附件下载链接
复杂的字符串混淆
原理
之前的字符串混淆是一次性解密的,找到解密函数即可获得所有字符串,同时执行解密函数后内存中也可直接获得所有字符串。
因此对抗人员升级了混淆技术,使得解密仅在使用时发生,从而避免了全部泄露的问题。
常见的形式是提供一个函数获取解密字符串,通过参数来决定返回的字符串。
对抗
同样分为静态和动态两种。
静态解密可以直接获取可分析到的全部引用点,但缺点也是同样的,可能会遗漏掉动态解密的引用点,例如SMC代码自解密技术。
动态记录虽然能够捕捉所有执行到的解密,但无法记录未被执行到的分支,对于需求代码的搜索能力较差。
因此这两种技术通常结合起来使用。
静态解密
简介
主要思路是
- 分析算法,编写解密函数
- 通过解密函数的交叉引用获得分析到的调用点
- 解析汇编提取参数
- 批量调用解密函数获得参数与字符串的对应表
- 注释至代码中
操作
以手游欢乐斗地主为例,解析它的动态链接库中的字符串混淆。
用JEB或zip压缩软件提取 hlddz.apk 中的 /lib/armeabi/libtprt.so 。
JNI_OnLoad 函数内容如下:
jint JNI_OnLoad(JavaVM *vm, void *reserved)
{void *v3; // r0int v4; // r0JNIEnv *v5; // r5char *v6; // r0void *v7; // r1JNIEnv *v9; // [sp+0h] [bp-418h] BYREFchar v10[1044]; // [sp+4h] [bp-414h] BYREFv3 = j_memset(v10, 0, 0x400u);v4 = j_getpid(v3);sub_F4A4(v4, v10, 1024);if ( &v9 == (JNIEnv **)&ptrace )j_exit(0);if ( (*vm)->GetEnv(vm, (void **)&v9, (jint)&loc_10004) )return -1;v5 = v9;if ( !v9 )return -1;v6 = sub_14084(329);v7 = (void *)sub_720C(v5, v6);if ( !v7 || (*v5)->RegisterNatives(v5, v7, &stru_56004, 13) < 0 )return -1;sub_29FB4(v9);return (jint)&loc_10004;
}
其中 RegisterNatives 中的 stru_56004 类型为 JNINativeMethod ,定义如下:
typedef struct { const char* name; const char* signature; void* fnPtr;
} JNINativeMethod;
然而实际观察发现 JNINativeMethod 中的字符串指针为空,怀疑存在字符串混淆。

查找该结构引用发现了 .init_array 中的 sub_6ED0 函数。该函数通过指定 sub_14084 函数的参数进行字符串解密。
char *sub_6ED0()
{char *result; // r0dword_578D8 = 0;stru_56004.name = sub_14084(0);stru_56004.signature = sub_14084(66);dword_56010 = (int)sub_14084(14);dword_56014 = (int)sub_14084(199);dword_5601C = (int)sub_14084(27);dword_56020 = (int)sub_14084(41);dword_56028 = (int)sub_14084(1191);dword_5602C = (int)sub_14084(1222);dword_56034 = (int)sub_14084(804);dword_56038 = (int)sub_14084(1293);dword_56040 = (int)sub_14084((int)&stru_508.st_info);dword_56044 = (int)sub_14084(1319);dword_5604C = (int)sub_14084(2671);dword_56050 = (int)sub_14084(1319);dword_56058 = (int)sub_14084(1343);dword_5605C = (int)sub_14084(34);dword_56064 = (int)sub_14084(1357);dword_56068 = (int)sub_14084(34);dword_56070 = (int)sub_14084(1376);dword_56074 = (int)sub_14084(34);dword_5607C = (int)sub_14084(1397);dword_56080 = (int)sub_14084(34);dword_56088 = (int)sub_14084(2800);dword_5608C = (int)sub_14084(34);dword_56094 = (int)sub_14084(1511);result = sub_14084(1546);dword_56098 = (int)result;return result;
}
sub_14084 函数的内容如下:
char *__fastcall sub_14084(int p)
{int v2; // r2unsigned int _len; // r5int v4; // r6unsigned __int8 *cur; // r3int v6; // r1void *hash; // r3unsigned __int8 *v8; // r7int v9; // r2char *v10; // r1char v11; // r0unsigned int i; // r6unsigned __int8 *v13; // r3char v14; // r2char v15; // r0int v16; // r1unsigned __int8 *v17; // r1unsigned __int8 *v18; // r3int v19; // r2void *v20; // r3unsigned int len; // [sp+0h] [bp-30h]char flag; // [sp+4h] [bp-2Ch]_BYTE *str; // [sp+8h] [bp-28h]int v25; // [sp+Ch] [bp-24h]*(_DWORD *)&flag = cipher[p];if ( *(_DWORD *)&flag == 1 ){len = plain[p + 1];}else{v25 = p + 1;v2 = 0xFF;_len = cipher[p + 1] ^ *(_DWORD *)&flag;v4 = p + 2;cur = &cipher[p + 2];len = _len;str = cur;while ( cur - str < _len ){v6 = *cur++;v2 ^= v6;}hash = (void *)cipher[_len + 3 + p];if ( hash != (void *)v2 )error(str, _len + p, v2, hash);v8 = &plain[v4];v9 = (unsigned __int8)key[0];if ( !key[0] ){qmemcpy(&key[1], "123456789", 9);do{v10 = &key[v9];v11 = v9++ + 'A';v10[10] = v11;}while ( v9 != 26 );key[0] = '0';}for ( i = 0; i < _len; ++i )v8[i] = str[i] ^ key_16[(unsigned __int8)(flag + i) % 0x24u + 16];v13 = v8;v14 = 0xFF;while ( v13 - v8 < (int)_len ){v15 = *v13++;v14 ^= v15;}v8[_len + 1] = v14;v16 = _len + p + 2;p = 0;plain[v16] = 0;plain[p] = 1;plain[v25] = _len;cipher[v16] = 0;cipher[p] = 1;}v17 = &plain[p + 2 + len];v18 = &plain[p + 2];v19 = 0xFF;while ( v18 != v17 ){p = *v18++;v19 ^= p;}v20 = (void *)plain[len + 3 + p];if ( v20 != (void *)v19 )error((char *)p, (int)v17, v19, v20);return (char *)&plain[p + 2];
}
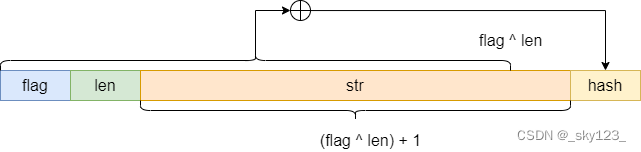
根据函数内容,首先可以大致确定出代码中定义的加密的字符串格式如下:
struct String {char key;char len;char str[len + 1];char hash;
}
首先判断加密的字符串的 flag 位是否为 1 ,如 flag = 1 则说明已经解密,不再对其进行解密,而是直接获取解密后字符的长度。
flag = cipher[p];if ( flag == 1 ){len = plain[p + 1];}
否则计算 hash 值验证数据是否正确。
v25 = p + 1;v2 = 0xFF;_len = cipher[p + 1] ^ flag;v4 = p + 2;cur = &cipher[p + 2];len = _len;str = cur;while ( cur - str < _len ){v6 = *cur++;v2 ^= v6;}hash = (void *)cipher[_len + 3 + p];if ( hash != (void *)v2 )error(str, _len + p, v2, hash);
计算过程如下图所示:
如果通过检测,则通过 key[0] 是否为 0 判断密钥是否初始化,若为初始化则将 key 填充为 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ 。
v9 = (unsigned __int8)key[0];if ( !key[0] ){qmemcpy(&key[1], "123456789", 9);do{v10 = &key[v9];v11 = v9++ + 'A';v10[10] = v11;}while ( v9 != 26 );key[0] = '0';}
之后将字符串异或 key 解密,结果存放在 plain 的对应位置上。
str = &cipher[p + 2];v8 = &plain[p + 2];for ( i = 0; i < _len; ++i )v8[i] = str[i] ^ key_16[(unsigned __int8)(flag + i) % 0x24u + 16];
这里 key_16 实际上是 key - 16
之后后为 解密的字符串计算 hash 值,写在 plain 的对应位置上,并更新 flag 以及把字符串最后一个元素置 0 。这里 p = 0; 操作有点奇怪,不过不影响结果。
v13 = &plain[p + 2];v14 = 0xFF;while ( v13 - v8 < (int)_len ){v15 = *v13++;v14 ^= v15;}v8[_len + 1] = v14;v16 = _len + p + 2;p = 0;plain[v16] = 0;plain[p] = 1;plain[v25] = _len;cipher[v16] = 0;cipher[p] = 1;
最后,不论是否解密过字符串,都要对解密后的字符串进行一次 hash 校验,然后返回指向该字符串的指针。
