为什么需要Spark Event Log?
我们都知道Spark启动后会启动Spark UI,这个Spark UI可以帮助我们监控应用程序的状态。但是如果Spark应用跑完了,Spark UI就无法查看,如果Spark在执行过程中出了问题,我们没有办法去快速查找出问题的原因,所以我们需要把Spark Event持久化到磁盘,然后通过Spark History Server去读取Spark Event Log就可以重现运行时情况,可以快速的帮助我们分析问题。
为什么要解析(读取)EventLog日志文件?
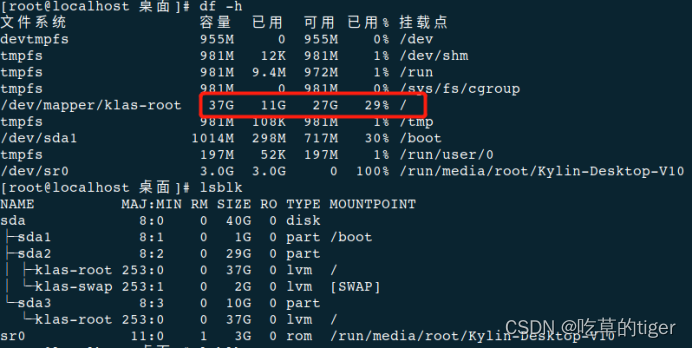
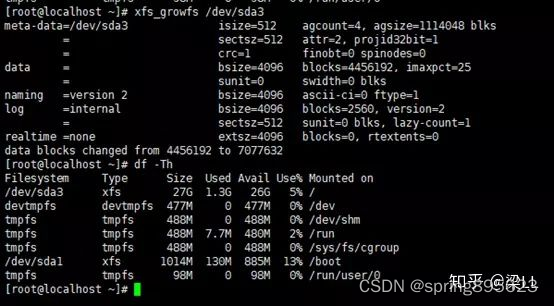
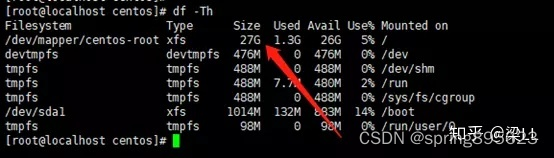
通常我们通过Spark History Server WEB UI查看已经结束的Spark作业日志,但是有时候作业生成的EventLog 文件非常大,几G甚至几十G,导致Spark History Server无法解析展示,最近就发现在生产环境中生成了一个达27G的eventlog文件。经过在网上搜索找到了如下的解析读取办法。
编写Spark代码解析EventLog文件
一般为减少磁盘空间占用,eventlog一般以lz4格式压缩存储,本文提供的方法也是读取这种格式文件,因为非压缩格式文件可以直接查看。
import java.io.{FileInputStream, FileOutputStream}
import org.apache.commons.io.IOUtils
import org.apache.spark.io.LZ4CompressionCodecval inFile = "local_lz4_event_log_file_path"
val outFile = "resolved_event_log_file_path"
val codec = new LZ4CompressionCodec(sc.getConf)
val is = codec.compressedInputStream(new FileInputStream(inFile))
val os = new FileOutputStream(outFile)
IOUtils.copyLarge(is,os)
os.close()
is.close()