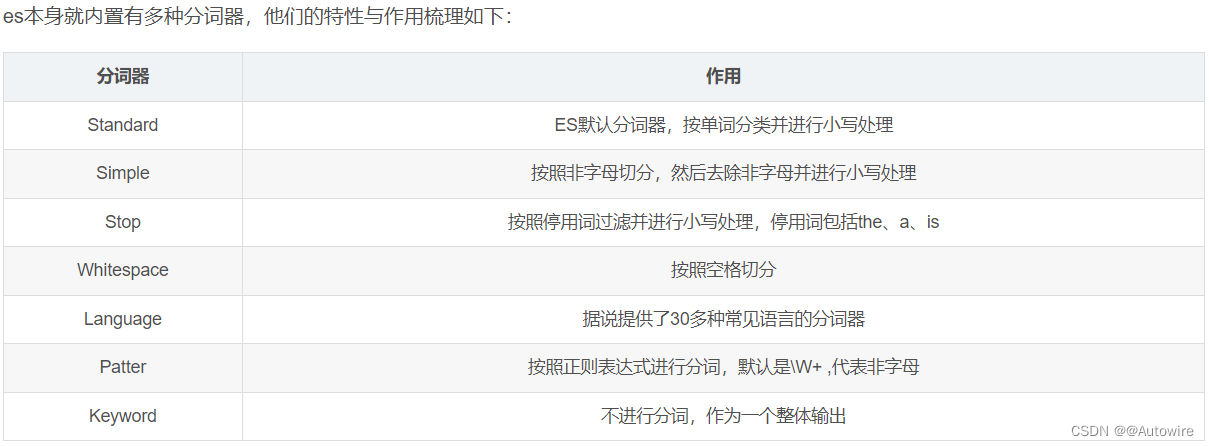
分词器是es中的一个组件,通俗意义上理解,就是将一段文本按照一定的逻辑,分析成多个词语,同时对这些词语进行常规化的一种工具;ES会将text格式的字段按照分词器进行分词,并编排成倒排索引,正是因为如此,es的查询才如此之快;
1 normalization 规范化
2 character filter 字符过滤器
分词之前的预处理,过滤无用字符
2.1 HTML Strip

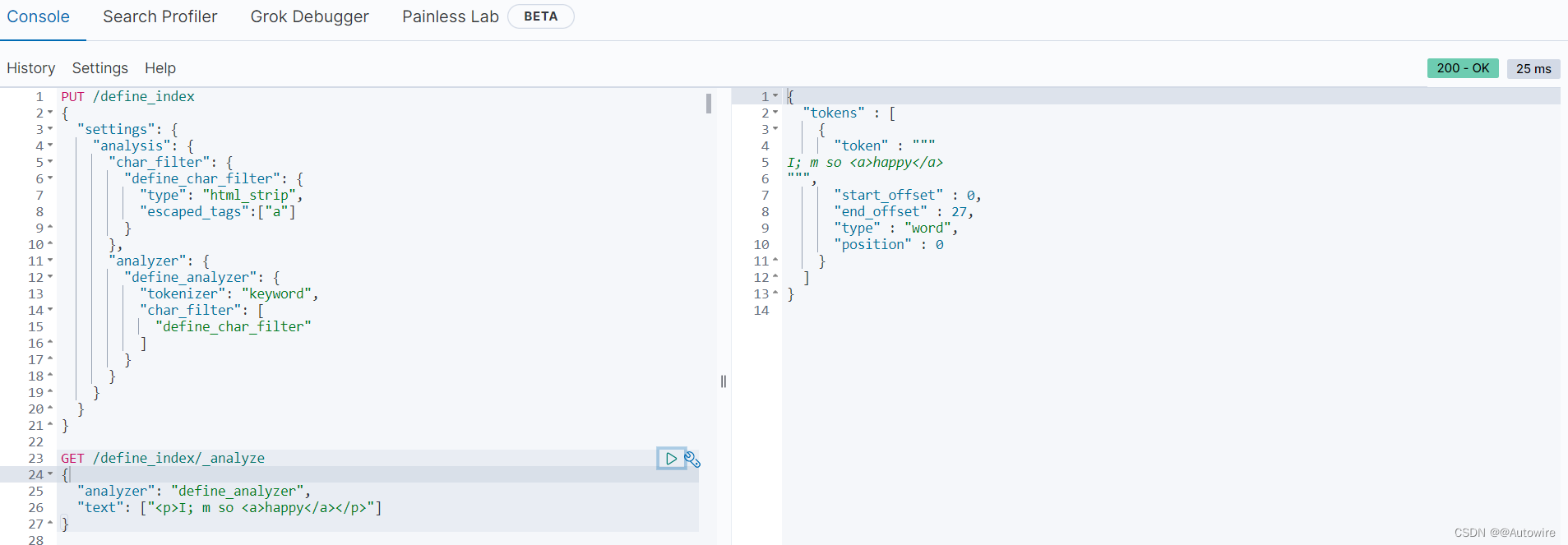
PUT /define_index
{"settings": {"analysis": {"char_filter": {"define_char_filter": {"type": "html_strip"}},"analyzer": {"define