什么是超参数?
今天,隐藏着数学世界的算法只需要几行代码就可以训练出来。它们的成功首先取决于训练的数据,然后取决于用户使用的超参数。这些超参数是什么?
超参数是用户定义的值,如kNN中的k和Ridge和Lasso回归中的alpha。它们严格控制模型的拟合,这意味着,对于每个数据集,都有一组唯一的最优超参数有待发现。最基本的方法便是根据直觉和经验随机尝试不同的值。然而,正如您可能猜到的那样,当有许多超参数需要调优时,这个方法很快就会变得无用。
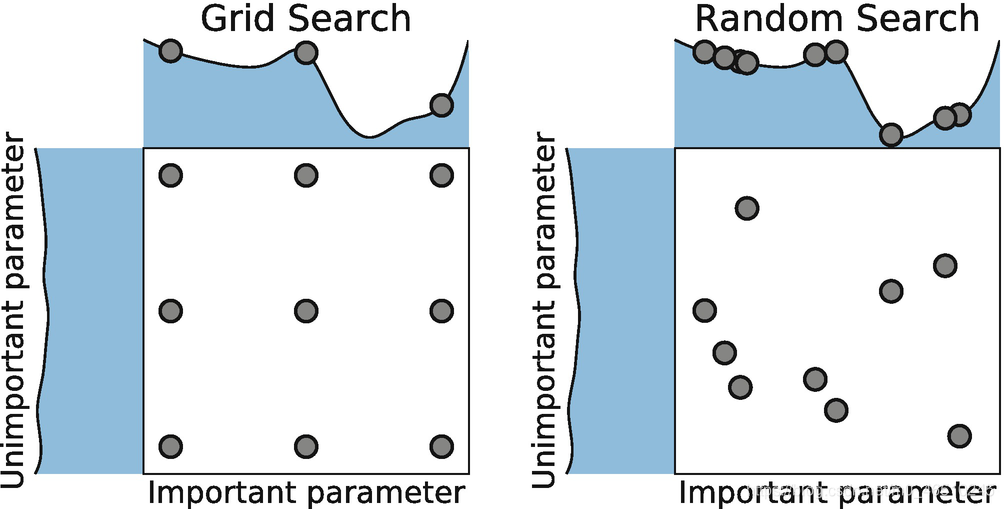
今天将介绍两种自动超参数优化方法:随机搜索和网格搜索。给定一组模型的所有超参数的可能值,网格搜索使用这些超参数的每一个组合来匹配模型。更重要的是,在每个匹配中,网格搜索使用交叉验证来解释过拟合。在尝试了所有的组合之后,搜索将保留导致最佳分数的参数,以便您可以使用它们来构建最终的模型。
随机搜索采用的方法与网格稍有不同。它不是详尽地尝试超参数的每一个单独组合,这在计算上可能是昂贵和耗时的,它随机抽样超参数,并试图接近最好的集合。
如果人工编写这种测试方法,会非常的费力,幸好Scikit-learn提供了GridSearchCV和RandomizedSearchCV类,使这个过程变得轻而易举。今天,你将了解他们的一切!
