文章目录
- 多处理器
- 单指令单数据流SISD结构
- 单指令流多数据流SIMD结构
- 向量处理器
- 多指令流单数据流MISD结构
- 多指令多数据流MIMD结构
- 小结
- 硬件多线程
- 细粒度多线程
- 粗粒度多线程
- 同时多线程
- 多核处理器
- 共享内存多处理器
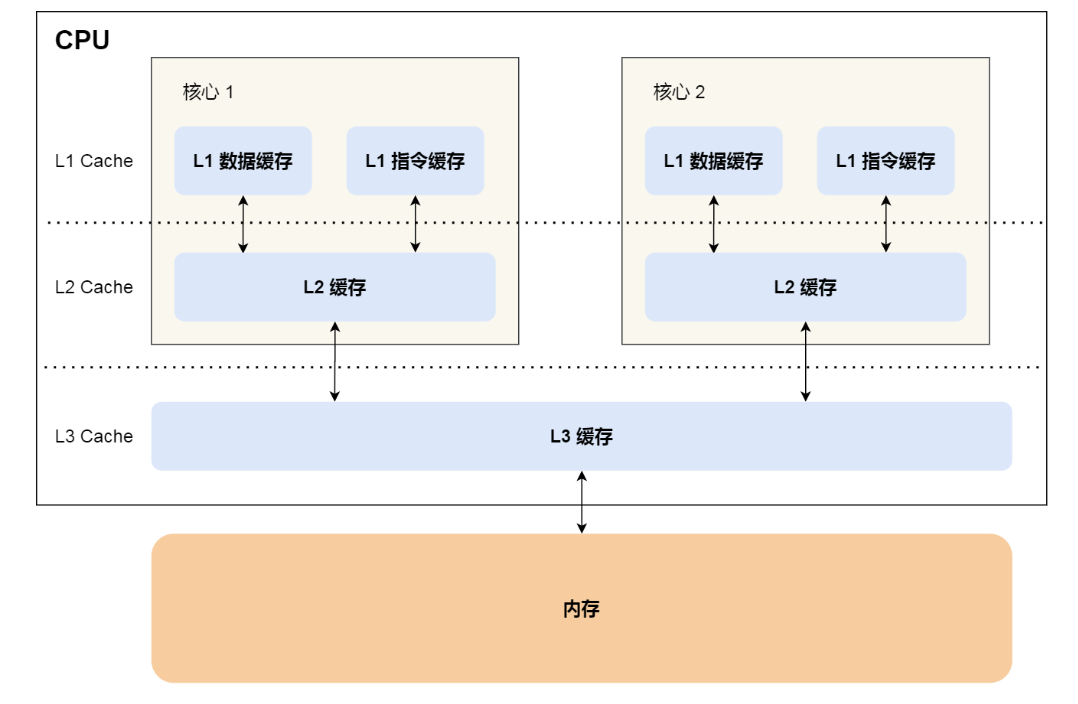
多处理器
- 常规的单处理器属于SISD
- 常规多处理器属于MIMD
单指令单数据流SISD结构
- SingleInstructionSingleData
- SISD是传统的串行计算机结构
- 这种计算机仅包含一个处理器和一个存储器
- 存储器在一段时间内仅执行一条指令
- 按指令流规定的顺序,串行执行指令流中的若干条指令
- 提高速度
- 采用流水线方式执行指令
- SISD处理器有时会设置多个功能部件,采用多模块交叉方式组织存储器
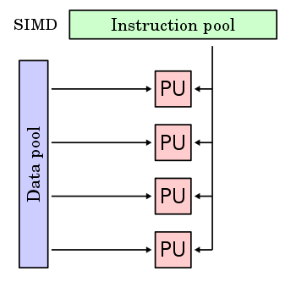
单指令流多数据流SIMD结构
-
singleInstructionMultipleData
- Single instruction, multiple data - Wikipedia
-
SIMD是指,一个指令流同时对多个数据流进行处理,一般称为**数据级并行技术**
-
这种结构的计算机通常有
- 一个指令控制部件
- 多个处理单元
-
每个处理单元执行的是同一条指令
-
但是每个单元都有自己的地址寄存器,(每个单元都有不同的数据地址)
-
也就是,不同的处理单元执行的同一条指令所处理的数据是不同的
-
一个顺序应用程序被编译后
- 可能按照SISD组织,运行在串行硬件上
- 也可能按SIMD组织,运行在并行硬件上
-
SIMD对于for循环处理最为有效
- 比如执行整形数组((16个元素)的各个元素倍乘运算,那么如果有16个ALU,那么可以在只需要计算一次的时间就可以完成16个元素的计算
- 如果是串行计算,则需要耗费16次计算的时间(16倍)
-
SIMD对于switch-case语句效率低
- 妹纸执行单元必须根据不同的数据执行不同的操作
向量处理器
- 向量处理器(VPU:Vector Processor)
- 是SIMD的变体,是一种实现了直接操作 一维数组(一维向量) 指令集的cpu
- 串行处理器则只能够处理单一数据集
- 把从存储器中收集的一组数据按照顺序放到一组向量寄存器中,然后以流水化的方式对它们依次操作
- 最后将结果协会寄存器
- VPU在特定工作环境中极大提升性能(比如数值模拟)
- 是SIMD的变体,是一种实现了直接操作 一维数组(一维向量) 指令集的cpu
多指令流单数据流MISD结构
- multipleInstructionInstructionData
- 同时执行多条指令处理同一个数据
- 不存在这类计算机
多指令多数据流MIMD结构
- multpleInstructionMultipleData
- 同时执行多条指令分别处理多个不同数据
- MIMD分为多计算机系统和多处理器系统
- 多计算机系统每个计算机结点都具有各自的存储器
- 并且具有独立的主存空间地址
- 不能够通过存取指令来访问不同结点的私有存储器
- 而要通过消息传递进行数据传送(称为消息传递MIMD)
- 多处理器系统是共享存储器多处理器(SMP)
