1.聚类问题
1)聚类问题与核心概念
聚类算法做的事情,就是对无标签的数据,基于数据分布进行分群分组,使得相似的数据尽量落在同一个簇内。
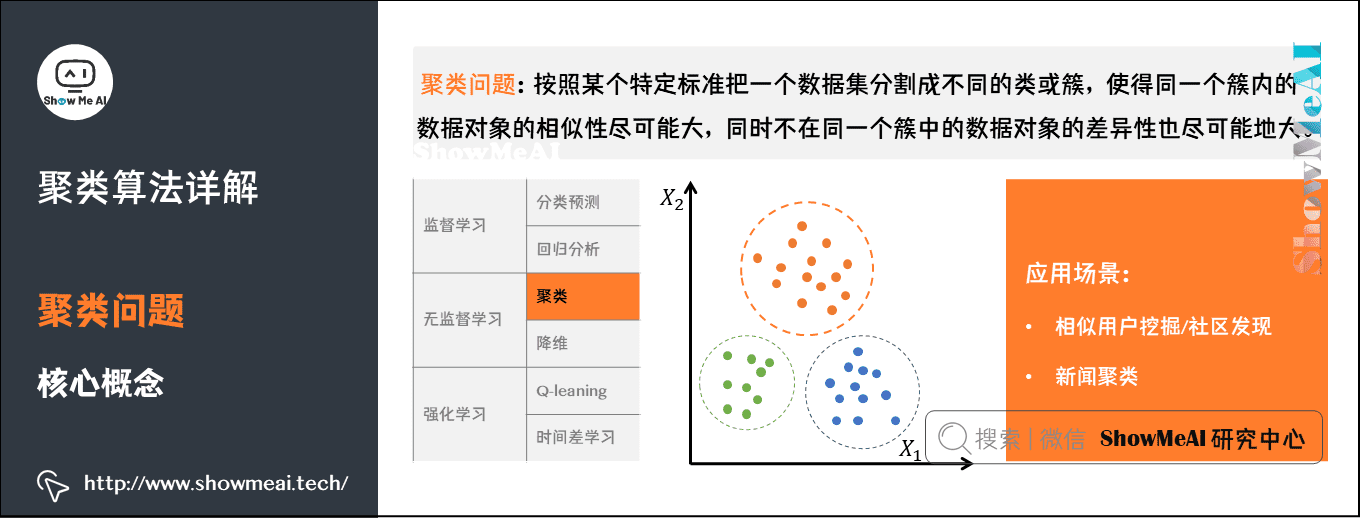
我们先对比区分一下聚类和分类:
- 聚类是一种无监督学习,而分类是一种有监督的学习。
- 聚类只需要人工指定相似度的标准和类别数就可以,而分类需要从训练集学习分类的方法

2)主流聚类算法
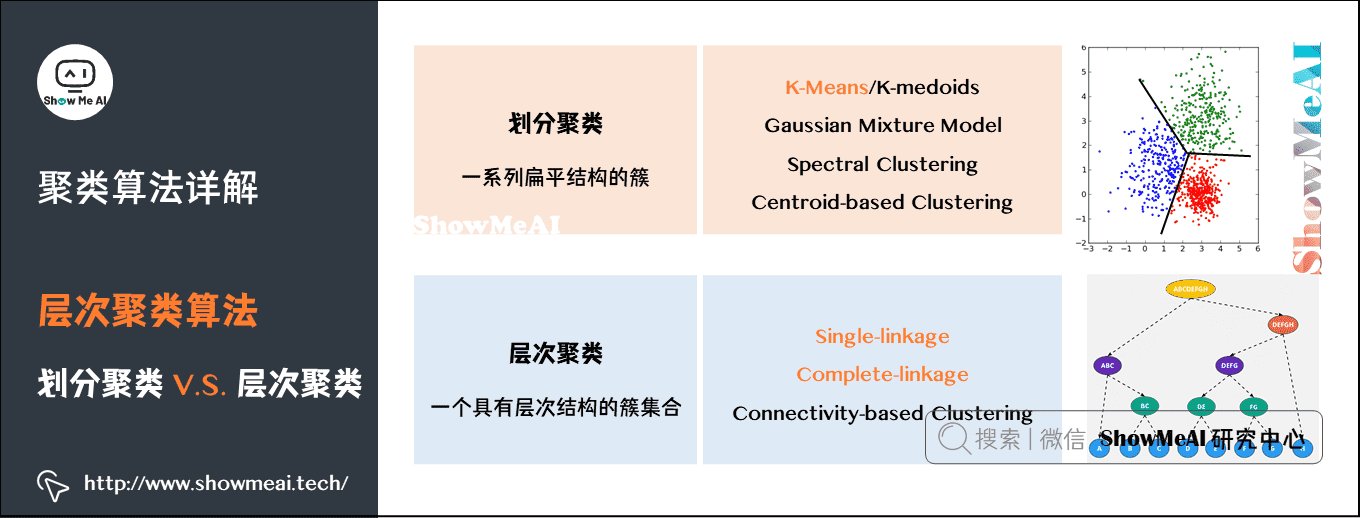
我们先对聚类算法做个了解,主流的聚类算法可以分成两类:划分聚类(Partitioning Clustering)和层次聚类(Hierarchical Clustering)。他们的主要区别如图中所示:
划分聚类算法会给出一系列扁平结构的簇(分开的几个类),它们之间没有任何显式的结构来表明彼此的关联性。
- 常见算法有 K-Means / K-Medoids、Gaussian Mixture Model (高斯混合模型)、Spectral Clustering(谱聚类)、Centroid-based Clustering等。
