Matching
ER的核心是匹配任务,它接收一个块集合作为输入,对于一个块中的每一对候选匹配,它决定它们是否指向相同的真实世界实体。
Preliminaries
匹配决策通常由匹配函数MMM做出,它将每一对实体描述(ei,ej)(e_{i}, e_{j})(ei,ej)映射到{true,false}\{true, false\}{true,false},其中M(ei,ej)=trueM(e_{i}, e_{j}) = trueM(ei,ej)=true表示eie_{i}ei和eje_{j}ej是匹配的,M(ei,ej)=falseM(e_{i}, e_{j}) = falseM(ei,ej)=false表示eie_{i}ei和eje_{j}ej不是匹配的。在最简单的形式中,MMM是通过一个相似函数simsimsim来定义的,该函数根据某些比较属性度量两个实体之间的相似程度。simsimsim可以包含一个原子相似性度量,如Jaccard相似性度量,也可以包含一个复合度量,例如,描述的不同属性上的多个原子相似性函数的线性组合。为了指定实体描述之间的等价关系,我们需要考虑一种满足非负性、恒等性、对称性和三角不等式性质的相似度量,即相似度量。给定相似阈值θθθ,一个简单的匹配函数可定义为:
M(ei,ej)={true,ifsim(ei,ej)≥θfalse,otherwiseM(e_{i}, e_{j})= \begin{cases} true,\quad if\ sim(e_{i}, e_{j})≥θ\\ false,\ otherwise \end{cases} M(ei,ej)={true,if sim(ei,ej)≥θfalse, otherwise
在更复杂的ER算法进程中,如手动提供匹配规则时,或从训练数据中学习时,可以将匹配函数MMM定义为包含多个匹配条件的复杂函数。例如,如果他们的SSN是相同的,或者他们的出生日期、邮政编码和姓氏是相同的,或者他们的电子邮件地址是相同的,那么两人的描述是匹配的。
通过对两个描述的属性值进行简单的两两比较,找到一个可以完美区分所有匹配和不匹配的相似性度量实际上是不可能的。特别是,相似性度量过于严格,无法识别接近相似的匹配。
因此,在现实中,我们寻求的相似函数只能是足够好的,即,最小化错误分类对的数量,并依靠集体ER方法将两个描述的实体邻居的相似度传播到这些描述的相似度。
在这个固有的迭代过程中,所采用的匹配函数是基于一个从迭代到迭代动态变化的相似性,其结果可能包括第三个状态,即不确定状态。具体来说,给定两个相似度阈值θθθ和θ′θ′θ′,θ′<θθ′<θθ′<θ,迭代nnn次时的匹配函数MnM_{n}Mn,由以下公式给出:
M(ei,ej)={true,ifsimn−1(ei,ej)≥θ,false,ifsimn−1(ei,ej)≤θ′,uncertain,otherwise.M(e_{i}, e_{j})= \begin{cases} true,\quad if\ sim^{n-1}(e_{i}, e_{j})≥θ,\\ false,\ if\ sim^{n-1}(e_{i}, e_{j})≤θ′,\\ uncertain,\ otherwise. \end{cases} M(ei,ej)=⎩⎨⎧true,if simn−1(ei,ej)≥θ,false, if simn−1(ei,ej)≤θ′,uncertain, otherwise.
根据实体集合的特点(如结构性、领域、规模)、比较的性质(基于属性或集体)以及已知的、预先标记的匹配对的可用性,可以采用不同的方法来确定适当的相似度函数,从而确定合适的匹配函数。在下文中,我们将探讨用于匹配任务的其他方法 并讨论这些方法更适合的情况。
5.2 Collective methods
为了尽量减少遗漏的匹配,通常对应于几乎相似的匹配,一个集体的ER过程可以联合发现相互关联的描述的匹配。集体ER过程可以联合发现相互关联描述的匹配。这是一个固有的迭代过程,需要额外的处理成本。我们区分了基于合并和基于关系的集体ER方法。
- 基于合并:In the former, new matches can be identified by exploiting the merging of the previously found matches.
- 基于关系:While in the latter, iterations rely on the similarity evidence provided by descriptions being structurally related in the original entity graph.