v17 = &plain[p + 2 + len];v18 = &plain[p + 2];v19 = 0xFF;while ( v18 != v17 ){p = *v18++;v19 ^= p;}v20 = (void *)plain[len + 3 + p];if ( v20 != (void *)v19 )error((char *)p, (int)v17, v19, v20);return (char *)&plain[p + 2];
根据前面的逆向分析可以写出对应的解密函数:
def sub_14084(p):flag = cipher[p]len = cipher[p + 1] ^ flagres = bytearray(len)for i in range(len):res[i] = cipher[p + 2 + i] ^ ord(key[((flag + i) & 0xFF) % 36])res = bytes(res)print(res)
查看 sub_14084 函数的引用,发现该函数有大量引用,且引用位置比较分散,因此考虑使用 IDAPython 脚本自动查找并解密。
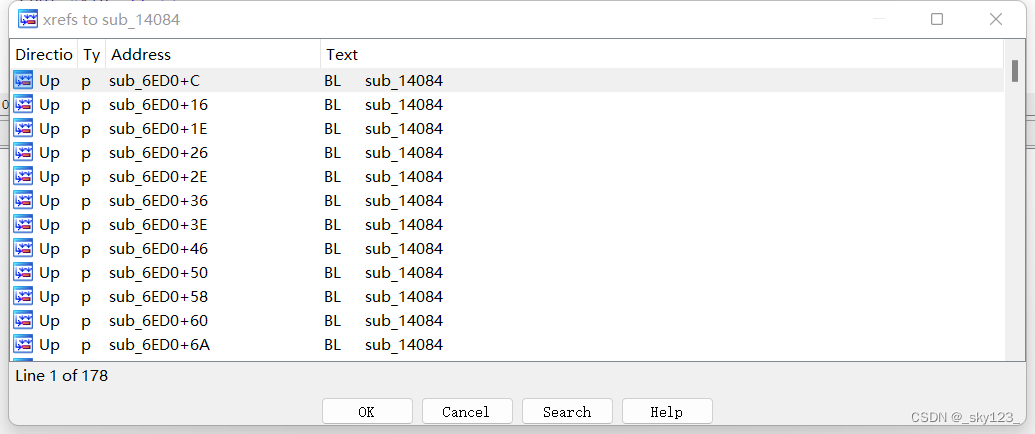
首先利用 CodeRefsTo 函数获取 sub_14084 函数的所有引用位置:
for addr in CodeRefsTo(0x14084, True):
在 ARM 汇编中,函数调用的参数如果只有一个,则采用 R0 传参,因此可以在该函数调用位置向上查询 R0 在何处被赋值,如果 R0 被另一个寄存器赋值则递归查询该寄存器在何处被赋值。最终在给寄存器符值的位置获取参数并调用事先写好的解密函数解密。在获取参数时主要先将参数类型修改为数字。
reg = "R0"
while True:while not ((print_insn_mnem(addr) == "MOVS" or print_insn_mnem(addr) == "LDR") and print_operand(addr, 0) == reg):addr = prev_head(addr)if get_operand_type(addr, 1) != o_reg:breakreg = print_operand(addr, 1)
ida_bytes.set_op_type(addr, ida_bytes.num_flag(), 1)
arg = int(print_operand(addr, 1).replace("=", "").replace("#", ""), 16)
sub_14084(arg)
完整代码如下:
import stringfrom idautils import *
from idc import *
import ida_byteskey = string.digits + string.ascii_uppercase
cipher = ida_bytes.get_bytes(0x56865, 3859)def sub_14084(p):flag = cipher[p]len = cipher[p + 1] ^ flagres = bytearray(len)for i in range(len):res[i] = cipher[p + 2 + i] ^ ord(key[((flag + i) & 0xFF) % 36])res = bytes(res)print(res)if __name__ == '__main__':for addr in CodeRefsTo(0x14084, True):print(hex(addr))reg = "R0"while True:while not ((print_insn_mnem(addr) == "MOVS" or print_insn_mnem(addr) == "LDR") and print_operand(addr, 0) == reg):addr = prev_head(addr)if get_operand_type(addr, 1) != o_reg:breakreg = print_operand(addr, 1)ida_bytes.set_op_type(addr, ida_bytes.num_flag(), 1)arg = int(print_operand(addr, 1).replace("=", "").replace("#", ""), 16)# print(print_insn_mnem(addr), hex(addr), hex(arg), get_operand_type(addr, 1))sub_14084(arg)