层次聚类会输出一个具有层次结构的簇集合,因此能够比划分聚类输出的无结构簇集合提供更丰富的信息。层次聚类可以认为是是嵌套的划分聚类。
- 常见算法有 Single-linkage、Complete-linkage、Connectivity-based Clustering等。
这两类算法在聚类过程中用到的具体算法不一样。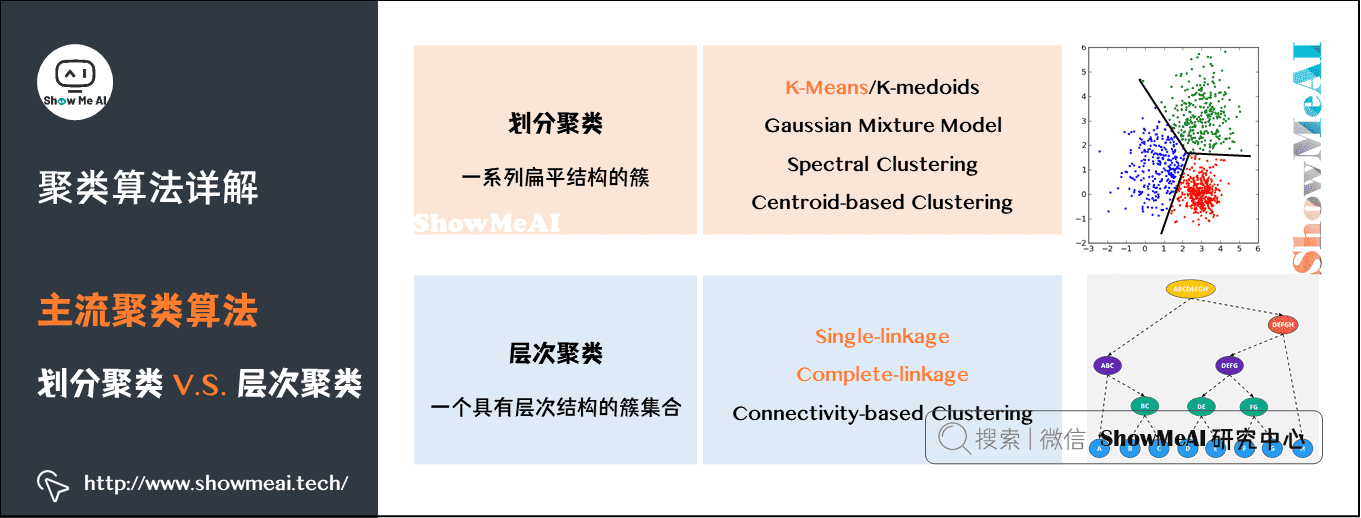
1.K-Means聚类算法
K-Means算法是聚类算法中一个非常基础的算法,同时应用又非常广泛。
1)K-Means算法核心概念
我们提到了聚类算法要把 n个数据点按照分布分成k类。我们希望通过聚类算法得到 k个中心点,以及每个数据点属于哪个中心点的划分。
- 中心点可以通过迭代算法来找到,满足条件:所有的数据点到聚类中心的距离之和是最小的。
- 中心点确定后,每个数据点属于离它最近的中心点。
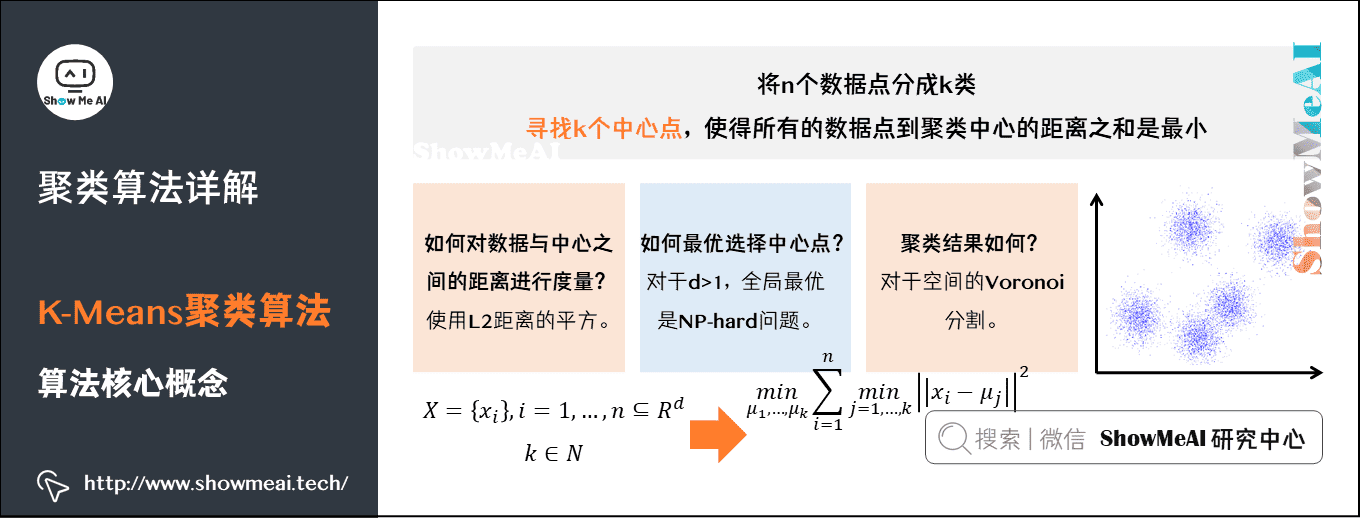