Example

Consider the descriptions in Figure, which stem from the knowledge base KB1. They all refer to the person Stanley Kubrick. Initially, it is difficult to match KB1:SKBRK with any other description, since many people named Kubrick may have been born in Manhattan, or died in the UK, respectively.
However, it is quite safe to match the first two descriptions (KB1:Stanley_Kubrick and KB1:Kubrick). By merging the first two descriptions, e.g., using the union of their attribute-value pairs, it becomes easier to identify that the last description (KB1:SKBRK) also refers to the same person, based on the name and the places of birth and death.
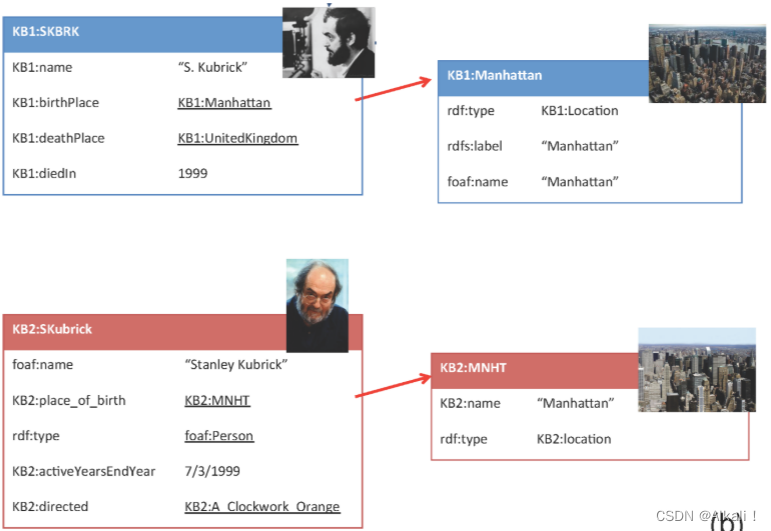
Consider now the descriptions in Figure, which stem from the knowledge bases KB1 and KB2. The descriptions on the left (KB1:SKBRK and KB2:SKubrick) represent Stanley Kubrick, while the descriptions on the right (KB1:Manhattan and KB2: MNHT) represent Manhattan, where Kubrick was born. Initially, it is difficult to identify the match between the descriptions on the left, based only on the common year of death and last name. However, it is quite straightforward to identify the match between the descriptions of Manhattan, on the right. Having identified this match, a relationship-based collective ER algorithm would re-consider matching KB1:SKBRK to KB2:SKubrick, since these descriptions are additionally related, with the same kind of relationship (birth place), to the descriptions of Manhattan that were previously matched. Therefore, a relationship-based ER algorithm would identify this new match in a second iteration.
请注意,待处理的输入实体集合的结构特征是决定集体方法性质的一个关键因素。
基于合并的方法通常是模式感知的,因为结构化的数据使合并的过程更容易。