运行脚本,效果如下:

动态记录
简介
主要思路是通过Hook解密函数来获取它的入口参数和返回值。
可以通过以下几种方法实现:
- Hook框架,如Frida
- IDA的条件断点
- dll注入、PatchHook
操作
在前面对解密函数的分析中发现,函数参数是通过 R0 寄存器传递的,而指向解密后的字符串的指针也是通过 R0 寄存器返回的,因此可以通过 IDA 写调试脚本来动态获取解密后的字符串。
使用IDA,在解密函数开头0x14084和结尾0x141ba处各下一个断点。打开断点菜单Debugger - BreakPoints - Breakpoint list。
分别右击两个断点,选择Edit,点击Condition右端的"…"按钮,在弹出的脚本编辑框中输入下述代码(由于已经动调过,函数地址被重定位,与描述不一样):
0x14084 :
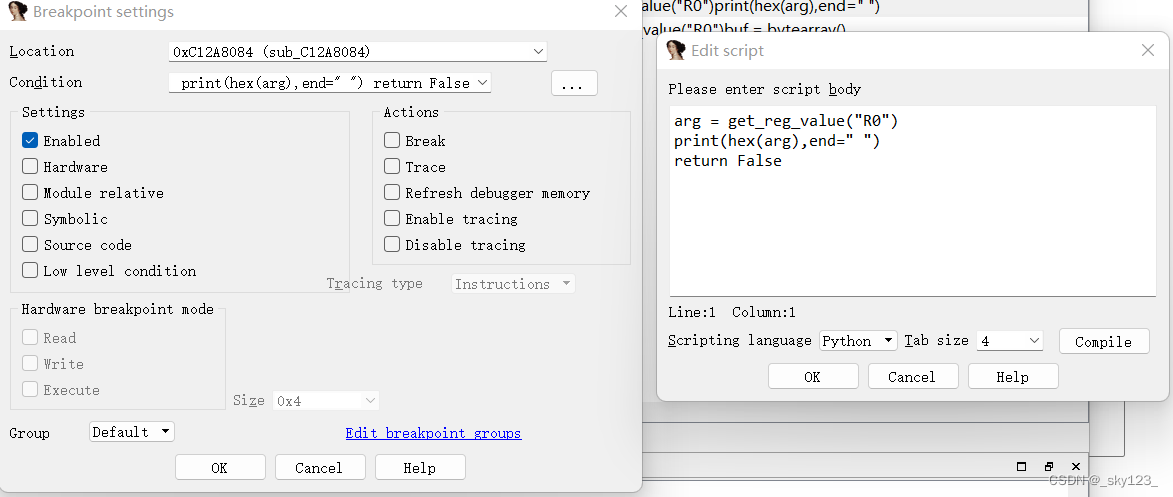
0x141BC :
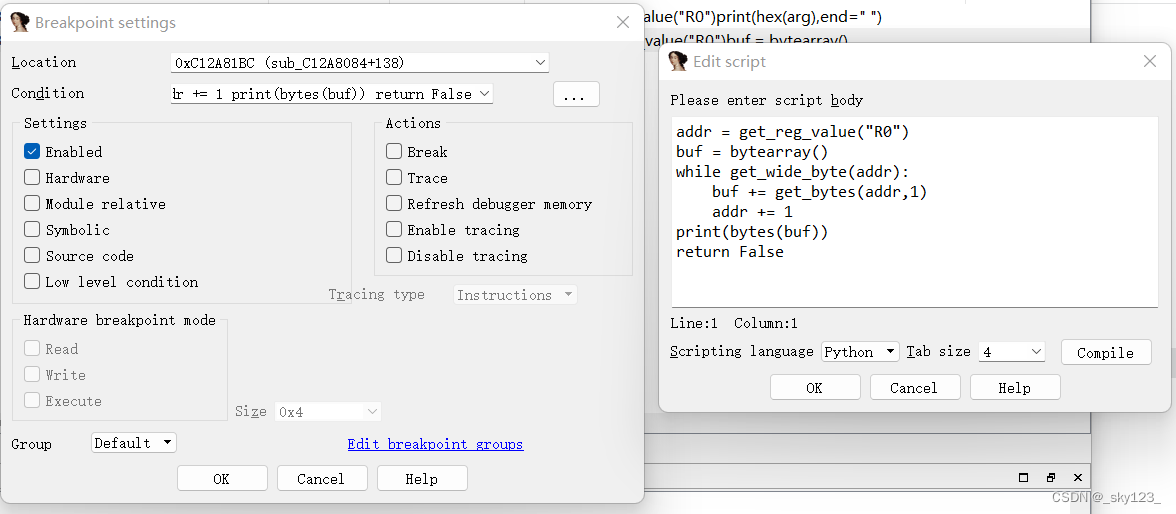
由于欢乐斗地主后面的代码存在反调试,并且很多字符串解密位于程序启动时,因此应当以调试模式启动,从程序的开始处开始调试。
调试启动根据 Manifest 中的第一个 Activity 的类名,调试模式启动程序的命令如下:
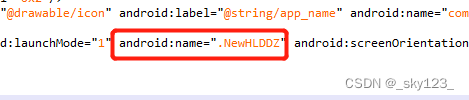
adb shell am start -D -n com.qqgame.hlddz/.NewHLDDZ
调试模式启动后首先用 ida 附加欢乐斗地主的动态库:
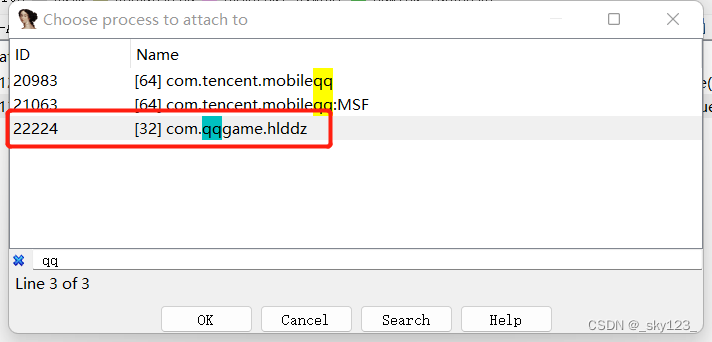
F9 继续执行后用 JEB 附加欢乐斗地主进程使其继续执行
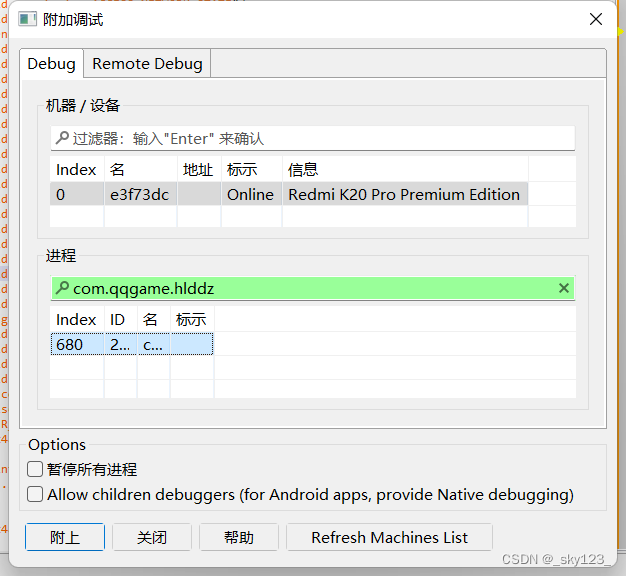
之后,解密的字符串被打印出来。

代码自解密
代码自解密基本情况
简介
代码自解密又叫SMC(Self Modifying Code),是一种加密代码的对抗技术。
原理
代码的本质也是一段数据,因此同样可以读写对应的机器码,从而修改代码。默认情况下.text段不可写,.data段不可执行。但可以通过设置编译选项,或修改文件头中的段属性来赋予它们权限,也可以通过mmap申请新的带有写属性和可执行属性的空间来解密代码并执行。
静态解密
以两个题目为例展示解密。
第一个题目babyRE,用IDA Pro(64位版本)打开它。
阅读代码可知对data段的judge数组逐字节异或0xc,然后跳转执行judge。
int __cdecl main(int argc, const char **argv, const char **envp)
{char s[24]; // [rsp+0h] [rbp-20h] BYREFint v5; // [rsp+18h] [rbp-8h]int i; // [rsp+1Ch] [rbp-4h]for ( i = 0; i <= 181; ++i )judge[i] ^= 0xCu;printf("Please input flag:");__isoc99_scanf("%20s", s);v5 = strlen(s);if ( v5 == 14 && (*(unsigned int (__fastcall **)(char *))judge)(s) )puts("Right!");elseputs("Wrong!");return 0;
}
解密的时候也只要对judge数组逐字节异或即可,比较简单。执行以下代码即可解密。
from idc import *
import ida_bytesaddr = get_name_ea_simple("judge")
