文章目录
- 一、原子类型
- 二、原子操作函数
- 三、内存序
- 1)happens-before和synchronizes-with语义
- 2)内存序模式
- 四、标准库函数
- 五、栅栏(Barrier)
一、原子类型
标准原子类型的备选名和与其相关的 std::atomic<> 特化类:
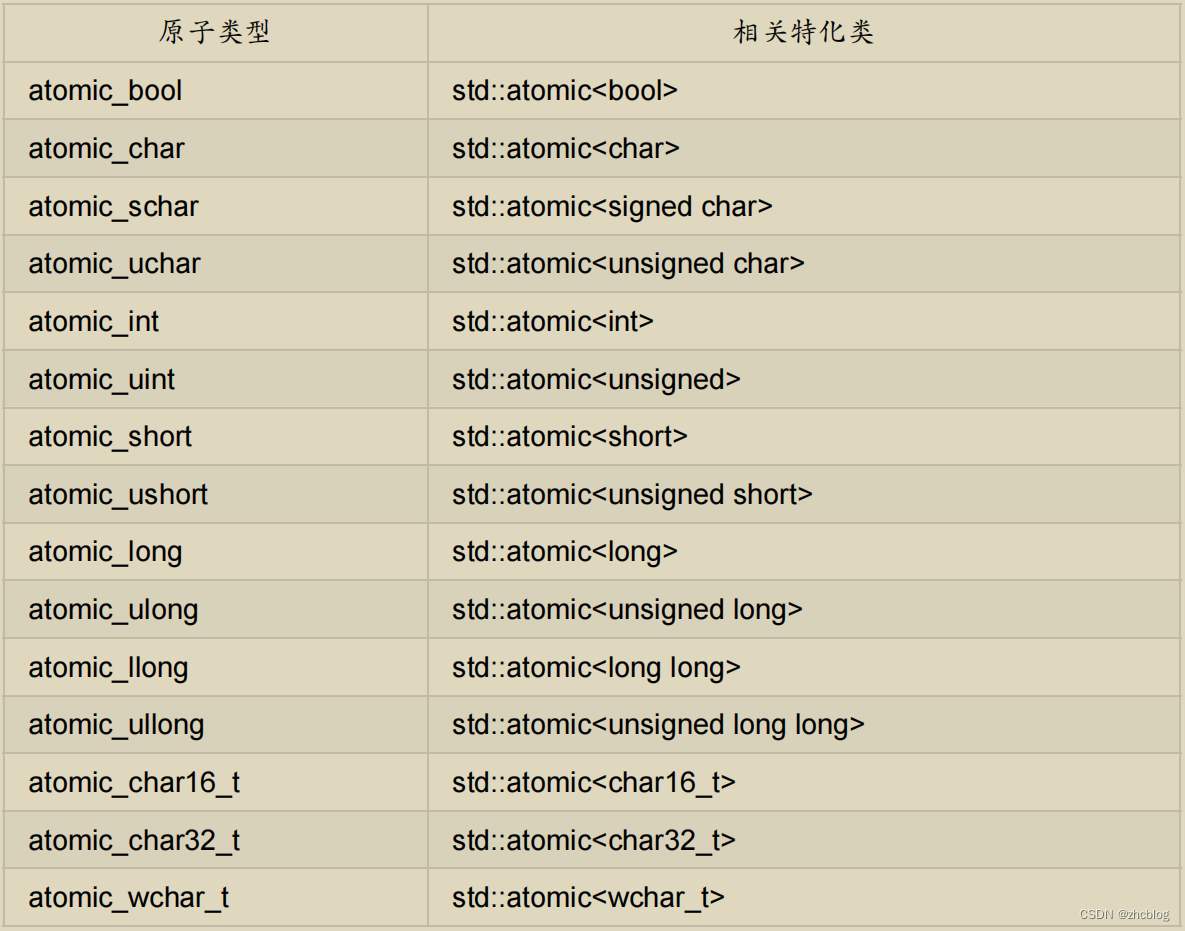
除上述类型外还有std::atomic<T*>类型,返回的也是T*类型,操作接口语义也是一样的。
同时原子类型也可能是自定义类型,如果是其它自定义类型,则需要满足下面一些条件:
- 这个类型必须有拷贝赋值运算符;
- 这个类型不能有任何虚函数或虚基类,以及必须使用编译器创建的拷贝赋值操作;
- 自定义类型中所有的基类和非静态数据成员也都需要支持拷贝赋值操作,即可使用memcpy()进行拷贝;
- 这个类型必须是“位可比的”(bitwise equality comparable),可以调用memcmp()对位进行比较;
但是建议自定义类型不要太过复杂,因为这样反而会降低程序性能。
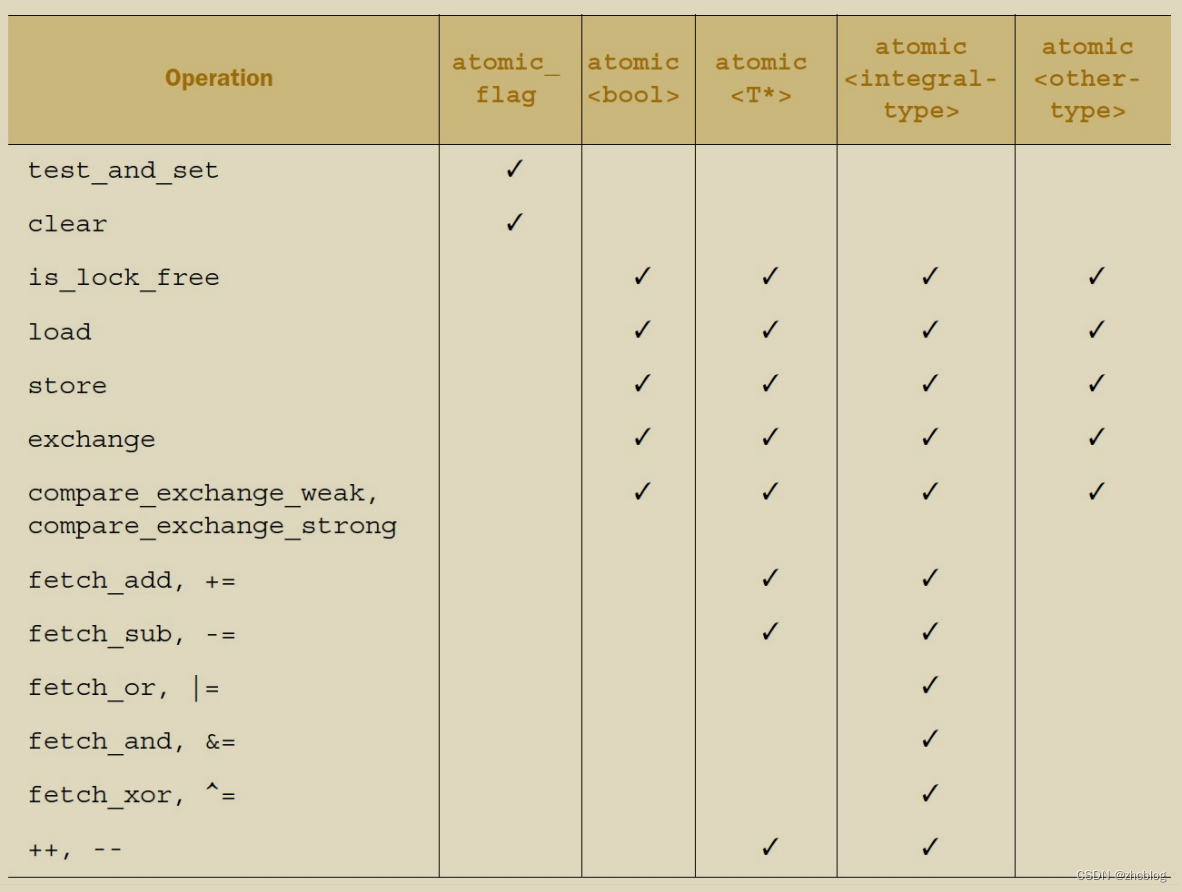
以下是对应每种类型必须提供的成员接口函数:
二、原子操作函数
原子操作类常用成员函数有fetch_*、store、load、exchange、compare_exchange_weak和compare_exchange_strong:
- fetch_*:先获取值再计算,即返回的是修改之前的值;
- store:写入数据;
- load:加载并返回数据;
- exchange:直接设置一个新值;
- compare_exchange_weak:先比较第一个参数的值和要修改的内存值(第二个参数)是否相等,如果相等才会修改,该函数有可能在except == value时也会返回false所以一般用在while中,直到为true才退出;
- compare_exchange_strong:功能和*_weak一样,不过except == value时该函数保证不会返回false,但该函数性能不如*_weak;
注意:使用操作符(如+=、++、^=等)时要看类成员是否提供对应操作符,否则可能出现意想不到的问题。
三、内存序
1)happens-before和synchronizes-with语义
-
happens-before:
如果两个操作之间存在依赖关系,并且一个操作一定比另一个操作先发生,那么者两个操作就存在happens-before关系;
-
synchronizes-with:
synchronizes-with关系指原子类型之间的操作,如果原子操作A在像变量X写入一个之后,接着在同一线程或其它线程原子操作B又读取该值或重新写入一个值那么A和B之间就存在synchronizes-with关系;
注意这两中语义只是一种关系,并不是一种同步约束,也就是需要我们编程去保证,而不是它本身就存在。
2)内存序模式
C++内存序有如下六种标记:
typedef enum memory_order{memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst} memory_order;
具体含义如下:
- memory_order_seq_cst:默认模式也是顺序要求最严格的一种模式,保证多个线程对同一个原子变量的访问,按照某种全局顺序进行,且不会出现重排序。
