前言
本文对Fluid基础功能-数据编排能力进行原理解析。其中涉及到Fluid架构和k8s csi driver相关知识。建议先了解相关概念,
为了便于理解,本文使用JuiceFS作为后端runtime引擎。
原理概述
Fuild数据编排能力,主要是在云原生环境中,能让用户在使用远端存储时,只需简单声明几个对象,即可像使用本地存储一样简单。无需关心后端的繁琐配置,和数据存储、拉取过程。甚至无需关心后端的存储实现方式。
该能力主要利用dataSet和Runtime以及对应的controller组件实现。
dataset是用于告诉Fluid,在哪里能够找到所需要的数据,比如对于JuiceFS,指的是 JuiceFS 的子目录,是用户在 JuiceFS 文件系统中存储数据的目录。
runtime这里根据后端实际引擎不同,runtime的实现形式有多种,比如AlluxioRuntime、JuiceFSRuntime等,这些都是k8s的CRD。
以JuiceFSRuntime为例,它用于声明一个juiceFS的最小化集群,包括worker副本数量,worker的缓存形式(mem、ssd、hdd),worker的缓存大小等。runtime-controller根据该声明,部署相应的juiceFS组件。
用户使用时,只需要在pod中使用同名的pvc即可。
工作流程梳理
若字体看不清,可点击图片查看大图:
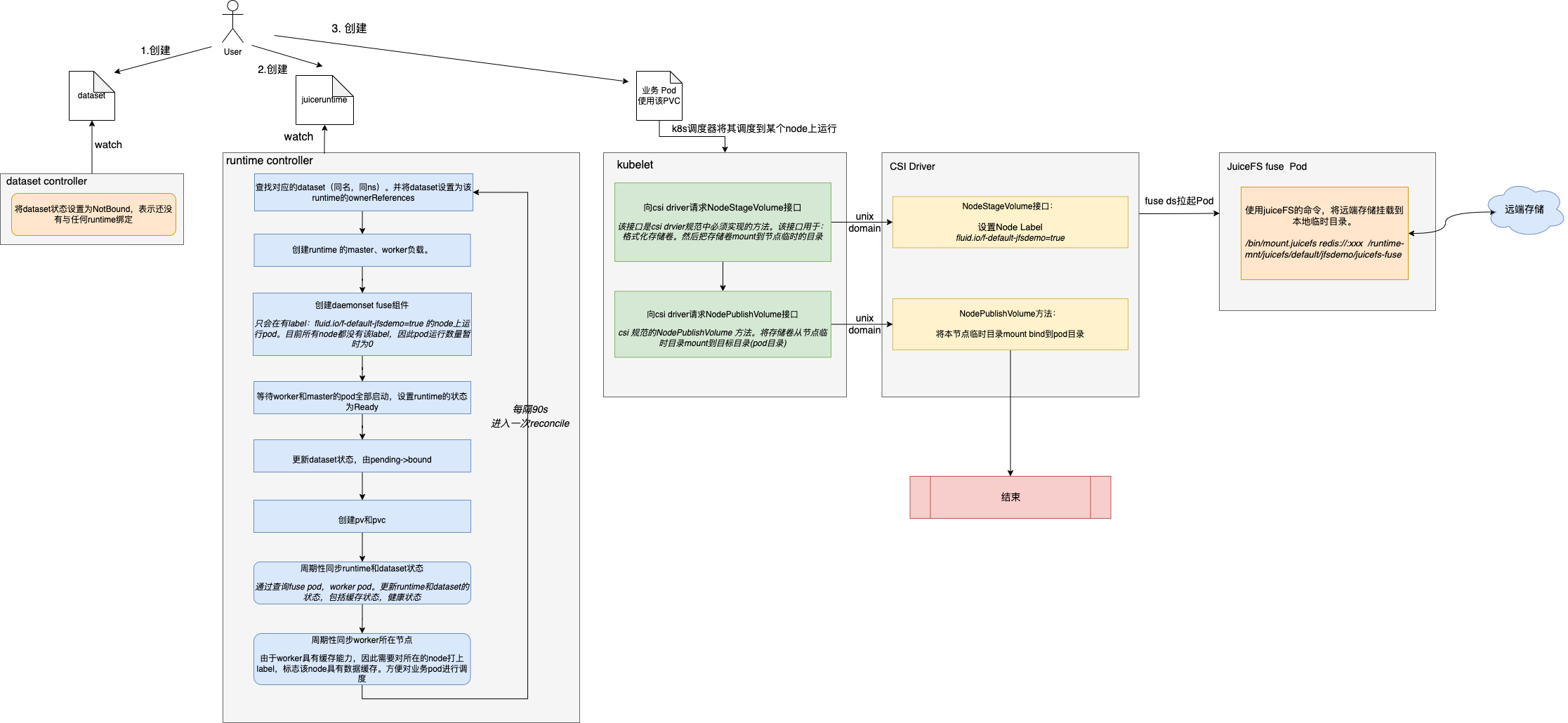
详细流程解析
一、用户创建Dataset
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:name: jfsdemo
spec:mounts:- name: testmountPoint: "juicefs:///demo"options:bucket: "<bucket>"mounts字段:
name:juiceFS中创建的文件系统名称
mountPoint:指的是 JuiceFS 的子目录,是用户在 JuiceFS 文件系统中存储数据的目录,以 juicefs:// 开头;如 juicefs:///demo 为 JuiceFS 文件系统的 /demo 子目录。
options.bucket:Bucket URL。例如使用 S3 作为对象存储,bucket 为对象存储URL,如果使用其他,比如minio,mysql,也为对应URL。
二、Dataset Controller处理Dataset
controller监听到dataset被创建,将dataset状态设置为NotBound,表示还没有与任何runtime绑定。
三、用户创建JuiceFSRuntime
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
metadata:name: jfsdemo
spec:replicas: 1tieredstore:levels:- mediumtype: MEMpath: /dev/shmquota: 40960mudiumtype:worker缓存形式,MEM,SSD,HDD
path:worker的缓存目录
quota:缓存大小,单位Mi
四、runtime controller处理JuiceFSRuntime
controller监听到JuiceFSRuntime被创建,开始一系列对于juiceFS 集群的创建操作。
1)查找对应的dataset(同名,同ns)。并将dataset设置为该runtime的ownerReferences。
...
if !utils.ContainsOwners(objectMeta.GetOwnerReferences(), dataset) {return r.AddOwnerAndRequeue(ctx, dataset)}
...2)创建runtime 的master负载。
根据runtime填入的参数,通过helm进行安装
valuefileName, err := j.generateJuicefsValueFile(runtime)
...found, err := helm.CheckRelease(j.name, j.namespace)
...return helm.InstallRelease(j.name, j.namespace, valuefileName, chartName)3)更新runtime的状态为NotReady
4)创建runtime的worker负载
根据runtime填入的参数,通过helm进行安装,同时设置pod 反亲和性,worker分散在不同节点
