损失函数和反向传播网络
在进行损失函数计算后,再进行.backward()反向传播。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("dataset_transform",train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x# 分类问题适合用交叉熵
loss = nn.CrossEntropyLoss()
zrf = Zrf()
for data in dataloader:imgs, targets = dataoutputs = zrf(imgs)# print(outputs)# print(targets)result_loss = loss(outputs, targets)result_loss.backward()优化器
以Adadelta为例,torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
params: 模型的参数,让优化器知道我们的模型长什么样子。
lr: Learning rate, 学习率
其他的参数可以采用默认,并且优化算法不同,参数也会有很大不同。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("dataset_transform",train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x# 分类问题适合用交叉熵
loss = nn.CrossEntropyLoss()
zrf = Zrf()
# 设置优化器
# SGD 随机梯度下降
# lr的设不可以太大也不可以太小,一般情况下我们采用训练开始时lr大,之后的训练中lr小的方式
optim = torch.optim.SGD(zrf.parameters(), lr=0.01)
for epoch in range(20) :running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = zrf(imgs)result_loss = loss(outputs, targets)# 在进行反向传播来计算梯度时,要先将梯度置为0,防止之前计算出来的梯度的影响optim.zero_grad()result_loss.backward()# 根据梯度对卷积核参数进行调优optim.step()running_loss = running_loss + result_lossprint(running_loss)
现有网络模型的使用及修改
torchvision.modles中的VGG为例。VGG常用VGG16和VGG19。
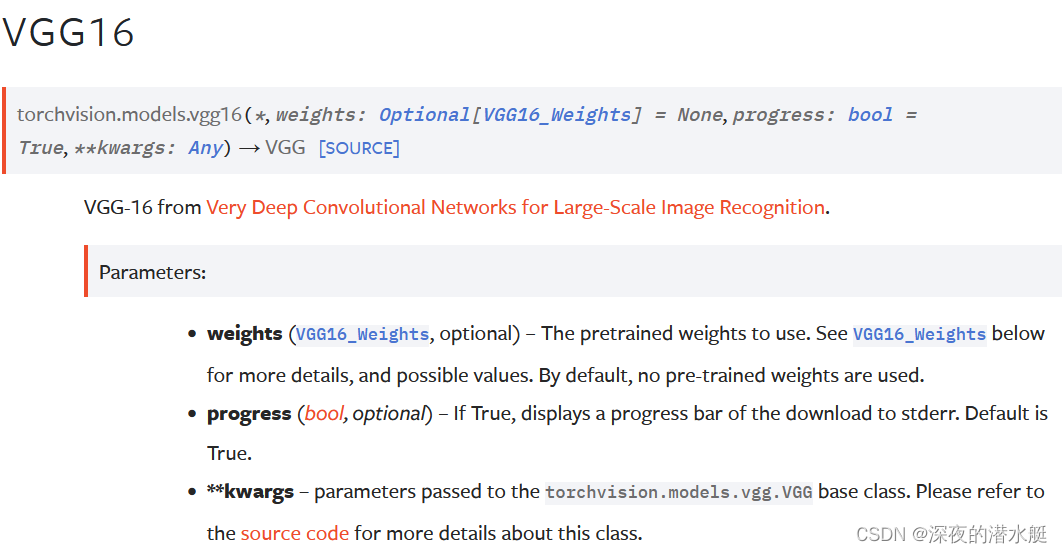
weights: 可选,要使用的预训练权重。默认情况下,不使用预先训练的权重。
progress: true时,会展示一个进度条
此外,pytorch在下载模型时会把模型下载到C盘,下面语句可以修改下载位置:
os.environ['TORCH_HOME'] = '/path/to/torch_home'
import torchvision
from torch import nn
from torchvision.models import VGG16_Weights
import os# train_data = torchvision.datasets.ImageNet(root="data_image_net", split="train", download=True,
# transform=torchvision.transforms.ToTensor())# 最新版本默认是没有预训练的,需要使用预训练设置weights='DEFAULT'os.environ['TORCH_HOME'] = '/path/to/torch_home'vgg16_noPre = torchvision.models.vgg16()
vgg16_pre = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT)
print(vgg16_pre)# 微调网络模型
train_data = torchvision.datasets.CIFAR10("dataset_transform",train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 添加一层
# 在vgg整体层面上加
vgg16_pre.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_pre)
# 只在某一部分加(classifier部分)
vgg16_pre.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_pre)# 修改
vgg16_noPre.classifier[6] = nn.Linear(4096, 10)
print(vgg16_noPre)网络模型的保存与读取
保存方法演示:model_save.py
import torch
import torchvision
from torch import nn# 使用未经过训练的,初始化的参数
vgg16 = torchvision.models.vgg16()
# 保存方式1
# 这样不仅保存了网络模型的结构,也保存了网络模型的参数
torch.save(vgg16, "vgg16_method1.pth")# 保存方式2
# 不保存网络的结构,只是把网络的参数保存成数据字典,也就是保存了网络的状态
# (官方推荐!!!)占用空间更小
torch.save(vgg16.state_dict(), "vgg16_method2.pth")# 陷阱1
class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3)def forward(self, x):x = self.conv1(x)return xzrf = Zrf()
torch.save(zrf, "zrf_method1.pth")读取方法演示:model_load.py
import torch
import torchvision
from torch import nn# 方式1 ----> 对应保存方式1,来加载模型
model = torch.load("vgg16_method1.pth")
# print(model)# 方式2 ---> 对应保存方式2
vgg16 = torchvision.models.vgg16() # 新建网络模型结构
model = torch.load("vgg16_method2.pth")
# print(model)
vgg16.load_state_dict(model) # 加载网络模型的状态
print(vgg16)# 陷阱1
# 在使用自己创建的网络时,注意要有网络的这个类在本文件(程序可以访问到网络),只是不需要zrf = Zrf()再创建网络了
# 方法1
# class Zrf(nn.Module):
# def __init__(self):
# super(Zrf, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
#
# def forward(self, x):
# x = self.conv1(x)
# return x
# 方法2
from model_save import *model = torch.load("zrf_method1.pth")
print(model)




