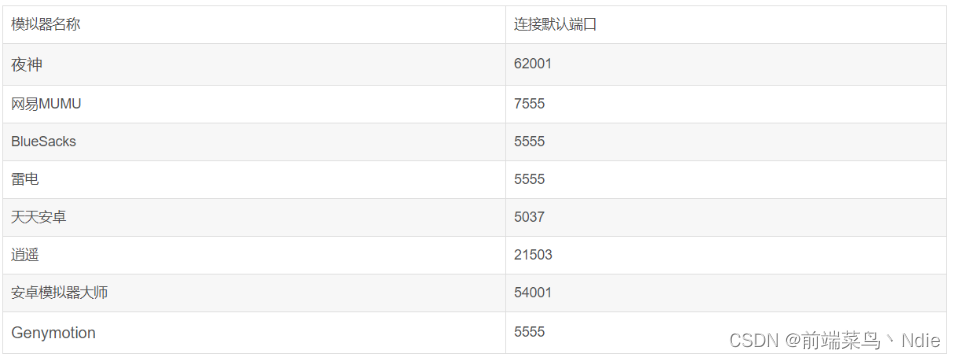
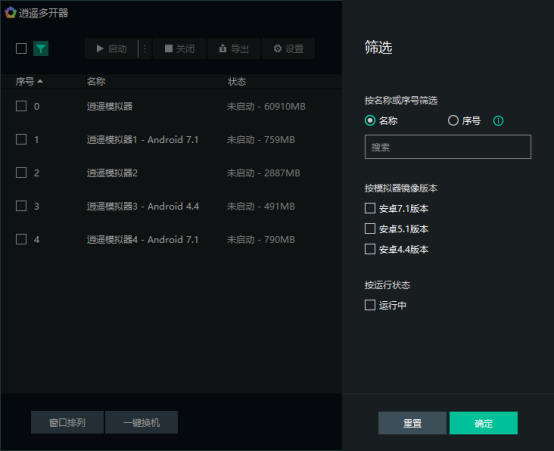
递归
概述
定义
计算机科学中,递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集
In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem.
比如单链表递归遍历的例子:
void f(Node node) {if(node == null) {return;}println("before:" + node.value)f(node.next);println("after:" + node.value)
}
说明:
- 自己调用自己,如果说每个函数对应着一种解决方案,自己调用自己意味着解决方案是一样的(有规律的)
- 每次调用,函数处理的数据会较上次缩减(子集),而且最后会缩减至无需继续递归
- 内层函数调用(子集处理)完成,外层函数才能算调用完成
原理
假设链表中有 3 个节点,value 分别为 1,2,3,以上代码的执行流程就类似于下面的伪码
// 1 -> 2 -> 3 -> null f(1)void f(Node node = 1) {println("before:" + node.value) // 1void f(Node node = 2) {println("before:" + node.value) // 2void f(Node node = 3) {println("before:" + node.value) // 3void f(Node node = null) {if(node == null) {return;}}println("after:" + node.value) // 3}println("after:" + node.value) // 2}println("after:" + node.value) // 1
}
思路
- 确定能否使用递归求解
- 推导出递推关系,即父问题与子问题的关系,以及递归的结束条件

- 深入到最里层叫做递
- 从最里层出来叫做归
- 在递的过程中,外层函数内的局部变量(以及方法参数)并未消失,归的时候还可以用到
单路递归 Single Recursion
E01. 阶乘
用递归方法求阶乘
-
阶乘的定义 n!= 1⋅2⋅3⋯(n-2)⋅(n-1)⋅n,其中 n 为自然数,当然 0! = 1
-
递推关系

代码
private static int f(int n) {if (n == 1) {return 1;}return n * f(n - 1);
}
拆解伪码如下,假设 n 初始值为 3
f(int n = 3) { // 解决不了,递return 3 * f(int n = 2) { // 解决不了,继续递return 2 * f(int n = 1) {if (n == 1) { // 可以解决, 开始归return 1;}}}
}
E02. 反向打印字符串
用递归反向打印字符串,n 为字符在整个字符串 str 中的索引位置
- 递:n 从 0 开始,每次 n + 1,一直递到 n == str.length() - 1
- 归:从 n == str.length() 开始归,从归打印,自然是逆序的
递推关系

代码为
public static void reversePrint(String str, int index) {if (index == str.length()) {return;}reversePrint(str, index + 1);System.out.println(str.charAt(index));
}
拆解伪码如下,假设字符串为 “abc”