另一方面,处理半结构化数据的集体方法通常是基于关系的,因为merging would require deciding not only which values are correct for a given attribute, but also which values are available for similar attributes and can be used to merge two descriptions.合并不仅需要决定 哪些值 对给定的属性是正确的,还需要决定 哪些值 对类似的属性是可用的,并且可以用来合并两个描述。
Schema-aware methods
在基于合并的集体ER中,两个描述之间的匹配决策会触发一个合并操作,通过添加新的、合并的描述并可能删除两个初始描述来改变初始实体集合。这一变化也触发了匹配决策的更多更新,因为新的、合并的描述需要与集合的其他描述进行比较。
直观地说,基于合并的集体ER的最终结果是一个新的实体集合,它是 合并在初始集合中发现的所有匹配的结果。换句话说,解析结果中的描述与输入实体集合中的实际现实世界实体之间应该有1-1的对应关系。
将匹配MMM和合并µµµ的功能视为黑盒,Swoosh是一个基于合并的集体ER策略族,它可以最小化对这些潜在昂贵的黑盒的调用次数;D-Swoosh引入了一系列算法,这些算法将基于合并的ER的工作负载分配到多个处理器上。这两种工作都依赖于以下一组ICAR特性,当MMM和µµµ满足时,会得到更高的效率:(幂等性、交换性、结合性、表征性)
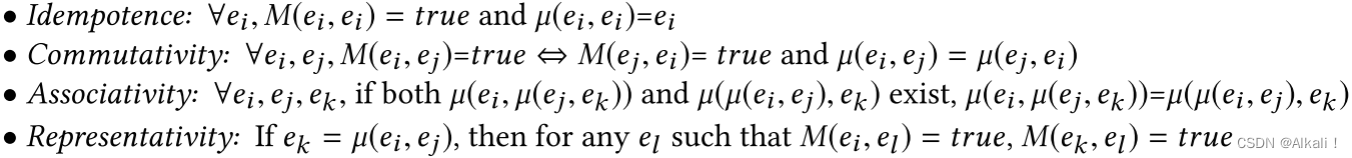
关于匹配函数,幂等性和交换性已经讨论过,分别记作自反性和对称性,而表征性通过包括合并函数扩展了传递性。 请注意,如果相关性不成立,解释合并的描述就变得更加困难,因为它取决于源描述合并的顺序。
R-Swoosh利用ICAR属性如下所示。
- 初始化实体描述集EEE以包含所有输入描述
- 然后,在每次迭代中,从EEE中删除描述eee,并将其与最初为空的集合E′E'E′的每个描述e′e'e′进行比较。 如果发现eee和e′e'e′匹配,那么它们分别从EEE和E′E'E′中移除,它们合并的结果放在E中(利用表征性)。 如果没有与eee匹配的描述e′e'e′,那么eee就放在E′E'E′中
- 这个过程一直持续到EEE变为空,即没有更多的匹配项可以找到
在基于关系的集合ER中,两个描述之间的匹配决策触发发现新的候选对进行解析,或者重新考虑已经比较的对; 匹配的描述可能与其他描述相关,这些描述现在更有可能相互匹配。
为了说明实体集合ϵ\epsilonϵ的描述之间的关系,通常使用实体图graphGϵ=(V,E)graphG_{\epsilon} = (V, E)graphGϵ=(V,E),其中节点V⊆ϵV ⊆ \epsilonV⊆ϵ表示实体描述,边EEE反映节点之间的关系。 例如,这样的匹配函数的形式可以是:
M(ei,ej)={true,ifsim(nbr(ei),nbr(ej))≥θfalse,else,M(e_{i}, e_{j})= \begin{cases} true,\quad if\ sim(nbr(e_{i}), nbr(e_{j}))≥θ\\ false,\ else, \end{cases} M(ei,ej)={true,if sim(nbr(ei),nbr(ej))≥θfalse, else,
其中simsimsim可以是一个关系相似度函数,θθθ是一个阈值。 直观地说,节点eee的邻域nbr(e)nbr(e)nbr(e)可以是与e相连的所有节点的集合,即nbr(e)={ej∣(e,ej)∈E}nbr(e)=\{e_{j}|(e,e_{j})∈E\}nbr(e)={ej∣(e,ej)∈E},也可以是包含eee的边的集合,即nbr(e)={(e,ej)∣(e,ej)∈E}nbr(e)=\{(e,e_{j})|(e,e_{j})∈E\}nbr(e)={(e,ej)∣(e,ej)∈E}。
