Apache APISIX 介绍
什么是Apache APISIX
Apache APISIX 是一个动态、实时、高性能的云原生 API 网关,提供了负载均 衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功 能。可以使用 Apache APISIX 处理传统的南北向流量,也可以处理服务间的东 西向流量。同时,它也支持作为 K8s Ingress Controller 来使用。
APISIX特征
| 产品 | APISIX | Kong | Nginx |
| 集群部署 | 支持 | 支持 | 不支持 |
| 数据存储 | Etcd | PostgreSQL或Cassandra | 不支持 |
| 热加载 | 支持 | 支持 | 不支持 |
| 插件 | 多语言 | moudle | |
| 动态路由 | 支持 | 支持 | 不支持 |
| 健康检查和熔断 | 支持 | 支持 | 不支持 |
- 多平台支持:APISIX 提供了多平台解决方案,它不但支持裸机运行, 也支持在 Kubernetes 中使用,还支持与 AWS Lambda、Azure Function、Lua 函数和 Apache OpenWhisk 等云服务集成。
- 全动态能力:APISIX 支持热加载,这意味着你不需要重启服务就可以 更新 APISIX 的配置。 精细化路由:APISIX 支持使用 NGINX 内置变量做为路由的匹配条 件,你可以自定义匹配函数来过滤请求,匹配路由。
- 运维友好:APISIX 支持与以下工具和平台集成:HashiCorp Vault、 Zipkin、Apache SkyWalking、Consul、Nacos、Eureka。通过 APISIX Dashboard,运维人员可以通过友好且直观的 UI 配置 APISIX。
- 多语言插件支持:APISIX 支持多种开发语言进行插件开发,开发人员 可以选择擅长语言的 SDK 开发自定义插件。
软件架构
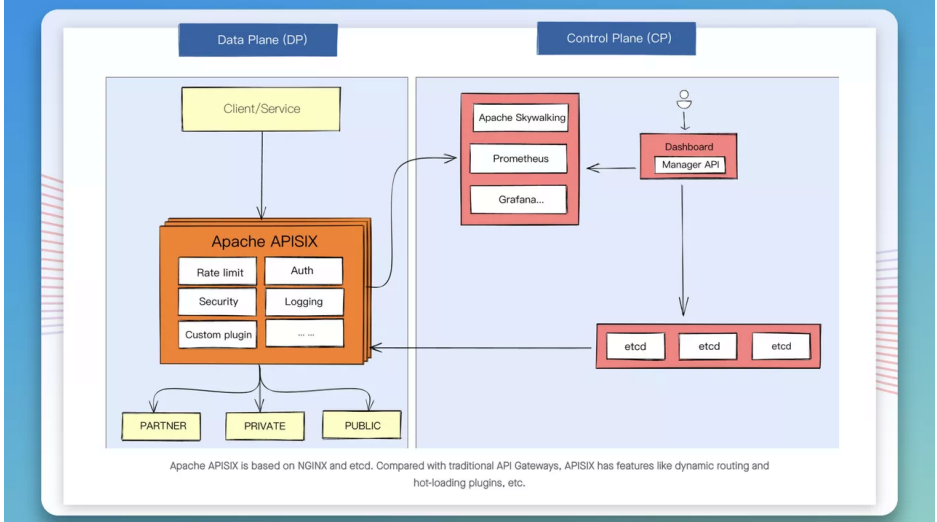
APISIX 的架构主要分成两部分:
- 第一部分叫做数据面,它是真正去处理来自客户端请求的一个组件,去处理用户 的真实流量,包括像身份验证、证书卸载、日志分析和可观测性等功能。数据面 本身并不会存储任何数据,所以它是一个无状态结构。
- 第二部分叫做控制面。APISIX 在底层架构上和其它 API 网关的一个很大不同就 在于控制面。APISIX 在控制面上并没有使用传统的类似于像 MySQL 去做配置 存储,而是选择使用 etcd。
APISIX 技术优势
无数据库依赖
APISIX 在设计之初,就从底层架构上避免了宕机、丢失数据等情况的发生。因 为在控制面上,APISIX 使用了 etcd 存储配置信息,而不是使用关系型数据 库,这样做的好处主要有以下几点:
- 与产品架构的云原生技术体系更统一;
- 更贴合 API 网关存放的数据类型;
- 能更好地体现高可用特性;
- 拥有低于毫秒级别的变化通知。
使用 etcd 存储配置信息后,对于数据面而言只需监听 etcd 的变化即可。如果 采用轮询数据库的方式,可能需要 5-10 秒才能获取到最新的配置信息;如果监 听 etcd 的配置信息变更,APISIX 就可以将获取最新配置的时间控制在毫秒级 别之内,达到实时生效。
插件热加载
APISIX 和 NGINX 相比,有两处非常大的变化:APISIX 支持集群管理和动态加 载。
