前言:声音事件检测与定位(SELD)作为DCASE挑战赛的子任务,从2019年开始已经举办了好几届。该子任务的目标也从2022年开始由原来的在仿真数据集上设计更优声学模型,过渡到了在真实数据集上进行模型优化。相对而言,SELD2022和SELD2023子任务在数据集构建与模型评测上相对于前几届挑战赛有比较大的变化,且逐渐向真实应用场景靠近。为此,我将通过几篇系列文章来从数据集构建与组织、基线模型方法设计、可提升模型性能的途径等三个方面来介绍该项挑战赛。
一、数据集收集
Sony-TAu Realistic Spatial Soundscapes 2022 (STARSS22) 数据集是在两个不同的国家(由芬兰坦佩雷大学的音频研究小组(ARG)组织,和日本东京的索尼公司组织)使用类似的设置和注释程序收集的。
这些录音被组织成一个个录音会话,每个会话都在一个独特的房间里进行。除了少数例外,参与者的分组、声音制作道具和场景都是独特的。在每个会话中捕获多个声音事件的1-5min录音。为了在声音事件的出现、密度、运动和/或空间分布方面实现数据的良好可变性和效率,数据记录情景被松散地剧本化处理过。
在实验记录设备方面,使用高声道数球形麦克风阵列(Eigenmike em32,由mh Acoustics公司提供)捕捉声音场景记录,同时使用与球形阵列记录(Ricoh Theta V)空间对齐的360视频记录。此外,主要声源配备了空间跟踪标记,即在整个录音过程中,都会使用Optitrack Flex 13系统围绕每个场景进行跟踪。所有的场景都是基于人类演员执行某些动作,他们之间以及与场景中的物体进行互动,而动态设计的。
由于演员在场景中制造了大部分声音(但不是全部),他们额外配备了DPA Wireless Go II麦克风,提供主要事件的近距离录音。录音会根据正在进行的场景进行启动和停止,通常持续1~5分钟。所有的麦克风和跟踪设备都会在场景开始前开始录音,然后立即停止。拍手声将启动动作,它将作为参考信号,用于em32录音、理光Theta V视频、DPA无线麦克风录音和Optitrack跟踪器数据之间的同步。
二、数据集标注
数据集的标注,包括在时间维度上识别活动的声音事件类别,并定位活动声音事件在空间中的(运动)轨迹。在同一时刻存在两个同时激活的声音事件(同类/不同类)是比较常见的,这要求声音事件检测与定位模型能够有效地识别叠音情况。
结合无线麦克风信息、光学跟踪信息和360度视频信息,该数据集的标注采用的是时空半自动标注和标注结果手动验证的形式。更具体地说,在每个录音过程中,演员都戴着带有标记的发带进行跟踪,而其他与人类相关的声源位置,如嘴、手或脚,则依据头部坐标按照人的身体几何结构推断出来。其他的标记点被安装在周围的东西上(例如吸尘器、吉他、水龙头、橱柜、门把手)。每个演员都在衣领上佩戴一个无线麦克风,可以清晰地记录该演员产生的所有声音事件。
声音事件类别标注,主要通过收听麦克风信号来标记它们的类。声音事件在空间中的位置,则由光学跟踪系统提供,并将位置信息转换为相对于麦克风阵列坐标的到达方向(DOAs)。最后,观察记录的视频数据,并在360视频平面上可视化各DOAs标记,从而验证注释。

(source:DCASE challenge website)来自360度视频的场景示意帧,EM32生成的空间声学功率图,光学跟踪标记数据,带注释的事件标签,用于可视化验证
三、声音事件标注格式
根据AudioSet数据集的声音事件类别划分方式,该数据集共标注了13个类别的声音事件:
| 1. Female speech, woman speaking |
| 2. Male speech, man speaking |
| 3. Clapping |
| 4. Telephone |
| 5. Laughter |
| 6. Domestic sounds |
| 7. Walk, footsteps |
| 8. Door, open or close |
| 9. Music |
| 10. Musical instrument |
| 11. Water tap, faucet |
| 12. Bell |
| 13. Knock |
来自目标类以外的声音事件被认为是干扰,其中一些类的内容对应于audioset相关子类范围的事件,例如
- Telephone
- Mostly traditional Telephone Bell Ringing and Ringtone sounds, without musical ringtones.