Collective ER采用实体图,遵循这样的直觉:如果两个节点的边连接到对应于同一实体的节点,则它们更有可能匹配。为了捕捉这种迭代的直觉,进行了分层聚类,在每次迭代中,两个最相似的聚类被合并,直到最相似的聚类的相似度低于一个阈值。当两个聚类被合并时,其相关聚类的相似性,即与合并后的聚类中的描述相关的描述所对应的聚类,将被更新。为了避免比较所有的输入描述对,最初应用了天幕聚类法。
Hybrid Collective ER是基于部分合并的结果和描述之间的关系。它构建了一个依赖图,其中每个节点代表一对实体描述之间的相似度,每条边代表两个节点的匹配决定之间的依赖关系。如果一对描述的相似度发生变化,这对描述的邻居可能需要重新计算相似度。匹配决定之间的依赖关系有布尔值和实值之分。前者表明,一个节点的相似性只取决于其邻居节点的描述是否匹配,而在实值依赖关系中,一个节点的相似性取决于其邻居节点的描述的相似性。布尔依赖关系又分为强(如果一个节点对应于一个匹配,它的邻居对也应该是一个匹配)和弱(如果一个节点对应于一个匹配,它的邻居对的相似度会增加)。最初,所有节点被添加到一个优先级队列中。在每次迭代中,一个节点被从队列中移除,如果该节点的相似度高于阈值,其描述将被合并,聚合其属性值,以实现进一步的匹配决策;如果该节点的相似度值增加,其邻居节点将被添加到优先队列中。这个迭代过程一直持续到优先级队列变空。
Schema-agnostic methods
研究了树状(XML)数据的集体ER。实体描述对应于由文本数据或其他XML元素组成的XML元素,领域专家指定哪些XML元素是匹配候选者,从而初始化一个优先比较队列。
在这种情况下,实体依赖性采取以下形式:如果c′c′c′是ccc的描述的一部分,那么一个XML元素ccc依赖于另一个XML元素c′c′c′。即使两个XML元素最初被认为是不匹配的,如果它们的相关元素被标记为匹配,它们也会被再次比较。一个类似的方法是基于这样的直觉:两个元素的相似性反映了它们的数据的相似性,以及它们的子元素的相似性。在对XML数据进行自上而下的遍历之后,DELPHI包含度指标被用来比较两个元素。
Example
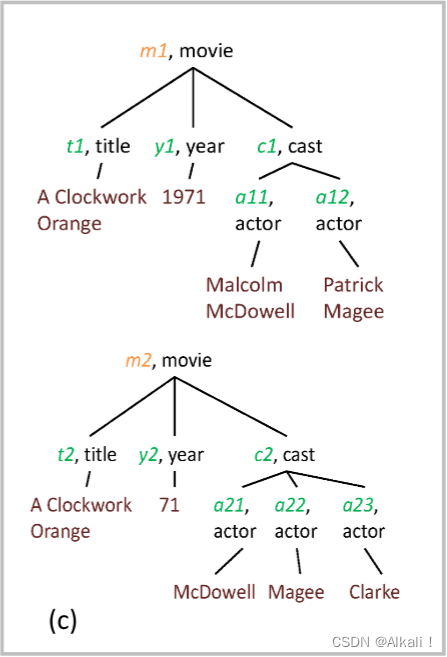
Figure shows two different descriptions of the movie A Clockwork Orange in XML. This representation means that the element movie consists of the elements title, year and cast, with the last one further consists of actor elements.
To identify that the two XML descriptions represent the same movie, we can start by examining the cast of the movies. After we identify that actors a11 and a21 represent the same person, Malcolm McDowell, the chances that the movies m1 and m2 match are increased. They are further increased when we find that actors a12 and a22 also match, representing Patrick Magee. The same matching process over all the sub-elements of m1 and m2 will finally lead us to identify that m1 and m2 match.