_analyzer": {"tokenizer": "keyword","char_filter": ["define_char_filter"]}}}}
}
自定义字符过滤器define_analyzer,作用是过滤数据中的html标签
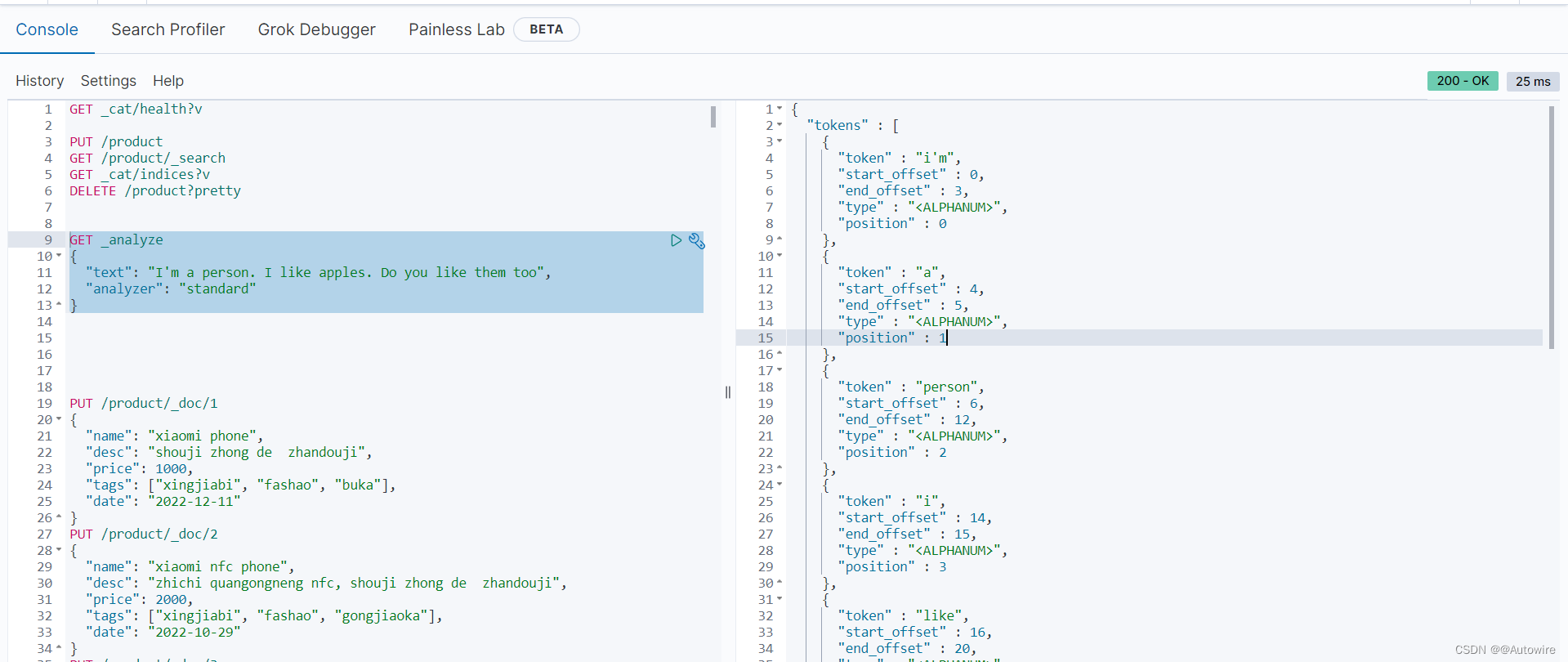
GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["<p>I; m so <a>happy</a></p>"]
}
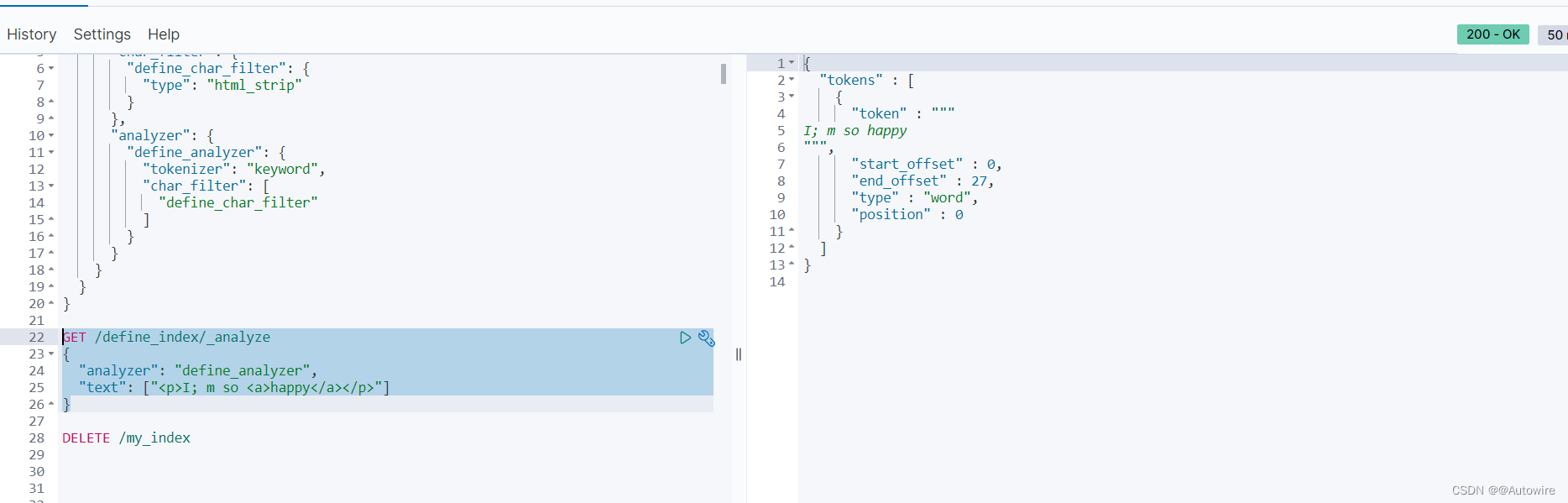
可使用"escaped_tags":[“a”]设置保留不被过滤的标签
2.2 Mapping
PUT /define_index