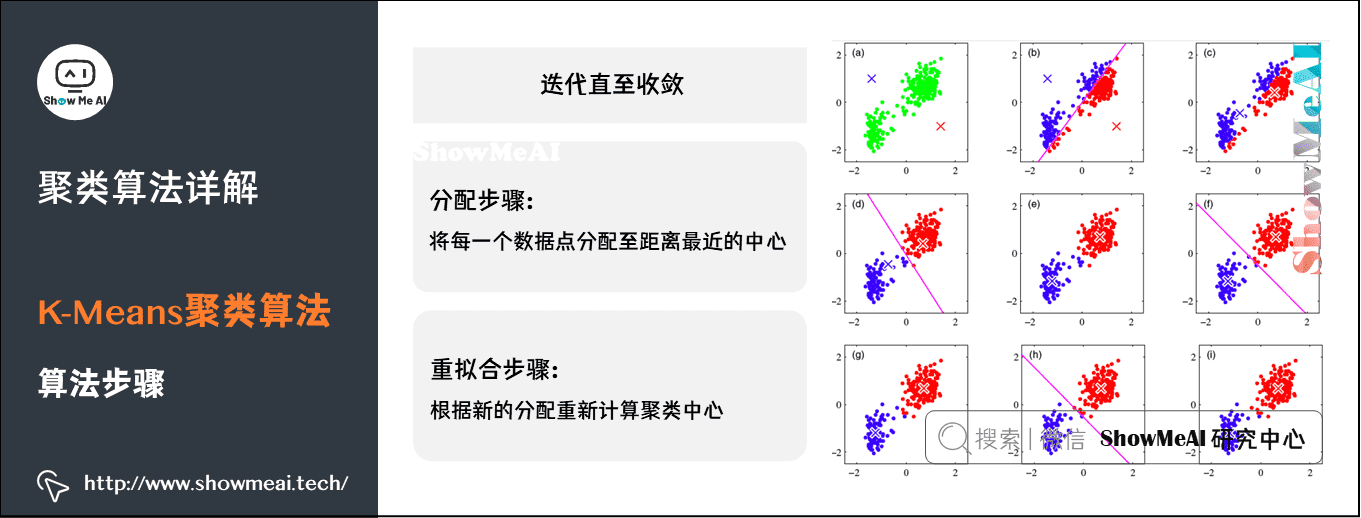
2)K-Means算法步骤
K-Means 采用 EM算法 迭代确定中心点。流程分两步:
- ① 更新中心点:初始化的时候以随机取点作为起始点;迭代过程中,取同一类的所有数据点的重心(或质心)作为新中心点。
- ② 分配数据点:把所有的数据点分配到离它最近的中心点。
重复上面的两个步骤,一直到中心点不再改变为止。过程如图所示:
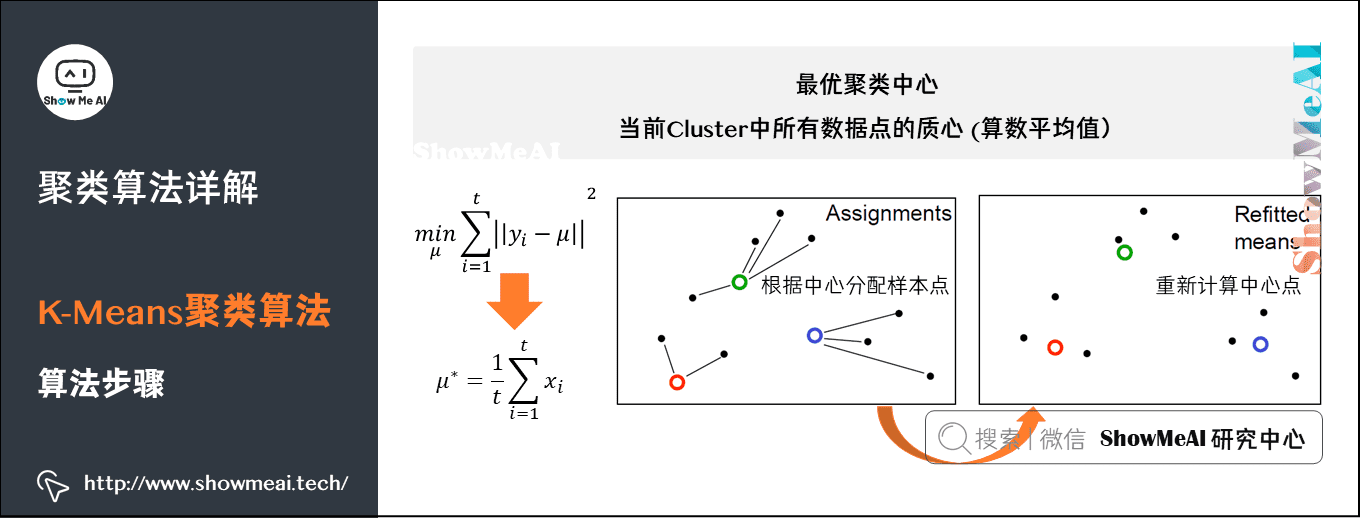
2.层次聚类算法
相比于 K-Means 这类划分聚类,我们有另外一类层次化聚类算法。
1)层次聚类 vs 划分聚类
划分聚类得到的是划分清晰的几个类,而层次聚类最后得到的是一个树状层次化结构。
 3. Birch算法
3. Birch算法
Birch(Balanced Iterative Reducing and Clustering using Hierarchies)是层次聚类的典型代表,天生就是为处理超大规模数据集而设计的,它利用一个树结构来快速聚类,这个树结构类似于平衡B+树,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。
聚类特征(CF):每一个CF都是一个三元组,可以用(N,LS,SS)表示。
N代表了这个CF中拥有的样本点的数量
LS代表了这个CF中拥有的样本点各特征维度的和向量
SS代表了这个CF中拥有的样本点各特征维度的平方和
比如:CF中含有N=5个点,以两维样本点值为:
(3,4)、(2,6)、(4,5)、(4,7)、(3,8)
然后计算:
LS=(3+2+4+4+3,4+6+5+7+8)=(16,30)
SS =(32+22+42+42+32,42+62+52+72+82)=(54,190)
CF有一个很好的性质——满足线性关系,即:
CF1+CF2=(N1+N2,LS1+LS2,SS1+SS2)
优点是聚类速度快,可以识别噪音点,还可以对数据集进行初步分类的预处理;
缺点有:对高维特征数据、非凸数据集效果不好;由于CF个数的限制会导致与真实类别分布不同.