SiGMa选择具有相同实体名称的配对作为种子匹配。然后,它将匹配决定传播到现有匹配的兼容邻居上。唯一映射聚类法被用于检测重复的内容。对于每一个新的匹配对,邻居的相似性被重新计算,他们在优先级队列中的位置也被更新。
LINDA遵循一个非常相似的方法,它与SiGMa的不同之处主要在于相似性函数和缺乏人工关系对齐。LINDA依靠两个知识库中使用的关系名称的编辑距离来确定它们是否等同。这种对齐方法做了一个强有力的假设,即知识库中的描述对关系使用有意义的名称,对等价关系使用相似的名称,这在数据网络中往往是不真实的。LINDA的解析过程没有使用相似性阈值,而是在优先级队列为空时,或者在执行了预定的迭代次数后终止。
RIMOM-IM最初将放置在大小为2的块中的实体视为匹配。 它还使用了一种叫做“单左对象”的启发式:如果两个匹配的描述e1,e′1e1,e'1e1,e′1通过对齐关系RRR和R′R'R′连接起来,并且除了e2e2e2和e′2e'2e′2之外,它们通过RRR和R′R'R′的所有实体邻居都是匹配的,那么e2,e′2e2,e'2e2,e′2也被认为是匹配的。 与SiGMa类似,RIMOM-IM使用复杂的相似性评分,这要求KB之间的关系对齐。
PARIS基于先前的匹配和实体关系的功能性质,使用概率模型来识别匹配证据。 如果对于给定的源实体,只有一个目的实体(例如,wasbornin),那么关系被认为是函数关系。 基本的匹配思想是,如果R(x,y)R(x,y)R(x,y)是一个KB中的函数,而R(x,y′)R(x,y′)R(x,y′)是另一个KB中的函数,那么YYY和Y′Y′Y′被认为是匹配的。 函数性,即关系接近于函数的程度,以及关系与先前匹配决策的对齐决定了后续迭代中的决策。 每个关系的功能在算法开始时计算,并保持不变。 最初,具有相同值(对于所有属性)的实例被认为是匹配的,并基于这些匹配进行关系对齐。 在每次迭代中,基于新的对齐关系来比较实例,这个过程一直持续到收敛。 在最后一步中,还进行类(即实体类型)的对齐。
在另一条研究路线上,MinoanER执行了一个非迭代过程,涉及四个匹配规则。首先,它根据它们的名字来识别匹配(规则R1)。这是一个非常有效和高效的方法,可以适用于所有的描述,无论其价值或相邻的相似性如何,通过自动指定基于数据统计的实体的独特名称。然后,利用价值相似性来寻找具有许多常见和不常见的标记的匹配,即强相似匹配(规则R2)。当价值相似度不高时,使用无阈值的等级聚合函数,根据价值和邻居相似度来识别近似的匹配(规则R3)。最后,利用相互匹配的证据作为对返回结果的验证:只有相互排在其统一排名列表中最匹配的候选位置的实体才被视为匹配(规则R4)。
Learning-based methods
ER的第一个概率模型使用属性相似性作为比较向量的维度,每个维度表示一对描述匹配的概率。 遵循相同的概念模型,大量的工作试图基于人工或自动生成的,甚至预先存在的训练数据来自动化学习这些概率的过程。 接下来,我们探讨了生成和利用训练数据的不同方法。
Supervised Learning
Adaptive Matching从训练数据中学习一个组合了许多属性相似性度量的复合函数。 类似地,Marlin在两个层次上使用标记数据。 首先,它可以利用可训练的字符串相似度/距离度量,如可学习的编辑距离,使文本相似度计算适应特定的属性。 其次,它使用标记数据训练一个分类器,以不同属性的文本相似度值作为特征来区分匹配和非匹配对。
Gradient-based Matching提出了一种模型,该模型可以根据来自不同属性的单个相似函数的聚合相似度得分来调整其结构和参数。 它的设计允许定位哪些相似函数和属性更重要,以正确分类对。 对于它的训练,它使用了一个性能指数,该指数有助于将已经匹配的描述与尚未匹配的描述分开。
BN-based Collective ER将基于关系的集体ER方法适应于监督学习设置。 贝叶斯网络用于捕获因果关系,并计算匹配概率,因果关系被建模为有向无环图。 描述的属性值中的词法相似性以及它们与现有匹配的链接构成了正的匹配证据,它增量地更新贝叶斯网络节点,类似于基于图的依赖模型中发生的增量更新。