{"settings": {"analysis": {"char_filter": {"define_char_filter": {"type": "mapping","mappings": ["滚 => *", "垃圾 => 可爱"]}},"analyzer": {"define_analyzer": {"tokenizer": "keyword","char_filter": ["define_char_filter"]}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["<p>你好啊 你这个大垃圾, 滚犊子"]
}
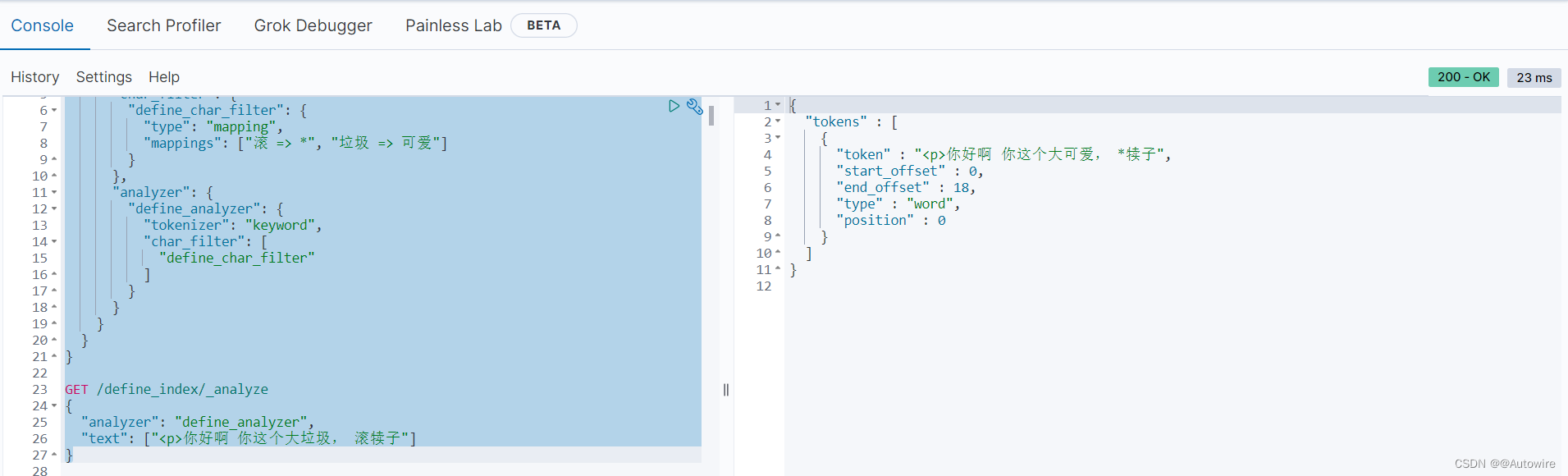
通过自定义的过滤器,可以将聊天、留言或者弹幕之类的发言根据需求进行屏蔽或替换。
2.3 Pattern Replace
PUT /define_index
