前言
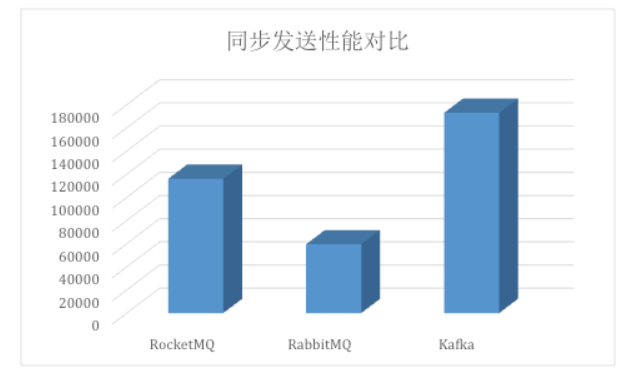
天下武功,唯快不破。同样的,kafka在消息队列领域,也是非常快的,这里的块指的是kafka在单位时间搬运的数据量大小,也就是吞吐量,下图是搬运网上的一个性能测试结果,在同步发送场景下,单机Kafka的吞吐量高达17.3w/s,不愧是高吞吐量消息中间件的行业老大。
那究竟是什么原因让kafka如此之快呢?这也是面试官非常喜欢问的问题。
四个原因
原因一:磁盘顺序读写
生产者发送数据到kafka集群中,最终会写入到磁盘中,会采用顺序写入的方式。消费者从kafka集群中获取数据时,也是采用顺序读的方式。
无论是机械磁盘还是固态硬盘SSD,顺序读写的速度都是远大于随机读写的。因为对于机械磁盘顺序读写省去了磁头频繁寻址和旋转盘片的开销。而固态硬盘就更加复杂,这里不展开阐述。
下图是网上关于读写方式的性能比较。
