STL(结)
- map
- 存储结构
- 基本操作
- equal_range
- 遍历方式
- 插入
- multimap
- set
- unordered_map
- map和无序map的异同
- map
- unordered_map
map
存储结构
map容器的底层存储是一个红黑树,遍历方式都是按照中序遍历的方式进行的。
int main() {std::map<int, std::string> ismap;ismap[12] = "yhping";ismap[34] = "xjq";ismap[23] = "hx";ismap[67] = "dxw";ismap[45] = "yx";ismap[56] = "dy";
}
上面代码,我们定义了一map容器,其中放置了数据,其存储结构是红黑树,按照关键码进行排序。如下图:
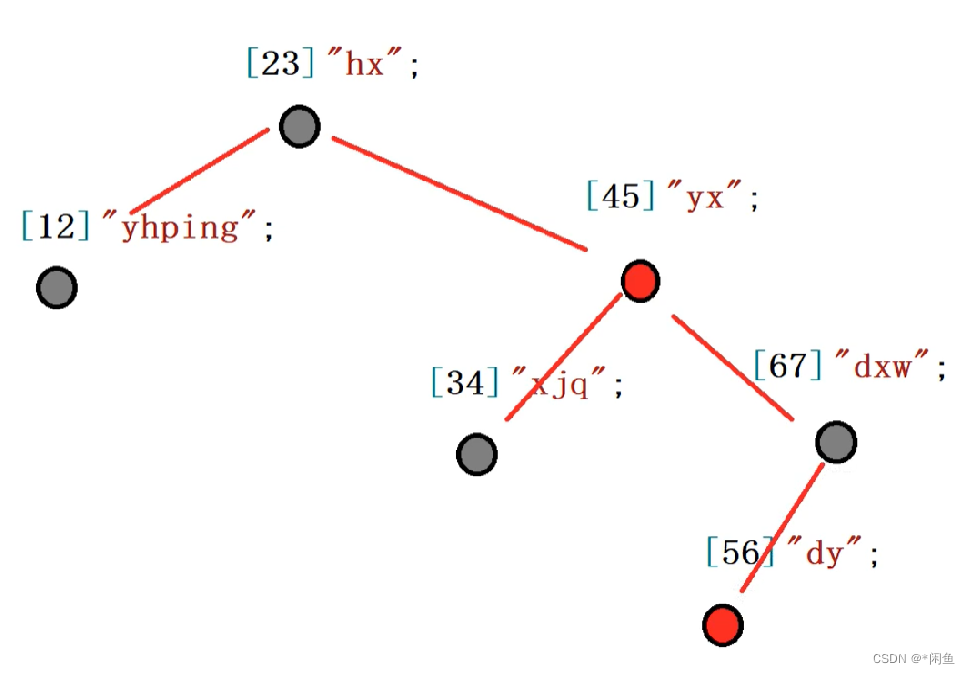
我们知道了其存储结构,才可以了解其成员方法。
基本操作
equal_range
函数声明:std::pair<const_iterator,const_iterator> equal_range(const k&x)const
该函数返回容器中所拥有给定关键的元素范围,其中键值对中存在两个迭代器,一个指向首个不小于key的元素,首个迭代器可以通过lower_bound()获得,而第二个迭代器指向首个大于key的元素,可换用upper_bound()获得。
试想 auto it= ismap.equal_range(40);该函数返回值的两个指针指向。
根据上面代码我们也可得到第一个迭代器指向45,第二个也指向45。
cout << it.first->first << " " << it.second->first << endl;
执行该语句得到的结果便是45,45。
auto et= ismap.equal_range(45);cout << et.first->first<<":"<<et.first->second << endl;cout << et.second->first <<":"<<et.second->second<< endl;auto it = ismap.lower_bound(45);cout << it->first <<":"<< it->second << endl;auto pt = ismap.upper_bound(45);cout << pt->first << ":"<< pt->second << endl;
执行结果: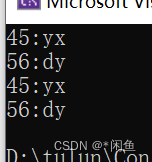
通过结果结果发现equal_range函数返回的是两个迭代器,而lower_bound和upper_bound返回的是一个迭代器,分别是首个不小于待查找的元素和首个大于带查找值得元素。
遍历方式
执行下面语句,判断其结果:
int main() {std::map<int, std::string> ismap;ismap[12] = "yhping";ismap[34] = "xjq";ismap[23] = "hx";ismap[67] = "dxw";ismap[45] = "yx";ismap[56] = "dy";auto p = ismap.begin();for (; p != ismap.end(); ++p) {cout << p->first <<" : " <<p->second<< endl;}
}
这段代码便是要我们遍历map容器,结果如下:
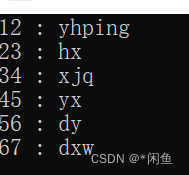
也可以通过map定义时加入geater< int >参数来改变存储顺序。通过上面执行结果我们可以看出,迭代器的首个元素指向关键码最小的位置,而末尾便是最大的位置。遍历的时候是按照中序遍历的顺序进行遍历,但是我们明明对迭代器进行了++操作,所以总觉得是对其进行了+1,而本质上是通过调用函数来移动到其直接后继。
插入
map容器插入时如果其中存在相同关键码,便只会插入一个。
int main() {std::map<int, std::string> ismap;ismap.insert(std::map<int, std::string>::value_type(18, "dxw"));ismap.insert(std::map<int, std::string>::value_type(18, "sxl"));ismap.insert(std::map<int, std::string>::value_type(12, "yhping"));ismap.insert(std::map<int, std::string>::value_type(12, "wt"));ismap.insert(std::map<int, std::string>::value_type(34, "newdata"));ismap.insert(std::map<int, std::string>::value_type(23, "yx"));ismap.insert(std::map<int, std::string>::value_type(24, "fjx"));ismap.insert(std::map<int, std::string>::value_type(22, "data"));for (auto& x : ismap) {cout << x.first << ":" << x.second << endl;}
}
结果: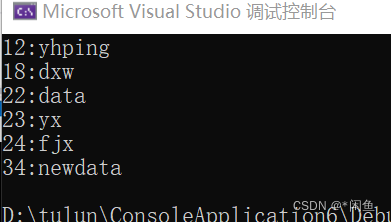
所以此时就要用多重map,
multimap
多重map可以存放关键码相同得数据,如下
