查询,同时给出更为完善的代码。