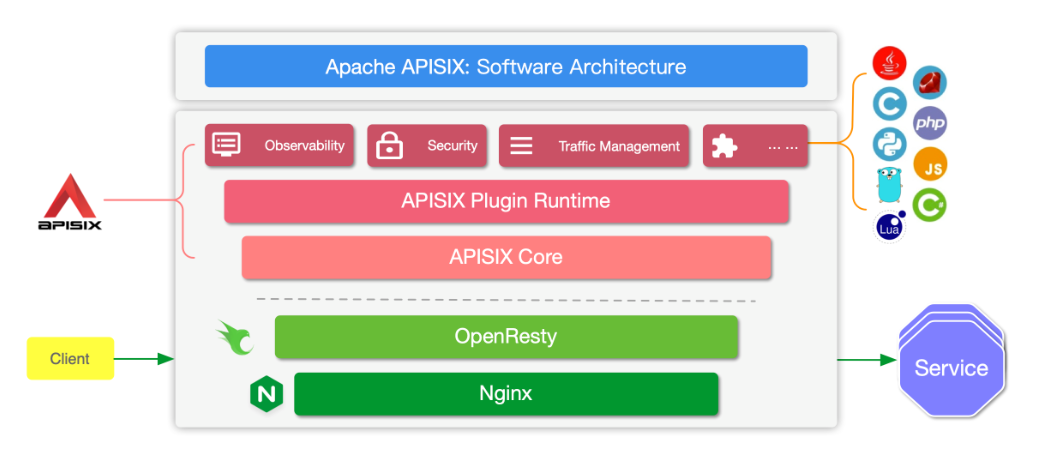
之所以 APISIX 能摆脱 NGINX 的限制是因为它把上 游等配置全部放到 APISIX Core 和 Plugin Runtime 中动态指定。 以路由为例,NGINX 需要在配置文件内进行配置,每次更改都需要 reload 之 后才能生效。而为了实现路由动态配置,Apache APISIX 在 NGINX 配置文件 内配置了单个 server,这个 server 中只有一个 location。我们把这个 location 作为主入口,所有的请求都会经过这个 location,再由 APISIX Core 动态指定 具体上游。因此 Apache APISIX 的路由模块支持在运行时增减、修改和删除路 由,实现了动态加载。所有的这些变化,对客户端都零感知,没有任何影响。 比如增加某个新域名的反向代理,在 APISIX 中只需创建上游,并添加新的路由 即可,整个过程中不需要 NGINX 进程有任何重启。再比如插件系统,APISIX 可以通过 ip-restriction 插件实现 IP 黑白名单功能,这些能力的更新也是动态 方式,同样不需要重启服务。借助架构内的 etcd,配置策略以增量方式实时推 送,最终让所有规则实时、动态的生效,为用户带来极致体验。
高性能路由匹配算法
API 网关需要从每个请求的 Host、URI、HTTP 方法等特征中匹配到目标规则,以决定如何对该请求进行处理,因此一个优秀的匹配算法是必不可少的。Hash 算法性能不错,但无法实现模糊匹配;正则可以模糊匹配,但性能不好,因此 Apache APISIX 选择使用树这样一种高效且支持模糊匹配的搜索数据结构。准确一些,Apache APISIX 使用的是 RadixTree,它提供了 KV 存储查找的数据结构并对只有一个子节点的中间节点进行了压缩,因此它又被称为压缩前缀树。此外,在已知 API 网关产品中 Apache APISIX 首次将 RadixTree 应用到了路由匹配中,支持一个前缀下有多个不同路由的场景,具体实现见 lua-``resty-radixtree。
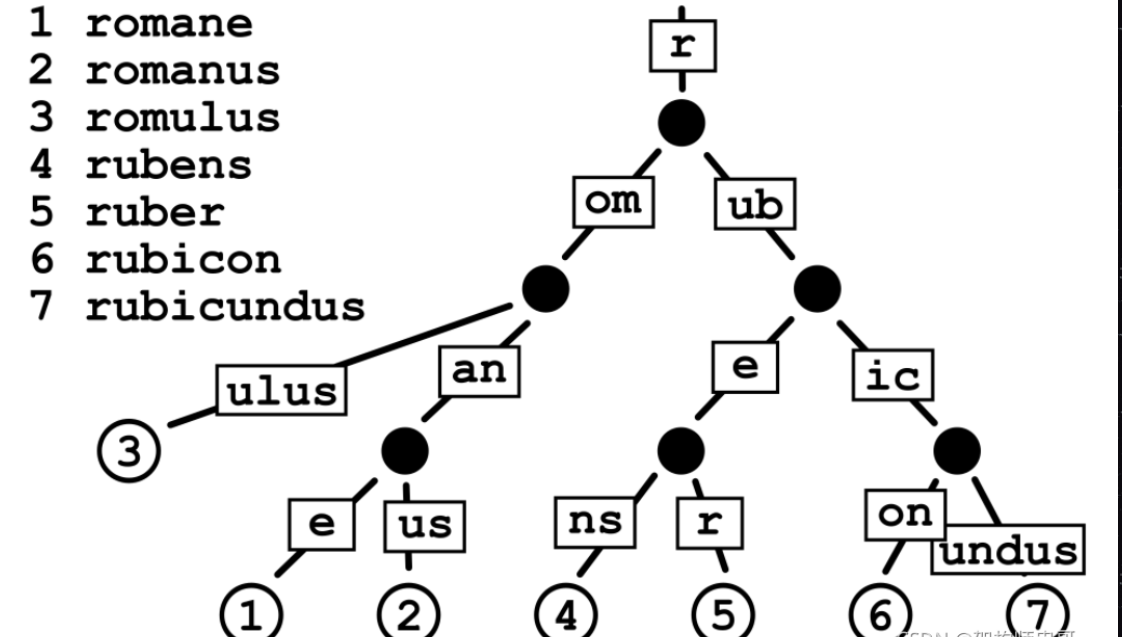
当对某个请求进行匹配时,RadixTree 将采用层层递进的方式进行匹配,其复杂度为 O(K)(K 是路由中 URI 的长度,与 API 数量多少无关),该算法非常适合公有云、CDN以及路由数量比较多的场景,可以很好地满足路由数量快速增长的需求。
高性能 IP 匹配算法
IP 地址有 2 种记法:标准 IP 表示方法与 CIDR 表示方法,以 32 位的 IPv4 为例:
- 标准 IP 记法:192.168.1.1
- CIDR 记法:192.168.1.1/8
Apache APISIX 的 IP 匹配算法与路由匹配算法所使用的原理以及原始数据是不一样的。以 192.168.1.1 这个 IP 为例,由于每个 IP 段的范围是 0 到 255,因此在对 IP 进行匹配时我们可以认为 IP 地址是由 4 个 16 位整数型的数构成的,IP 长度是固定的。那么我们可以采用更高效的算法完成匹配。
假设现在有一个包含 500 条 IPv4 记录的 IP 库,APISIX 会将 500 条 IPv4 的记 录缓存在 Hash 表中,当进行 IP 匹配时使用 Hash 的方式进行查找,时间复杂 度为 O(1)。 而其他 API 网关则是通过遍历的方式完成 IP 匹配,发送到网关每个请求将逐个 遍历最多 500 次是否相等后才能知道计算结果。所以 APISIX 的高精度 IP 匹配 算法大大提高了需要进行海量 IP 黑白名单匹配场景的效率。