int main() {std::multimap<int, std::string> ismap;ismap.insert(std::multimap<int, std::string>::value_type(18, "dxw"));ismap.insert(std::multimap<int, std::string>::value_type(18, "sxl"));ismap.insert(std::multimap<int, std::string>::value_type(12, "yhping"));ismap.insert(std::multimap<int, std::string>::value_type(12, "wt"));ismap.insert(std::multimap<int, std::string>::value_type(34, "newdata"));ismap.insert(std::multimap<int, std::string>::value_type(23, "yx"));ismap.insert(std::multimap<int, std::string>::value_type(24, "fjx"));ismap.insert(std::multimap<int, std::string>::value_type(22, "data"));for (auto& x :ismap) {cout << x.first << ":" << x.second << endl;}
}
使用了多重map之后就会发现可以存放多个关键码相同得元素,

如果在此时用equal_range函数,会出现什么情况呢?
我们可以在上面代码得前提下执行下面代码
auto it = ismap.equal_range(18);for (auto p = it.first; p != it.second; ++p) {cout << p->first << " : " << p->second << endl;}
得到结果便是关键码为18得两个迭代器。如果在容器中没有关键码为18得值,返回得两个迭代器和有序map一样,返回的是指向首个不小于和首个大于关键码的迭代器。
set
set容器智能存放一种类型,其底层也是红黑树,遍历是有序的,其插入的参数有两个,一个是要插入的关键码类型,另一个是bool类型,可以通过bool类型的返回值判断是否插入成功。
int main() {std::set<int> iset;for (int i = 0; i < 100; ++i) {auto it=iset.insert(rand()%100);if (it.second) {cout << "insert seccod" << endl;}else {cout << "已经有重复值" << endl;cout << *it.first << endl;}}std::set<int>::iterator it = iset.begin();for (; it != iset.end(); ++it) {cout << *it << endl;}
}
unordered_map
通过代码比较map和unordered_map的区别
int main() {std::map<int, std::string> ismap;std::unordered_map<int, std::string> isunmap;ismap[12] = "yhping";ismap[34] = "xjq";ismap[23] = "hx";ismap[67] = "dxw";ismap[45] = "yx";ismap[56] = "dy";isunmap[12] = "yhping";isunmap[34] = "xjq";isunmap[23] = "hx";isunmap[67] = "dxw";isunmap[45] = "yx";isunmap[56] = "dy";cout << "map" << endl;for (auto& x : ismap) {cout << x.first << ":" << x.second << endl;}cout << "------------------------" << endl;cout << "undered_map" << endl;for (auto& x : isunmap) {cout << x.first << ":" << x.second << endl;}return 0;
}
我们通过代码可以发现其区别和名字一样,一个是有序的一个是无序的,这是为什么呢?
无需map的底层实际上不是红黑树,而是哈希桶,我们可以通过画图来理解其底层结构。
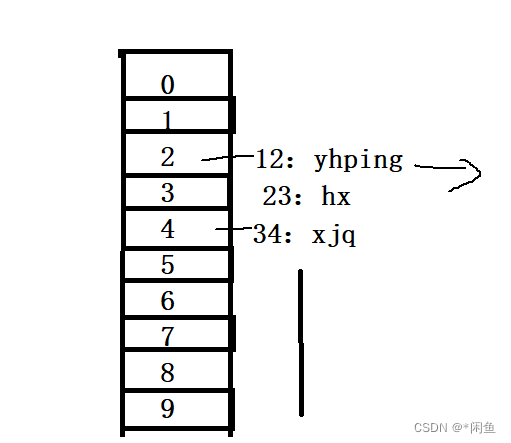
这里桶中结点个数是10个,所以存放结点是这样存放的,关键码对10取余,得到的结果是多少就存放在那个结点后面,存放的方式便是链表。而如果数据量太大的情况下,而桶中结点个数很少,这样导致一个结点后的元素个数很多,遍历时元素效率就很低,所以桶的也会进行扩容(更改10),然后重构哈希表(桶)。而每当结点个数等于桶中元素个数时就会扩容。
map和无序map的异同
map
优点:底层是红黑树,其有序性可以在很多的操作中应用,复杂度logN
缺点:空间占用率高,每个结点都需要存指针来指向父节点和子节点,以及红黑性质,所以每个结点都占用了大量空间。
适用范围:对那些有顺序要求的问题,用map会很高效。
unordered_map
优点:底层是哈希表,为此查找速度很快,时间复杂度为O(1);
缺点:更改哈希表的大小,重构哈希表比较浪费时间。
使用范围:对于查找问题,使用无序map会比较高效。