文章目录
- Instance-specific and Model-adaptive Supervision for Semi-supervised Semantic Segmentation
- 摘要
- 本文方法
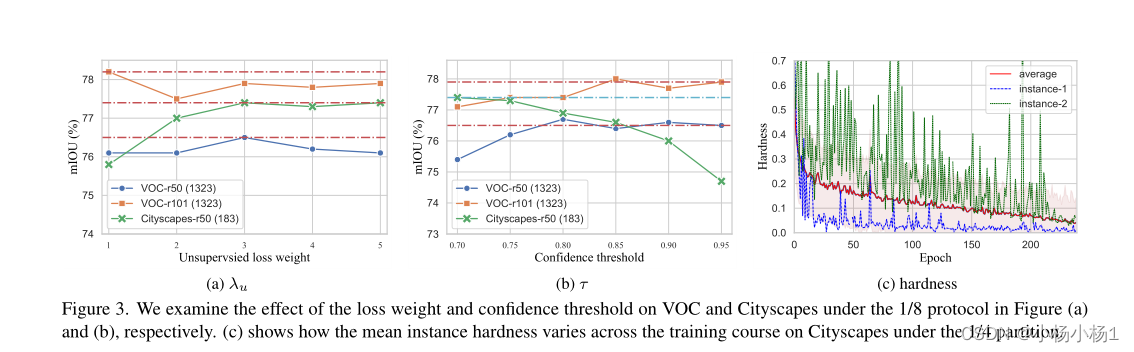
- Quantitative hardness analysis
- Model-adaptive supervision
- Intensity-based augmentations
- CutMix-based augmentations
- Model-adaptive unsupervised loss
- 实验结果
Instance-specific and Model-adaptive Supervision for Semi-supervised Semantic Segmentation
摘要
最近,半监督语义分割在少量标记数据的情况下取得了很好的性能。然而,大多数现有研究对所有未标记的数据一视同仁,几乎没有考虑未标记实例之间的差异和训练困难。区分未标记实例可以促进实例特定监督动态适应模型的演化。
本文方法
- 强调了实例差异的关键性,并提出了一种用于半监督语义分割的实例专用和模型自适应监督,称为iMAS
- 根据模型的性能,iMAS采用类加权对称交集-联合来评估每个未标记实例的定量硬度,并以模型自适应的方式监督对未标记数据的训练。
- iMAS通过根据评估的硬度权衡其相应的一致性损失,逐步从未标记的实例中学习