func (e *Helper) SetupWorkers(runtime base.RuntimeInterface,currentStatus datav1alpha1.RuntimeStatus,workers *appsv1.StatefulSet) (err error) {desireReplicas := runtime.Replicas()if *workers.Spec.Replicas != desireReplicas {// workerToUpdate, err := e.buildWorkersAffinity(workers)workerToUpdate, err := e.BuildWorkersAffinity(workers)if err != nil {return err}workerToUpdate.Spec.Replicas = &desireReplicaserr = e.client.Update(context.TODO(), workerToUpdate)if err != nil {return err}
5)创建daemonset fuse组件
且只会在有label:fluid.io/f-default-jfsdemo=true 的node上运行pod。目前所有node都没有该label,因此fuse 的ds虽然部署成功,但是pod运行数量暂时为0。什么时候会给node打上该label呢,继续往后看。
6)等待worker和master的pod全部启动,设置runtime的状态为Ready
func (j *JuiceFSEngine) CheckAndUpdateRuntimeStatus() (ready bool, err error) {......runtimeToUpdate.Status.WorkerNumberReady = int32(workers.Status.ReadyReplicas)runtimeToUpdate.Status.WorkerNumberUnavailable = int32(*workers.Spec.Replicas - workers.Status.ReadyReplicas)runtimeToUpdate.Status.WorkerNumberAvailable = int32(workers.Status.CurrentReplicas)if workers.Status.ReadyReplicas > 0 {if runtime.Replicas() == workers.Status.ReadyReplicas {runtimeToUpdate.Status.WorkerPhase = data.RuntimePhaseReadyworkerReady = true} else if workers.Status.ReadyReplicas >= 1 {runtimeToUpdate.Status.WorkerPhase = data.RuntimePhasePartialReadyworkerReady = true}7)更新dataset状态,由pending->bound
func (j *JuiceFSEngine) BindToDataset() (err error) {return j.UpdateDatasetStatus(datav1alpha1.BoundDatasetPhase)
}8)创建pv和pvc
controller接下来创建pv和pvc
创建pv
PersistentVolumeSource: v1.PersistentVolumeSource{CSI: &v1.CSIPersistentVolumeSource{Driver: common.CSIDriver,VolumeHandle: pvName,VolumeAttributes: map[string]string{common.FluidPath: mountPath,common.MountType: mountType,其中pv的参数需要注意:
driver:所使用的csi driver的名称。这个值必须与 CSI 驱动程序在 GetPluginInfoResponse 中返回的值相对应;CSI 驱动程序也使用该值来辨识哪些 PV 对象属于该 CSI 驱动程序。这里common.CSIDriver就是:fuse.csi.fluid.io
VolumeHandle:唯一标识卷的字符串值。 该值必须与 CSI 驱动在 CreateVolumeResponse 的 volume_id 字段中返回的值相对应;在所有对 CSI 卷驱动程序的调用中,引用该 CSI 卷时都使用此值作为 volume_id 参数
