作者:肖念康,东莞怡合达智能制造供应链资深 Java 开发工程师,主要负责公司内部 DevOps、代码托管平台、任务需求管理平台的研发及其他项目的管理,云原生的研究与开发工作。
公司简介

怡合达致力于自动化零部件研发、生产和销售,提供 FA 工厂自动化零部件一站式供应,怡合达深耕自动化设备行业,基于应用场景对自动化设备零部件进行标准化设计和分类选型,通过标准设定、产品开发、供应链管理、平台化运营,以信息和数字化为驱动,为自动化设备行业提供高品质、低成本、短交期的自动化零部件产品。
技术现状
- 在使用 Kubernetes 之前,公司一直是采用超融合传统虚拟机的方式来部署上线项目,这就导致公司资源浪费非常严重,每年单单在服务器的开销就大大增加。
- 项目在上线的过程中出错的几率非常大,并且难以排查,没有一套规范的流程,需要开发人员手动部署,导致人员消耗非常严重。
团队规模
目前公司拥有 3000+ 的员工,其中研发团队(运维,开发,测试,产品等)超过 300 人,在苏州,湖北都有研发团队。
背景介绍
目前行业正在向自动化、云原生靠近,传统的互联网模式已经无法满足大公司的业务需求了,为了让开发人员将更多的精力放在业务上,自动化部署、项目的全方位监控就变得越来越重要。
目前公司云原生是刚刚起步,很多东西需要去探索发现,所以技术上有很多欠缺,需要非常细致的理解各个组件的运行原理和模式。
拥抱云原生就意味着公司的 IT 层面将上升一个等级,原有的项目治理将完全摒弃,将会以一套全新的方式来全方位地治理项目,使用 Kubernetes 和容器化技术将减少服务的运维成本和项目的容错成本,为客户带来的使用体验也将提升一个层次。
选型说明
工具选型的过程
在使用 KubeSphere 之前,我们也使用了很多其他的项目,如 KubeOperator,DaoCloud,Choerodon等。但是在使用过程中发现,其他工具的功能并不是很完善,遇到问题很难排查,社区也不是很活跃,这就导致我们的使用成本和维护成本大大增加。
选择 KubeSphere 的原因
我通过博客和论坛发现了 KubeSphere,Issue 的提出与解决非常的完善和及时。KubeSphere 官网有很多案例与讲解,社区活跃度非常高。这不正是我想要的吗?
经过实践使用 KubeSphere 搭建的集群更加稳定,资源管控更加便捷,与同类云原生产品相比,KubeSphere 几乎实现了我们在生产环境会用到的所有功能。
于是我们就开始在测试环境搭建并使用,随后慢慢地向生产环境迁移。目前我们公司有三分一的项目已经迁移到 KubeSphere 平台上,并且回收了之前的旧服务器,大大提高了资源使用率。
实践过程
基础设施与部署架构
Kubernetes 与 KubeSphere 的搭建也非常简单,根据官方文档先下载 KubeKey, 使用 KubeKey 搭建就可以了。
目前我们使用私有环境来搭建 Kubernetes 与 KubeSphere,因为是在我们内部使用,所以不考虑在云上进行搭建。
基础服务器采用的是 Linux Centos 7,内核版本是 5.6。
在搭建 Kubernetes 集群时,我选择使用 Keepalived 和 HAproxy 创建高可用 Kubernetes 集群,其中包括两个负载均衡入口。