void reversePrint(String str, int index = 0) {void reversePrint(String str, int index = 1) {void reversePrint(String str, int index = 2) {void reversePrint(String str, int index = 3) { if (index == str.length()) {return; // 开始归}}System.out.println(str.charAt(index)); // 打印 c}System.out.println(str.charAt(index)); // 打印 b}System.out.println(str.charAt(index)); // 打印 a
}
多路递归 Multi Recursion
E01. 斐波那契数列
- 之前的例子是每个递归函数只包含一个自身的调用,这称之为 single recursion
- 如果每个递归函数例包含多个自身调用,称之为 multi recursion
递推关系
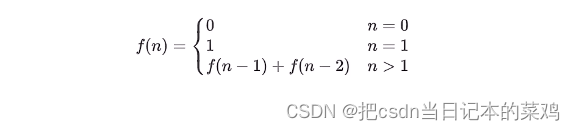
下面的表格列出了数列的前几项
| F0 | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | F11 | F12 | F13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | 144 | 233 |
实现
public static int f(int n) {if (n == 0) {return 0;}if (n == 1) {return 1;}return f(n - 1) + f(n - 2);
}
执行流程
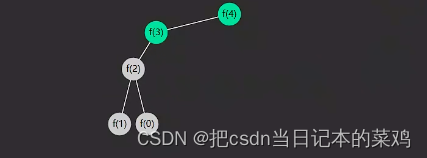
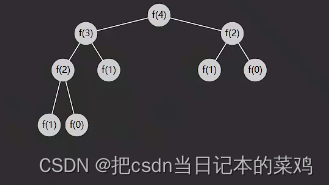
- 绿色代表正在执行(对应递),灰色代表执行结束(对应归)
- 递不到头,不能归,对应着深度优先搜索
时间复杂度
- 更多 Fibonacci 参考[^8] [^9] [^10]
- 以上时间复杂度分析,未考虑大数相加的因素
变体1 - 兔子问题[^8]
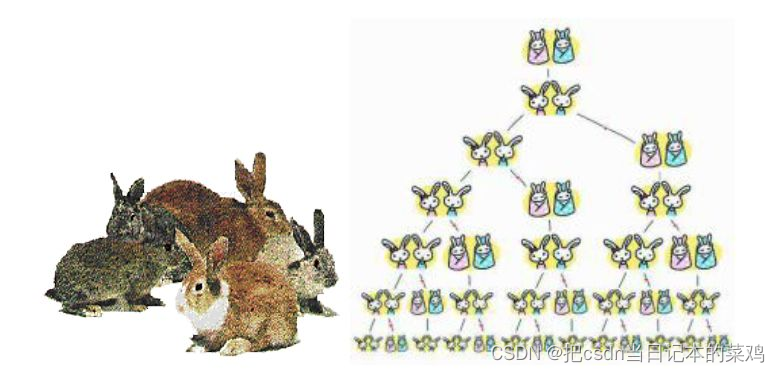
- 第一个月,有一对未成熟的兔子
- 第二个月,它们成熟
- 第三个月,它们能产下一对新的小兔
- 所有兔子遵循相同规律,求第 n 个月的兔子数
分析
兔子问题如何与斐波那契联系起来呢?设第 n 个月兔子数为 f(n)
- f(n) = 上个月兔子数 + 新生的小兔子数
- 而【新生的小兔子数】实际就是【上个月成熟的兔子数】
- 因为需要一个月兔子就成熟,所以【上个月成熟的兔子数】也就是【上上个月的兔子数】
- 上个月兔子数,即 f(n-1)
- 上上个月的兔子数,即 f(n-2)
因此本质还是斐波那契数列,只是从其第一项开始
变体2 - 青蛙爬楼梯
- 楼梯有 n 阶
- 青蛙要爬到楼顶,可以一次跳一阶,也可以一次跳两阶
- 只能向上跳,问有多少种跳法
分析
| n | 跳法 | 规律 |
|---|---|---|
| 1 | (1) | 暂时看不出 |
| 2 | (1,1) (2) | 暂时看不出 |
| 3 | (1,1,1) (1,2) (2,1) | 暂时看不出 |
| 4 | (1,1,1,1) (1,2,1) (2,1,1) (1,1,2) (2,2) | 最后一跳,跳一个台阶的,基于f(3) 最后一跳,跳两个台阶的,基于f(2) |
| 5 | … | … |
-
因此本质上还是斐波那契数列,只是从其第二项开始
-
对应 leetcode 题目 70. 爬楼梯 - 力扣(LeetCode)
递归优化-记忆法
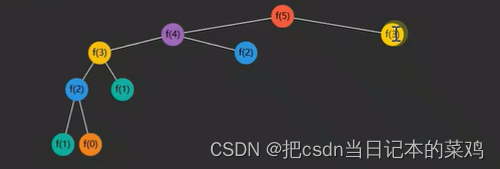
上述代码存在很多重复的计算,例如求 f(5) 递归分解过程
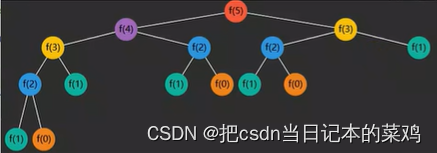
可以看到(颜色相同的是重复的):
