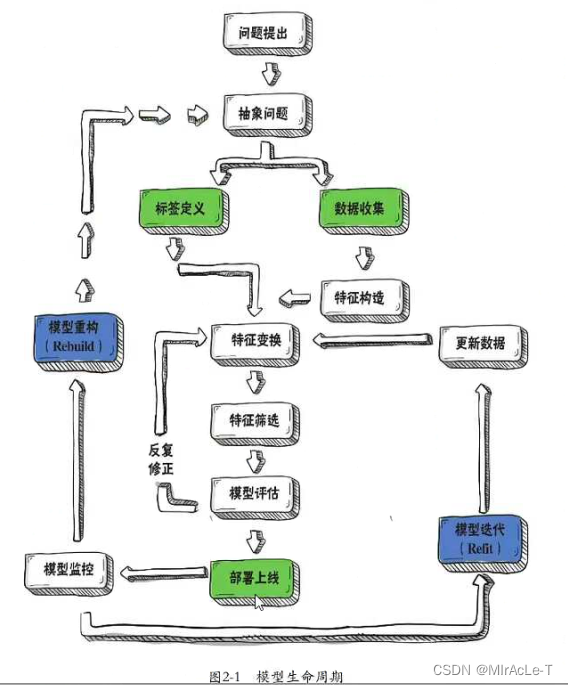
金融评分卡
网站:百融、同盾
1.导入
信贷评分卡是一种用于评估个人或企业申请贷款的工具,就像-个评分表-样。我们可以把它看作是银行或金融机构用来判断某人是否有资格获得贷款的一-种方式。
想象一下,你是一个银行家,有很多人向你申请贷款,比如个人贷款或房屋贷款。你需要决定哪些人更有可能按时还款,哪些人可能会有逾期还款或违约的风险。
那么,信贷评分卡就是一-种帮助你做出这个决策的工具。它通过考虑一系列与借款人相关的因素来给每个人打分。这些因素可以包括年龄、收入、职业、信用记录等等。
首先,我们需要收集大量的数据,比如以往的借款记录、个人信息和其他与还款能力相关的数据。然后,我们会使用统计和分析的方法,找出与还款能力最相关的因素。接下来,我们会为每个因素赋予- -定的权重。 这些权重代表了每个因素对于决定一个人是否有能力按时还款的重要性。例如,一个人的收入可能比年龄更重要,所以收入的权重会更高。
然后,当有新的借款人申请贷款时,我们会根据他们的个人信息和数据,计算他们的得分。这个得分可以告诉我们这个借款人有多大的潜在风险。
最后,我们会设定一个阈值, 比如说,如果得分超过某个特定值,那么我们会认为这个人是有资格获得贷款的。如果得分低于阈值,那么我们可能会拒绝他们的贷款申请,或者要求他们提供更多的担保或保证人。
2.评分卡的类别
●申请评分卡:申请评分卡用于评估借款人在提交贷款申请时的信用风险。当一个人向银行或金融机构申请贷款时,机构需要快速评估其信用状况。申请评分卡基于申请人提供的信息和数据(例如个人资料、收入、就业状况等), 根据历史数据和统计模型,给出一个评分来预测该借款人是否有可能按时还款。这样银行可以更快地作出决策,是否接受或拒绝贷款申请。
●行为评分卡:行为评分卡用于评估借款人或客户在贷款期间的行为表现和还款能力。它基于贷款人的还款历史、逾期记录、使用信用额度的方式等行为数据,以及其他因素,如收入和债务负担等,来预测借款人在未来的行为表现。行为评分卡对于银行或金融机构来说,是监控和管理贷款组合的重要工具,帮助它们识别风险客户并采取相应的措施。
●催收评分卡:催收评分卡是用于评估已逾期贷款客户的催收风险和催收策略的工具。当借款人未能按时偿还贷款时,银行或金融机构需要采取适当的催收措施来追回欠款。催收评分卡基于逾期客户的还款历史、欠款金额、与催收人员的沟通互动等因素,给出一个评分来预测催收的成功概率。这有助于银行制定催收策略,优化资源分配,提高催收效率。
3.评分卡常用模型
**逻辑回归: **
●优点:
简单而直观,易于解释和理解。计算效率高, 适用于大规模数据集。可以得到变量的系数,用于解释变量对目标变量的影响。
●缺点:
假设自变量与因变量之间的关系是线性的,无法捕捉非线性关系。对于变量之间存在多重共线性的情况,系数的解释可能会变得困难。对于特征工程的要求较高,需要对输入特征进行一定的预处理和转换。
决策树:
●优点:
适用于处理分类和回归问题,能够处理离散和连续特征。可以处理非线性关系和交互作用,不需要对数据进行过多的预处理。结果易于解释,可以生成可视化的决策树模型。
●缺点:
决策树容易过拟合,特别是当树的深度较大时。对于数据中的噪声和不规则性较敏感。容易产生复杂的树结构,导致模型的泛化能力下降。
XGBoost:
●优点:
在决策树的基础.上使用了集成学习的方法,提高了模型的准确性和稳定性。能够处理大规模数据集和高维特征。对于特征的选择和权重调整 具有自动化的能力。可以处理非线性关系、交互作用和缺失值。
●缺点:
相对于其他模型,XGBoos在计算方面的复杂性较高,训练时间可能会更长。对于数据质量的要求较高,对于异常值和噪声比较敏感。参数调整和模型调优可能需要一 些经验和领域知识。
4.特征构造
在评分卡模型的开发中,特征构造是极其关键的步骤,其作用是将分散在不同字段中的信息加以组合,从中提炼出有价值的、可用的信息进而进行评分卡模型的开发。
●求和:例如过去-段时间内的每月网购金额的总和
●比例:例如申请贷款的月还款本息与月收入的占比
●频率:例如过去一 -段时间内的境外消费次数
●平均:例如过去一段时间内平均每次信用 卡取现额度
案例:
对PPD. LogInfo. 3_ .1 _Training. Set字段的处理
由于绝大部分观测样本的时间跨度在半年内,所以我们选取半年内的时间切片,考虑以月为单位的时间切片,则可以衍生出30天、60天、90天、120天、 150天、 180天等多种选择。
同时,对于类别型变量,可以考虑构造如下计算逻辑:
●时间切片内的登录的次数