{"settings": {"analysis": {"char_filter": {"define_char_filter": {"type": "pattern_replace","pattern": "(\\d{3})\\d{4}(\\d{4})","replacement": "$1****$2"}},"analyzer": {"define_analyzer": {"tokenizer": "keyword","char_filter": ["define_char_filter"]}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["电话号码:13792223536"]
}
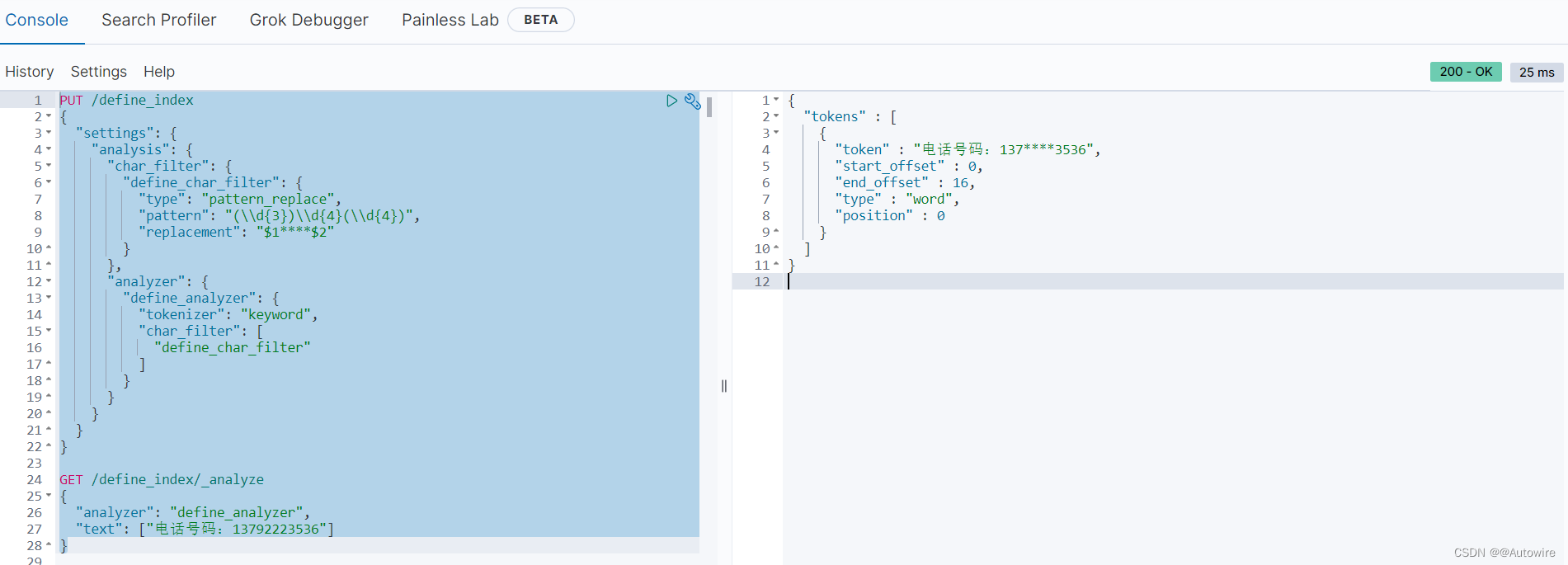
通过正则表达式进行数据的替换。
3 token filter 令牌过滤器
停用词、时态转换、大小写转换、同义词转换、语气词处理等。
