文章目录
- 购置清单
- GPU选购参考指标
- CPU及主板选购参考
- 固态硬盘选择
- 参考教程及相关问答
- Reference
目标:构建一个深度学习个人工作站
组装性能: 组装好后先装了windows系统用鲁大师跑分,最终63w分,超越99%用户,其中GPU性能良好排名第5,在显示测试时一度达到1000+fps,实力非常能打!!!
购置清单
| 硬件 | 型号 | 数量 | 参考价格 |
|---|---|---|---|
| CPU | I7-9700k | 1 | 2899 |
| GPU | RTX 2080ti | 1 | 8999 |
| 内存 | 金士顿 DDR4 2666 8GB | 2 | 259 * 2 |
| 主板 | ASUS Z390-A | 1 | 1749 |
| 机箱 | Tt(Thermaltake) 启航者S5 | 1 | 139 |
| 电源 | 海盗船 850W 支持2080ti | 1 | 949 |
| SSD固态硬盘 | 三星 250GB M.2接口 860 EVO | 1 | 389 |
-
为什么不选择i7 8700+B360主板?
-
一个非常重要的问题就是:与i7 8700搭配的主板B360仅拥有1个PCU-E X16显卡插槽,具体参数参考链接 ,因此不支持多显卡技术。
-
未来如果需要跑大型神经网络实验需要利用两个显卡的算力时,就不再需要重新购买主板机箱重新搭建,可以在i7 9700k+Z390-a显卡主板机箱内直接加显卡,从而构建支持多显卡的高性能深度学习工作站。
-
CPU可支持内存条频率2666,选购内存条时需要注意频率可用
-
主板板型ATX板型,外型尺寸 30.5 x 24.4 cm,需要考虑可以放置下主板的机箱
GPU选购参考指标
-
GPU:
GPU的选购从高性价比出发和高性能出发,最后选择了RTX 2080ti 和 TITAN RTX两款型号。
-
高性价比 — RTX 2080ti
-
GIGABYTE GEFORCE RTX 2080ti
京东购买链接
-
-
高性能 — TITAN RTX
-
NVIDIA TITAN RTX
亚马逊Titan RTX 深度学习显卡 链接
-
-
Q:怎么选择一块做深度学习的GPU?(CUDA核心?时钟频率?RAM大小?)
A:针对不同神经网络架构,需要考虑显卡的参数优先级如下:
-
卷积神经网络以及Transformer模型(Convolutional networks and Transformers):
Tensor Cores > FLOPs > Memory Bandwidth > 16-bit capability
-
循环神经网络(Recurrent networks):
Memory Bandwidth > 16-bit capability > Tensor Cores > FLOPs
即如果我想要用于跑循环神经网络,我需要优先考虑显存带宽,然后是16位半精度计算能力,接下来是Tensor核,最后考虑32位浮点数计算能力。
-
-
RTX 2080ti和Titan RTX的重要参数性能对比如下:
参数 RTX 2080ti Titan RTX CUDA核心 4352个 4608个 显存容量 11GB 24GB 核心频率 1350/1635MHz 1770MHz
-
上图为NVIDIA各型号GPU性能对比,除去前三价格高达五六万的GPU, RTX 2080ti和TITAN RTX 已经是性价比最高的最适合用于搭建深度学习环境的机器(已用紫色框图标出)。
CPU及主板选购参考
-
CPU主要考虑intel i7 8700k和i7 9700k两个版本:
- 其中i7 8700k在京东英特尔官方旗舰店目前缺货,京东上的第三方卖家对i7 8700k的出价是2749,并由第三方卖家开发票并负责售后。
- 而i7 9700k在京东英特尔官方旗舰店有售,价格为2899,和主板一起搭配购买还可以省449,综合考虑,购买i7 9700k的性价比更高也更有保障。
-
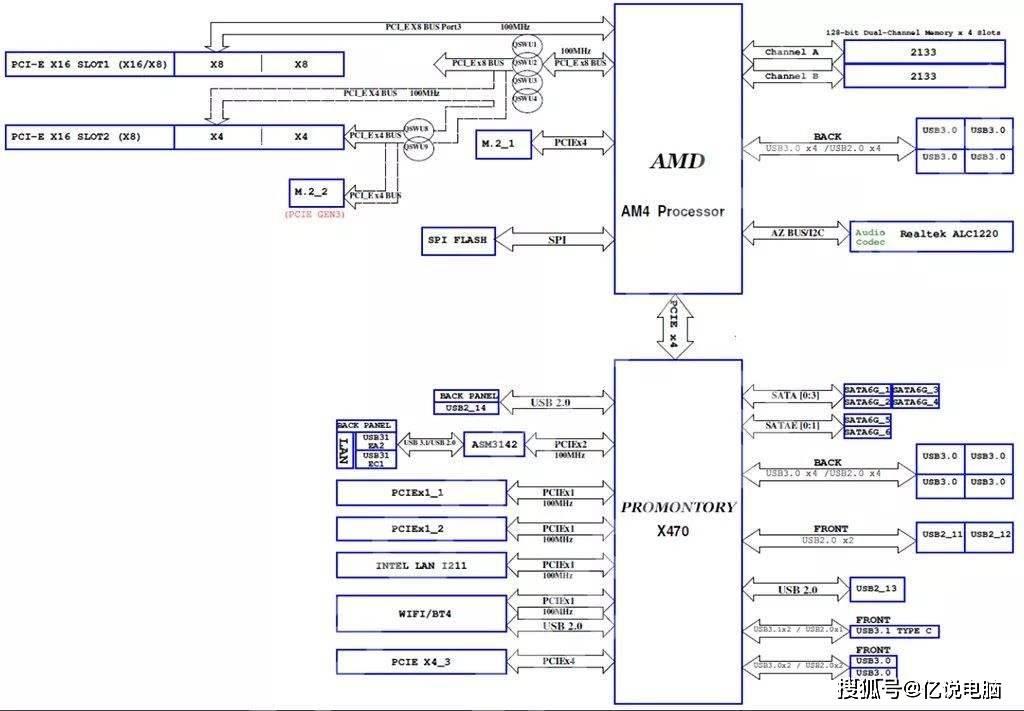
主板:
官方推荐主板 Z390 ,单独购买的话京东链接为1749元,和CPU一起搭配购买京东链接总价4199,可节省449元。