content = bytearray(ida_bytes.get_bytes(addr, 182))
for _ in range(len(content)): content[_] ^= 0xC
ida_bytes.patch_bytes(addr, bytes(content))
解密后judge函数内容如下:
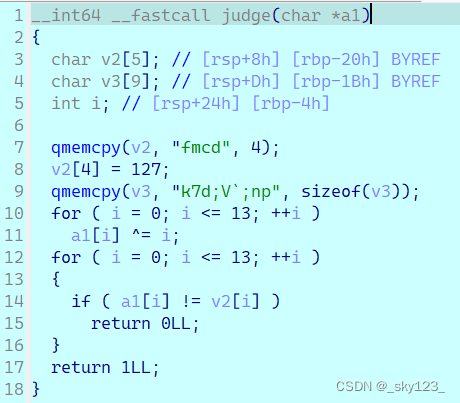
__int64 __fastcall judge(char *a1)
{char v2[5]; // [rsp+8h] [rbp-20h] BYREFchar v3[9]; // [rsp+Dh] [rbp-1Bh] BYREFint i; // [rsp+24h] [rbp-4h]qmemcpy(v2, "fmcd", 4);v2[4] = 127;qmemcpy(v3, "k7d;V`;np", sizeof(v3));for ( i = 0; i <= 13; ++i )a1[i] ^= i;for ( i = 0; i <= 13; ++i ){if ( a1[i] != v2[i] )return 0LL;}return 1LL;
}
第二个题目morph,用IDA Pro(64位版本)打开它。
main 函数内容如下:
__int64 __fastcall main(int a1, char **a2, char **a3)
{int i; // [rsp+14h] [rbp-1Ch]void *mem; // [rsp+18h] [rbp-18h]Node *node_1; // [rsp+20h] [rbp-10h]Node *node_2; // [rsp+28h] [rbp-8h]mem = mmap(0LL, 0x1000uLL, 7, 34, -1, 0LL);init_node(mem);memcpy(mem, code, 0x2F5uLL);if ( a1 != 2 )exit(1);if ( strlen(a2[1]) != 23 )exit(1);shuffle_node();for ( i = 0; i <= 22; ++i ){node_1 = array[i];node_2 = array[i + 1];if ( node_2 )node_1->function(&a2[1][node_1->id], node_2->function, (unsigned int)node_2->offset);elsenode_1->function(&a2[1][node_1->id], mem, 0LL);}puts("What are you waiting for, go submit that flag!");return 0LL;
}
阅读代码可知通过 mmap 申请了一段具备可读写可执行的空间,然后调用 init_node 函数初始化这段内存。其中 init_node 函数逻辑如下:
_QWORD *__fastcall init_node(void *mem)
{_QWORD *result; // raxint i; // [rsp+14h] [rbp-Ch]Node *node; // [rsp+18h] [rbp-8h]array = (Node **)malloc(0xC0uLL);for ( i = 0; i <= 22; ++i ){node = (Node *)malloc(0x10uLL);node->function = (void (__fastcall *)(char *, __int64, _QWORD))((char *)mem + 17 * i);node->offset = 17 * i;node->id = i;array[i] = node;}result = array + 23;array[23] = 0LL;return result;
}
由此可知程序中各结构关系如下:
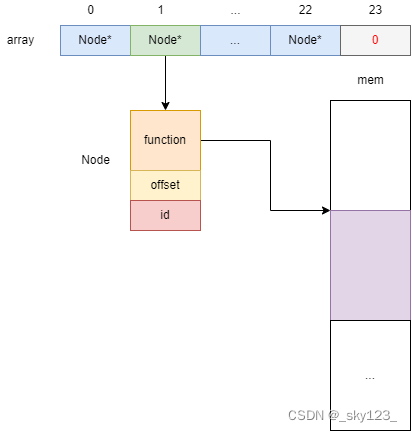
之后将 code 中的内容复制到 mem 中,code 实际上是未解密的代码。