GenLink是一种有监督的遗传编程算法,用于学习表达性链接规则,即为描述对分配相似性值的函数。 GenLink生成链接规则,该规则选择用于比较两个描述的重要属性,在相似性计算之前对其属性值进行归一化,选择适当的相似性度量和阈值,并使用线性和非线性聚合函数将多次比较的结果结合起来。 它已被纳入Silk Link发现框架。
Weakly Supervised Learning
可以说,有监督方法的最大限制是需要一个有标记的数据集,基础机器学习算法将基于该数据集学习如何分类新的实例。 此类方法降低了获取此类数据集的成本。
文献[173]提出了一种迁移学习方法,目的是适应和重用相关数据集中的标记数据。 其思想是使用一个标准化的特征空间,在该空间中,重用数据集和目标数据集的实体嵌入将被转移。这样,即使目标数据集没有显式标记的数据,也可以使用来自另一个数据集的已有标记数据来训练一个分类器,该分类器可以与目标数据集一起工作。 在[152]中也遵循了类似的迁移学习方法来推断链接数据设置中的等效链接。
Snorkel[149]是一个通用工具,可以用来为比ER更广泛的问题生成训练数据。 它依赖于用户提供的启发式规则(例如,几个匹配函数)来标记一些用户提供的数据,并使用一个小的预先标记的数据集来评估该标记。 Snorkel尝试学习提供的匹配函数的重要性,而不是属性加权。 这种对匹配规则进行加权而不是对特征进行加权的方法与ER中已有的工作相类似和补充。 例如,[184]中的目标是在给定一组正反示例的情况下,确定哪种相似性度量可以最大化ER任务的特定目标函数。 这些示例可以逐个手动生成,也可以利用Snorkel之类的工具生成。
Unsupervised Learning
Unsupervised Ensemble Learning生成使用不同相似性度量的自动自学习模型的集成。 为了提高自学习过程的自动化程度,在每个自学习模型的自动种子选择中加入属性权重。 为了保证所选自学习模型之间具有较高的多样性,它采用了一种无监督的多样性度量。 在此基础上,保留贡献率高的自学习模型,舍弃精度差的自学习模型。
在[102]中提出的无监督ER系统不依赖于领域专家或人工标记的样本,而是自动生成自己的启发式训练集。 作为正例,我们认为这对描述的标记集在其属性值上具有非常高的Jaccard相似性。 在Clean-Clean ER的上下文中,在生成了正例(e1,e2)(e1,e2)(e1,e2),其中e1e1e1属于实体集合ϵ1\epsilon1ϵ1,e2e2e2属于实体集合ϵ2\epsilon2ϵ2,对于每个其他正例(e3,e4)(e3,e4)(e3,e4),其中e3∈ϵ1e3∈\epsilon1e3∈ϵ1和e4∈ϵ2e4∈\epsilon2e4∈ϵ2,进一步推论出反例(e1,e4)(e1,e4)(e1,e4)和(e3,e2)(e3,e2)(e3,e2)。 系统首先使用得到的训练集进行模式匹配,以对齐输入数据集中的属性。 然后使用属性对齐和训练集同时学习两个函数,一个用于分块,另一个用于匹配。
Parallel methods
我们现在讨论能够利用大规模并行化框架的工作。
在[148]中提出了一个将集体ER[16]扩展到大数据集的框架,并假设了一个黑盒ER算法。为了实现高可伸缩性,它在实体描述的小子集中运行ER算法的多个实例。使用Canopy Clustering基于描述的相似性构建初始块集合[118]。然后,每个块通过其实体关系的边界进行扩展。接下来,运行一个简单的消息传递算法,以确保一个块中的匹配决策(可能会影响其他块中的匹配决策)被传播到其他块中。这个算法保留一个活动块列表,它最初包含所有块。黑盒ER算法在本地运行,对于每个活动块,将新识别出的匹配项添加到结果集中。所有对新识别出的匹配项有描述的块都被设置为活动块。当活动块列表变为空时,此迭代算法终止。
