tip: 作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。
文章目录
- 一、简介
- 深入理解
- 三、CAP的应用应用
一、简介
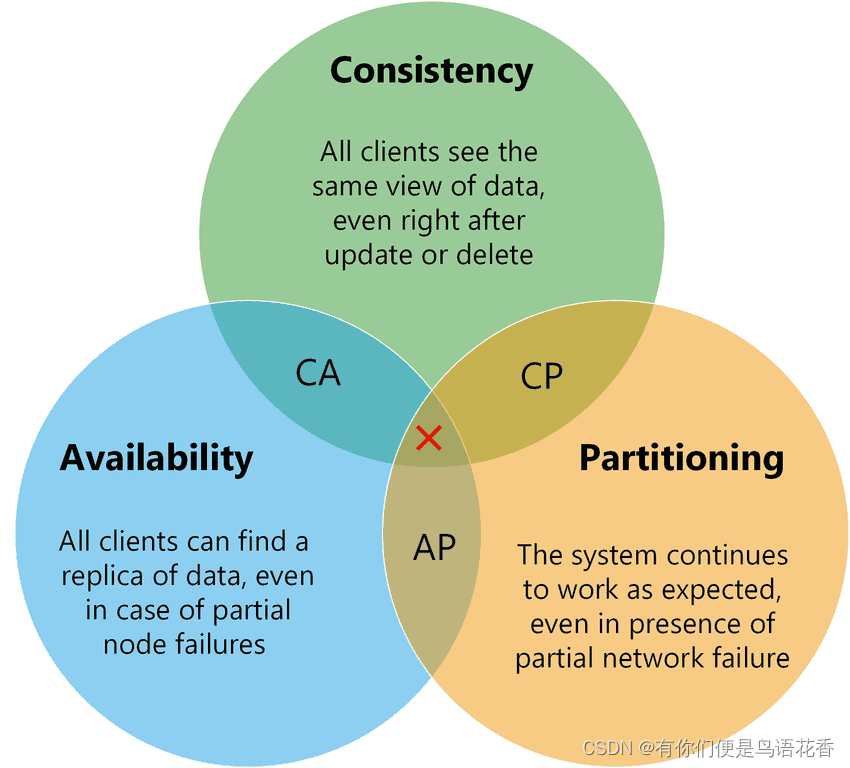
CAP理论是分布式系统中最重要的理论之一,它是由Eric Brewer于2000年提出的。CAP理论指出,在分布式系统中,一致性(Consistency)、**可用性(Availability)和分区容错性(Partition Tolerance)**这三个目标不可能同时满足,最多只能同时满足其中两个。
一致性指的是在分布式系统中的所有节点中,数据的状态是一致的。可用性指的是分布式系统在任何时候都能够对外提供服务。分区容错性指的是分布式系统在面对网络分区的情况下,仍然能够继续工作。
根据CAP理论,当分布式系统发生网络分区时,必须要在一致性和可用性之间做出选择。如果选择一致性,则在网络分区的情况下,分布式系统会暂停对外服务,直到网络分区恢复,所有节点的数据状态一致后,才能够继续对外提供服务。如果选择可用性,则在网络分区的情况下,分布式系统会继续对外提供服务,但是此时不同节点的数据状态可能不一致,需要后续的数据同步操作来保证数据一致性。
总之,CAP理论提醒我们,在设计分布式系统时,需要根据具体的业务需求和实际情况,权衡一致性和可用性之间的关系,并在此基础上选择合适的分布式系统架构和技术方案。
深入理解
CAP理论认为在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)这三个目标不可能同时满足,最多只能同时满足其中两个。具体来说,当分布式系统发生网络分区时,必须要在一致性和可用性之间做出选择。如果选择一致性,则在网络分区的情况下,分布式系统会暂停对外服务,直到网络分区恢复,所有节点的数据状态一致后,才能够继续对外提供服务。如果选择可用性,则在网络分区的情况下,分布式系统会继续对外提供服务,但是此时不同节点的数据状态可能不一致,需要后续的数据同步操作来保证数据一致性。
因此,在设计分布式系统时,需要根据具体的业务需求和实际情况,权衡一致性和可用性之间的关系,并在此基础上选择合适的分布式系统架构和技术方案。比如,对于金融、电商等对一致性要求比较高的系统,可以优先考虑一致性,而对于社交、游戏等对可用性要求比较高的系统,则可以优先考虑可用性。
举个例子,假设有一个在线银行系统,它需要处理用户的交易请求。这个系统对一致性和可用性都有一定的要求,但是在网络分区的情况下,需要做出权衡。
如果选择一致性,那么在网络分区的情况下,整个系统会暂停对外服务,直到所有节点的数据状态一致后,才能够继续对外提供服务。这样可以保证交易的一致性,但是会导致用户无法及时进行交易操作,影响用户体验。
如果选择可用性,那么在网络分区的情况下,系统会继续对外提供服务,但是此时不同节点的数据状态可能不一致,需要后续的数据同步操作来保证数据一致性。这样可以保证用户可以及时进行交易操作,但是可能会出现数据不一致的情况,需要后续的同步操作来解决。