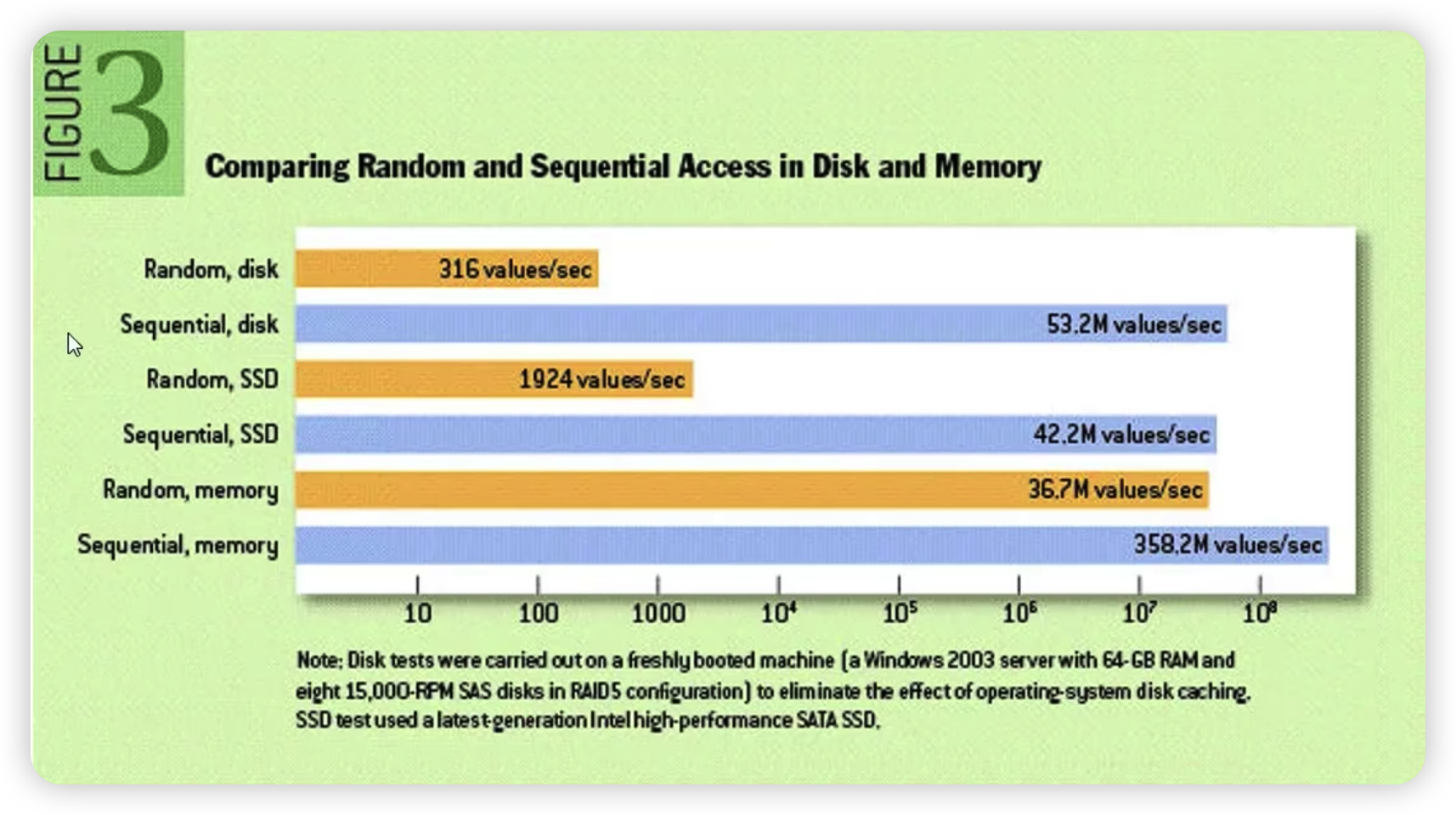
- 机械磁盘顺序读写 53M/s,随读写 316k/s
- 固态硬盘顺序读写 42M/s, 随机读写 1000k/s
因而,由于kafka一般使用机械磁盘存储消息,因为机械磁盘的价格远小于固态硬盘SSD。
原因二:PageCache页缓存技术
前面提到了kafka采用顺序读写写入到磁盘中,难道是直接kafka到磁盘吗,实际上不是的,中间多了一道操作系统的PageCache页缓存,可以理解为内存。
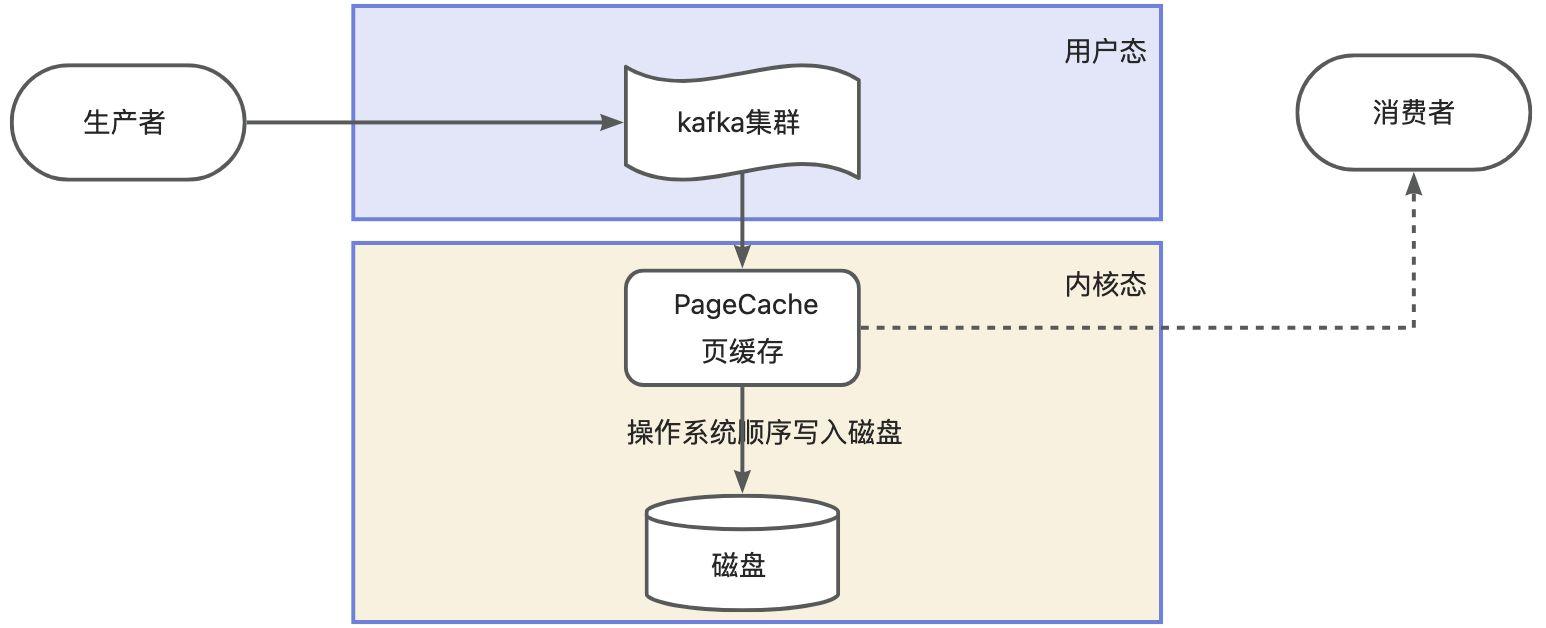
- 当kafka有写操作时,先将数据写入
PageCache中,然后在定时方式顺序写入到磁盘中。 - 当读操作发生时,先从
PageCache中查找,如果找不到,再去磁盘中读取。
通过页缓存技术,更近一步的提高了读写的性能。
原因三:零拷贝技术
kafka之所以快的另外一个原因是采用了零拷贝技术。
