matplotlib实操
- 问题
- 1.分析离网用户的基本特征:包括但不限于地市、年龄、网龄、融合类型、套餐分布、用户价值等,年龄、网龄、用户价值(ARPU)、MOU、DOU;
- 数据预处理
- 处理异常值
- 地市分布
- 县级分布
- 年龄分布
- 网龄分布
- 性别与年龄分布
- 融合类型
- 套餐分布
- 用户价值(ARPU)
- MOU(每用户每月平均通话时长)
- DOU(平均每户每月上网流量 单位:兆(M))
- 2.分析离网用户网龄和年龄之间是否存在一定的关系?
- 3.分析离网用户离网是否与拥有多个其他号码有关系?
ok,现在我们有以下数据集,我们开始进行实操
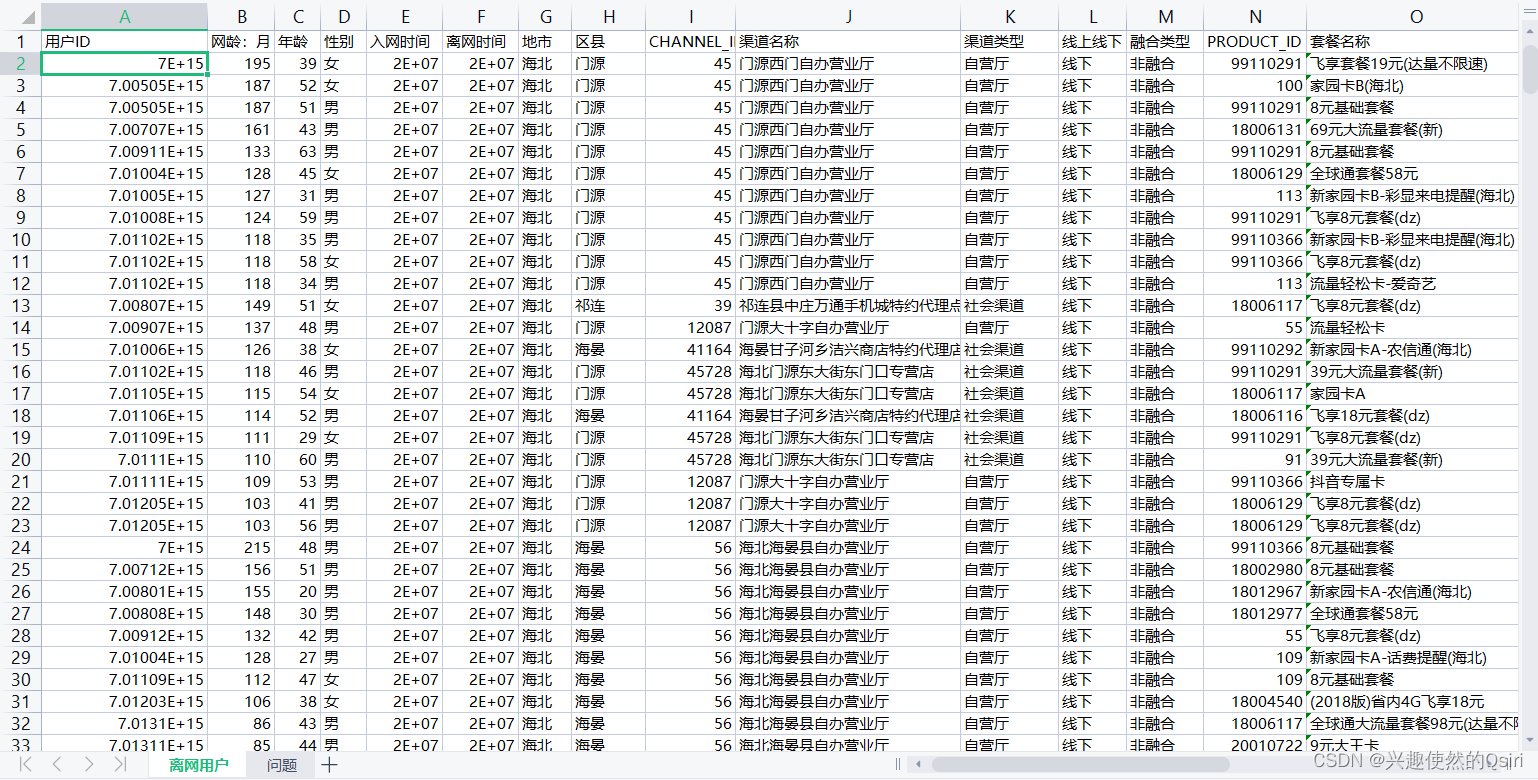
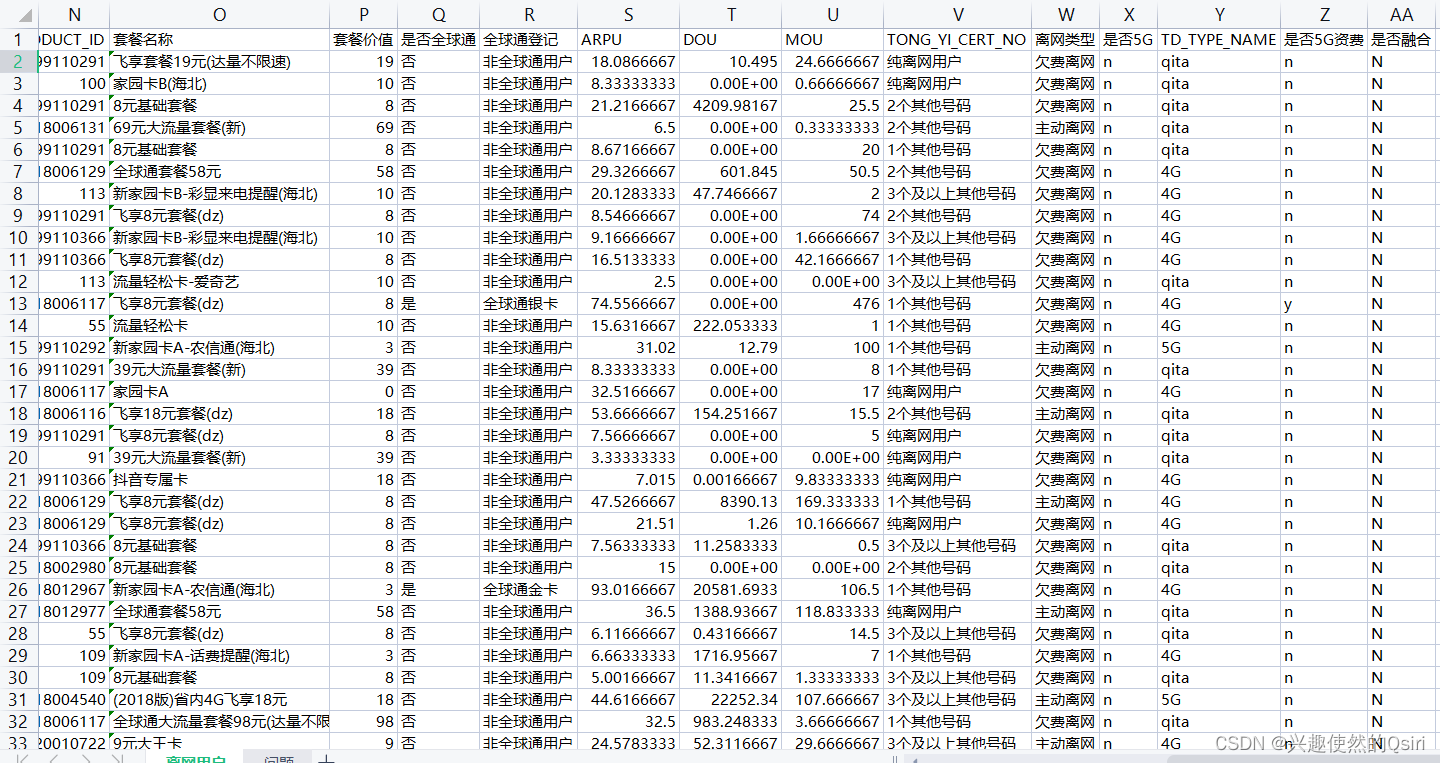
问题
1.分析离网用户的基本特征:包括但不限于地市、年龄、网龄、融合类型、套餐分布、用户价值等,年龄、网龄、用户价值(ARPU)、MOU、DOU;
数据预处理
import pandas as pd
import matplotlib.pyplot as plt
import numpy as npmissing_values = ["n/a", "na", "--","NaN","(null)",""] #指定空数据
# 读取Excel文件
df=pd.read_excel('D:/WPS/WPS文件储存库/python数据分析/数据分析题目-实习生.xlsx',na_values = missing_values)
print(df)
print("------------------------------------------------------------------------------------------------------")