LINDA使用MapReduce扩展。描述对按照相似性降序排序,并存储在优先队列中。每个集群节点持有:
(i)该优先队列的一个分区,(ii)实体图的相应部分,其中包含本地优先队列分区中的描述以及它们的邻居。
算法的迭代步骤是,默认情况下,优先队列中的第一对被认为是匹配的,然后从队列中删除并添加到已知的匹配中。
这一知识触发了相似度的重新计算,它通过以下方式影响优先队列:(i)扩大它,当新的匹配的邻居再次添加到队列中,(ii)重新排序,当识别的匹配的邻居在秩上移动得更高,或(iii)收缩它,在应用传递性和每KB唯一匹配的约束后。当优先级队列为空或经过特定次数的迭代后,算法将停止。
最后,Minoan-ER[56]运行在Apache Spark之上。为了最小化它的总体运行时,它应用了名称阻塞,同时提取每个实体顶部类似的邻居,并运行令牌阻塞。然后,它同步最后两个进程的结果:它将通过令牌阻塞计算出的值相似度与每个实体的顶部邻居相结合,以估计邻居同时出现在至少一个块中的所有实体对的邻居相似度。匹配规则R1(根据它们的名称寻找匹配)在名称阻塞之后立即开始,R2(寻找强烈相似的匹配)在H1和令牌阻塞之后,R3(寻找接近相似的匹配)在R2和计算邻居相似度之后,而R4(互惠过滤器)最后运行,提供最终的、过滤的匹配集。在每个规则的执行过程中,每个Spark worker只包含块图的部分信息,这是寻找特定节点的匹配所必需的。
Discussion
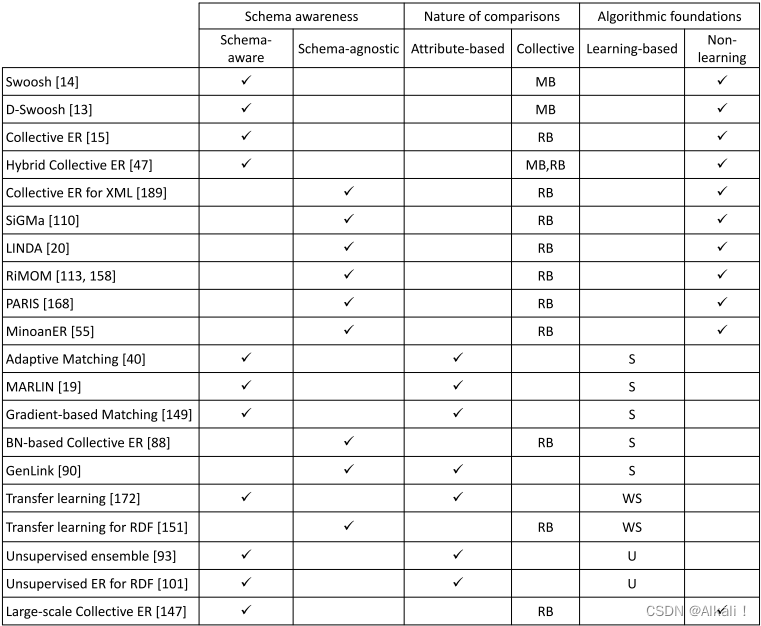
表中给出了本节中讨论的匹配方法的概述。它们根据模式感知(模式感知或模式不可知)、比较的性质(基于属性或集体)和算法基础(非学习或基于学习)进行组织。集合方法被进一步细化为基于合并(MB)或基于关系(RB),基于学习的方法被细化为有监督(S)、弱监督(WS)和无监督(U)。
我们注意到,所有已经提出的与模式无关的方法都是集体的,更具体地说,是基于关系的。发生这种情况的原因是,与模式感知的方法不同,模式无关的方法不能依赖于属性级别的相似性,因为这些属性事先不知道,或者不知道描述是否实际使用它们。因此,这些方法在可能的情况下传播实体邻居提供的信息作为匹配证据。
因此,根据经验法则(取决于输入数据的性质):
- 对于来自单个脏实体集合的数据(例如,用于脏客户数据库的重复数据删除),我们推荐基于合并的集体ER方法(模式感知)
- 对于来自多个经过管理的实体集合的数据(例如,用于在两个或多个Web KBs中寻找等效描述),我们推荐基于关系的集体ER方法(模式无关)
请注意,基于学习的方法可以被视为基于属性的方法,因为它们本质上试图学习两个描述匹配的概率,这是基于之前的类似对的例子,或集合,因为它们的模型是在对集合上训练的,甚至是实体描述的向量表示,或这些描述值中使用的单词。为了完整起见,表3将它们分类为基于属性的,遵循传统的学习方法,因为它们的集体性质不容易标记为基于合并或基于关系的。我们相信,随着表示个体或实体描述组的新的、更有效的方法的出现,基于学习的方法正在取得进展(见9.1节)。弱监督和迁移学习方法的出现似乎缓解了为训练数据生成标记集的问题。因此,当有标记的示例可用(如迁移学习中),或易于使用现有工具生成(如[149]),且测试数据预计不会与训练数据有很大偏差时,这些方法似乎是最有希望的方法。在选择基于学习的方法或非学习的方法之前,还应该考虑希望重新训练一个新的分类模型的频率、每种方法的内存占用(即整个模型是否需要驻留在内存中)以及训练和分类所需的时间。
总的来说,最近的研究[52,104,122]表明,在一些实际场景中,基于学习的技术比基于规则的技术获得了更高的准确性。然而,尽管过去做了一些努力(例如,[90,105,106]),我们注意到缺乏系统的匹配方法基准。一个全面的基准应该评估有效性(即输出匹配的质量),时间和空间效率(即预处理、训练和匹配所需的时间,每种方法所需的内存和磁盘空间),以及可伸缩性(即,使用相同的计算和存储资源,每种方法可以处理的数据限制)。