精细化路由
首先,Apache APISIX 支持 NGINX 内置变量,意味着我们可以将诸如 uri、 server_name、server_addr、request_uri、remote_port、remote_addr、 query_string、host、hostname、hostname、arg_name 等数十种 NGINX 内置变量作 为匹配参数,以支持更复杂多变的匹配场景。
其次,Apache APISIX 支持将条件表达式作为匹配规则,其结构是 [var, operator, val], …]],其中: var 值可使用 NGINX 内置变量; operator 支持相等、不等、大于、小于、正则、包含等操作符。 假设表达式为 [“arg_name”, “==”, “fox”] ,它意味着当前请求的 URI 查询参数 中,是否有一个为 name 的参数值等于 fox。
此外,Apache APISIX 支持设置路由 ttl 存活时间;
curl http://127.0.0.1:9080/apisix/admin/routes/2?ttl=60 \‐H 'X‐API‐KEY: edd1c9f034335f136f87ad84b625c8f1' ‐X PUT ‐i ‐d '{"uri": "/aa/index.html","upstream": {"type": "roundrobin","nodes": {"39.97.63.215:80": 1}}}'
Apache APISIX 支持自定义过滤函数,你可以通过在 filter_func 参 数中编写自定义 Lua 函数。
curl http://127.0.0.1:9080/apisix/admin/routes/1 \‐H 'X‐API‐KEY: edd1c9f034335f136f87ad84b625c8f1' ‐X PUT ‐i ‐d '{"uri": "/index.html","hosts": ["foo.com", "*.bar.com"],"filter_func": "function(vars)return vars['host'] == 'api7.ai'end","upstream": {"type": "roundrobin","nodes": {"127.0.0.1:1980": 1}}}'
支持多语言插件
APISIX 目前已经支持了 80 多种插件。在实际使用场景中,很多企业都会针对具体业务进行定制化的插件开发,通过网 关去集成更多的协议或者系统,最终在网关层实现统一管理。 在 APISIX 早期版本中,开发者仅能使用 Lua 语言开发插件。虽然通过原生计算 语言开发的插件具备非常高的性能,但是学习 Lua 这门新的开发语言是需要时 间和理解成本的。 针对这种情况,APISIX 提供了两种方式来解决:
第一种方式是通过 Plugin Runner 来支持更多的主流编程语言(比如 Java、 Python、Go 等等)。通过这样的方式,可以让后端工程师通过本地 RPC 通 信,使用熟悉的编程语言开发 APISIX 的插件。 这样做的好处是减少了开发成本,提高了开发效率,但是在性能上会有一些损 失。那么,有没有一种既能达到 Lua 原生性能,同时又兼顾高级编程语言的开 发效率方案呢?