- f(3) 重复了 2 次
- f(2) 重复了 3 次
- f(1) 重复了 5 次
- f(0) 重复了 3 次
随着 n 的增大,重复次数非常可观,如何优化呢?
Memoization 记忆法(也称备忘录)是一种优化技术,通过存储函数调用结果(通常比较昂贵),当再次出现相同的输入(子问题)时,就能实现加速效果,改进后的代码
public static void main(String[] args) {int n = 13;int[] cache = new int[n + 1];Arrays.fill(cache, -1);cache[0] = 0;cache[1] = 1;System.out.println(f(cache, n));
}public static int f(int[] cache, int n) {if (cache[n] != -1) {return cache[n];}cache[n] = f(cache, n - 1) + f(cache, n - 2);return cache[n];
}
优化前后的图示,只要结果被缓存,就不会执行其子问题
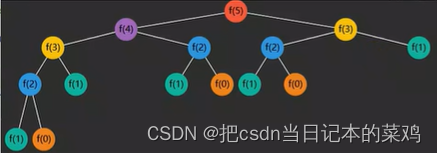
- 改进后的时间复杂度为 O(n)
- 请自行验证改进后的效果
- 请自行分析改进后的空间复杂度
注意
- 记忆法是动态规划的一种情况,强调的是自顶向下的解决
- 记忆法的本质是空间换时间
递归优化-尾递归
爆栈
用递归做 n + (n-1) + (n-2) … + 1
public static long sum(long n) {if (n == 1) {return 1;}return n + sum(n - 1);
}
在我的机器上 n = 12000 时,爆栈了
Exception in thread "main" java.lang.StackOverflowErrorat Test.sum(Test.java:10)at Test.sum(Test.java:10)at Test.sum(Test.java:10)at Test.sum(Test.java:10)at Test.sum(Test.java:10)...
为什么呢?
- 每次方法调用是需要消耗一定的栈内存的,这些内存用来存储方法参数、方法内局部变量、返回地址等等
- 方法调用占用的内存需要等到方法结束时才会释放
- 而递归调用我们之前讲过,不到最深不会回头,最内层方法没完成之前,外层方法都结束不了
- 例如,sum(3) 这个方法内有个需要执行 3 + sum(2),sum(2) 没返回前,加号前面的 3 不能释放
- 看下面伪码
long sum(long n = 3) {return 3 + long sum(long n = 2) {return 2 + long sum(long n = 1) {return 1;}}
}
尾调用
如果函数的最后一步是调用一个函数,那么称为尾调用,例如
function a() {return b()
}
下面三段代码不能叫做尾调用
function a() {const c = b()return c
}
- 因为最后一步并非调用函数
function a() {return b() + 1
}
- 最后一步执行的是加法
function a(x) {return b() + x
}
- 最后一步执行的是加法
一些语言[^11]的编译器能够对尾调用做优化,例如
从Java8开始,Java不提供尾叫优化(TCO)
function a() {// 做前面的事return b()
}function b() {// 做前面的事return c()
}function c() {return 1000
}a()
没优化之前的伪码
function a() {return function b() {return function c() {return 1000}}
}
优化后伪码如下
a()
b()
c()
为何尾递归才能优化?