- iMAS动态调整每个实例的扩充,使得扩充实例的失真度适应模型在整个训练过程中的泛化能力。
- 在不集成额外损失和训练过程的情况下,iMAS可以在不同的半监督分割协议下,在分割基准上获得与当前最先进方法相比的显著性能增益
代码地址
本文方法
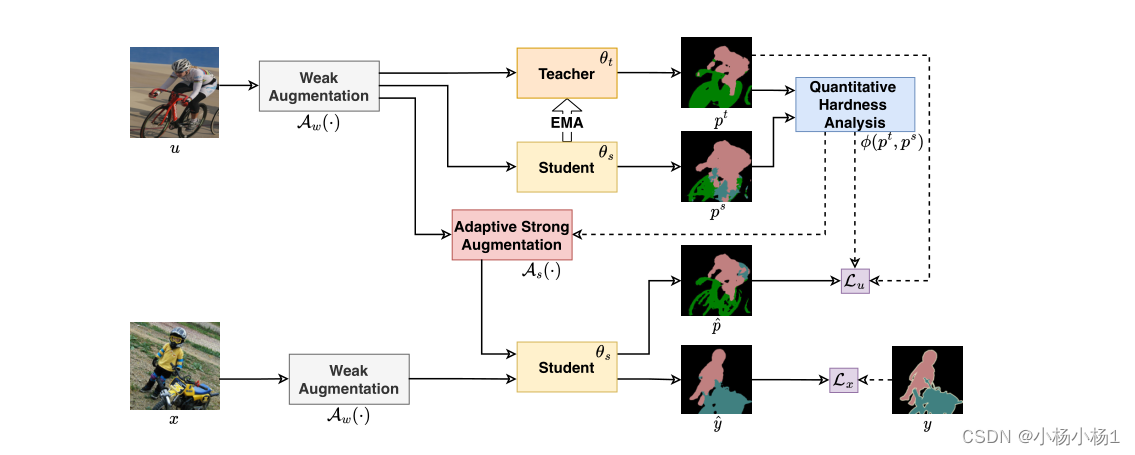
提出的iMAS示意图。在师生框架中,通过最小化监督损失Lx,使用标记数据(x,y)来训练由θs参数化的学生模型。
未标记的数据u,由Aw(·)弱增广,首先被输入到学生和教师模型中,以分别获得预测ps和pt。
通过策略ξ(pt,ps)对每个未标记的实例进行定量硬度评估。这样的硬度信息随后可以被利用:
1)在未标记的数据上应用自适应增强,用As(·)表示,以获得学生模型的预测;
2) 以特定实例的方式对无监督损失Lu进行权衡。教师模型的权重θt由指数移动平均值(EMA)更新。

弱扩充Aw包括标准的调整大小、裁剪和翻转操作。重要的是,利用未标记数据的方法是半监督学习的关键,也是将我们的方法与其他方法区分开来的关键部分。
Quantitative hardness analysis
在半监督分割中,在1)缺乏准确的基本事实标签和2)与模型性能密切相关的动态变化的情况下,评估未标记数据的硬度是具有挑战性的。随着模型的发展,“硬”样本可能会变得更容易,但如果没有准确的标签信息,就无法轻易识别这种动态。
本文在学生和教师模型的分割结果之间设计了一个对称的类加权IoU来评估瞬时硬度。类加权设计用于缓解分割任务中的类不平衡问题。