准备数据
我们将对爱荷华州住房数据集(https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data)的随机森林回归模型进行调整。我之所以选择随机森林,是因为它有足够大的超参数,使本指南的信息更加丰富,但您将学习的过程可以应用于Sklearn API中的任何模型。所以,让我们开始:
houses_train = pd.read_csv("data/train.csv")
houses_test = pd.read_csv("data/test.csv")houses_train.head()
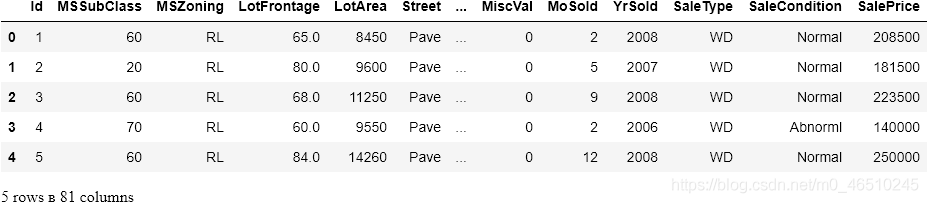
目标是SalePrice。为简单起见,我将只选择数字特性:
X = houses_train.select_dtypes(include="number").drop("SalePrice", axis=1)
y = houses_train.SalePriceX_test = houses_test.select_dtypes(include="number")
首先,训练集和测试集都包含缺失值。我们将使用SimpleImputer来处理它们:
from sklearn.impute import SimpleImputer# Impute both train and test sets
imputer = SimpleImputer(strategy="mean")
X = imputer.fit_transform(X)
X_test = imputer.fit_transform(X_test)
现在,让我们用默认参数拟合一个基本的RandomForestRegressor。由于我们将只将测试集用于最终评估,我将使用训练数据创建一个单独的验证集:
%%timefrom sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_splitX_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3)# Fit a base model
forest = RandomForestRegressor()_ = forest.fit(X_train, y_train)>>> print(f"R2 for training set: {forest.score(X_train, y_train)}")
>>> print(f"R2 for validation set: {forest.score(X_valid, y_valid)}\n")R2 for training set: 0.9785951576271396
R2 for validation set: 0.832622375495487Wall time: 1.71 s
注意:本文的主要重点是如何执行超参数调优。我们不会担心其他问题,如过拟合或特征工程,因为这里我们要说明的是:如何使用随机和网格搜索,以便您可以在现实生活中应用自动超参数调优。
我们在测试集上得到了R2的0.83。我们只使用默认参数来拟合回归变量,这些参数是:
>>> forest.get_params(){'bootstrap': True,'ccp_alpha': 0.0,'criterion': 'mse','max_depth': None,'max_features': 'auto','max_leaf_nodes': None,'max_samples': None,'min_impurity_decrease': 0.0,'min_impurity_split': None,'min_samples_leaf': 1,'min_samples_split': 2,'min_weight_fraction_leaf': 0.0,'n_estimators': 100,'n_jobs': None,'oob_score': False,'random_state': None,'verbose': 0,'warm_start': False}
有很多超参数。我们不会调整所有的内容,而是只关注最重要的内容。具体地说:
n_esimators:要使用的树的数量
max_feauters:每个节点拆分时要使用的特性数量
max_depth:每棵树上的叶子数量
min_samples_split:分裂内部节点所需的最小样本数
min_samples_leaf:每个叶子中的最小样本数量
bootstrap:取样方法,是否替换。
网格搜索和随机搜索都试图为每个超参数找到最优值。让我们先看看随机搜索的实际情况。
随机搜索Sklearn RandomizedSearchCV
Scikit-learn提供RandomizedSearchCV类实现随机搜索。它需要两个参数来建立:一个估计器和超参数的可能值集,称为参数网格或空间。让我们为我们的随机森林模型定义这个参数网格:
n_estimators = np.arange(100, 2000, step=100)
max_features = ["auto", "sqrt", "log2"]
max_depth = list(np.arange(10, 100, step=10)) + [None]
min_samples_split = np.arange(2, 10, step=2)
min_samples_leaf = [1, 2, 4]
bootstrap = [True, False]param_grid = {"n_estimators": n_estimators,"max_features": max_features,"max_depth": max_depth,"min_samples_split": min_samples_split,"min_samples_leaf": min_samples_leaf,"bootstrap": bootstrap,
}>>> param_grid{'n_estimators': array([ 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100,1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900]),'max_features': ['auto', 'sqrt', 'log2'],'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, None],'min_samples_split': array([2, 4, 6, 8]),'min_samples_leaf': [1, 2, 4],'bootstrap': [True, False]}