- 对称多处理(Symmetrical Multi-Processing);
- 对称多处理器(Symmetric Multi-Processor)
- 它具有共享的单一地址空间
- 通过存取指令来访问系统中的所有存储器;也称为共享存储MIMD
小结
- SIMD和MIMD是两种并行计算机模式
- SIMD是一种数据级的并行模式
- MIMD是并行程度更高的线程级或以上的并行计算模式
硬件多线程
- 线程切换包含一些列开销
- 为了减少线程切换中的开销,发展除了硬件多线程
- 支持硬件多线程的cpu必须为每个线程提供单独的
- 通用寄存器组GPRs
- 程序计数器PC
- …
- 线程切换只需要激活选中的寄存器,省略了与存储器数据交换的环节,减少了线程切换的开销
细粒度多线程
- 多个线程之间轮流交叉执行
- 多个线程之间的指令是不相关的
- 可以乱序并行执行
- 处理器可以在每个时钟周期切换线程
粗粒度多线程
- 仅在一个线程出现(较大开销的)阻塞时,才切换进程
- 比如CacheMissing
- 当指令流水发生阻塞时,必须清除被阻塞的指令流水线
- 新线程的指令开始执行前需要重载流水线
- 因此,开销较大
同时多线程
- 同时多线程(SMT)
- Simultaneous MultiThreading,SMT
- 在实现指令级并行的同时,还实现线程级并行
- 在同一个时钟周期内,发射多个不同线程中的多条指令执行
- 例如:Intel处理器中的超线程(HyperThreading)
- 在一个处理器(或者单个核心)中设置了两套线程状态部件,共享告诉缓存和功能部件
多核处理器
- 将多个处理单元继承到单个cpu中
- 每个处理单元称为核(core)
- 所有的核可能是对称的,也可能是大小核
- 多个核,可以共享cache,也可以由独立的cache
- 但是都共享主存储器
- 必须采用多线程(多进程)方式执行,才能发挥多核的最大性能
- 同一个时每个核都有线程在运行
- 多核处理器可以实现真正物理意义上的并行执行
- 同一个时刻可能有多个线程同时执行
- 单核处理器只能够交错执行多线程/进程
- 同一时刻只要一个线程在执行,其他一个线程别暂停执行
共享内存多处理器
-
共享单一物理地址空间的多处理器被称为:共享内存多处理器(SMP)
-
虽然所有处理器都能够通过存取指令访问任何存储器的位置(共享物理地址空间)
- SMP通过存储器中的共享变量进行通信
- 但是多处理器仍然可以在自己的虚拟地址空间中单独运行程序
-
SMP
- UMA
- 同一存储访问多处理器
- 内存控制器在cpu外部
- 每个处理器对所有存储单元的访问时间大致相同
- 访问时间与处理器提出访问请求和访问的存储字无关
- NUMA
- 非同一存储访问多处理器
- 主存被分割并分配个了同一个机器的不同处理器或者内存控制器
- 进一步分为:
- NC-NUMA
- 处理器中不带有cache
- CC-NUMA
- 处理器中带有cache
- NC-NUMA
- NUMA是UMA的发展
- 内存控制器被集成到了cpu内部
- 解决多cpu对前端总线的争用导致的性能瓶颈
- 内地内存
- 每个cpu都有独立的内存控制器
- 每个CPU都独立链接到一部分内存,这部分内存称为本地内存
- 远程内存
- 非本地内存称为远程内存
- 访问速度慢于本地内存
- cpu之间则通过QPI总线向量
- UMA