●时间切片内不同的登录方式的个数
●时间切片内不同登录方式的平均个数
5.特征分箱
不需要分箱的变量
对于类别型变量,如果取值个数较少,一般无需分箱
分箱结果的有序性
对于有序型变量(包括数值型和有序离散型,例如学历),分箱要求保证有序性
分箱的平衡性
在较严格的情况下,分箱后的每-箱的占比不能相差太大。- -般要求占比最小的占,占比不低于5%
分箱的单调性
在较严格的情况下,有序型变量分箱后每箱的坏样本率要求与箱呈单调关系。例如,将收入分为<5K, 5K~ 10K, 10k~20k, >20k后,坏样本率分别是20%,15%, 10%, 5%。或者,将学历分为{低于高中},{高中,大专},{本科,硕士}, {博士}后,坏样本率分别是15%,10%, 5%,1% 。
分箱的个数
通常要求分箱后,箱的个数不能太多,- -般在7或5个以内
分箱的优点
●稳定:分箱后,变量原始值在一定范围内的波动不会影响到评分结果
●缺失值处理:缺失值可以作为一个单独的箱,或者与其他值进行合并作为一个箱
●异常值处理:异常值可以和其他值合并作为-一个箱
●无需归一化:从数值型变为类别型,没有尺度的差异
分箱的缺点
●有一定的信息丢失:数值型变量在分箱后,变为取值有限的几个箱
●需要编码:分箱后的变量是类别型,不能直接带入逻辑回归模型中,需要进行一次数值编码
分箱的调整
每箱的坏样本率单调且需要同时包含好坏变量
6.WOE编码
编码操作是一种用数值代替非数值的操作,目的是为了让模型能够对其进行数学运算。例如,可以用3组0~255之间的整数来对颜色进行编码。在评分卡模型开发中,完成变量的分箱后所有的变量都变成了组别。此时需要对其进行编码才能下一步的建模。 评分卡模型里常用WOE (Weight of Evidence)的形式进行分箱后的编码。其计算公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ooGBcVCz-1686020274145)(C:\Users\Administrator\Desktop\b.png)]](https://img-blog.csdnimg.cn/3eb9ebe60f844ba488e4353912df28ca.png)
●优点
提高模型的性能:以每一箱中的相对全体的log odds的超出作为编码依据,能够提高模型的预测精度;
统一变量的尺度:经验上来看,WOE编码后的取值范围一般介意4与4之间;
分层抽样中的WOE不变性:如果建模需要对好坏样本进行分层抽样,则抽样后计算的WOE与未抽样计算的WOE是一致的;
●缺点
要求每箱中同时包含好坏样本:已在之前有过说明;
对多类别标签无效:如果目标变量取值个数超过2个,分箱后的WOE是无法计算的;
7.IV值
在评分卡模型中,衡量变量重要性的工作是-项必要的工作。在特征工程的初期我们往往能够衍生出数量较多的变量,但是并不能保证这些变量对于模型开发来说都很重要。通过衡量变量重要性,能够让我们从中挑选出相对更加重要的变量,为后续的分析提供降维的能力。
此处我们通过计算特征信息值(Information Value)来衡量其重要性。其计算公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AzHhOfXc-1686020274146)(C:\Users\Administrator\Desktop\c.png)]](https://img-blog.csdnimg.cn/8d7434112b3746fdaeb564853a9852e4.png)
单变量分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pp8ylMh3-1686020274147)(C:\Users\Administrator\Desktop\d.png)]](https://img-blog.csdnimg.cn/23d1f732de2147a6815d28c7e126c842.png)
多变量分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lpcYGxn8-1686020274148)(C:\Users\Administrator\Desktop\e.png)]](https://img-blog.csdnimg.cn/54ab1dc0c2ec41728fed2181be98ddd9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-68UBIVOG-1686020274149)(C:\Users\Administrator\Desktop\d1.png)]](https://img-blog.csdnimg.cn/be44f1c9acc546eeb1e6382f0ceae8df.png)