调用 a 时
- a 返回时发现:没什么可留给 b 的,将来返回的结果 b 提供就可以了,用不着我 a 了,我的内存就可以释放
调用 b 时
- b 返回时发现:没什么可留给 c 的,将来返回的结果 c 提供就可以了,用不着我 b 了,我的内存就可以释放
如果调用 a 时
- 不是尾调用,例如 return b() + 1,那么 a 就不能提前结束,因为它还得利用 b 的结果做加法
尾递归
尾递归是尾调用的一种特例,也就是最后一步执行的是同一个函数
尾递归避免爆栈
安装 Scala
Scala 入门
object Main {def main(args: Array[String]): Unit = {println("Hello Scala")}
}
- Scala 是 java 的近亲,java 中的类都可以拿来重用
- 类型是放在变量后面的
- Unit 表示无返回值,类似于 void
- 不需要以分号作为结尾,当然加上也对
还是先写一个会爆栈的函数
def sum(n: Long): Long = {if (n == 1) {return 1}return n + sum(n - 1)
}
- Scala 最后一行代码若作为返回值,可以省略 return
不出所料,在 n = 11000 时,还是出了异常
println(sum(11000))Exception in thread "main" java.lang.StackOverflowErrorat Main.sum(Main.scala:25)at Main.sum(Main.scala:25)at Main.sum(Main.scala:25)at Main.sum(Main.scala:25)...
这是因为以上代码,还不是尾调用,要想成为尾调用,那么:
- 最后一行代码,必须是一次函数调用
- 内层函数必须摆脱与外层函数的关系,内层函数执行后不依赖于外层的变量或常量
def sum(n: Long): Long = {if (n == 1) {return 1}return n + sum(n - 1) // 依赖于外层函数的 n 变量
}
如何让它执行后就摆脱对 n 的依赖呢?
- 不能等递归回来再做加法,那样就必须保留外层的 n
- 把 n 当做内层函数的一个参数传进去,这时 n 就属于内层函数了
- 传参时就完成累加, 不必等回来时累加
sum(n - 1, n + 累加器)
改写后代码如下
@tailrec
def sum(n: Long, accumulator: Long): Long = {if (n == 1) {return 1 + accumulator} return sum(n - 1, n + accumulator)
}
- accumulator 作为累加器
- @tailrec 注解是 scala 提供的,用来检查方法是否符合尾递归
- 这回 sum(10000000, 0) 也没有问题,打印 50000005000000
执行流程如下,以伪码表示 sum(4, 0)
// 首次调用
def sum(n = 4, accumulator = 0): Long = {return sum(4 - 1, 4 + accumulator)
}// 接下来调用内层 sum, 传参时就完成了累加, 不必等回来时累加,当内层 sum 调用后,外层 sum 空间没必要保留
def sum(n = 3, accumulator = 4): Long = {return sum(3 - 1, 3 + accumulator)
}// 继续调用内层 sum
def sum(n = 2, accumulator = 7): Long = {return sum(2 - 1, 2 + accumulator)
}// 继续调用内层 sum, 这是最后的 sum 调用完就返回最后结果 10, 前面所有其它 sum 的空间早已释放
def sum(n = 1, accumulator = 9): Long = {if (1 == 1) {return 1 + accumulator}
}
本质上,尾递归优化是将函数的递归调用,变成了函数的循环调用
改循环避免爆栈
public static void main(String[] args) {long n = 100000000;long sum = 0;for (long i = n; i >= 1; i--) {sum += i;}System.out.println(sum);
}
递归时间复杂度-Master theorem[^14]
若有递归式


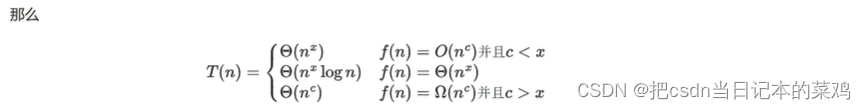
例1
T(n) = 2T(\frac{n}{2}) + n^4
- 此时 x = 1 < 4,由后者决定整个时间复杂度 \Theta(n^4)