PUT /define_index
{"settings": {"analysis": {"filter": {"define_synonym": {"type": "synonym","synonyms": ["东邪 => 黄药师","西毒 => 欧阳锋","南帝 => 段智兴","北丐 => 洪七公"]}},"analyzer": {"define_analyzer": {"tokenizer": "standard","filter": ["define_synonym"]}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["东邪", "西毒"]
}
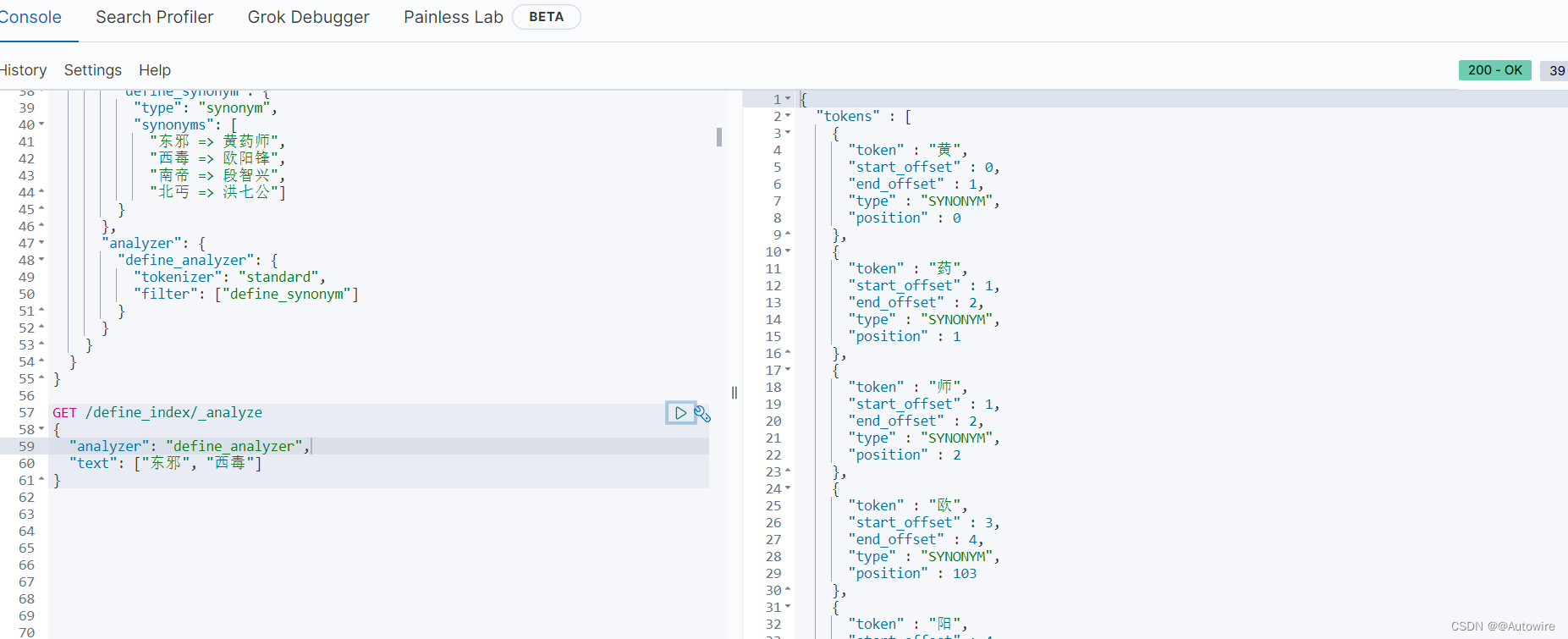
可以看到"东邪"检索到"黄药师"的分词,"西毒"检索到"欧阳锋"的分词。