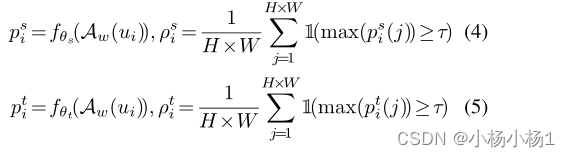
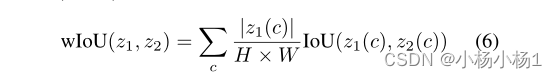
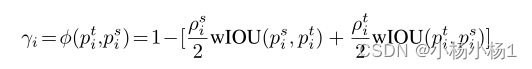
Model-adaptive supervision
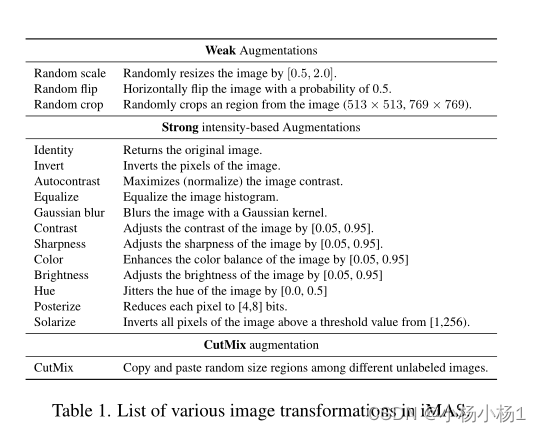
最近的半监督分割研究中流行的强增强主要由两种不同类型组成:基于强度的增强和CutMix,如表1所示。在iMAS中,我们将特定于实例的调整应用于这两种类型的增强
Intensity-based augmentations
标准的基于强度的数据增强从增强池中随机选择两种图像操作,并将它们应用于弱增强实例。
然而,强增强可能会损害数据分布并降低分割性能,尤其是在早期训练阶段。
与特定于分布的设计不同,我们只是通过混合其强增强和弱增强输出来调整未标记实例的增强程度。
形式上,第i个未标记实例的最终扩充输出AIs(ui)可以通过以下方式获得:
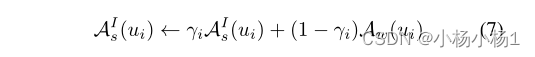
其中由基于强度的强增强引起的失真被相应的弱增强输出成比例地削弱。通过这种方式,硬度较大的较难实例不会受到显著干扰,因此模型不会在潜在的分布外情况下受到挑战。另一方面,模型很好地拟合了γ值较低的更容易的实例,可以从它们的强强化变体中进一步学习。这种模型自适应增强可以更好地适应模型的泛化能力
CutMix-based augmentations