首先我们来看下从磁盘读取数据到网卡场景下,传统IO的整个过程,如下图所示:
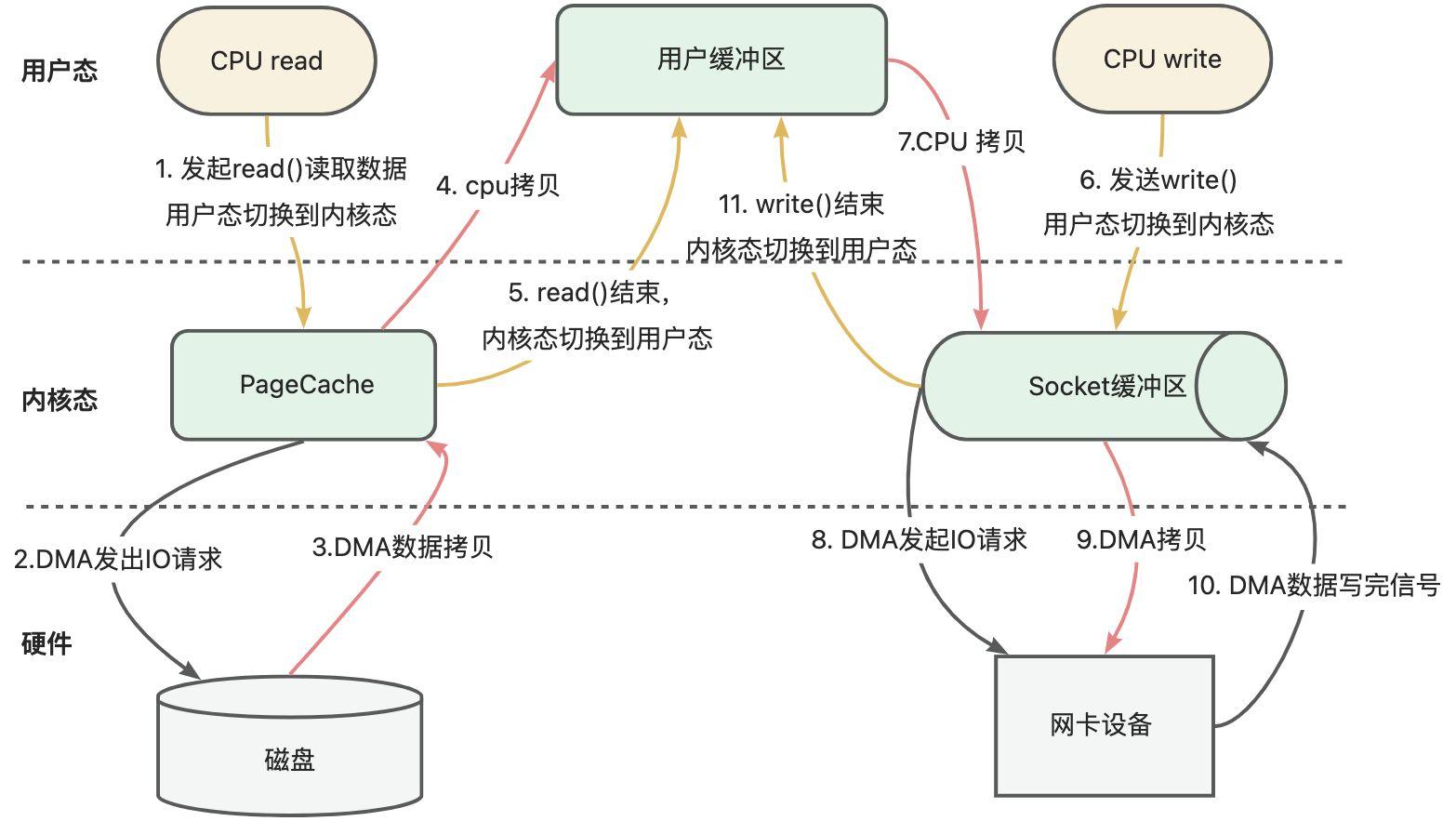
传统IO模型下,从磁盘读取数据,写到网卡设备中,经历了4次用户态和内核态之间的切换,以及4次数据的拷贝,包括CPU拷贝和DMA拷贝。这些操作都是十分损耗性能。
DMA, Direct Memory Access, 直接内存访问是一些计算机总线架构提供的功能,它能使数据从附加设备(如磁盘驱动器)直接发送到计算机主板的内存上。
那能否减少这样的切换和拷贝呢? 答案是肯定的,不知道大家发下没有,kafka的消息在应用层做任何转换,怎么存就怎么取,你看连序列化、反序列化都是在生产者和消费者做的。所以kafka采用了sendfile的零拷贝技术。
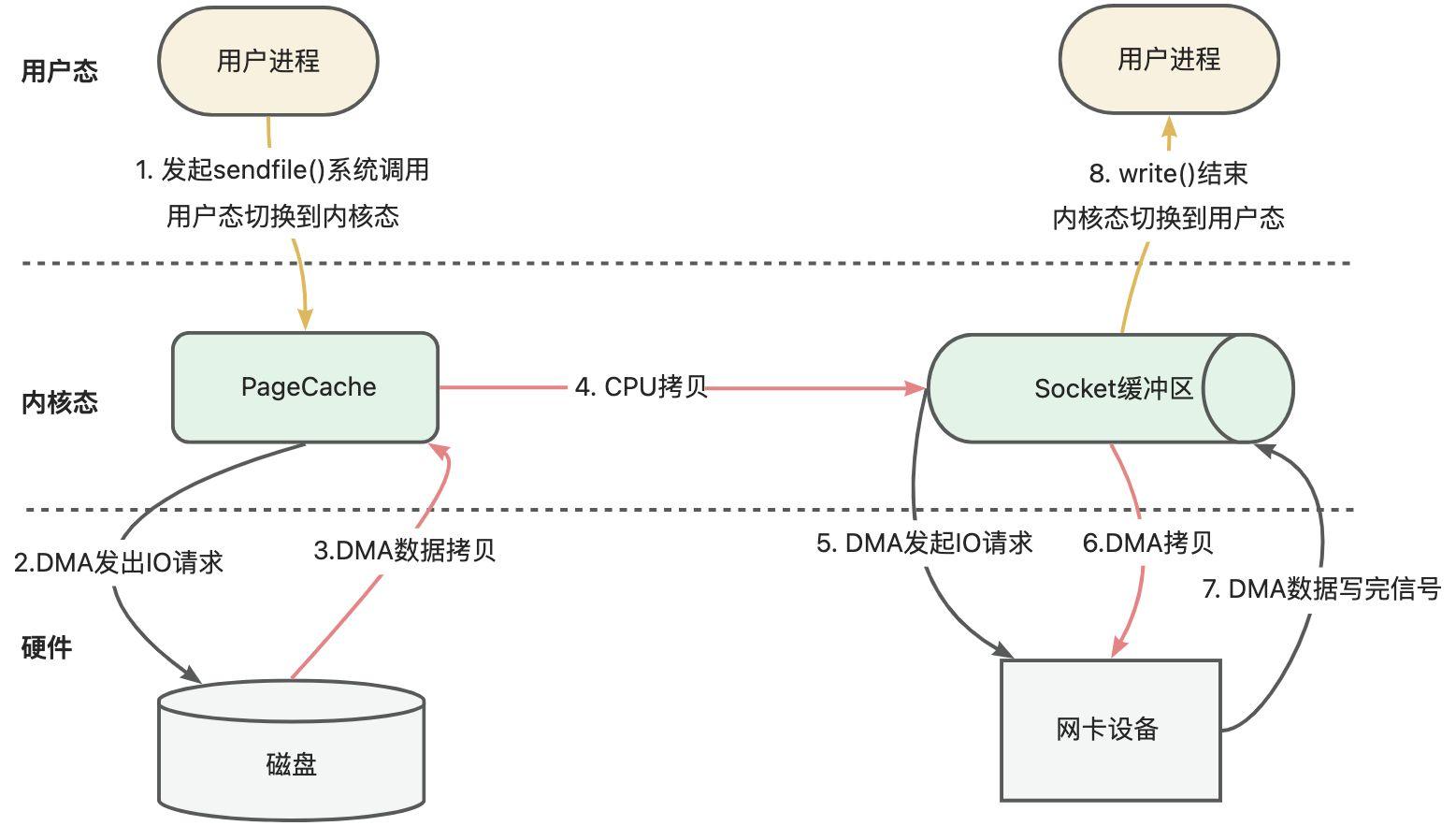