- memory_order_release:释放内存序
-
保证之前的所有写操作都在该操作之前完成,不能重排序,即保证happens-before关系。
-
保证该操作之前写入的值对其它线程都是可见,这和写屏障功能很像:把CPU高速缓存中的数据同步到主存和其它CPU高速缓存中(其实是发送了一个更新指令消息到其它CPU的invalidate queue中),即该操作写入一个值后其它线程读取该值一定是之前写入的值,满足可见性。
-
注意该模式只针对写,对读没有约束(即读可能会重排),一般和memory_order_acquire成对使用。
-
memory_order_release和memory_order_acquire常用用法(下面的2和3操作存在synchronizes-with关系):
-
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{x.store(true,std::memory_order_relaxed); // 1y.store(true,std::memory_order_release); // 2 保证写如的y对其它线程立马可见
}
void read_y_then_x()
{while(!y.load(std::memory_order_acquire)); // 3 保证能够读到y的最新值if(x.load(std::memory_order_relaxed)) // 4++z;
}
int main()
{x=false;y=false;z=0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load()!=0); // 5 这里z一定不会为0
}
- memory_order_acquire:获取内存序
- 保证之后的所有读操作都在该操作之后完成,不能重排序,即保证happens-before关系。
- 保证该操作读取到的值一定是之前写入的值,这么读屏障功能很像:让store buffer和CPU高速缓存中的数据失效重主存中加载最新主句(其实是看invalidate queue中是否有该内存的更新指令,如果有重新重主存中加载最新的数据),即保证后面其它线程读取该值时能够读到最新值,满足可见性。
- 注意该操作指针对读,对写没有约束(即写可能会重排),一般和memory_order_release成对使用。
- memory_order_acq_rel:获取-释放内存序
- 该操作和之前的写操作,该操作和之后的读操作,不能重排序,即保证happens-before关系。
- 确保该原子操作之前的所有写操作在该原子操作之前都完成,并且该原子操作之后的所有读写操作都在该原子操作之后完成,即同时具有release和acquire内存序的功能。
- 注意该操作对之前的读和之后的写没有约束。
- memory_order_consume:消费内存序
-
保证指针指向的原子对象指行原子读操作和之后的指针指向该原子操作的读是可见的,即满足happens-before关系,可理解为指针版的memory_order_acquire。
-
如果一个线程在该原子操作之前执行了通过指针进行的读操作,那么该指针指向的对象在该原子操作在其它线程之后的读操作中一定是可见的。
-
对指针进行的读操作产生约束,对其他类型的操作没有约束力。
-
memory_order_consume用法 :
-
struct X