通过模型自适应设计改进了标准CutMix,这在两个方面是不同的:1)平均硬度决定了CutMix在小批量上增加的触发概率,而不是使用预定义的超参数;2) 复制和粘贴对专门分配在硬样本和易样本之间。根据实例硬度,我们分别按升序和降序对小批量的未标记样本进行排序,得到两个序列。然后,我们逐个元素地聚合两个序列,以生成难易对。形式上,给定一个特定的hardeasy对(um,un),模型自适应CutMix可以表示为,
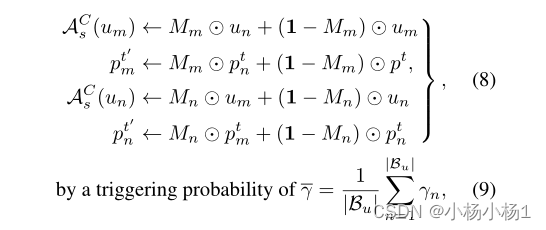
其中Mm和Mn分别表示um和un的随机生成的区域掩模。此外,在应用CutMix数据增强,获得pt′m和pt′n后,需要对伪标签进行相应的修改。这种相互增强是在伯努利过程之后应用的,即只有当均匀随机概率高于平均硬度时才触发
Model-adaptive unsupervised loss
优先考虑简单样本的训练,而不是困难样本的训练。准确地说,我们通过乘以1−γ来评估每个实例的无监督损失的相应易失性。结合模型自适应增强,我们可以通过
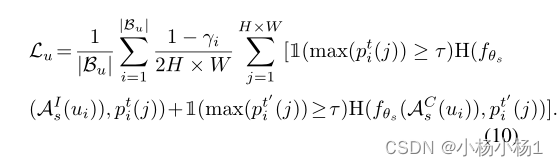
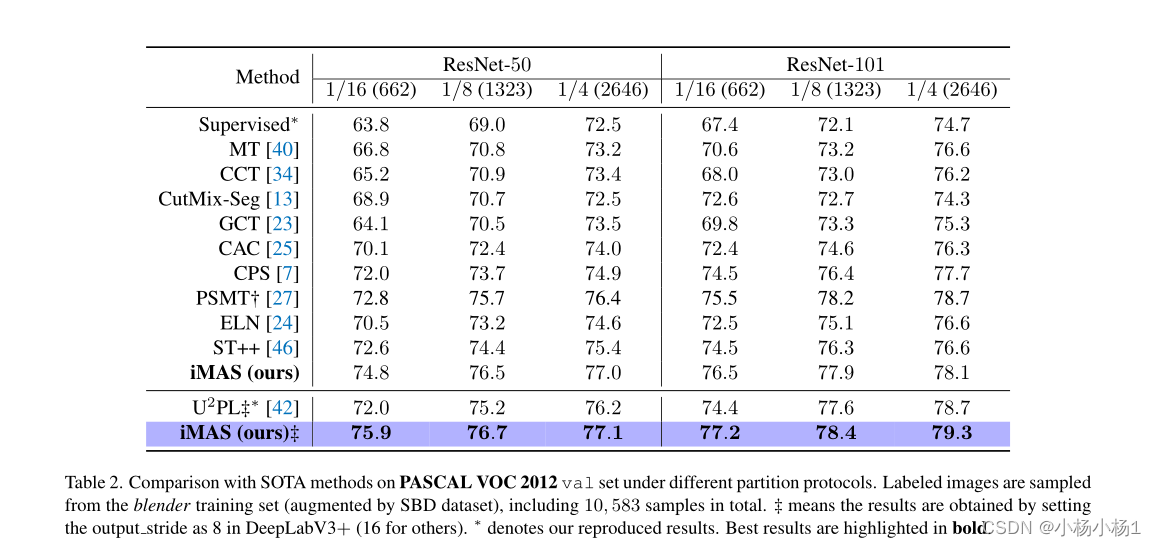
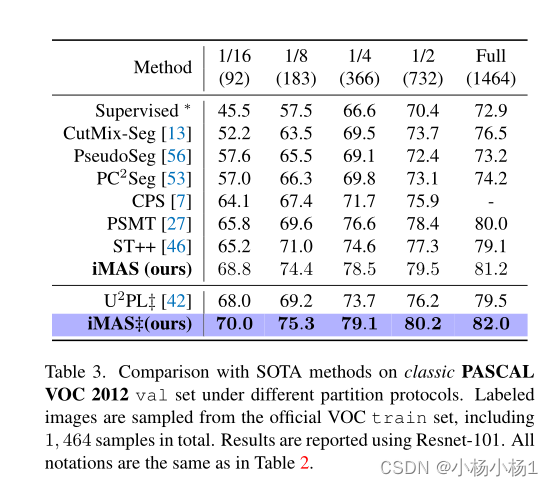
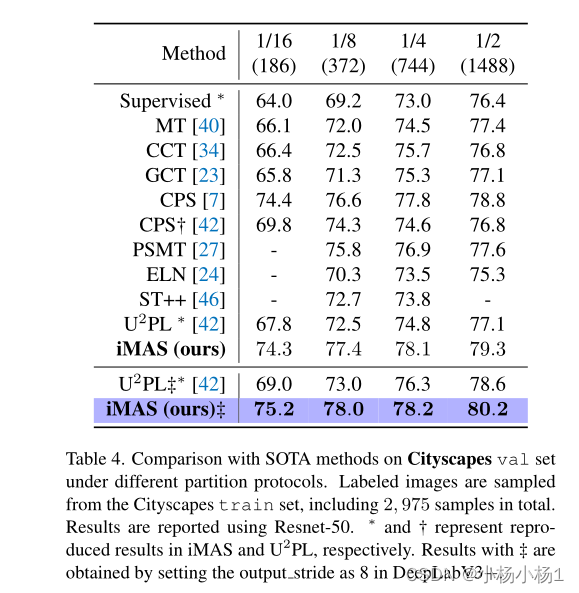
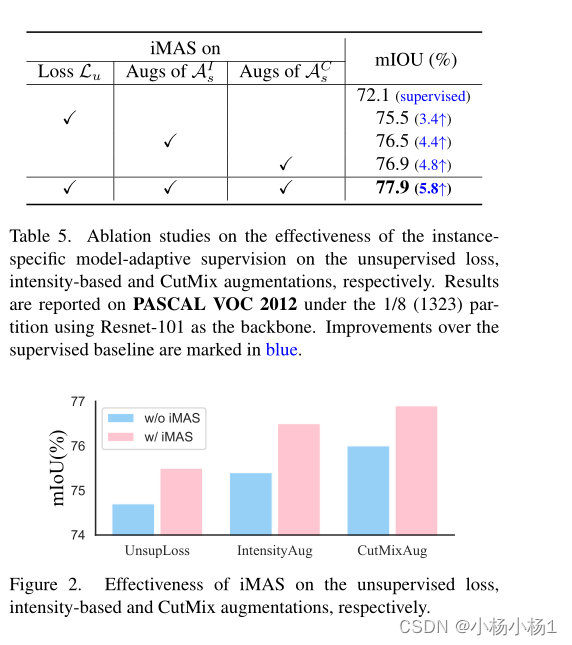
实验结果