Mini Batch K-means一般用于类别数适中或者较少的时候,而BIRCH适用于类别数比较大的情况,除此之外,BIRC还可以做一些异常点检测。
4.DB-SCAN算法
1)DB-SCAN算法
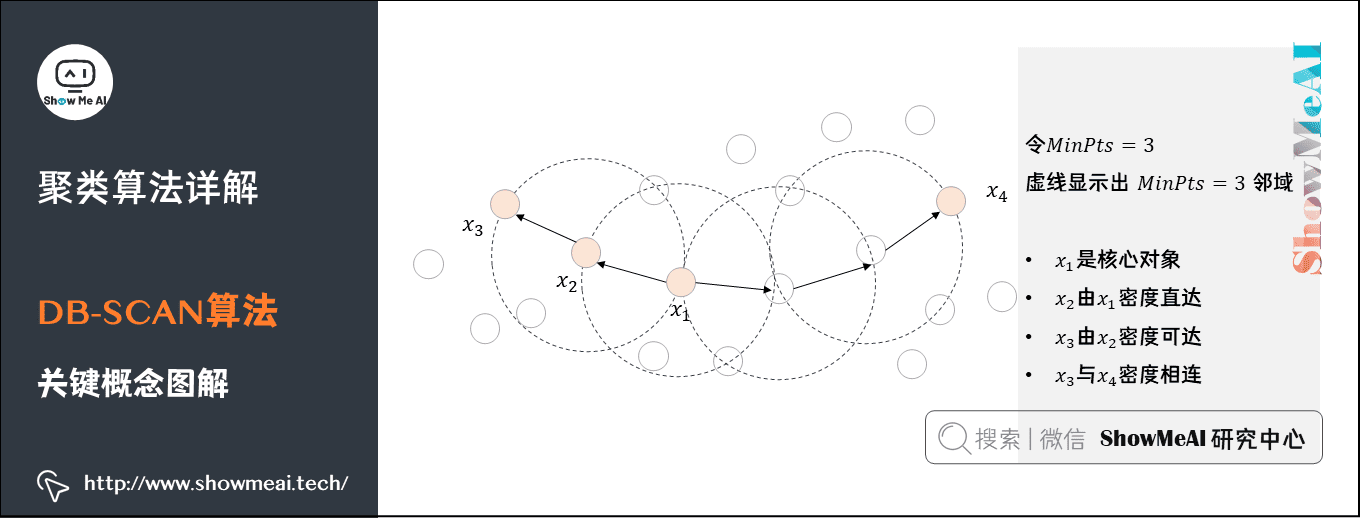
接下来我们学习另外一个聚类算法:DB-SCAN 算法。
DB-SCAN 是一个基于密度的聚类。如下图中这样不规则形态的点,如果用 K-Means,效果不会很好。而通过 DB-SCAN 就可以很好地把在同一密度区域的点聚在一类中。