sendfile零拷贝技术在内核态将数据从PageCache拷贝到了Socket缓冲区,这样就大大减少了不同形态的切换以及拷贝。
所谓的零拷贝技术不是指不发生拷贝,而是在用户态没有进行拷贝。
原因四:kafka分区架构和批量操作
一方面kafka的集群架构采用了多分区技术,并行度高。另外一方面,kafka采用了批量操作。生产者发送的消息先发送到一个队列,然后有sender线程批量发送给kafka集群。
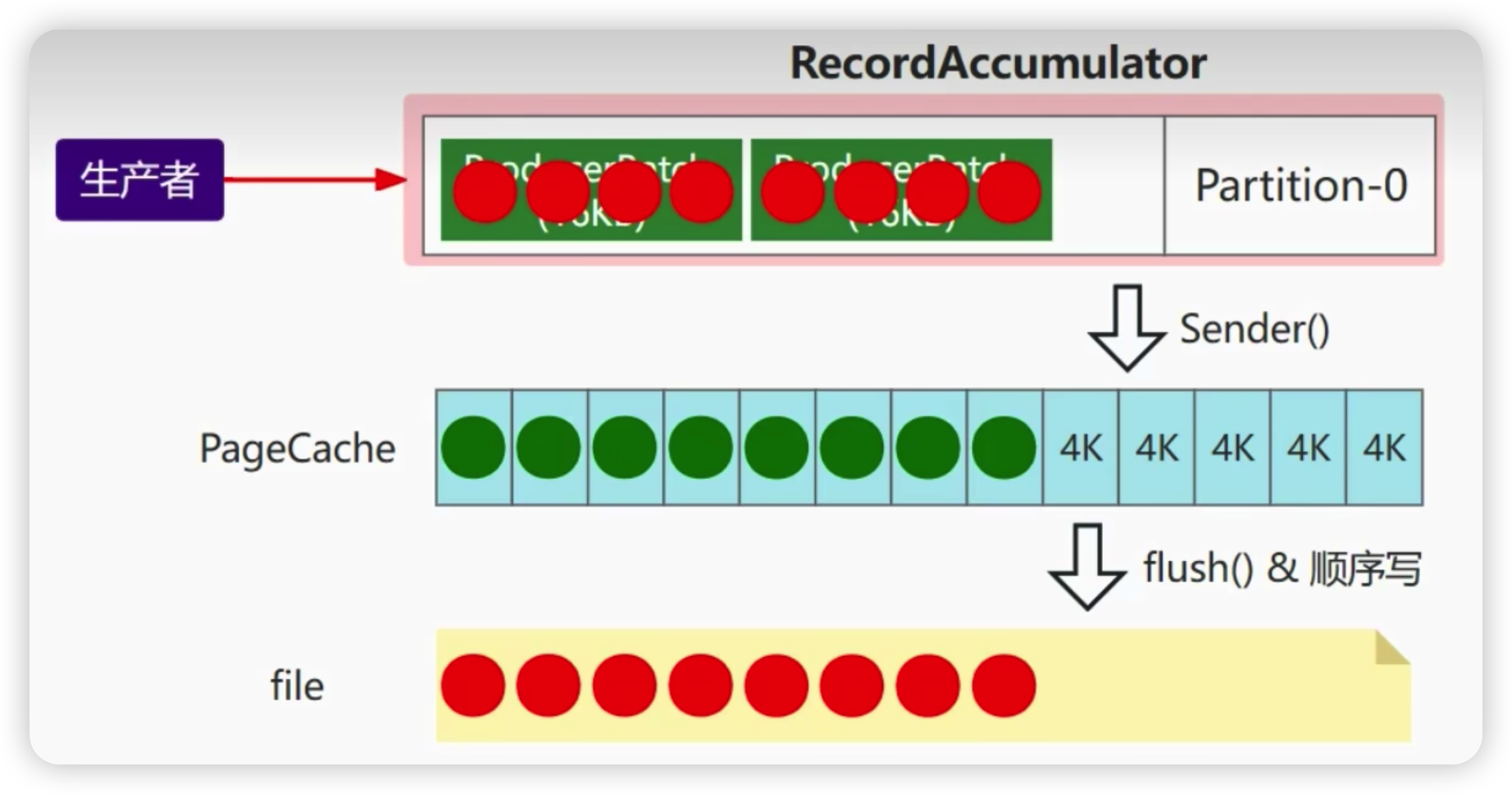
如何提高生产者的吞吐量?
kafka生产者提供的一些配置参数可以有助于提高生产者的吞吐量。
| 参数名称 | 描述 |
|---|---|
buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。适当增加该值,可以提高吞吐量。 |
batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