因此,在设计这个在线银行系统时,需要根据业务需求和实际情况,权衡一致性和可用性之间的关系,并在此基础上选择合适的分布式系统架构和技术方案。比如,可以采用一些数据同步技术,如异步复制、基于版本的控制等,来保证数据的一致性。同时,也可以采用一些负载均衡、故障转移、自动扩缩容等技术,来提高系统的可用性。
三、CAP的应用应用
CAP理论是分布式系统设计中的一个重要理论,很多中间件都采用了CAP理论来支持分布式系统的设计。以下是一些常见的中间件和它们使用的CAP理论解决方案:
-
Apache Cassandra:Cassandra采用了分区容错性(Partition tolerance)和可用性(Availability)的解决方案,即在网络分区的情况下,系统会继续对外提供服务,但是此时不同节点的数据状态可能不一致,需要后续的数据同步操作来保证数据一致性。
-
Apache ZooKeeper:ZooKeeper采用了一致性(Consistency)和可用性(Availability)的解决方案,即在网络分区的情况下,整个系统会暂停对外服务,直到所有节点的数据状态一致后,才能够继续对外提供服务。
-
MongoDB:MongoDB采用了一致性(Consistency)和分区容错性(Partition tolerance)的解决方案,即在网络分区的情况下,整个系统会暂停对外服务,直到所有节点的数据状态一致后,才能够继续对外提供服务。同时,MongoDB还采用了一些数据同步技术,如副本集和分片等,来保证数据的一致性。
-
Apache Kafka:Kafka采用了分区容错性(Partition tolerance)和可用性(Availability)的解决方案,即在网络分区的情况下,系统会继续对外提供服务,但是此时不同节点的数据状态可能不一致,需要后续的数据同步操作来保证数据一致性。
-
Eureka对于CAP理论的运用主要体现在可用性(Availability)和分区容错性(Partition tolerance)方面。Eureka的设计目标之一就是保证服务的高可用性,即使在网络分区的情况下也能够继续对外提供服务。为了实现这一目标,Eureka采用了以下策略:
a). Eureka Server采用了集群化部署的方式,可以部署多个Eureka Server实例,以提高服务的可用性和容错性。
b). Eureka Client会定时向Eureka Server发送心跳,以保持服务的可用性。如果Eureka Server在一定时间内没有收到Eureka Client的心跳,则会将该服务实例标记为不可用,从而避免服务的调用失败。
c). Eureka Client会缓存Eureka Server返回的服务信息,以避免频繁向Eureka Server发送请求。同时,Eureka Client还会定时从Eureka Server获取最新的服务信息,以保证服务的可用性。
d). Eureka Server采用了自我保护机制,在一定时间内如果有大量服务实例失去联系,则会进入自我保护模式,避免误判导致服务不可用。
Eureka通过集群化部署、心跳检测、服务信息缓存和自我保护机制等策略,保证了服务的高可用性和分区容错性,从而实现了CAP理论中的可用性和分区容错性。