无论对于机器视觉,还是人工智能,相对从前,数据量发生了地覆天翻的变化。传统的运算框架不能满足现实的发展。人工智能影响不是一点一线,而是整个计算体系。
从AI/AR/VR芯片,到GPU数据处理,再到平台架构,框架编程,外部接口调用,都有巨大的变革。今天我们谈一下基于大批量数据的运算框架。

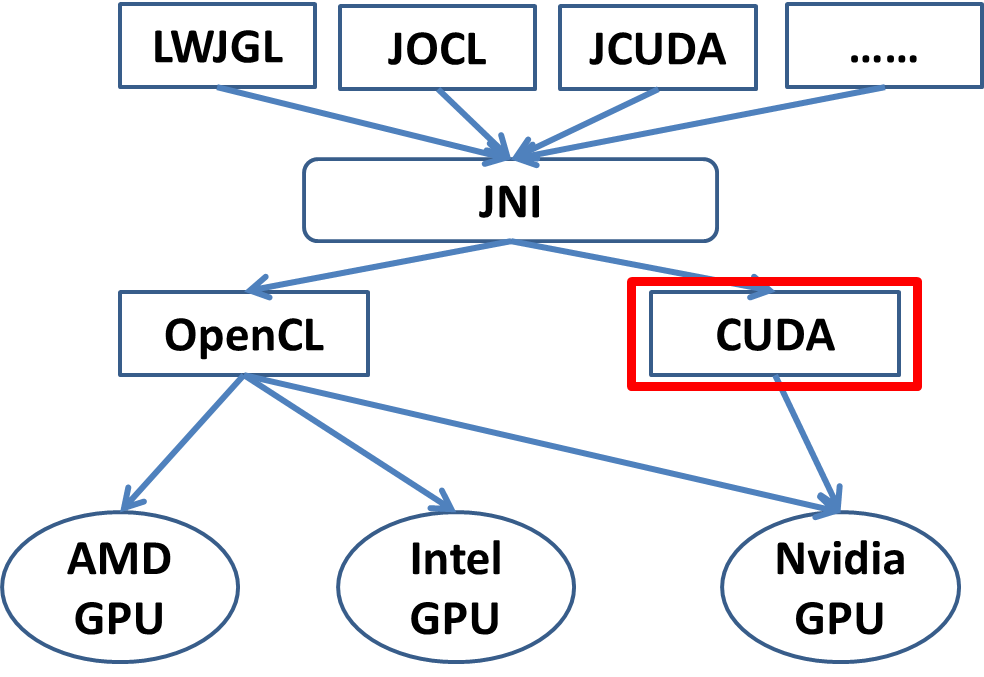
GPU的参与数据处理已经多年,多年发展过程中,GPU不过是硬件的支持(如下图),指令的提供,传统的工程师很难进行指令级的开发。所以,运算平台出现了,拓展了技术应用,便捷了软件开发。

下面讲述目前最广泛的两个运算平台,英伟达的CUDA和开放的OPENCL平台。
6.6.2.1、CUDA
CUDA(Compute Unified Device Architecture),CUDA™是由NVIDIA推出的并行计算架构,该架构使GPU解决复杂的计算问题。包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。

开发人员可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。编写出的程序可以在支持CUDA™的处理器上以超高性能运行。
计算行业从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。为打造这一全新的计算典范,NVIDIA™(英伟达™)发明了CUDA(Compute Unified Device Architecture,统一计算设备架构)这一编程模型。
6.6.2.1.1、应用
在应用程序中充分利用CPU和GPU各自的优点。该架构已应用于GeForce™(精视™)、ION™(翼扬™)、Quadro以及Tesla GPU(图形处理器)上,对应用程序开发人员来说,这是一个巨大的市场。
在消费级市场上,几乎每一款重要的消费级视频应用程序都已经使用CUDA加速或很快将会利用CUDA来加速,其中包括Elemental Technologies公司、MotionDSP公司以及LoiLo公司的产品。
在科研界,CUDA一直受到热捧。例如,CUDA现已能够对AMBER进行加速。AMBER是一款分子动力学模拟程序,全世界在学术界与制药企业中有超过60,000名研究人员使用该程序来加速新药的探索工作。