主板详细参数如下:
| 类型 | 规格 |
|---|---|
| 主板芯片 | Intel Z390 |
| CPU类型 | 第九代/第八代Core i9/i7/i5/i3/Pentium/Celeron |
| 内存类型 | 4 x DDR4 |
| 最大内存容量 | 64GB |
| PCI-E插槽 | 3×PCI-E X16显卡插槽,3×PCI-E X1插槽 |
| 多显卡技术 | 支持NVIDIA 2-Way SLI技术 |
| 存储接口 | 2×M.2接口,6×SATA III接口 |
| USB接口 | 4×USB3.1 Gen 2接口,4×USB3.1 Gen 1接口,6×USB2.0接口 |
| 视频接口 | 1个DP接口,1个HDMI接口 |
| 电源接口 | 1个8针,1个24针电源接口 |
| 其他接口 | 1×RJ45网络接口,1×光纤接口,5×音频接口,1×PS/2键鼠通用接口 |
| RAID功能 | 支持RAID 0,1,5,10 |
| 主板板型 | ATX板型 |
| 外形尺寸 | 30.5×24.4cm |
固态硬盘选择
我们挑选的与i7 9700k相对应的Z390-A主板配备有2×M.2接口,6×SATA III接口。(MSATA是专门针对笔记本用的固态硬盘,小尺寸,与我们工作站主板不适配),固态硬盘主要考虑存储容量和接口:
-
存储容量选择:240GB-256GB
这里我们搭建深度学习环境对固态硬盘的存储容量需求并不是很大,只需要安装linux系统以及在其上搭建环境,并安装一些必要的软件,因此购买240GB-256GB容量的SSD固态硬盘就已经够用。
-
接口:M.2接口
固态硬盘有三种常见接口:M.2 、 SATA 3.0 以及 MSATA
-
M.2 接口
M.2接口有两种通道,也是有速度差异的。PCI-E通道和sata通道。这也取决于自身的主板硬件的支持与否。PCI-E理论接口速度高达32Gbps!相比SATA 通道的6Gbps高了五倍多。在价格差别不大的情况下,尽可能选择M.2插口的固态硬盘。
-
SATA 3.0
这种接口为很多笔记本用户所选择的原因就在于通用性很强,既可以取代原装硬盘,也可以利用专用的光驱盒装在光驱位,理论速度6Gbps,对比32Gbps的M.2性能要弱很多。
-
参考教程及相关问答
参考教程链接_需要梯子
Q:多GPUs会让我的训练过程更快吗?
A:CNN和RNN可以很容易做并行化,但是包含transformer的全连接神经网络并不能直接做并行化,需要由专门的算法使其能够在GPU上执行。
现在很多开源库如TensorFlow和PyTorch可以为循环神经网络和卷积神经网络做并行化。针对卷积,你可以看到2/3/4个GPU带来的大约1.9倍/2.8倍/3.5倍的提速。对于循环神经网络,序列长度是针对NLP问题最重要的参数,与卷积神经网络相比会得到一个相似或稍弱的速度提升效果。
全连接网络,包括transformer,在数据并行化方面性能很差需要更高级的算法来对这部分的网络进行加速。如果你想要运行transformer在多GPUs上,你应该先尝试在一个GPU上运行它并观察是否运算得更快。
Q:NVIDIA的利弊?
Pros:NVIDIA的标准库使得在CUDA上构建第一个深度学习库非常简单,因为AMD的OpenCL显卡就没有这样强有力的标准库。这个早期的优势和NVIDIA的强力社区支持相结合使得CUDA社区增长扩大得非常快。
Cons:NVIDIA的新政策是在“数据中心(data center)”使用CUDA只允许在Tesla型号的GPUs上运行,不允许GTX或RTX系列。但关于数据中心也没有明确的定义。而Tesla卡花费10倍价格并不能带来足够的性能和速度提升。
Reference
Titan RTX评测 _ CV任务
6200美元,高性价比构建3块2080Ti的强大工作站
这一篇文章有提到一个重点:“请购买 after-market GPU(如 EVGA 或 MSI),而不是英伟达 Founders Edition。”
7000美元,搭建4块2080Ti的深度学习工作站
RTX 2080时代,如何打造属于自己的深度学习机器