然后是 3 个 Master 节点,3 个 Worker 节点,一个 Etcd 集群,因为是多集群,我会为公司每个项目创建一个集群,所有我们单个集群分配的资源不是很多,当资源不够使用时需要进行申请。
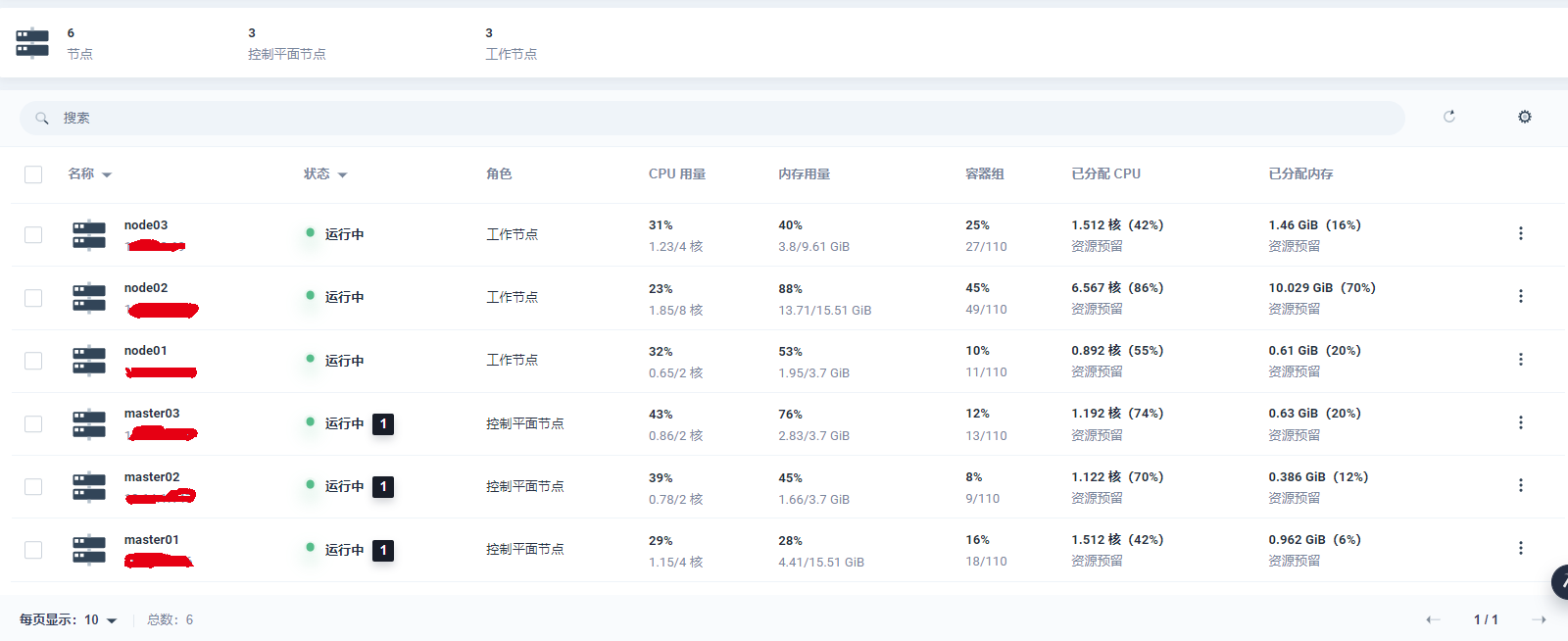
平台的存储与网络
平台的持久化存储我们使用的是第三方杉岩,这就需要对方来提供存储卷和创建存储系统空间,所以在这里就不做过多介绍。大家也可以使用开源的存储插件来做,KubeSphere 文档中提到了很多开源存储插件,使用起来也非常的方便。
在集群内部我们采用的是 Calico CNI 插件负责集群的内部通讯,当我们的服务部署至 Kubernetes 集群时会产生一个内部访问地址,这个地址在我们集群内是可以 ping 通和访问的,但外部无法访问。
所以在外部网络通讯方面我做了两套方案:
- 考虑到我们之前的项目使用 APISIX 作为网关路由,所以我们就在集群内搭建了 APISIX:

搭建方式也非常简单,创建一个 APISIX 模板,再创建一个应用就可以了:

创建完成之后集群内的项目就可以使用 APISIX 了,将 APISIX 开启对外访问,作为集群的唯一入口,接下来在服务中创建路由,就会在 APISIX 中自动生成一条路由规则与上游服务:

- 第二种方案则是使用负载均衡器 OpenELB,OpenELB 官方提供了三种模式,我们选用的是 Layer2 模式,因为 BGP 和 VIP 需要机器的支持,就暂时没有搭建,后续会考虑改用另外两种模式对外访问。
官方文档:https://openelb.io/docs/getting-started/usage/use-openelb-in-vip-mode/
安装和使用也很方便,可以直接在 KubeSphere 应用商店中选择安装,也可以在集群中通过 yaml 进行安装:

但是需要注意的是,通过应用商店进行安装一定要注意集群的内存空间是否充足,否则会导致集群监控组件异常。
安装完成之后,我们只需要开启 strictARP: true,并设置 EIP 池就可以了,然后我们在部署服务时加上注解:
annotations:lb.kubesphere.io/v1alpha1: openelbprotocol.openelb.kubesphere.io/v1alpha1: layer2eip.openelb.kubesphere.io/v1alpha2: eip-layer2-pool
将 type 改为:LoadBalance,就会在我们的 IP 池中获取一个对外访问的 IP 分配给服务进行对外访问了。
日志与监控
我们搭建了一套 EFK 的日志系统,通过 Filebeat 收集服务端的数据,再通过 Kafka 发送到 es 中,然后通过 Kibana 查询日志数据,另外我们增加了一套 SkyWalking,它会给我们生成一个链路 ID,这样我们就可以根据这个链路 ID 直接查找当前请求下的所有日志。
在监控方面除了 KubeSphere 自带的监控之外,我们还用了一套外部的监控系统:
- 主机层面:Prometheus + General
- 服务层面:SkyWalking
- 包括服状态的监控以及所有的告警
CI/CD
我们开启了 KubeSphere 的 DevOps 模块,里面集成了 Jenkins,流水线的构建,实现了项目从拉取代码,质量检查到项目部署一键化的流程。
在 DevOps 模块中用的是自定义 GitLab 仓库,如果是自己实践的话可以去 KubeSphere 应用商店中下载使用,在这里我就介绍一下自定义实现。
首先需要打开 KubeSphere 自带的 Jenkins,进入页面创建一个 GitLab 的凭证,然后在系统配置自定义 GitLab 的地址。
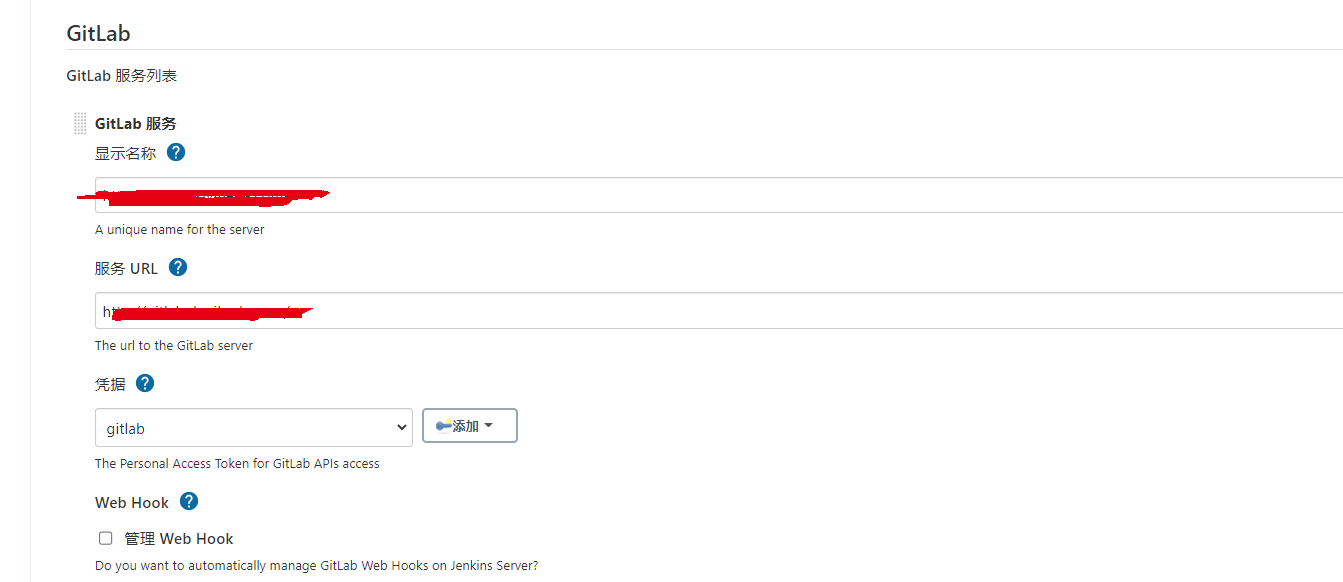
这里的凭据就是我们刚刚创建的 GitLab 凭据,地址就直接填自己仓库的地址,然后就可以在 KubeSphere 中看到刚刚填写的地址了。

我是根据官方文档创建的流水线,其中有些地方需要自己指定。
在 Jenkins 中是提供一个 Maven,在这里我需要改成自定义的 Maven,不然项目构建的时候会失败,我们只需要在 configMap 中修改 setting.xml 文件就可以了。
镜像仓库用的是自定义 Harbor 仓库,要在 Harbor 中先创建存放镜像的地址,然后创建权限,在 KubeSphere 中添加凭证就可以使用了。

在使用流水线之前一定要把 GitLab、Kubernetes、镜像仓库的凭证建好,后面直接使用就可以了。

一些前置的条件配置好之后就可以直接去创建流水线了。

运行后可以看到运行记录。

流水线跑完之后就可以在项目中看到之前部署的项目了。
包括服务和容器组,在里面就可以对项目进行管理了,包括负载均衡,网关,路由,扩容等一些操作。
使用效果
- 在使用 KubeSphere 之后,我们所有的项目都集中在一起了,管理起来方便很多,服务器的资源也很大程度的减少,在资金方面节省了很多。
- 项目上线现在只需要创建执行流水线就可以了,再根据定时任务定时执行,并且项目可以自动增加副本,项目启动失败会自动回滚到之前的版本。
- 在业务方面,接口的请求时间降低了,用户的使用体验也增加了不少,出现 bug 能够快速的定位并解决问题。
未来规划
未来我们将把公司内部系统与 KubeSphere 完全打通,成立云原生小组来负责云原生的研发工作。
公司的服务器资源将完全回收,将会以集群分配的方式管理项目,之后会自研一些插件和组件使用并进行开源。
对于 KubeSphere,我们也有一些建议:
- 希望文档能够在详细一点,有一些插件的文档说明只是大概的介绍了一下。
- 监控面板不是很细致,需要使用自定义的监控面板进行使用。
- 目前发现告警通知方面只能在通知聚到中配置钉钉一个地址,希望的是在每一个项目中都能够配置通知地址,这样每一个钉钉告警通知群就能够做到互不干扰。
希望 KubeSphere 未来会发展的越来越好!
本文由博客一文多发平台 OpenWrite 发布!