5. OPTICS聚类算法
基础
OPTICS聚类算法是基于密度的聚类算法,全称是Ordering points to identify the clustering structure,目标是将空间中的数据按照密度分布进行聚类,其思想和DBSCAN非常类似。
但是和DBSCAN不同的是,OPTICS算法可以获得不同密度的聚类,直接说就是经过OPTICS算法的处理,理论上可以获得任意密度的聚类。因为OPTICS算法输出的是样本的一个有序队列,从这个队列里面可以获得任意密度的聚类。
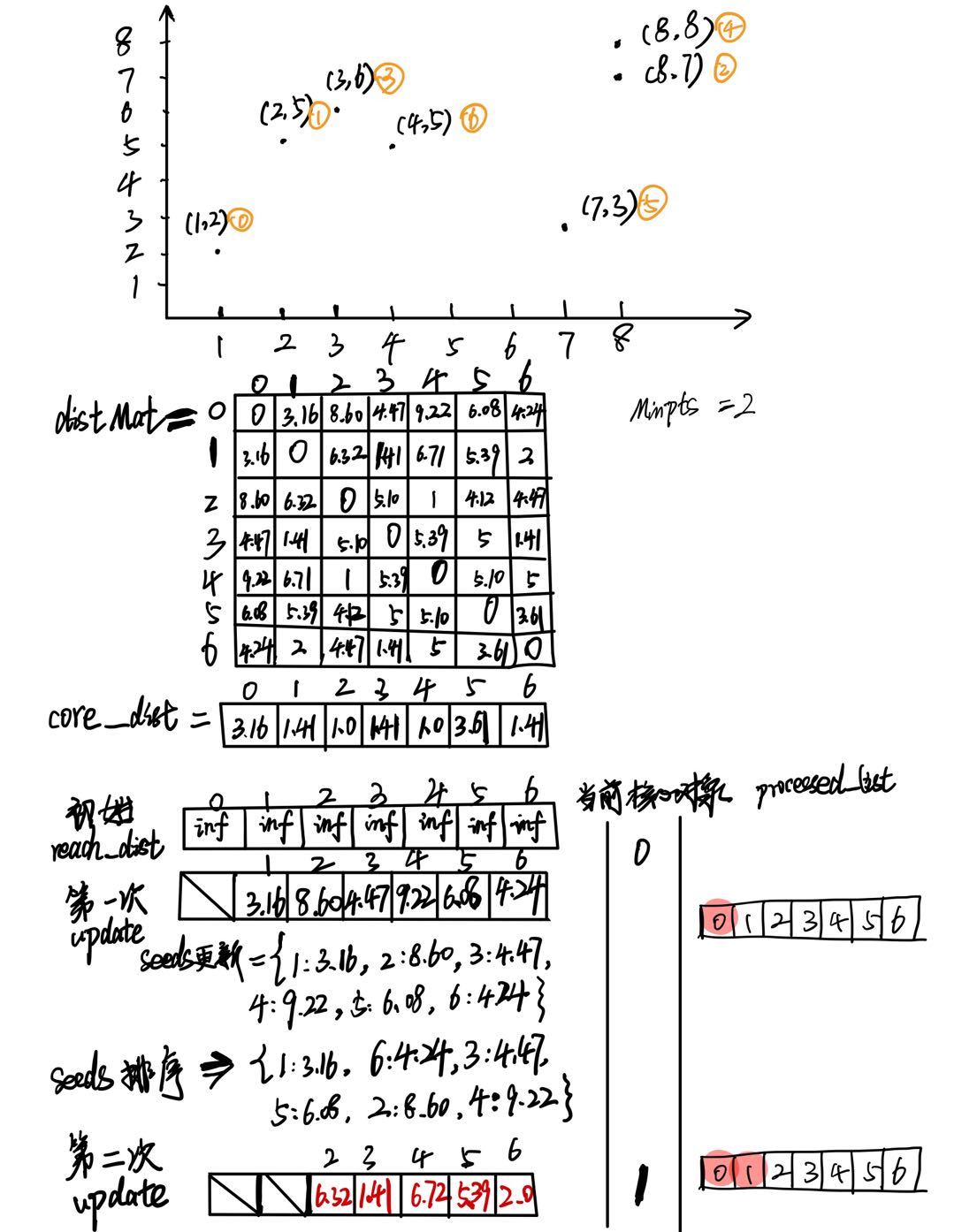
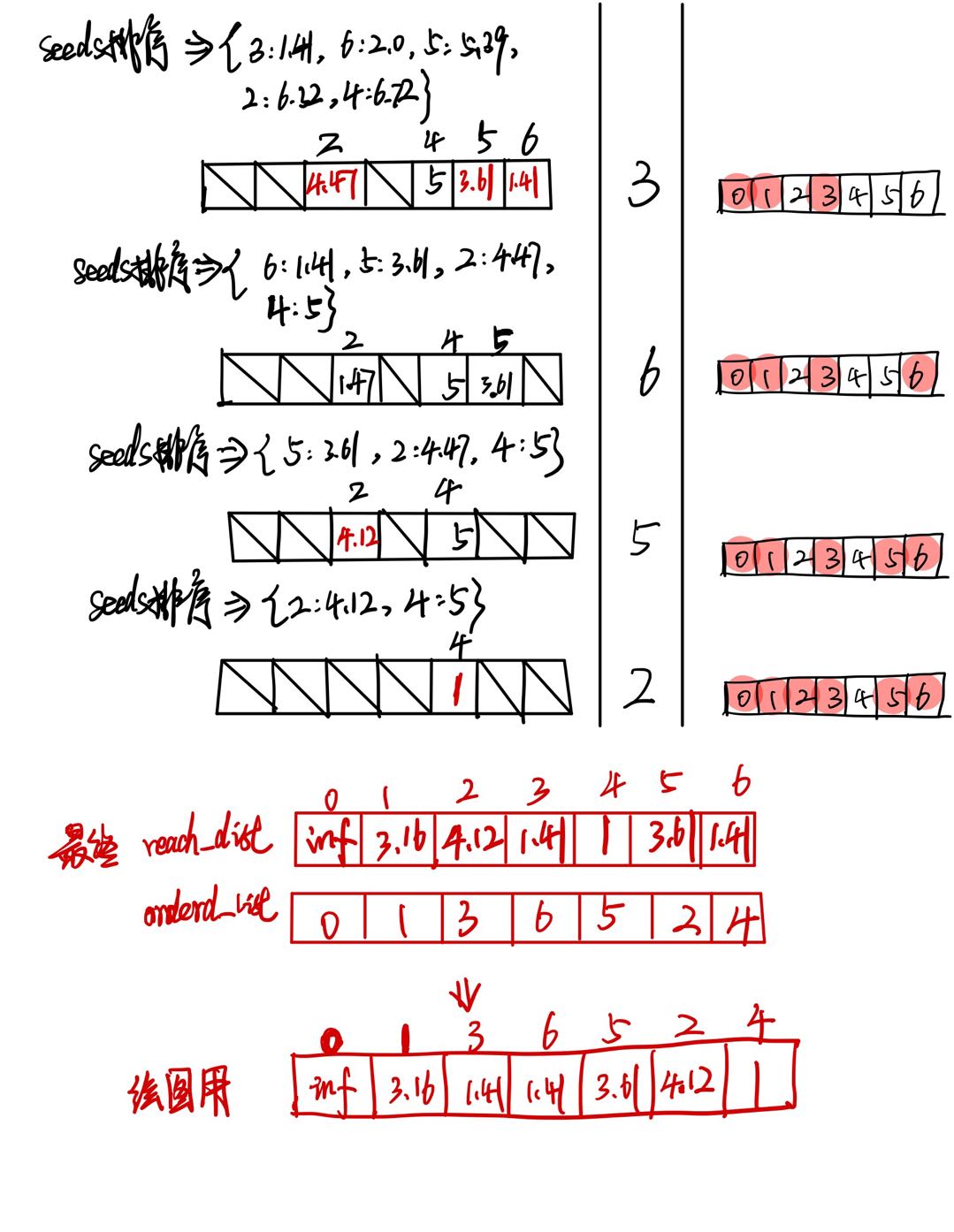
OPTICS算法的基础有两点,
- 参数(半径,最少点数):
一个是输入的参数,包括:半径ε,和最少点数MinPtsMinPts。
- 定义(核心点,核心距离,可达距离,直接密度可达):