这个参数网格字典应该在模型文档中出现的语法中有超参数作为键。可能的值可以以数组的形式给出。
现在,让我们最后从sklearn导入RandomizedSearchCV。model_selection并实例化它:
from sklearn.model_selection import RandomizedSearchCVforest = RandomForestRegressor()random_cv = RandomizedSearchCV(forest, param_grid, n_iter=100, cv=3, scoring="r2", n_jobs=-1
)
除可接受的估计量和参数网格外,还具有n_iter参数。它控制了我们在搜索中允许的超参数组合的随机选择的迭代次数。我们将其设置为100,因此它将随机抽样100个组合并返回最好的分数。我们也使用三折交叉验证与决定系数作为评分,这是默认的。你可以从sklearn.metrics.SCORERS.keys()中传递任何其他得分函数。现在让我们开始这个过程:
注意,因为随机搜索执行交叉验证,所以我们可以将它作为一个整体来适应训练数据。由于交叉验证的工作方式,它将为训练和验证创建单独的设置。另外,我将n_jobs设置为-1,以使用我的机器上的所有内核。
%%time_ = random_cv.fit(X, y)>>> print("Best params:\n")
>>> print(random_cv.best_params_)Best params:{'n_estimators': 800, 'min_samples_split': 4,
'min_samples_leaf': 1, 'max_features': 'sqrt',
'max_depth': 20, 'bootstrap': False}Wall time: 16min 56s
经过~17分钟的训练后,可以使用.best_params_属性访问找到的最佳参数。我们也可以看到最好的分数:
>>> random_cv.best_score_0.8690868090696587
我们得到了87%左右的决定系数比基础模型提高了4%
Sklearn GridSearchCV
你永远不要根据RandomSearchCV的结果来选择你的超参数。只使用它来缩小每个超参数的值范围,以便您可以为GridSearchCV提供更好的参数网格。
你会问,为什么不从一开始就使用GridSearchCV呢?看看初始参数网格:
n_iterations = 1for value in param_grid.values():n_iterations *= len(value)>>> n_iterations13680
有13680个可能的超参数组合和3倍CV, GridSearchCV将必须适合随机森林41040次。使用RandomizedGridSearchCV,我们得到了相当好的分数,并且只需要100 * 3 = 300 次训练。
现在,是时候在之前的基础上创建一个新的参数网格,并将其提供给GridSearchCV:
new_params = {"n_estimators": [650, 700, 750, 800, 850, 900, 950, 1000],"max_features": ['sqrt'],"max_depth": [10, 15, 20, 25, 30],"min_samples_split": [2, 4, 6],"min_samples_leaf": [1, 2],"bootstrap": [False],
}
这次我们有:
n_iterations = 1for value in new_params.values():n_iterations *= len(value)>>> n_iterations240
240种组合,这还是很多,但是比起之前的计算已经少很多了。让我们导入GridSearchCV并实例化它:
from sklearn.model_selection import GridSearchCVforest = RandomForestRegressor()grid_cv = GridSearchCV(forest, new_params, n_jobs=-1)
我不需要指定评分和CV,因为我们使用的是默认设置,所以不需要指定。让我们适应并等待:
%%time_ = grid_cv.fit(X, y)print('Best params:\n')
print(grid_cv.best_params_, '\n')
Best params:{'bootstrap': False, 'max_depth': 15, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 950} Wall time: 35min 18s
35分钟后,我们得到了以上的分数,这一次——确实是最优的分数。让我们看看他们与RandomizedSearchCV有多少不同:
>>> grid_cv.best_score_0.8696576413066612
你感到惊讶吗?我也是。结果的差别很小。然而,这可能只是给定数据集的一个特定情况。
当您在实践中使用需要大量计算的模型时,最好得到随机搜索的结果,并在更小的范围内在网格搜索中验证它们。
结论
从上面看您可能会认为这一切都很棒。 如果我们使用了以上的方法对超参数进行调整就可以不必再去看超参数的实际用途,并且可以找到它们的最佳值。 但是这种自动化需要付出巨大的代价:计算量大且费时。
您可能会像我们在这里那样等待几分钟才能完成。 但是,我们的数据集只有1500个样本,如果您同时结合了网格搜索和随机搜索,找到最佳参数将花费我们近一个小时的时间。 想象一下,您要等待那里的大型数据集需要多少时间。
那么,网格搜索和随机搜索是否可用于较小的数据集?当然可以! 对于大型数据集,您需要采用其他方法。 幸运的是,Scikit学习已经涵盖了“不同的方法”……。 我们会在后面文章中介绍HalvingGridSearchCV和HalvingRandomizedSearchCV。 敬请关注!
作者:Bex T
deephub翻译组