{int i;std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
void create_x()
{X* x=new X;x->i=42;x->s="hello";a.store(99,std::memory_order_relaxed); // 1p.store(x,std::memory_order_release); // 2
}
void use_x()
{X* x;while(!(x=p.load(std::memory_order_consume))) // 3std::this_thread::sleep(std::chrono::microseconds(1));assert(x->i==42); // 4assert(x->s=="hello"); // 5assert(a.load(std::memory_order_relaxed)==99); // 6
}
int main()
{std::thread t1(create_x);std::thread t2(use_x);t1.join();t2.join();
}
有时我们为了提升性能对于memory_order_consume,我们可以使用 std::kill_dependecy()打破依赖关系提升性能,该函数会复制提供的参数给返回值:
int global_data[]={ … };
std::atomic<int> index;
void f()
{int i=index.load(std::memory_order_consume);do_something_with(global_data[std::kill_dependency(i)]);
}
- memory_order_relaxed:松散的内存序,保证本线程中的原子变量满足happens-before关系,不能对其进行重排序,但是其它变量可以重排序,该约束对多线程之间没有要求,可能产生数据竞争。
四、标准库函数
C++标志也提供独立的(非类成员函数)原子操作函数如下:
- std::atomic_load
- std::atomic_store
- std::atomic_exchange
- std::atomic_compare_exchange_weak
- std::atomic_compare_exchange_strong
这些函数和原子类成员函数功能一样,不过这些函数第一个参数传入的是原子类对象指针类型。同时以上接口还有*_explicit版本,这版接口最后一个参数支持传递memory order类型,如:std::atomic_store(&atomic_var,new_value) 与 std::atomic_store_explicit(&atomic_var,new_value,std::memory_order_release )
std::atomic_load(&a) 和a.load()的作用一样,但需要注意的是,与a.load(std::memory_order_acquire)等价的操作是 std::atomic_load_explicit(&a, std::memory_order_acquire);
为什么会提供这类函数?
在C中只能使用指针,而不能使用引用,为了要与C语言兼容,例如:compare_exchange_weak()和compare_exchange_strong()成员函数的第一个参数(期望值)是一个引用,而 std::atomic_compare_exchange_weak() (第一个参数是指向对象的指针)的第二个参数是一个指针。