第二种方式是使用 Wasm 开发插件,也就是上图左侧部分。 Wasm(WebAssembly)最早是用在前端和浏览器上的一个技术,但是现在在 服务端它也逐渐展示出来它的优势。我们将 Wasm 嵌入到了 APISIX 中,用户 就可以使用 Wasm 去编译成 Wasm 的字节码在 APISIX 中运行。最终达到的效 果就是利用高效率,开发出了一个既有高性能又使用高级计算语言编写的 APISIX 插件。 因此,在当前 APISIX 版本中,用户可以使用 Lua、Go、Python 和 Wasm 等 多种方式,基于 APISIX 编写自定义插件。通过这样的方式,降低了开发者的使 用门槛,也为 APISIX 的功能提供了更多的可能性。

Apache APISIX 入门
- 上游
Upstream 是虚拟主机抽象,对给定的多个服务节点按照配置规则进行负载均衡。Upstream 的地址信息可以直接配置到 Route(或 Service) 上,当 Upstream 有重复时,需要用“引用”方式避免重复。
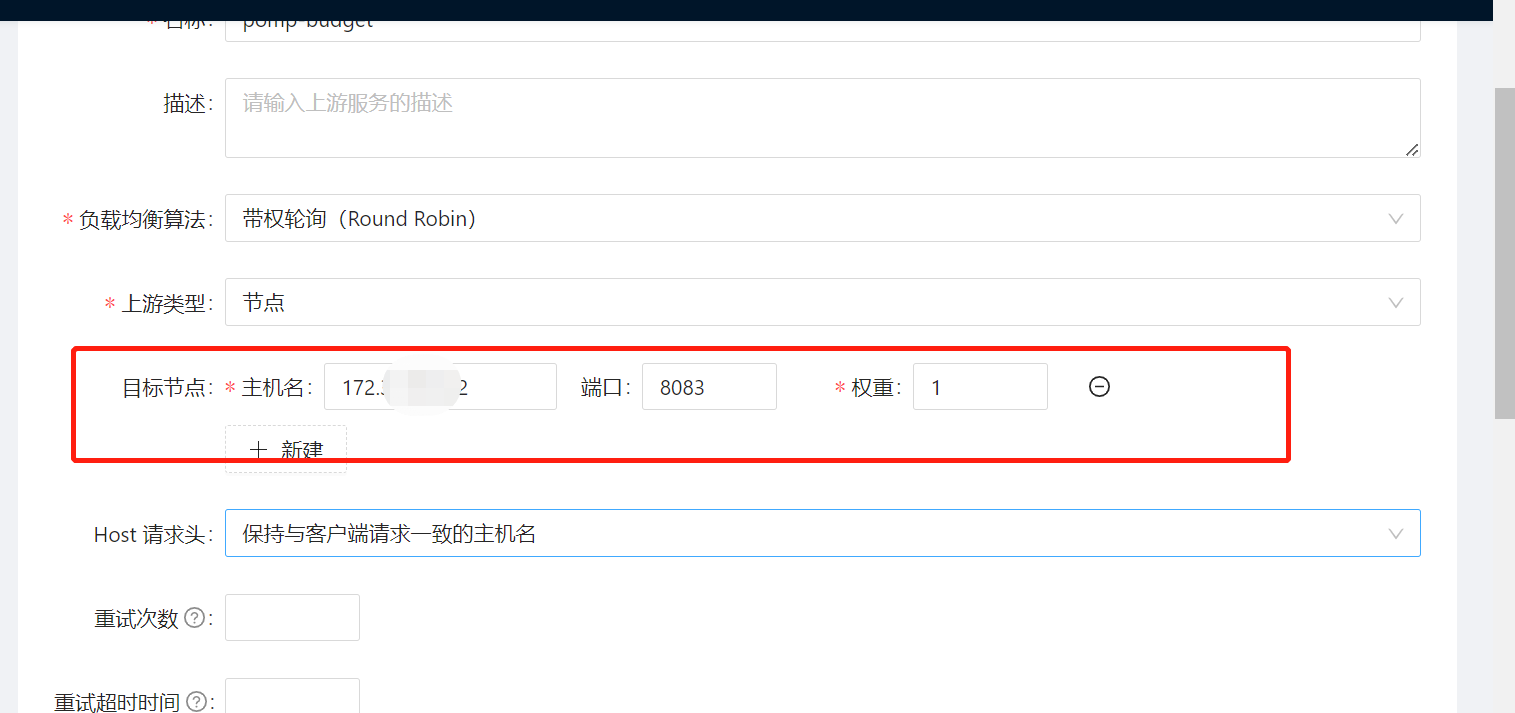
- 路由
Route 也称之为路由,可以通过定义一些规则来匹配客户端的请求,然后根据匹配结果加载并执行相应的插件,并把请求转发给到指定 Upstream(上游)。

- 服务
Service 是某类 API 的抽象(也可以理解为一组 Route 的抽象)。它通常与上游服务抽象是一一对应的,Route 与 Service 之间,通常是 N:1 的关系。
- 消费者
Consumer 是某类服务的消费者,需要与用户认证体系配合才能使用。Consumer 使用 username 作为唯一标识,仅支持使用 HTTP PUT 方法创建 Consumer。