- 如果觉得对数不好算,可以换为求【b 的几次方能等于 a】
例2
T(n) = T(\frac{7n}{10}) + n
- a=1, b=\frac{10}{7}, x=0, c=1
- 此时 x = 0 < 1,由后者决定整个时间复杂度 \Theta(n)
例3
T(n) = 16T(\frac{n}{4}) + n^2
- a=16, b=4, x=2, c=2
- 此时 x=2 = c,时间复杂度 \Theta(n^2 \log{n})
例4
T(n)=7T(\frac{n}{3}) + n^2
- a=7, b=3, x=1.?, c=2
- 此时 x = \log_{3}{7} < 2,由后者决定整个时间复杂度 \Theta(n^2)
例5
T(n) = 7T(\frac{n}{2}) + n^2
- a=7, b=2, x=2.?, c=2
- 此时 x = log_2{7} > 2,由前者决定整个时间复杂度 \Theta(n^{\log_2{7}})
例6
T(n) = 2T(\frac{n}{4}) + \sqrt{n}
- a=2, b=4, x = 0.5, c=0.5
- 此时 x = 0.5 = c,时间复杂度 \Theta(\sqrt{n}\ \log{n})
例7. 二分查找递归
int f(int[] a, int target, int i, int j) {if (i > j) {return -1;}int m = (i + j) >>> 1;if (target < a[m]) {return f(a, target, i, m - 1);} else if (a[m] < target) {return f(a, target, m + 1, j);} else {return m;}
}
- 子问题个数 a = 1
- 子问题数据规模缩小倍数 b = 2
- 除递归外执行的计算是常数级 c=0
T(n) = T(\frac{n}{2}) + n^0
- 此时 x=0 = c,时间复杂度 \Theta(\log{n})
例8. 归并排序递归
void split(B[], i, j, A[])
{if (j - i <= 1) return; m = (i + j) / 2; // 递归split(A, i, m, B); split(A, m, j, B); // 合并merge(B, i, m, j, A);
}
- 子问题个数 a=2
- 子问题数据规模缩小倍数 b=2
- 除递归外,主要时间花在合并上,它可以用 f(n) = n 表示
T(n) = 2T(\frac{n}{2}) + n
- 此时 x=1=c,时间复杂度 \Theta(n\log{n})
例9. 快速排序递归
algorithm quicksort(A, lo, hi) is if lo >= hi || lo < 0 then return// 分区p := partition(A, lo, hi) // 递归quicksort(A, lo, p - 1) quicksort(A, p + 1, hi)
- 子问题个数 a=2
- 子问题数据规模缩小倍数
- 如果分区分的好,b=2
- 如果分区没分好,例如分区1 的数据是 0,分区 2 的数据是 n-1
- 除递归外,主要时间花在分区上,它可以用 f(n) = n 表示
情况1 - 分区分的好
T(n) = 2T(\frac{n}{2}) + n
- 此时 x=1=c,时间复杂度 \Theta(n\log{n})
情况2 - 分区没分好
T(n) = T(n-1) + T(1) + n
- 此时不能用主定理求解
递归时间复杂度-展开求解
像下面的递归式,都不能用主定理求解
例1 - 递归求和
long sum(long n) {if (n == 1) {return 1;}return n + sum(n - 1);
}
T(n) = T(n-1) + c,T(1) = c
下面为展开过程
T(n) = T(n-2) + c + c
T(n) = T(n-3) + c + c + c
…
T(n) = T(n-(n-1)) + (n-1)c
- 其中 T(n-(n-1)) 即 T(1)
- 带入求得 T(n) = c + (n-1)c = nc
时间复杂度为 O(n)
例2 - 递归冒泡排序
void bubble(int[] a, int high) {if(0 == high) {return;}for (int i = 0; i < high; i++) {if (a[i] > a[i + 1]) {swap(a, i, i + 1);}}bubble(a, high - 1);
}
T(n) = T(n-1) + n,T(1) = c
下面为展开过程
T(n) = T(n-2) + (n-1) + n
T(n) = T(n-3) + (n-2) + (n-1) + n
…