除了自定义的以外,也可以使用ES自带的,比如大小写的转换:

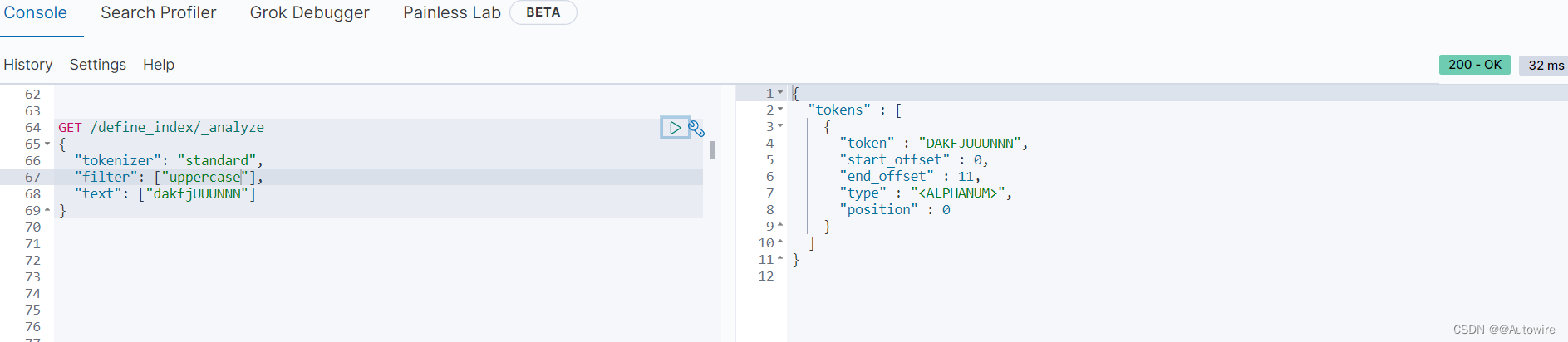
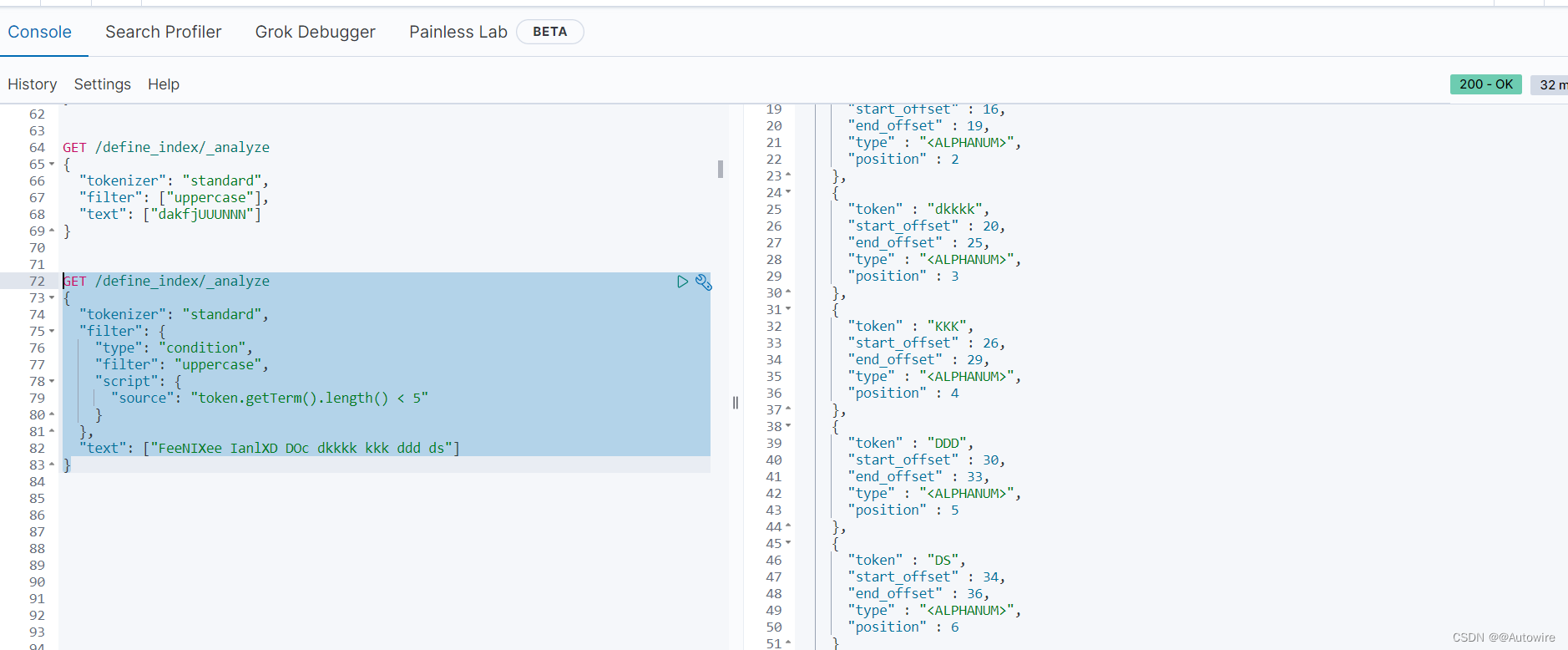
甚至可以通过自定义脚本动态的控制过滤逻辑,比如将长度小于5的字符串转为全大写:
GET /define_index/_analyze
{"tokenizer": "standard","filter": {"type": "condition","filter": "uppercase","script": {"source": "token.getTerm().length() < 5"}},"text": ["FeeNIXee IanlXD DOc dkkkk kkk ddd ds"]
}
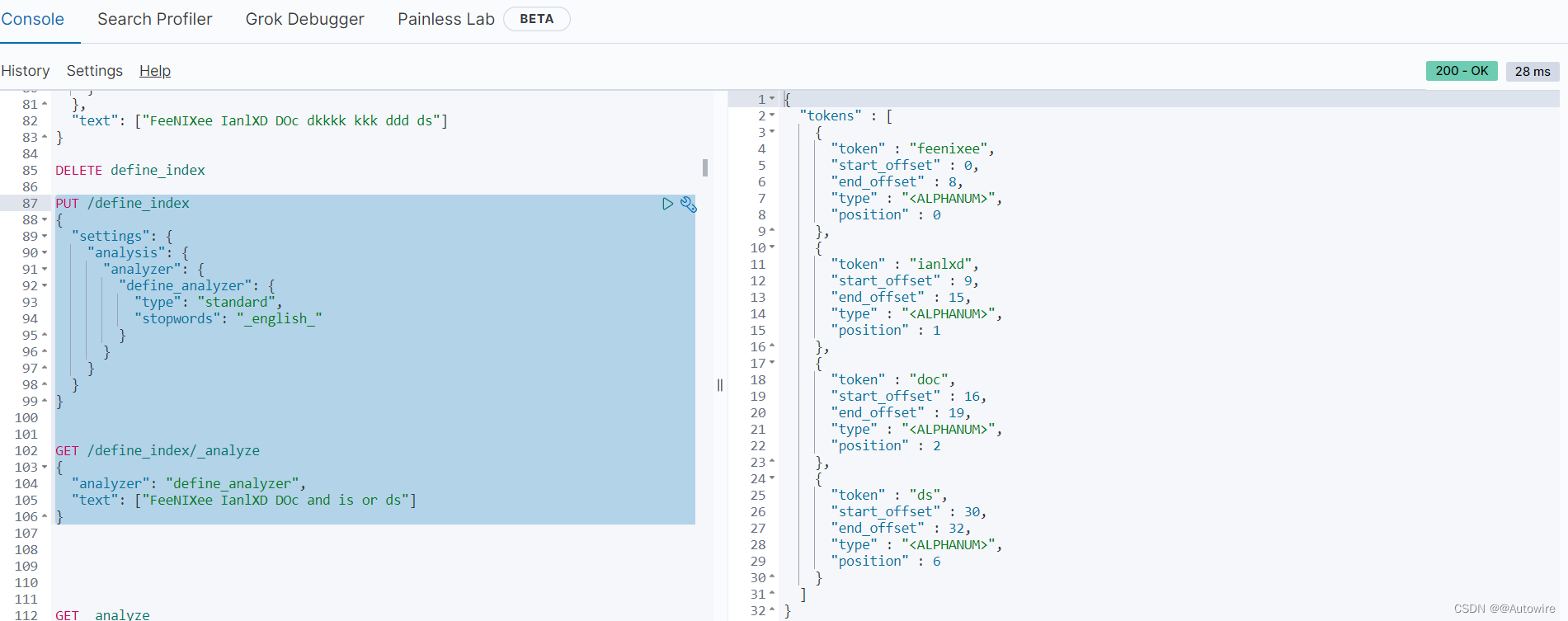