Apache APISXI 实战
基于Nacos服务发现
注册中心本质上是为了解耦服务提供者和服务消费者,在微服务体系中,各个业务服务之间 会频繁互相调用,并且需要对各个服务的 IP、port 等路由信息进行统一的管理。 注册中心的核心功能为以下三点:
-
服务注册:服务提供方向注册中心进行注册。
-
服务发现:服务消费方可以通过注册中心寻找到服务提供方的调用路由信息。
-
健康检测:确保注册到注册中心的服务节点是可以被正常调用的,避免无效节点 导致的调用资源浪费等问题。
Apache APISIX + Nacos 可以将各个微服务节点中与业务无关的各项控制,集中在 Apache APISIX 中进行统一管理,即通过 Apache APISIX 实现接口服务的代理和路由转发 的能力。在 Nacos 上注册各个微服务后,Apache APISIX 可以通过 Nacos 的服务发现功 能获取服务列表,查找对应的服务地址从而实现动态代理。
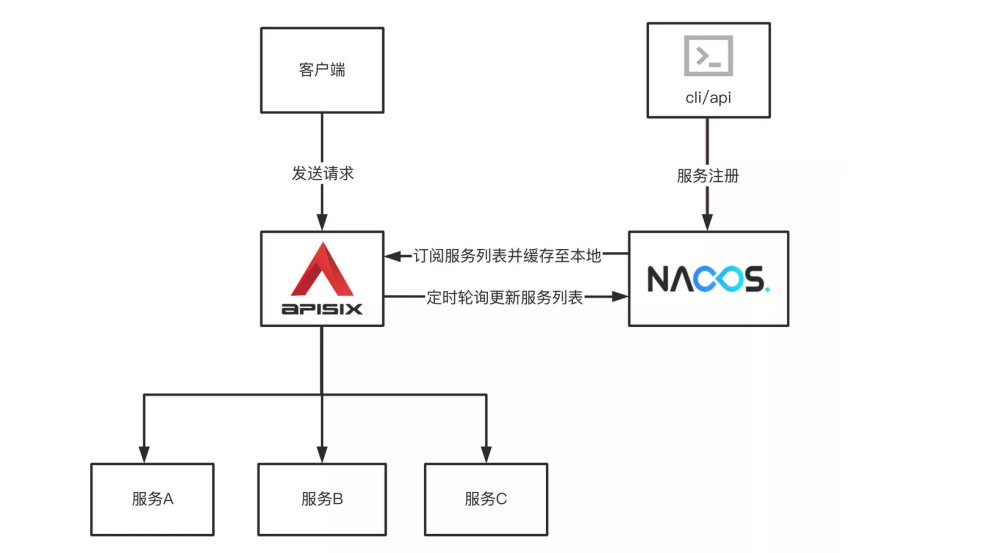
在文件 conf/config.yaml 中添加以下配置到:
discovery:nacos:host:- "http://127.0.0.1:8848"
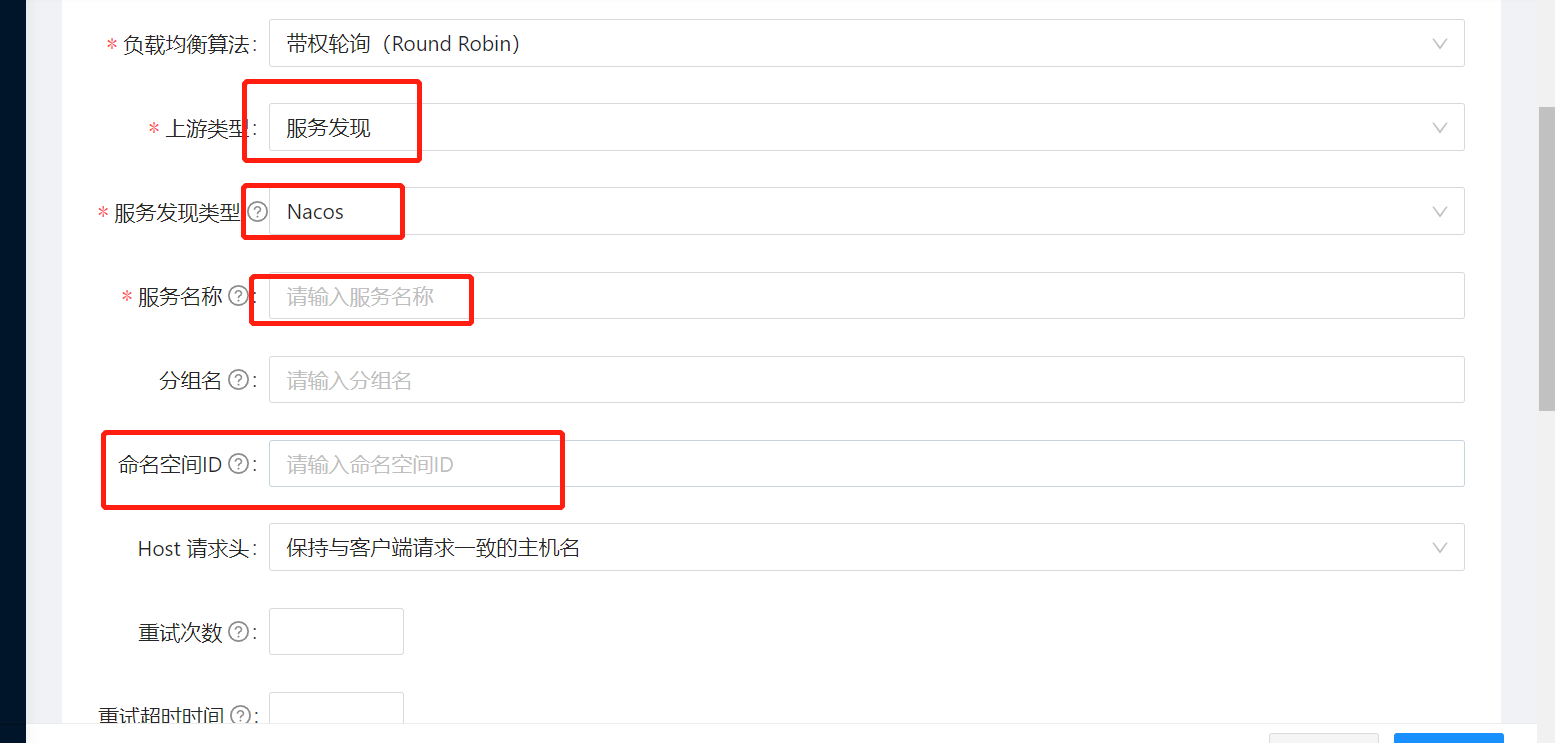
创建路由或者上游的时候选择服务发现:
Java Plugin Runner插件
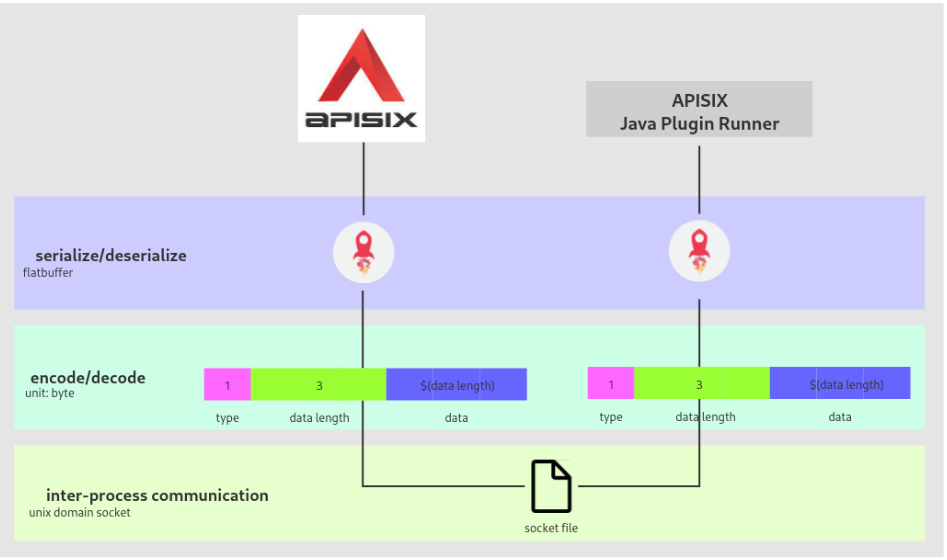
{"conf": [{"name": "TokenValidator","value": "{\"loginUserSign\":\"user\",\"rejected_code\":\"A0400\",\"validate_url\":\"http://172.31.114.74:8080/restapi/cs/v1/sso/userLoginState\"}"}],"disable": false