在金融市场,Numerix以及CompatibL针对一款全新的对手风险应用程序发布了CUDA支持并取得了18倍速度提升。Numerix为近400家金融机构所广泛使用。

CUDA的广泛应用造就了GPU计算专用Tesla GPU的崛起。全球财富五百强企业已经安装了700多个GPU集群,这些企业涉及各个领域,例如能源领域的斯伦贝谢与雪佛龙以及银行业的法国巴黎银行,包括阿里云。
GPU计算目前成为主流。在显卡硬件上,GPU将不仅仅是图形处理器,还是应用程序均可使用的通用并行处理器。

随着显卡的发展,GPU越来越强大,GPU为图像处理做了优化。计算上超越了通用的CPU。强大的芯片不能仅仅进行显示,因此NVIDIA推出CUDA,让显卡可以用于图像计算以外的目的。
CUDA架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。它是一个完整的GPGPU解决方案,提供了硬件的直接访问接口,而不必像传统方式一样必须依赖图形API接口来实现GPU的访问。
6.6.2.1.2、系统结构
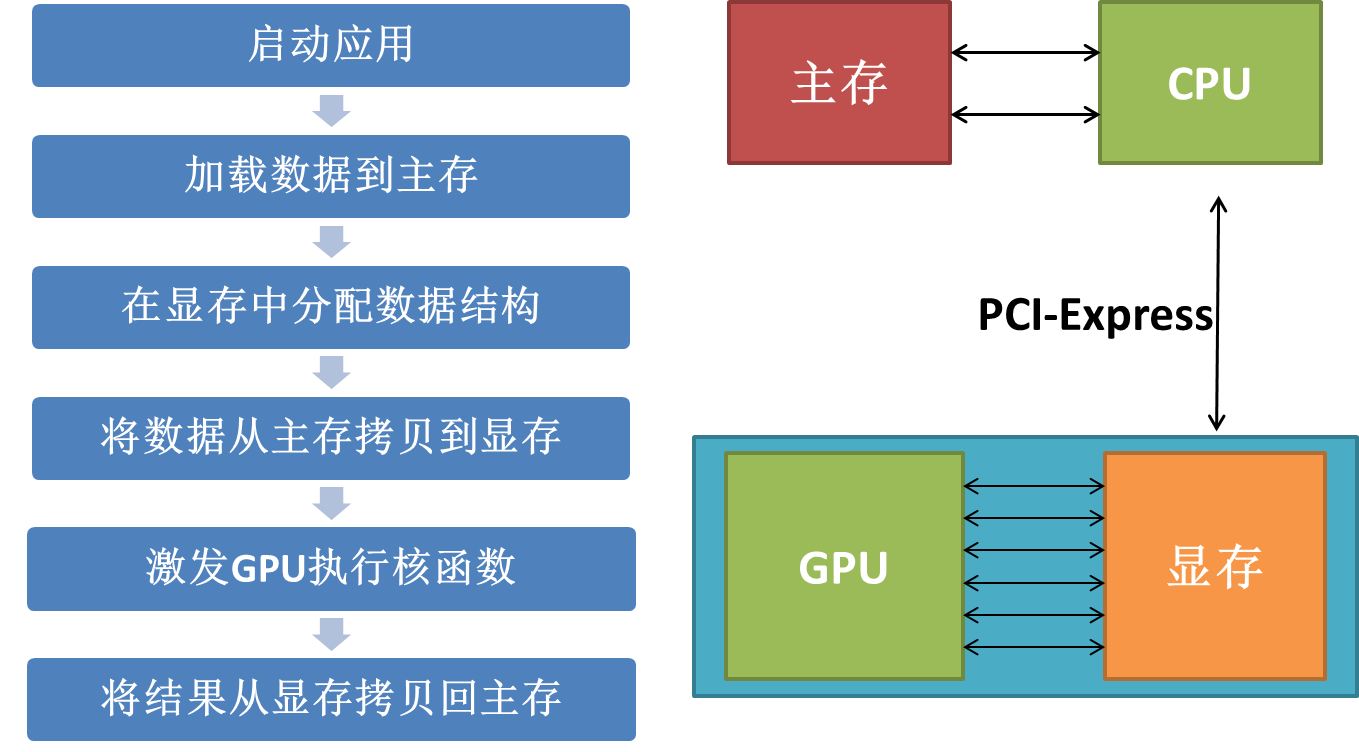
在架构上采用了一种全新的计算体系结构来使用GPU提供的硬件资源,从而给大规模的数据计算应用提供了一种比CPU更加强大的计算能力。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。