也可以将一些语句中没有什么意义的语气词等作为停用词不参与检索:
PUT /define_index
{"settings": {"analysis": {"analyzer": {"define_analyzer": {"type": "standard","stopwords": "_english_"}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["FeeNIXee IanlXD DOc and is or ds"]
}
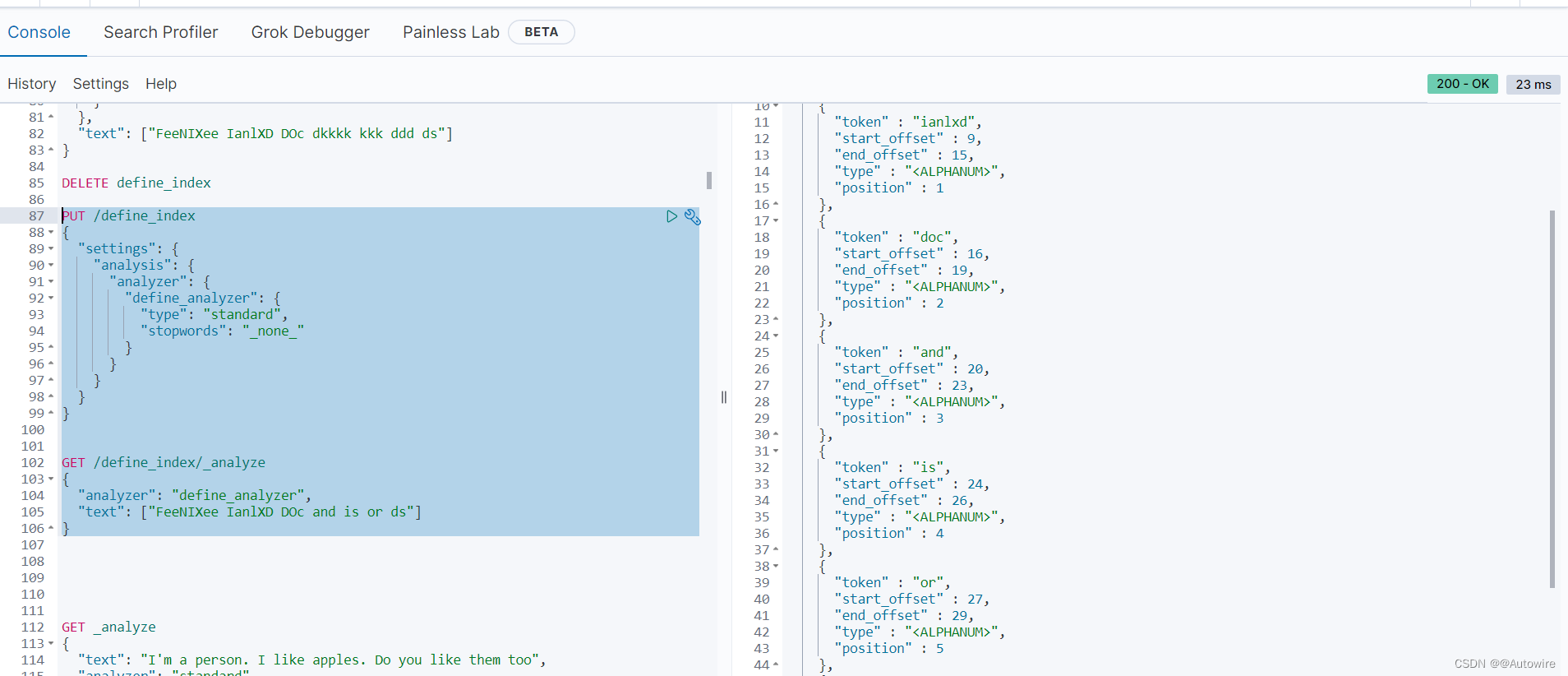
也可以将一些语句中不管有没有意义所有的词都不作为停用词参与检索:
PUT /define_index
{"settings": {"analysis": {"analyzer": {"define_analyzer": {"type": "standard","stopwords": "_none_"}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["FeeNIXee IanlXD DOc and is or ds"]
}
当然也可以手动自定义去设置那些词作为停用词使用:
PUT /define_index
{"settings": {"analysis": {"analyzer": {"define_analyzer": {"type": "standard","stopwords": ["is", "or", "ds"]}}}}
}GET /define_index/_analyze
{"analyzer": "define_analyzer","text": ["FeeNIXee IanlXD DOc and is or ds"]
}