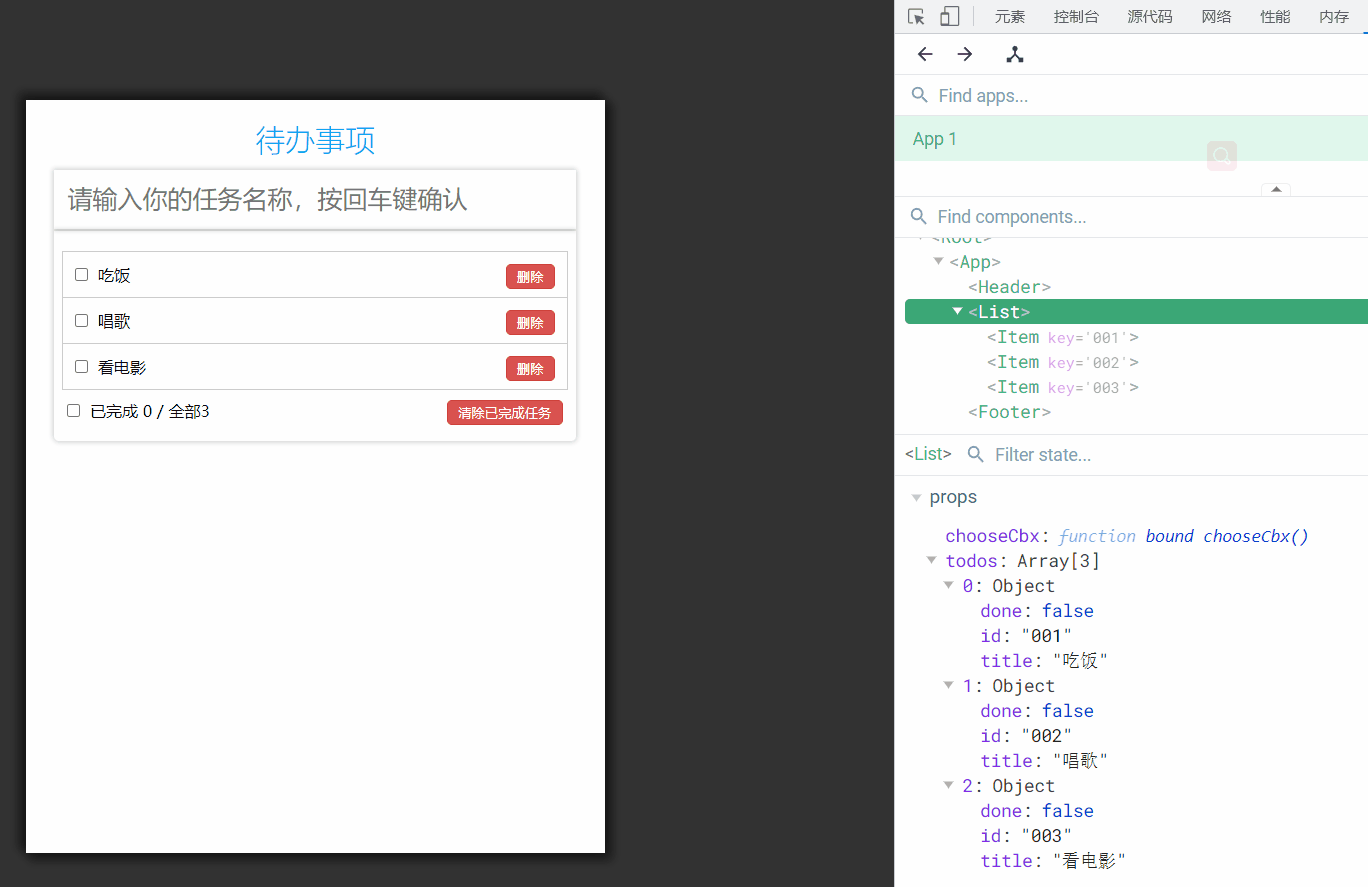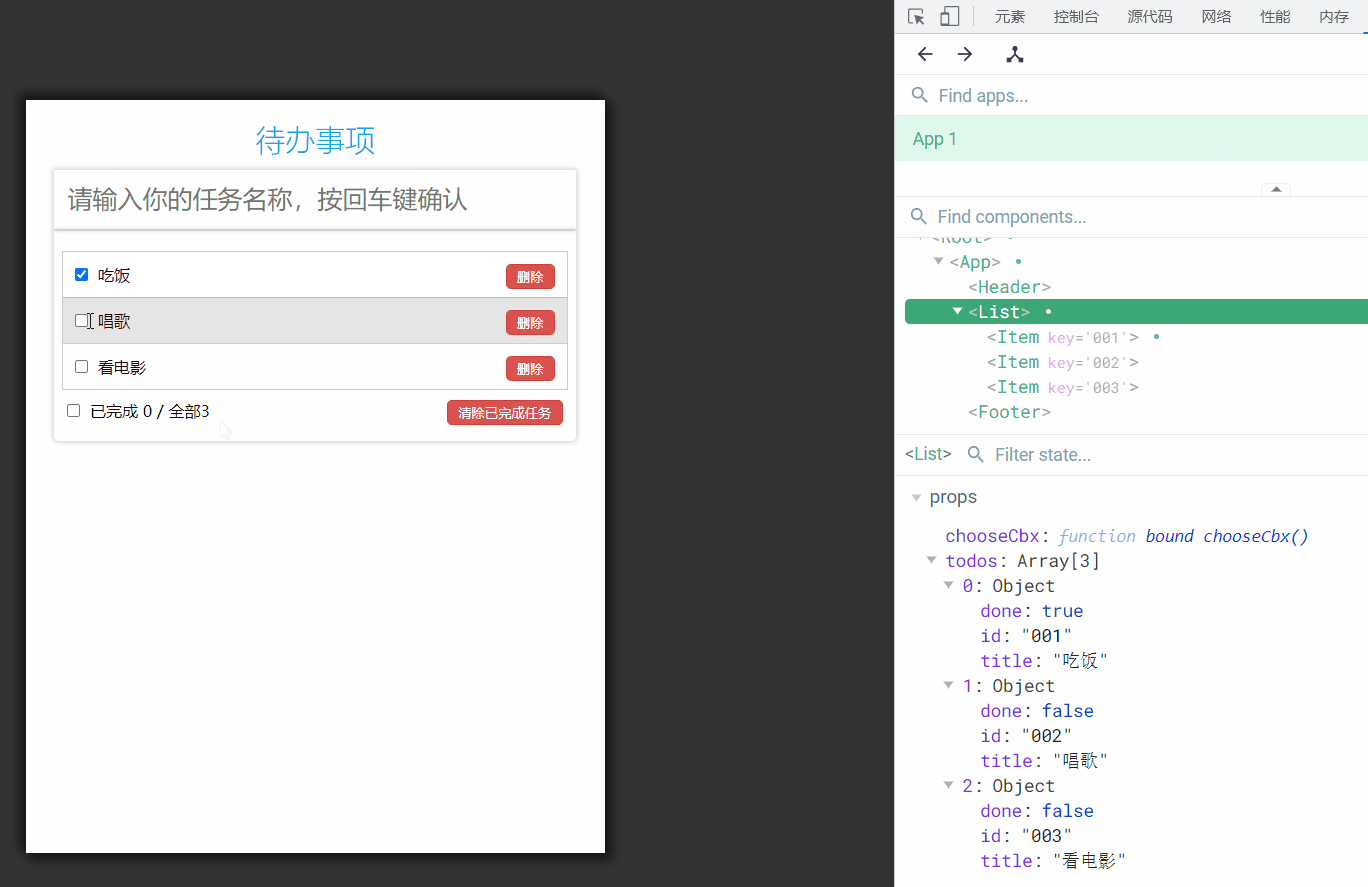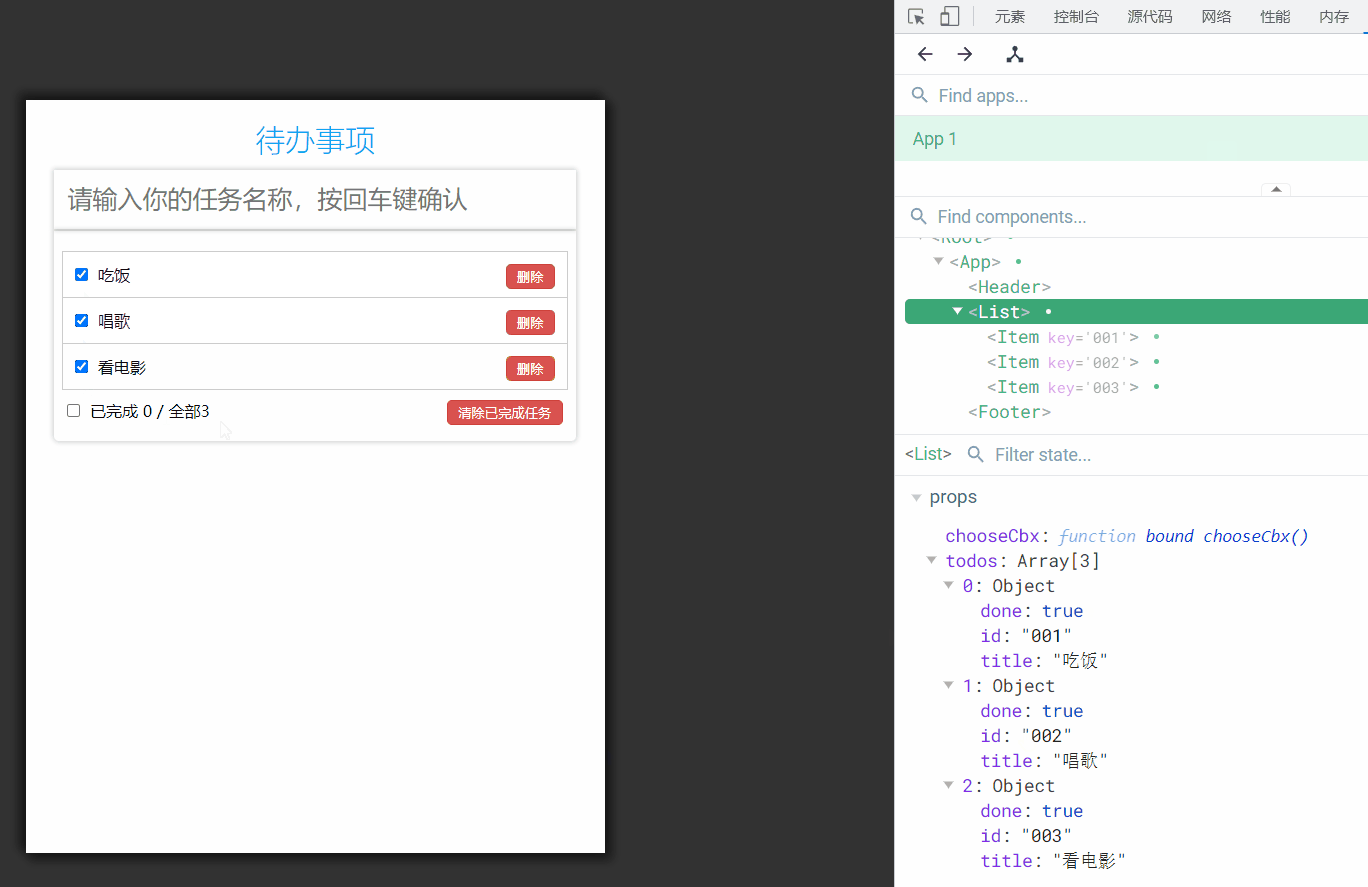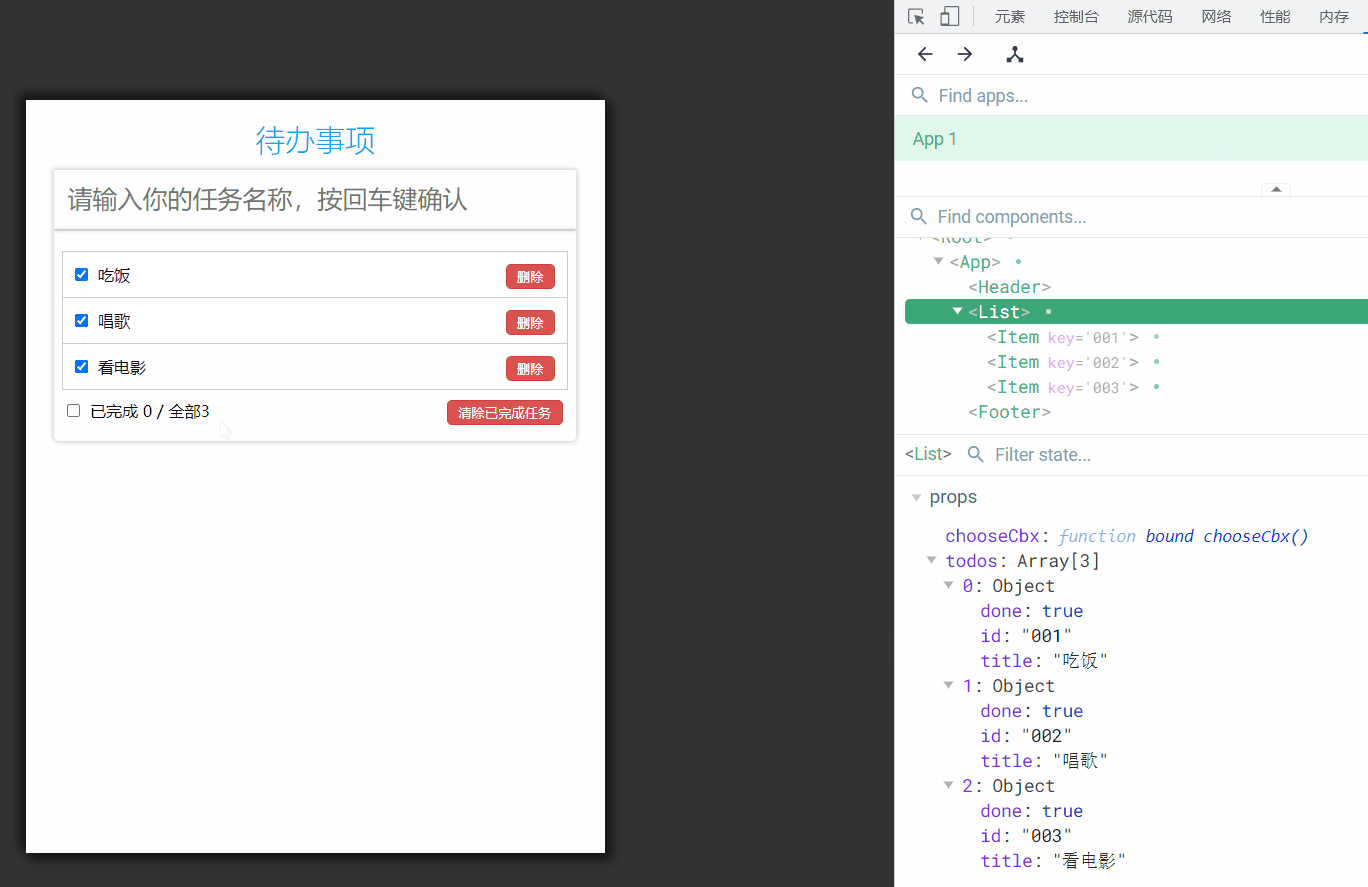
1、抽象类和接口的区别
共同点 :
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法(Java 8 可以用
default关键字在接口中定义默认方法,而抽象类的实现方法是不能带default的)
区别 :
- 一个类只能继承一个类,但是可以实现多个接口。
- 接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值。 - 抽象类里可以没有抽象方法,也就是说有默认方法的实现;JDK1.8中接口中可以有静态方法(static)和默认方法(default)。使得接口中可以实现方法
- 在实现接口上可以对默认方法进行重写、但不能对静态方法进行重写;如果一个类实现多个接口且有相同的静态方法则需要重写该静态方法
- 接口可以通过匿名内部类实例化
- 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
2、重写equals方法为什么必须重写hashCode方法
equals相同的对象,hashCode必然相同。
如果重写了equals就必须重写hashCode,如果不重写hashCode方法,会导致通过equals判断两个对象相等, 但是hashCode不相等,如果把这两个对象存储到map中,发现两个相同对象存储到map中不同位置,这与map中不同位置存放相同的对象是矛盾的。
3、String为什么是不可变的
- 保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。 String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变
4、Java内存区域详情
Java 内存区域详解 | JavaGuide(Java面试+学习指南)
5、String s1 = new String(“abc“) 会创建多少个字符串对象?