}
@Component
@Slf4j
public class TokenValidator implements PluginFilter {public static final String ACCOUNT_NAME = "accountName";@Autowiredprivate Auth auth;@Overridepublic String name() {return "TokenValidator";}@Overridepublic void filter(HttpRequest request, HttpResponse response, PluginFilterChain chain) {// get APISIX configString configStr = request.getConfig(this);Gson gson = new Gson();Map<String, Object> config = new HashMap<>();config = gson.fromJson(configStr, config.getClass());// get request pathString path = request.getPath();log.info("TokenValidator filter path:{}", path);Map<String, String> headers = request.getHeaders();// get custom parametersString loginUserSign = (String) config.get("loginUserSign");String rejectedCode = (String) config.get("rejectedCode");log.debug("get headers :{}", headers);String headerToken = request.getHeader(loginUserSign);// filter white path listif (permitAll(headerToken)) {request.setHeader(ACCOUNT_NAME, "APISIX");chain.filter(request, response);return;}responseWriter(response,rejectedCode);chain.filter(request, response);}private boolean permitAll(String token) {if(Objects.equals("ssk",token)){return true;}return auth.validator(token);}private void responseWriter(HttpResponse response, String rejectedCode) {String sb = "{\"msg\":\"" +"The user is not login\"," +"\"code\":\"" +rejectedCode +"\"}";response.setStatusCode(200);response.setBody(sb);}
灰度发布