T(n) = T(1) + 2 + … + n = T(1) + (n-1)\frac{2+n}{2} = c + \frac{n^2}{2} + \frac{n}{2} -1
时间复杂度 O(n^2)
注:
- 等差数列求和为 个数*\frac{\vert首项-末项\vert}{2}
例3 - 递归快排
快速排序分区没分好的极端情况
T(n) = T(n-1) + T(1) + n,T(1) = c
T(n) = T(n-1) + c + n
下面为展开过程
T(n) = T(n-2) + c + (n-1) + c + n
T(n) = T(n-3) + c + (n-2) + c + (n-1) + c + n
…
T(n) = T(n-(n-1)) + (n-1)c + 2+…+n = \frac{n^2}{2} + \frac{2cn+n}{2} -1
时间复杂度 O(n^2)
不会推导的同学可以进入 https://www.wolframalpha.com/
- 例1 输入 f(n) = f(n - 1) + c, f(1) = c
- 例2 输入 f(n) = f(n - 1) + n, f(1) = c
- 例3 输入 f(n) = f(n - 1) + n + c, f(1) = c
E03. 二分查找
public static int binarySearch(int[] a, int target) {return recursion(a, target, 0, a.length - 1);
}public static int recursion(int[] a, int target, int i, int j) {if (i > j) {return -1;}int m = (i + j) >>> 1;if (target < a[m]) {return recursion(a, target, i, m - 1);} else if (a[m] < target) {return recursion(a, target, m + 1, j);} else {return m;}
}
E04. 冒泡排序
public static void main(String[] args) {int[] a = {3, 2, 6, 1, 5, 4, 7};bubble(a, 0, a.length - 1);System.out.println(Arrays.toString(a));
}private static void bubble(int[] a, int low, int high) {if(low == high) {return;}int j = low;for (int i = low; i < high; i++) {if (a[i] > a[i + 1]) {swap(a, i, i + 1);j = i;}}bubble(a, low, j);
}private static void swap(int[] a, int i, int j) {int t = a[i];a[i] = a[j];a[j] = t;
}
- low 与 high 为未排序范围
- j 表示的是未排序的边界,下一次递归时的 high
- 发生交换,意味着有无序情况
- 最后一次交换(以后没有无序)时,左侧 i 仍是无序,右侧 i+1 已然有序
- 视频中讲解的是只考虑 high 边界的情况,参考以上代码,理解在 low … high 范围内的处理方法
E05. 插入排序
public static void main(String[] args) {int[] a = {3, 2, 6, 1, 5, 7, 4};insertion(a, 1, a.length - 1);System.out.println(Arrays.toString(a));
}private static void insertion(int[] a, int low, int high) {if (low > high) {return;}int i = low - 1;int t = a[low];while (i >= 0 && a[i] > i) {a[i + 1] = a[i];i--;}if(i + 1 != low) {a[i + 1] = t;} insertion(a, low + 1, high);
}
- 已排序区域:[0 … i … low-1]
- 未排序区域:[low … high]
- 视频中讲解的是只考虑 low 边界的情况,参考以上代码,理解 low-1 … high 范围内的处理方法
- 扩展:利用二分查找 leftmost 版本,改进寻找插入位置的代码
E06. 约瑟夫问题[^16]
n 个人排成圆圈,从头开始报数,每次数到第 m 个人(m 从 1 开始)杀之,继续从下一个人重复以上过程,求最后活下来的人是谁?