spec:
......csi:driver: fuse.csi.fluid.io //csi drivervolumeAttributes:fluid_path: /runtime-mnt/juicefs/default/jfsdemo/juicefs-fusemount_type: JuiceFSvolumeHandle: default-jfsdemopersistentVolumeReclaimPolicy: RetainstorageClassName: fluidvolumeMode: Filesystem9)周期性同步runtime和dataset状态
通过查询fuse pod,worker pod。更新runtime和dataset的状态。包括
根据查询worker pod的metrics监控信息,查询缓存状态。并更新runtime和dataset的缓存数据状态,缓存进度。
根据worker pod数量是否正常,设置runtime和dataset的状态是否健康。
10)同步worker所在节点
由于worker具有缓存能力,因此需要对所在的node打上label,标志该node具有数据缓存。方便对业务pod进行调度。
查询所有worker所在节点,并与当前已经打上缓存label的节点进行对比,worker所在节点没有label的,需要加上。worker不在节点上有label的,需要删除。
五、创建业务pod,并使用该pvc
apiVersion: v1
kind: Pod
metadata:name: demo-app
spec:containers:- name: demoimage: nginxvolumeMounts:- mountPath: /dataname: demovolumes:- name: demopersistentVolumeClaim:claimName: jfsdemok8s调度器将其调度到某个node上运行。将pod信息与node绑定,接下来该节点上的kubelet接手pod,开始pod的真正创建流程。
六、kubelet向csi driver请求NodeStageVolume
kubelet发现pod有pvc的需求,kubelet的volumemanager组件会根据pvc声明所使用的csi driver名称:fuse.csi.fluid.io。查询当前集群中注册的csi driver,一旦发现匹配,就根据注册的信息,向csi driver发送请求,让csi driver开始进行数据卷挂载。
请求的接口是:NodeStageVolume。该接口也是csi drvier规范中必须实现的方法。该接口用于:如果存储卷没有格式化,首先要格式化。然后把存储卷mount到一个临时的目录(这个目录通常是节点上的一个全局目录)。
kubelet代码:
k8s.io/kubernetes/pkg/volume/csi/csi_attacher.go
func (c *csiAttacher) MountDevice(spec *volume.Spec, devicePath string, deviceMountPath string) error {.....fsType := csiSource.FSTypeerr = csi.NodeStageVolume(ctx,csiSource.VolumeHandle,publishContext,deviceMountPath,fsType,accessMode,nodeStageSecrets,csiSource.VolumeAttributes,mountOptions)....}七、csi driver 设置Node label
fluid的csi driver接收到kubelet发送的NodeStageVolume请求后,设置所在Node的label:fluid.io/f-default-jfsdemo=true
fluid/pkg/csi/plugins/nodeserver.go