# 删除存在空值的行
df.dropna(inplace=True)
print(df)
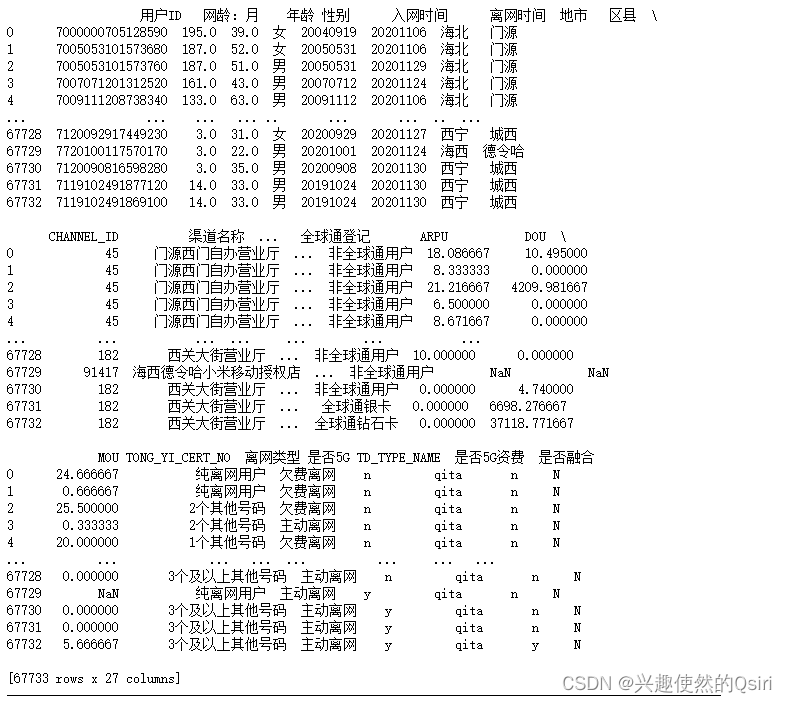
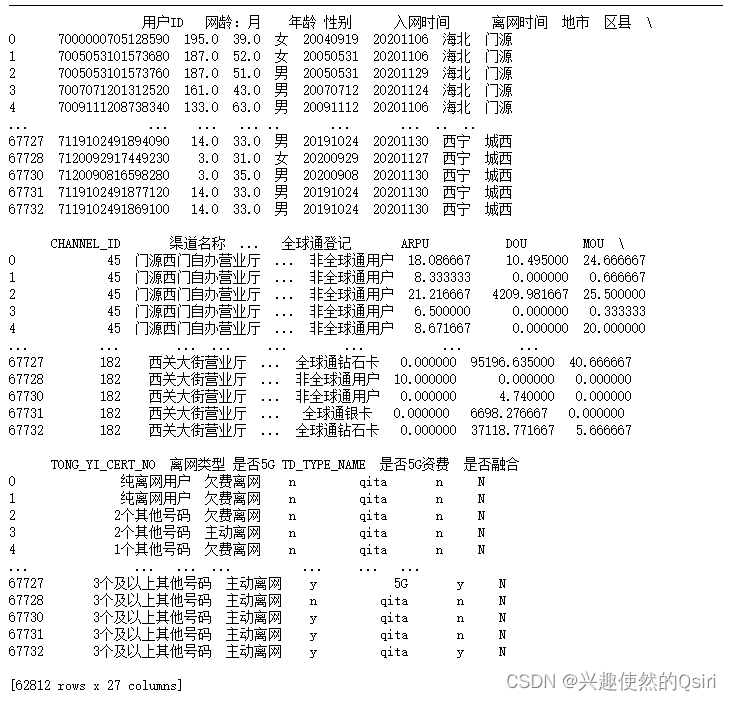
删除空值之后剩余62812条数据
处理异常值
将年龄控制在一定的范围
#异常值处理
# 检查年龄是否有超过人类寿命的上限
df = df[df['年龄'] <= 120]
print(df)
# 检查网龄是否为负数
df = df[df['网龄:月'] >= 0]
print(df)
地市分布
# 获取地市这一列中不同的地方,并去重
cities = df["地市"].unique()
# 打印输出结果
print("地市这一列有{}种不同的地方,分别是:".format(len(cities)))
for city in cities:print(city)# # 统计海北、西宁、海东、黄南、海南、果洛、玉树、海西、格尔木的数量
hb_count = df[df['地市'] == '海北'].count()['地市']
xn_count = df[df['地市'] == '西宁'].count()['地市']
hd_count = df[df['地市'] == '海东'].count()['地市']
hn_count = df[df['地市'] == '黄南'].count()['地市']
han_count = df[df['地市'] == '海南'].count()['地市']
gl_count = df[df['地市'] == '果洛'].count()['地市']
ys_count = df[df['地市'] == '玉树'].count()['地市']
hx_count = df[df['地市'] == '海西'].count()['地市']