8.逻辑斯蒂回归建模
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SHLvQ0je-1686020274151)(C:\Users\Administrator\Desktop\f.png)]](https://img-blog.csdnimg.cn/8e60758cd9644a5eb19bdea23f91d145.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uD1IzX8p-1686020274152)(C:\Users\Administrator\Desktop\f1.png)]](https://img-blog.csdnimg.cn/f064dbe79d7a4eee95c719a88d252490.png)
处理方案:重新做特征选择
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iB9DDQte-1686020274153)(C:\Users\Administrator\Desktop\g.png)]](https://img-blog.csdnimg.cn/c1166c3e651346128f3250bfffc6826c.png)
9.尺度化
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vuha4Zyh-1686020274154)(C:\Users\Administrator\Desktop\h.png)]](https://img-blog.csdnimg.cn/ecd29c17cbc646a2a8d8d72f63b6b33f.png)
10.模型评估
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cd9Xh8Im-1686020274155)(C:\Users\Administrator\Desktop\j.png)]](https://img-blog.csdnimg.cn/46ac20d55c924cfc918cf58c16f32e20.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QPD1g165-1686020274156)(C:\Users\Administrator\Desktop\j1.png)]](https://img-blog.csdnimg.cn/0e78b274e4fc409f9e4e3f7fa6b8863e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IQOS11gE-1686020274157)(C:\Users\Administrator\Desktop\k.png)]](https://img-blog.csdnimg.cn/f2bb9f5a2018456a812c91ad4fd029e4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d8klexpf-1686020274159)(C:\Users\Administrator\Desktop\k1.png)]](https://img-blog.csdnimg.cn/267c0a577bfe4aaf9f71316ee773fb8c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mX5ZDwJR-1686020274160)(C:\Users\Administrator\Desktop\k2.png)]](https://img-blog.csdnimg.cn/cb49c56936d945d7890de80b7dc1f121.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fV6pQ8HJ-1686020274161)(C:\Users\Administrator\Desktop\k3.png)]](https://img-blog.csdnimg.cn/952817df611f48888ddd35e2a7e627f0.png)