接下来检验运行参数是否有输入内容以及输入内容长度是否等于 23 。如果两个检验均通过则会执行 shuffle_node 函数,该函数内容如下:
void shuffle_node()
{unsigned int t; // eaxint i; // [rsp+Ch] [rbp-14h]int j; // [rsp+10h] [rbp-10h]int k; // [rsp+14h] [rbp-Ch]Node *temp; // [rsp+18h] [rbp-8h]t = time(0LL);srand(t);for ( i = 0; i <= 255; ++i ){j = rand() % 22 + 1;k = rand() % 22 + 1;temp = array[j];array[j] = array[k];array[k] = temp;}
}
shuffle_node 函数将 array 中 1 到 22 项顺序打乱。特别的,第 0 项不受影响。
之后从 0 到 22 依次调用 array[i] 指向的 function 。
for ( i = 0; i <= 22; ++i ){node_1 = array[i];node_2 = array[i + 1];if ( node_2 )node_1->function(&a2[1][node_1->id], node_2->function, (unsigned int)node_2->offset);elsenode_1->function(&a2[1][node_1->id], mem, 0LL);}
根据前面的分析,array[0] 的内容是固定的,因此可以推断出 array[0] 指向的 function 未被加密。
array[0] 指向的 function 内容如下,其中 v6 实际上就是参数 a1,不过由于中间经过进出栈以及一个跳转导致 IDA 没有准确识别。
signed __int64 __fastcall sub_C78(_BYTE *a1, __int64 a2, signed __int64 a3)
{signed __int64 result; // rax_BYTE *v4; // rdi__int64 i; // r8_BYTE *v6; // [rsp+0h] [rbp-8h]if ( *a1 != '3' )return sys_exit(1);result = a3;v4 = v6; // a1for ( i = 0LL; i != 17; ++i )*v4++ ^= a3;return result;
}
该函数检验了输入字符串的第 array[0]->id 项,并将 array[1]->function 函数的前 17 个字节都异或了 array[1]->offset 。由于 array 中的第 1 到第 22 项顺序被打乱却能够保证解密正确,因此这些待解密部分的逻辑应该与 array[0]->function 的逻辑大致相同,都只是做了对输入字符串的其中一个字节的校验然后跳转到代码自解密的逻辑解。
特别的,循环到 i = 22 时会由于传进来的第三个参数为 0 ,因此等价为只进行输入的第 23 个字节的校验不进行代码自解密操作。
根据如上分析可以写出解密代码:
from idc import *
import ida_bytesaddr = get_name_ea_simple("sub_C78")
content = bytearray(ida_bytes.get_bytes(addr, 17 * 23))
flag = ""
for i in range(0, 23):if i != 0:for j in range(17):content[i * 17 + j] ^= (17 * i) & 0xFFflag += chr(content[i * 17 + 5])
ida_bytes.patch_bytes(addr, bytes(content))
print(flag)运行该代码,加密代码成功解密

顺带获取到 flag :34C3_M1GHTY_M0RPh1nG_g0
动态调试
以 babyRE 为例,动调可以看到解密后的代码。