声音事件标注格式:
对于开发数据集中的每个记录,声音事件标签和DoAs以与记录文件名相同的纯文本CSV文件的形式提供,格式如下:
[frame number (int)], [active class index (int)], [source number index (int)], [azimuth (int)], [elevation (int)]标注解释为:帧代号、活动声音事件类别和声源标签(从0开始)、方向角、俯仰角。
其中,帧代号对应于100毫秒的时间分辨率。方位角和俯仰角以度数表示,并四舍五入到最接近的整数值,以正面的方位角和俯仰角为零参考值,其中方位角ϕ在[−180∘,180∘],俯仰角θ在[−90∘,90∘]。方位角逆时针增加,且ϕ =90∘时在正左侧。
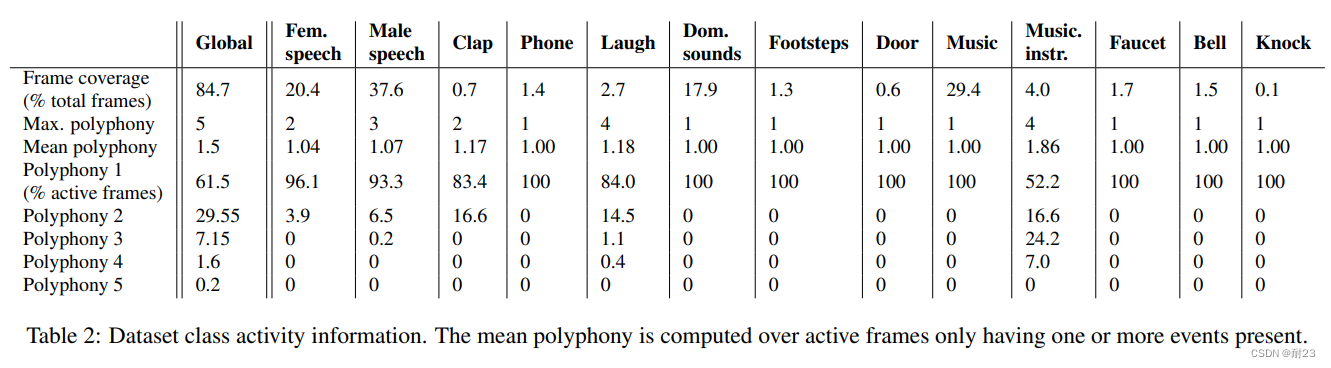
(source:STARSS22数据集标注的各声音事件类别所占比例,以及混音情况统计2)
四、声音数据记录格式与数据集组织形式
通过高阶球形麦克风阵列(Eigenmike em32)记录的原始声音数据未直接用于挑战赛,而是通过声音数据转换/通道选择提供了两种格式的4声道声音数据(FOA:first-order ambisonics 和MIC: tetrahedral microphone array)。可以认为这两种记录格式的阵列响应是已知的。后续博文介绍的用于声音事件检测与定位任务的有效数据增强技术 ACS(:audio channel swapping)的提出则是与FOA的阵列响应表达形式息息相关的。
该数据集的组织细节总结如下,
- 该数据集包含:70个30s~ 5min的录音片段,总时长约2小时,由Sony提供(开发数据集dev);51个1 min ~ 5 min的录音片段,总时长约为3小时,由TAU提供(开发数据集dev)。
- 开发集组成:训练集包含来自Sony的40个录音片段(dev-train-sony),在2个房间中记录,和来自TAU的27个录音片段(dev-train-tau),在4个房间中记录;测试集包含来自Sony的30个录音片段(dev-test-sony),在2个房间中记录,和来自TAU的24个录音片段(dev-test-tau),在3个房间中记录。
- 每个录音片段都是一个独特房间中的录音记录的一部分,同时出现3个声音事件是相当常见的,而更多重叠事件(最多5个)可能发生,但很少。
- 总结,该数据集包含11个独特房间的声音记录,其中4个来自Sony, 7个来自TAU,采样频率24kHz。
【可参考资源】
挑战赛描述 SELD2022:Sound Event Localization and Detection Evaluated in Real Spatial Sound Scenes - DCASE
描述数据集组织的论文:STARSS22: A DATASET OF SPATIAL RECORDINGS OF REAL SCENES WITH SPATIOTEMPORAL ANNOTATIONS OF SOUND EVENTS