CUDA体系结构包含三部分:开发库、运行期环境和驱动。
开发库是基于CUDA技术提供的应用开发库。CUDA1。1版提供了两个标准的数学运算库——CUFFT(离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库解决的是典型的大规模并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。

运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型代码运行的物理位置不同,访问的资源不同,对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员通过运行期环境的编程接口实现各种类型的计算。
由于存在着多种GPU版本的NVidia显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境通过这一层来实现各种功能。基于CUDA开发的应用必须有NVIDIA CUDA-enable的硬件支持。
NVIDIA公司GPU运算事业部总经理Andy Keane在活动中表示:一个充满生命力的技术平台应该是开放的,CUDA未来也会向这个方向发展。由于CUDA的体系结构中有硬件抽象层的存在,因此今后也有可能发展成为一个通用的GPGPU标准接口,兼容不同厂商的GPU产品。

支持CUDA的GPU销量逾10亿,数以万计的开发人员正在使用免费的CUDA软件开发工具来解决各种问题。从视频与音频处理和物理效果模拟到石油天然气勘探、产品设计、医学成像以及科学研究,涵盖了各个领域。
6.6.2.1.3、核心
CUDA的核心有三个重要抽象概念: 线程组层次结构、共享存储器、屏蔽同步(barriersynchronization),轻松将其作为C语言的最小扩展级公开给程序员。

CUDA 软件堆栈由几层组成,一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime,还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻量级的驱动和Runtime 层面,因而提高性能。
6.6.2.1.4、其它
NVIDIA进军高性能计算领域,推出了Tesla&CUDA高性能计算系列解决方案,CUDA技术,一种基于NVIDIA图形处理器(GPU)上全新的并行计算体系架构,让科学家、工程师和其它专业技术人员能够解决以前无法解决的问题,作为一个专用高性能GPU计算解决方案,NVIDIA把超级计算能够带给任何工作站或服务器,以及标准、基于CPU的服务器集群。

CUDA是用于GPU计算的开发环境,是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对计算分配和管理。CUDA的架构中,计算不再像过去所谓的GPGPU架构那样必须将计算映射到图形API(OpenGL和Direct 3D)中,对于开发者来说,CUDA的开发门槛大大降低。CUDA编程基于C语言,任何有C语言基础的用户都很容易地开发CUDA的应用程序。

GPU的特点是处理密集型数据和并行数据计算,因此CUDA非常适合需要大规模并行计算的领域。CUDA除了可以用C、C++、JAVA、Python语言开发。广泛的应用在图形动画、科学计算、地质、生物、物理模拟等领域。
计算正在从CPU"中央处理"向CPU与GPU"协同处理"的方向发展。对应用程序开发商来说,英伟达™ CUDA™ 架构拥有庞大的用户群。
6.6.2.2、OPENCL
OpenCL(Open Computing Language,开放运算语言)是第一个面向异构系统并行编程的开放式、免费标准,也是一个统一的编程环境。
便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其它并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。

OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织Khronos Group掌管。

6.6.2.2.1、发展
OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和NVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。5个月后的2008年11月18日,该工作组完成了OpenCL 1。0规范的技术细节。2010年6月14日,OpenCL 1。1 发布。2011年11月15日,OpenCL 1。2 发布。2013年11月19日,OpenCL 2。0发布。目前,OpenCL最新版本是3。0。