标准库函数还支持std::shared_ptr<>智能指针类型,使用如下:
std::shared_ptr<my_data> p;
void process_global_data()
{std::shared_ptr<my_data> local=std::atomic_load(&p);process_data(local);
}
void update_global_data()
{std::shared_ptr<my_data> local(new my_data);std::atomic_store(&p,local);
}
五、栅栏(Barrier)
以上函数都是只针对原子变量,而栅栏是对所有数据有效。栅栏是一种同步原语,它可以用来同步多个线程之间的操作。栅栏可以将线程分为若干个阶段,在每个阶段中,线程需要等待其他线程完成特定的操作后才能继续执行下一步操作。栅栏的主要作用是协调多个线程之间的操作,确保它们按照预期的顺序执行。
在C++中,栅栏有多种实现,包括std::atomic_thread_fence、std::atomic_signal_fence、std::thread::join等。其中,std::atomic_thread_fence和std::atomic_signal_fence是用于控制内存访问顺序的栅栏,std::thread::join是用于等待其他线程完成的栅栏。
下面是std::atomic_thread_fence的用法示例:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{x.store(true,std::memory_order_relaxed); // 1std::atomic_thread_fence(std::memory_order_release); // 2 栅栏也要指向如何限制内存序y.store(true,std::memory_order_relaxed); // 3
}
void read_y_then_x()
{while(!y.load(std::memory_order_relaxed)); // 4std::atomic_thread_fence(std::memory_order_acquire); // 5 保证之的读操作能读到最新数据if(x.load(std::memory_order_relaxed)) // 6++z;
}
void write_y_then_x()
{y.store(true, std::memory_order_relaxed);std::atomic_thread_fence(std::memory_order_release); // 7int r = x.load(std::memory_order_relaxed);
}
在使用栅栏的情况下原子变量就不需要指定内存序列了,可以改成memory_order_relaxed松散内存序。
注意栅栏的有效范围是前后紧邻的一行语句,如下代码中后面两行的语句顺序无法保证:
void write_x_then_y()
{std::atomic_thread_fence(std::memory_order_release);x.store(true,std::memory_order_relaxed);y.store(true,std::memory_order_relaxed);
}