泳道:为相同版本应用定义的一套隔离环境。只有满足了流控路由规则的请求流量才会路由到对应泳道里的打标应用。一个应用可以属于多个泳道,一个泳道可以包含多个应用,应用和泳道是多对多的关系。
基线环境:未打标的应用属于基线稳定版本的应用,即稳定的线上环境。
流量回退:泳道中所部署的服务数量并非要求与基线环境完全一致,当泳道中并不存在调用链中所依赖的其他服务时,流量需要回退至基线环境,进一步在必要的时候路由回对应标签的泳道。
泳道组:泳道的集合。泳道组的作用主要是为了区分不同团队或不同场景。

创建路由绑定灰度标识
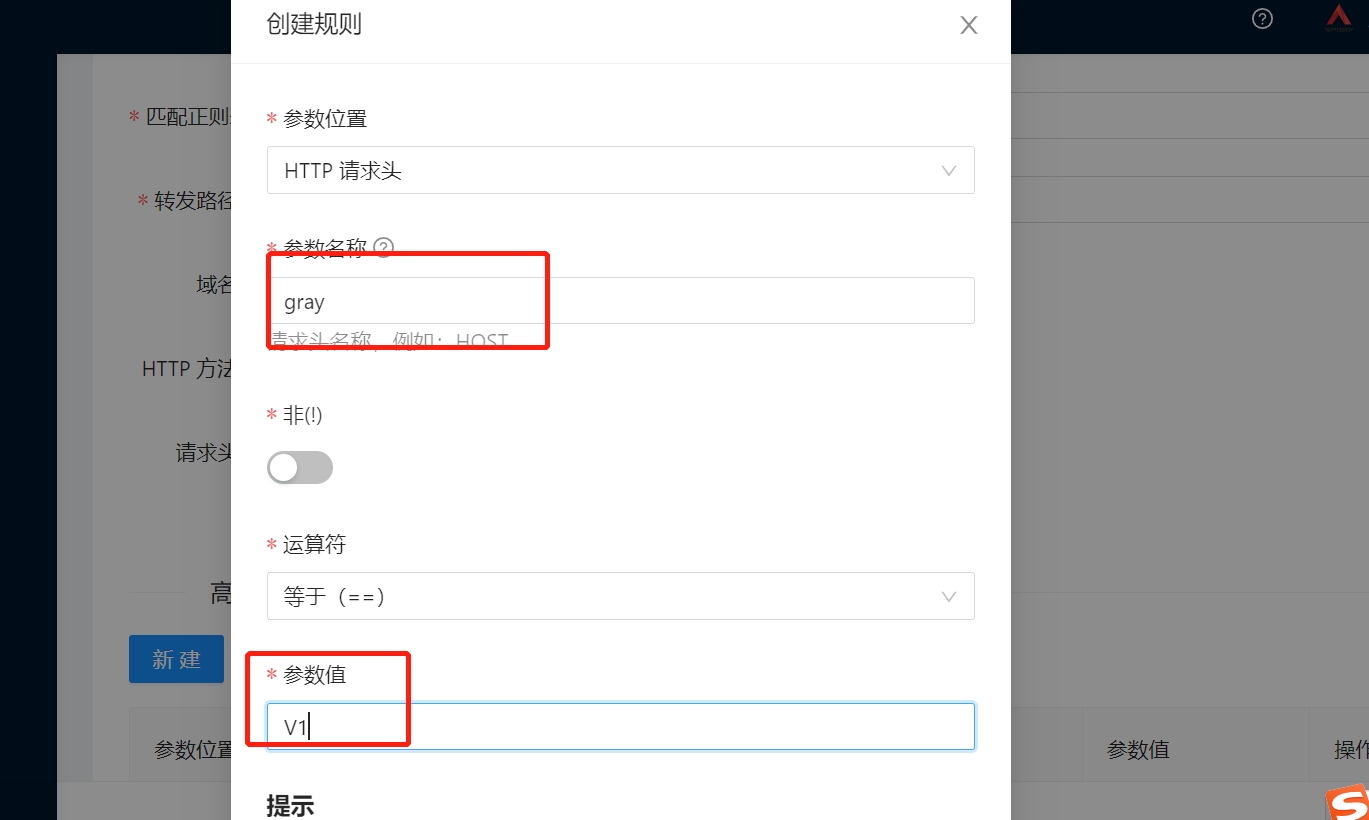
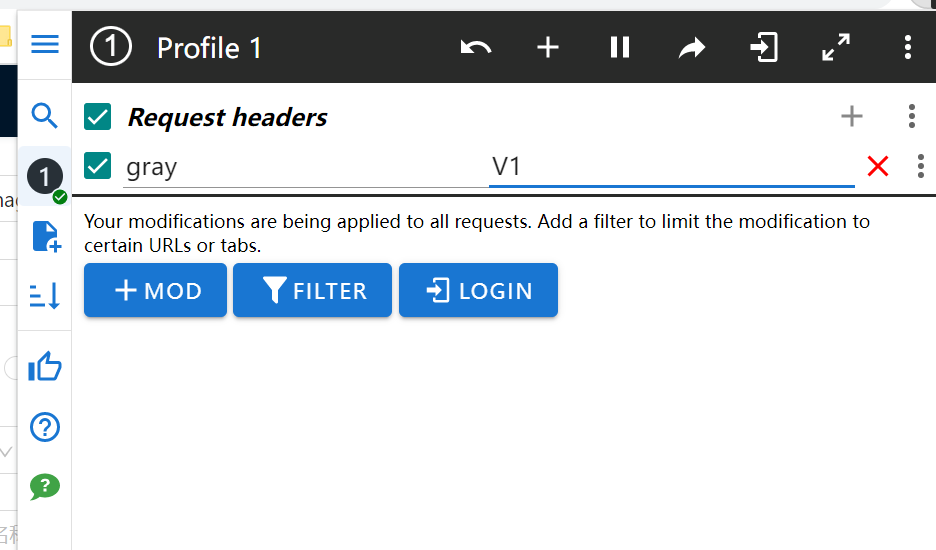
安装chrom浏览器modheader插件,在发起请求时添加灰度标识
退:泳道中所部署的服务数量并非要求与基线环境完全一致,当泳道中并不存在调用链中所依赖的其他服务时,流量需要回退至基线环境,进一步在必要的时候路由回对应标签的泳道。
泳道组:泳道的集合。泳道组的作用主要是为了区分不同团队或不同场景。
![[外链图片转存中...(img-5fFbY4SK-1686038583822)]](https://img-blog.csdnimg.cn/eafe001c39c84774bad89315d9c3aeb0.png)
创建路由绑定灰度标识
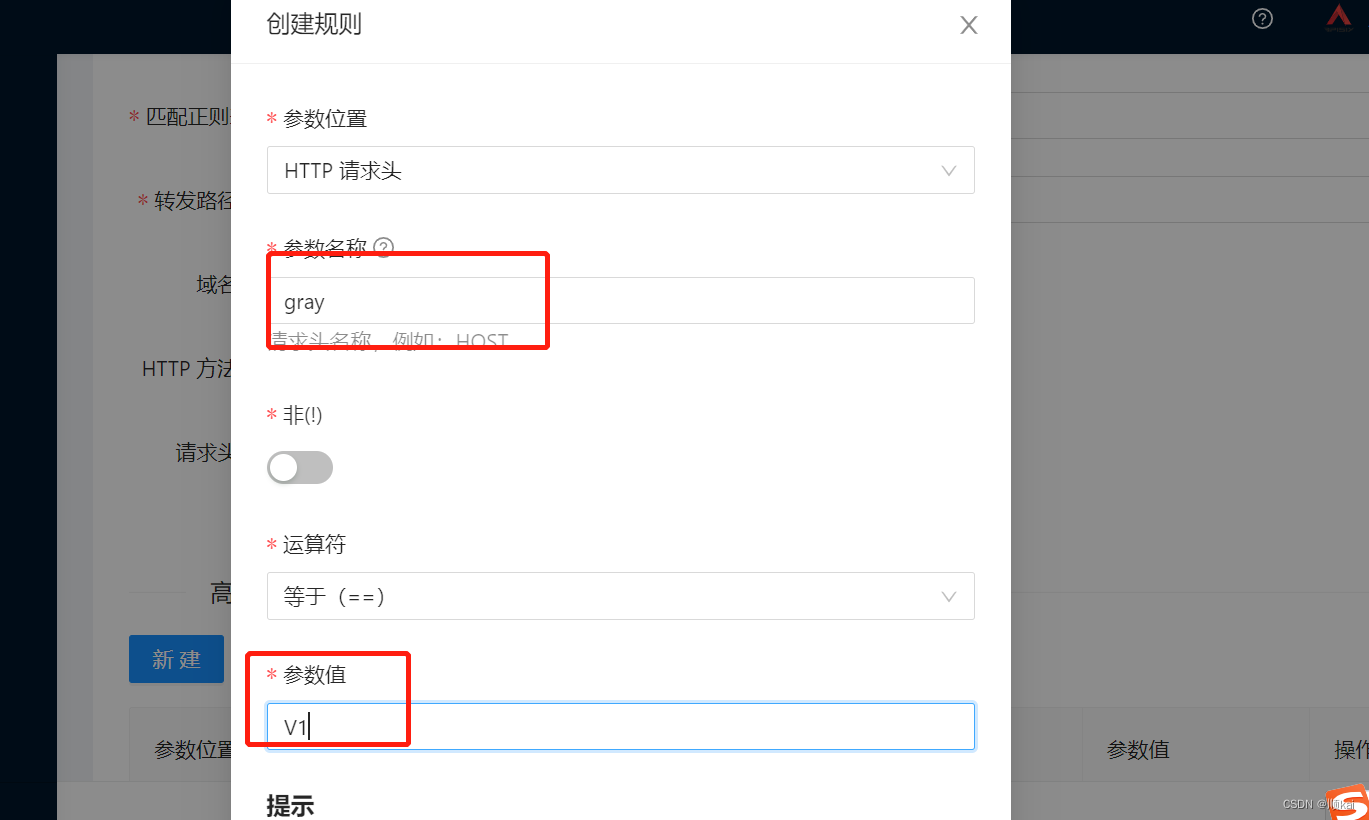
安装chrom浏览器modheader插件,在发起请求时添加灰度标识
![[外链图片转存中...(img-poVpOiJZ-1686038583826)]](https://img-blog.csdnimg.cn/9bea969cc7df415c9876bcbb01e64dc6.png)