2009年6月NVIDIA首家发布了支持OpenCL 1。0通用计算规范的驱动程序,支持Windows和Linux操作系统。
2009年8月初AMD首次发布了可支持IA处理器(x86和amd64/x64)的OpenCL SDK——ATI Stream SDK v2。0Beta,交由业界标准组织Khronos 进行审核。目前,该SDK更名为AMD APP SDK。
2012年2月,intel发布了The Intel® SDK for OpenCL* Applications 2012,支持OpenCL 1。1基于带HD4000/2500的显示核心的第三代酷睿CPU(i3,i5,i7)和GPU。
2013年6月,intel发布了第四代酷睿CPU haswell 其内置的HD4600/4400/4200 Iris(锐矩)5000/5100/pro 5200(自带eDRAM缓存)支持OpenCL 1。2(未来可能升级到OpenCL 2。0)
NVIDIA显卡方面 Geforce 8000\9000\100、GTX200-1000,RTX2000均支持OpenCL 1。0-1。2

AMD显卡方面 Radeon HD 4000-7000\Rx 200\Rx 300\RX 400-500/Fury系列,Vega系列 均支持OpenCL 1。0-1。2,除Radeon HD4000-6000系列外,其余均会支持OpenCL 2。0
移动平台方面目前高通adreno320/330/400系列/500系列提供了Android上的OpenCL1。2或者2。0支持,NVIDIA的Tegra K1也提供了OpenCL 支持。
6.6.2.2.2、支持
OpenCL工作组的成员包括:3Dlabs、AMD、苹果、ARM、Codeplay、爱立信、飞思卡尔、华为、HSA基金会、GraphicRemedy、IBM、Imagination Technologies、Intel、诺基亚、NVIDIA、摩托罗拉、QNX、高通,三星、Seaweed、德州仪器、布里斯托尔大学、瑞典Ume大学。像Intel、NVIDIA和AMD都是这个标准的支持者,不过微软并不在其列。目前,NVIDIA显卡对OpenCL技术支持较好。

在NVIDIA的Quadro、Geforce系列专业显卡中,能够使用OpenCL技术。只要显卡能够达到CUDA的要求,就能够正常使用OpenCL,以获得优异的CPU运算效率。
在AMD-ATI的Stream技术中(现已经改名为AMD APP并行加速技术),已经为日常使用、办公、游戏等提供物理加速。基于OpenCL标准开发,其中,ATI Radeon HD 4000-5000、AMD Radeon HD 6000系列同时支持ATI Stream和AMD APP(由于Stream基于CAL和Brook+语言开发,更适合VLIW5和VLIW4这样的SIMD架构),AMD Radeon HD7000和Radeon Rx 200系列支持AMD APP,运算效率较老架构提升十分明显。

6.6.2.2.3、API

OpenCL平台API:定义了宿主机程序发现OpenCL设备所用的函数以及这些函数的功能,还定义了OpenCL应用创建上下文的函数。
OpenCL运行时API:管理上下文来创建命令队列以及运行时发生的其它操作。例如,将命令提交到命令队列的函数就来自OpenCL运行时API。

OpenCL编程语言:编写内核代码的编程语言。基于ISO C99标准的一个扩展子集,通常称为OpenCL C编程语言。
6.6.2.2.4、总结
综合上述内容,形成OpenCL全景图(如下),首先是一个定义上下文的宿主机程序。上图中的上下文包含两个OpenCL设备、一个CPU和一个GPU。接下来定义了命令队列。

这里有两个队列,一个是面向GPU的有序命令队列,另一个是面向CPU的乱序命令队列。然后宿主机程序定义一个程序对象,这个程序对象编译后将为两个OpenCL设备(CPU和GPU)生成内核。
接下来宿主机程序定义程序所需的内存对象,并把它们映射到内核的参数。最后,宿主机程序将命令放入命令队列来执行这些内核。