方法1
根据最后的存活者 a 倒推出它在上一轮的索引号
| f(n,m) | 本轮索引 | 为了让 a 是这个索引,上一轮应当这样排 | 规律 |
|---|---|---|---|
| f(1,3) | 0 | x x x a | (0 + 3) % 2 |
| f(2,3) | 1 | x x x 0 a | (1 + 3) % 3 |
| f(3,3) | 1 | x x x 0 a | (1 + 3) % 4 |
| f(4,3) | 0 | x x x a | (0 + 3) % 5 |
| f(5,3) | 3 | x x x 0 1 2 a | (3 + 3) % 6 |
| f(6,3) | 0 | x x x a |
方法2
设 n 为总人数,m 为报数次数,解返回的是这些人的索引,从0开始
| f(n, m) | 解 | 规律 |
|---|---|---|
| f(1, 3) | 0 | |
| f(2, 3) | 0 1 => 1 | 3%2=1 |
| f(3, 3) | 0 1 2 => 0 1 | 3%3=0 |
| f(4, 3) | 0 1 2 3 => 3 0 1 | 3%4=3 |
| f(5, 3) | 0 1 2 3 4 => 3 4 0 1 | 3%5=3 |
| f(6, 3) | 0 1 2 3 4 5 => 3 4 5 0 1 | 3%6=3 |
一. 找出等价函数
规律:下次报数的起点为 k = m % n
- 首次出列人的序号是 k-1,剩下的的 n-1 个人重新组成约瑟夫环
- 下次从 k 开始数,序号如下
- k,\ k+1, \ …\ ,\ 0,\ 1,\ k-2,如上例中 3\ 4\ 5\ 0\ 1
这个函数称之为 g(n-1,m),它的最终结果与 f(n,m) 是相同的。
二. 找到映射函数
现在想办法找到 g(n-1,m) 与 f(n-1, m) 的对应关系,即
3 \rightarrow 0 \
4 \rightarrow 1 \
5 \rightarrow 2 \
0 \rightarrow 3 \
1 \rightarrow 4 \
映射函数为
mapping(x) =
\begin{cases}
x-k & x=[k…n-1] \
x+n-k & x=[0…k-2]
\end{cases}
等价于下面函数
mapping(x) = (x + n - k)%{n}
代入测试一下
3 \rightarrow (3+6-3)%6 \rightarrow 0 \
4 \rightarrow (4+6-3)%6 \rightarrow 1 \
5 \rightarrow (5+6-3)%6 \rightarrow 2 \
0 \rightarrow (0+6-3)%6 \rightarrow 3 \
1 \rightarrow (1+6-3)%6 \rightarrow 4 \
综上有
f(n-1,m) = mapping(g(n-1,m))
三. 求逆映射函数
映射函数是根据 x 计算 y,逆映射函数即根据 y 得到 x
mapping^{-1}(x) = (x + k)%n
代入测试一下
0 \rightarrow (0+3)%6 \rightarrow 3 \
1 \rightarrow (1+3)%6 \rightarrow 4 \
2 \rightarrow (2+3)%6 \rightarrow 5 \
3 \rightarrow (3+3)%6 \rightarrow 0 \
4 \rightarrow (4+3)%6 \rightarrow 1 \
因此可以求得
g(n-1,m) = mapping^{-1}(f(n-1,m))
四. 递推式
代入推导
\begin{aligned}
f(n,m) = \ & g(n-1,m) \
= \ & mapping^{-1}(f(n-1,m)) \
= \ & (f(n-1,m) + k) % n \
= \ & (f(n-1,m) + m%n) % n \
= \ & (f(n-1,m) + m) % n \
\end{aligned}
最后一步化简是利用了模运算法则
(a+b)%n = (a%n + b%n) %n 例如
- (6+6)%5 = 2 = (6+6%5)%5
- (6+5)%5 = 1 = (6+5%5)%5
- (6+4)%5 = 0 = (6+4%5)%5
最终递推式
f(n,m) =
\begin{cases}
(f(n-1,m) + m) % n & n>1\
0 & n = 1
\end{cases}
E02. 汉诺塔[^13]
Tower of Hanoi,是一个源于印度古老传说:大梵天创建世界时做了三根金刚石柱,在一根柱子从下往上按大小顺序摞着 64 片黄金圆盘,大梵天命令婆罗门把圆盘重新摆放在另一根柱子上,并且规定
- 一次只能移动一个圆盘
- 小圆盘上不能放大圆盘
下面的动图演示了4片圆盘的移动方法

使用程序代码模拟圆盘的移动过程,并估算出时间复杂度
思路
-
假设每根柱子标号 a,b,c,每个圆盘用 1,2,3 … 表示其大小,圆盘初始在 a,要移动到的目标是 c
-
如果只有一个圆盘,此时是最小问题,可以直接求解
- 移动圆盘1 a ——> c
-
如果有两个圆盘,那么
- 圆盘1 a ——> b
- 圆盘2 a ——> c
- 圆盘1 b ——> c
-
如果有三个圆盘,那么
- 圆盘12 a ——> b
- 圆盘3 a ——> c
- 圆盘12 b ——> c
-
如果有四个圆盘,那么
- 圆盘 123 a ——> b
- 圆盘4 a ——> c
- 圆盘 123 b ——> c
题解