一个或者两个。
分情况讨论。
1、等号左边的String s1 是声明了一个 String 类型的 s1 变量,它不是对象。再来看等号右边,使用new关键字,会在堆中创建一个对象,另外会在常量池中创建一个常量"abc",所以一共创建了两个对象。
2、如果 "abc"在常量池中已经存在的话,那么就只会创建一个对象。
6、Exception 和 Error 有什么区别?
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。Error:Error属于程序无法处理的错误 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
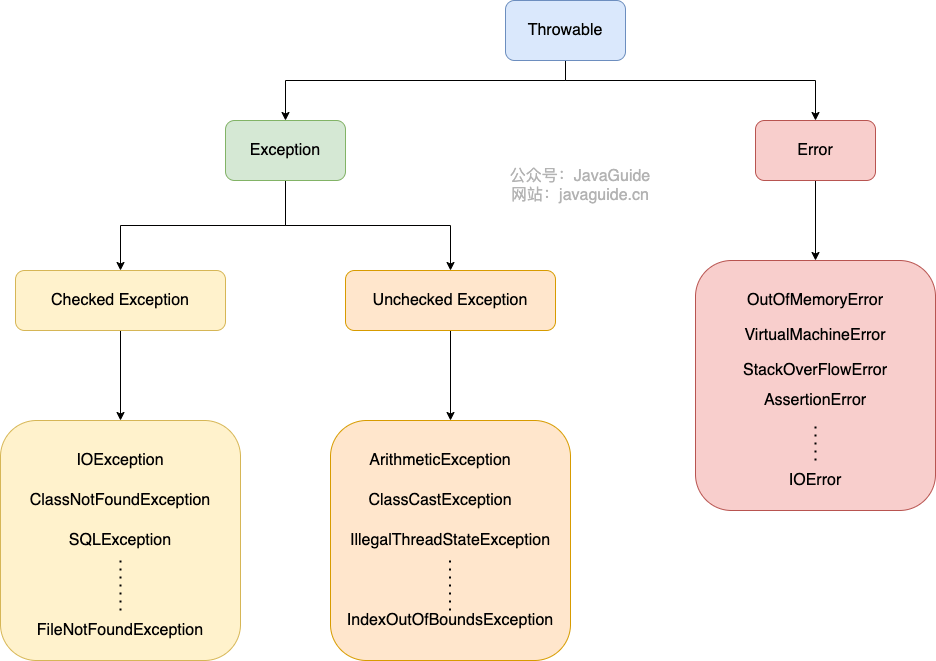
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、ClassNotFoundException 、SQLException...。
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译
RuntimeException 及其子类都统称为非受检查异常
NullPointerException(空指针错误)IllegalArgumentException(参数错误比如方法入参类型错误)NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)ArrayIndexOutOfBoundsException(数组越界错误)ClassCastException(类型转换错误)ArithmeticException(算术错误)SecurityException(安全错误比如权限不够)UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)
7、java反射
JAVA机制反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象
像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
8、HashMap和HashTable的区别
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它; - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException。 - 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证,下面给出了源代码)。也就是说HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable没有这样的机制。
9、HashMap和HashSet区别

10、HashSet如何检查重复