// 2. Label nodefuseLabelKey := common.LabelAnnotationFusePrefix + namespace + "-" + namevar labelsToModify common.LabelsToModifylabelsToModify.Add(fuseLabelKey, "true")node, err := kubeclient.GetNode(ns.client, ns.nodeId)if err != nil {glog.Errorf("NodeStageVolume: can't get node %s: %v", ns.nodeId, err)return nil, errors.Wrapf(err, "NodeStageVolume: can't get node %s", ns.nodeId)}if _, ok := node.Labels[fuseLabelKey]; !ok {_, err = utils.ChangeNodeLabelWithPatchMode(ns.client, node, labelsToModify)if err != nil {glog.Errorf("NodeStageVolume: error when patching labels on node %s: %v", ns.nodeId, err)return nil, errors.Wrapf(err, "NodeStageVolume: error when patching labels on node %s", ns.nodeId)}设置该label后,之前部署的fuse daemonset会检测到该node存在符合条件label,就会在node上拉起fuse pod。
八、juice fuse pod进行本地目录挂载
fuse pod在节点上启动后,会使用juiceFS的命令,将远端存储挂载到本地临时目录。
fuse内部执行命令:
/usr/local/bin/juicefs format --storage=mysql --bucket=mysql2.redis.svc.linux.local:3306/test --access-key=${ACCESS_KEY} --secret-key=${SECRET_KEY} ${METAURL} mysql/bin/mount.juicefs redis://:123456@mymaster,redis-0.redis.redis.svc.linux.local,redis-1.redis.redis.svc.linux.local,redis-2.redis.redis.svc.linux.local:26379/3 /runtime-mnt/juicefs/default/jfsdemo/juicefs-fuse /runtime-mnt/juicefs/default/jfsdemo/juicefs-fuse 就是本节点的临时存储目录。
九、kubelet向csi driver请求NodePublishVolume
csi 规范的NodePublishVolume 方法。将存储卷从节点临时目录mount到目标目录(pod目录)。
k8s.io/kubernetes/pkg/volume/csi/csi_mounter.go
func (c *csiMountMgr) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {err = csi.NodePublishVolume(ctx,volumeHandle,readOnly,deviceMountPath,dir,accessMode,publishContext,volAttribs,nodePublishSecrets,fsType,mountOptions,)
}十、csi driver 执行NodePublishVolume方法
fluid的csi driver接收到kubelet发送的NodePublishVolume请求后,将本节点临时目录mount bind到pod目录。
func (c *csiMountMgr) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {err = csi.NodePublishVolume(ctx,volumeHandle,readOnly,deviceMountPath,dir,accessMode,publishContext,volAttribs,nodePublishSecrets,fsType,mountOptions,)
}比如pod目录:/var/lib/kubelet/pods/15b00274-11f2-4dde-9fdf-e590a6284e20/volumes/kubernetes.io~csi/default-jfsdemo/mount
该目录也是在节点上,也通过docker -v的形式挂载到pod内部,因此该目录的改动也能够在pod内部感知到。
以上,就完成了将远端存储挂载到pod内部的操作。