public class E02HanoiTower {/*源 借 目h(4, a, b, c) -> h(3, a, c, b)a -> ch(3, b, a, c)*/static LinkedList<Integer> a = new LinkedList<>();static LinkedList<Integer> b = new LinkedList<>();static LinkedList<Integer> c = new LinkedList<>();static void init(int n) {for (int i = n; i >= 1; i--) {a.add(i);}}static void h(int n, LinkedList<Integer> a, LinkedList<Integer> b, LinkedList<Integer> c) {if (n == 0) {return;}h(n - 1, a, c, b);c.addLast(a.removeLast());print();h(n - 1, b, a, c);}private static void print() {System.out.println("-----------------------");System.out.println(a);System.out.println(b);System.out.println(c);}public static void main(String[] args) {init(3);print();h(3, a, b, c);}
}
E03. 杨辉三角[^6]
分析
把它斜着看
11 11 2 11 3 3 1
1 4 6 4 1
- 行 i,列 j,那么 [i][j] 的取值应为 [i-1][j-1] + [i-1][j]
- 当 j=0 或 i=j 时,[i][j] 取值为 1
题解
public static void print(int n) {for (int i = 0; i < n; i++) {if (i < n - 1) {System.out.printf("%" + 2 * (n - 1 - i) + "s", " ");}for (int j = 0; j < i + 1; j++) {System.out.printf("%-4d", element(i, j));}System.out.println();}
}public static int element(int i, int j) {if (j == 0 || i == j) {return 1;}return element(i - 1, j - 1) + element(i - 1, j);
}
优化1
是 multiple recursion,因此很多递归调用是重复的,例如
- recursion(3, 1) 分解为
- recursion(2, 0) + recursion(2, 1)
- 而 recursion(3, 2) 分解为
- recursion(2, 1) + recursion(2, 2)
这里 recursion(2, 1) 就重复调用了,事实上它会重复很多次,可以用 static AtomicInteger counter = new AtomicInteger(0) 来查看递归函数的调用总次数
事实上,可以用 memoization 来进行优化:
public static void print1(int n) {int[][] triangle = new int[n][];for (int i = 0; i < n; i++) {// 打印空格triangle[i] = new int[i + 1];for (int j = 0; j <= i; j++) {System.out.printf("%-4d", element1(triangle, i, j));}System.out.println();}
}public static int element1(int[][] triangle, int i, int j) {if (triangle[i][j] > 0) {return triangle[i][j];}if (j == 0 || i == j) {triangle[i][j] = 1;return triangle[i][j];}triangle[i][j] = element1(triangle, i - 1, j - 1) + element1(triangle, i - 1, j);return triangle[i][j];
}
- 将数组作为递归函数内可以访问的遍历,如果 triangle[i][j] 已经有值,说明该元素已经被之前的递归函数计算过,就不必重复计算了
优化2
public static void print2(int n) {int[] row = new int[n];for (int i = 0; i < n; i++) {// 打印空格createRow(row, i);for (int j = 0; j <= i; j++) {System.out.printf("%-4d", row[j]);}System.out.println();}
}private static void createRow(int[] row, int i) {if (i == 0) {row[0] = 1;return;}for (int j = i; j > 0; j--) {row[j] = row[j - 1] + row[j];}
}
注意:还可以通过每一行的前一项计算出下一项,不必借助上一行,这与杨辉三角的另一个特性有关,暂不展开了
力扣对应题目,但递归不适合在力扣刷高分,因此只列出相关题目,不做刷题讲解了
- 118. 杨辉三角 - 力扣(LeetCode)
- 119. 杨辉三角 II - 力扣(LeetCode)