linger.ms | 如果数据迟迟未达到 batch.size,sender线程等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
compression.type | 指定消息的压缩方式,默认值为“none ",即默认情况下,消息不会被压缩。该参数还可以配置为 "gzip","snappy" 和 "lz4"。对消息进行压缩可以极大地减少网络传输、降低网络 I/O,从而提高整体的性能 。 |
如何提高消费者的吞吐量?
- 如果是Kafka消费能力不足,则可以考虑增加
Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数,并发度最高。 - 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少,使处理的数据小于生产的数据,也会造成数据积压。
fetch.max.bytes:默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝、对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。max.poll.records:一次poll拉取数据返回消息的最大条数,默认是500条
- 优化消费者代码处理的逻辑。
总结
本文总结了Kafka为什么快的原因,4个关键字,磁盘顺序读写,页缓存技术,零拷贝技术,Kafka本身分区机制和批量操作。我们抓住这4个关键字,有点到面地和面试官娓娓道来。
Kafka 在性能上确实是一骑绝尘,但在消息选型过程中,我们不仅仅要参考其性能,还有从功能性上来考虑,例如 RocketMQ 提供了丰富的消息检索功能、事务消息、消息消费重试、定时消息等。
通常在大数据、流式处理场景基本选用 Kafka,业务处理相关选择 RocketMQ更佳。