grm_count = df[df['地市'] == '格尔木'].count()['地市']# 将结果组成列表
counts = [hb_count, xn_count, hd_count,hn_count,han_count,gl_count,ys_count,hx_count,grm_count]
labels = ['海北', '西宁', '海东','黄南','海南','果洛','玉树','海西','格尔木']
# 将 counts 数组从大到小进行排序
sorted_counts = np.argsort(counts)[::-1]
# 根据排序后的索引重新排列 labels 和 counts 数组
labels = np.array(labels)[sorted_counts]
counts = np.array(counts)[sorted_counts]
#格式设置
plt.rcParams['font.sans-serif']=['SimHei']#解决中文乱码
plt.figure(figsize=(9,5))#画布大小
colors=['r','y','g','b','m']#设置饼形图每块的颜色# 绘制饼图
plt.pie(counts, labels=labels, autopct='%1.1f%%',startangle=90,colors=colors)
plt.title('地市数量分布')
plt.show()

县级分布
# 统计各个区县在数据集中出现的次数
district_count = df['区县'].value_counts()plt.figure(figsize=(35, 10))#将画布的宽度设置为 30 英寸,高度设置为 10 英寸
# 绘制柱状图
plt.bar(district_count.index, district_count.values)
plt.ylabel('出现次数')
plt.xticks(rotation=14,fontsize=14)
plt.show()
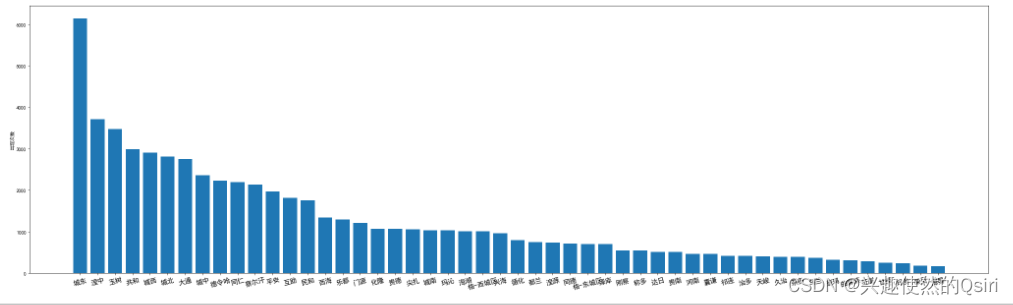
年龄分布
# 将年龄列分组,并统计每个组的数量
age_groups = pd.cut(df['年龄'], [18, 30, 40, 50, 60, 70, 80, 120])
age_counts = age_groups.value_counts()# 设置画布大小
plt.figure(figsize=(10, 6))# 绘制柱形图,并添加人数文本标签
labels = ['18-30', '30-40', '40-50', '50-60', '60-70', '70-80', '80-120']
ax = plt.subplot() # 创建子图,用于绘制柱状图
rects = ax.bar(labels, age_counts.values) # 绘制柱状图,并将返回的Rectangle对象存储在rects列表中
ax.set_title('年龄分布') # 设定图表标题# 遍历每一个Rectangle对象,添加文本标签
for rect in rects:height = rect.get_height() # 获取柱状图的高度ax.text(rect.get_x() + rect.get_width() / 2, height, '%d' % height, ha='center', va='bottom')# 在柱状图顶部的中心位置添加文本标签,'%d' % height 表示要添加的文本,ha和va参数分别表示水平和垂直对齐方式#图例
plt.legend(['年龄分布'])
plt.show()
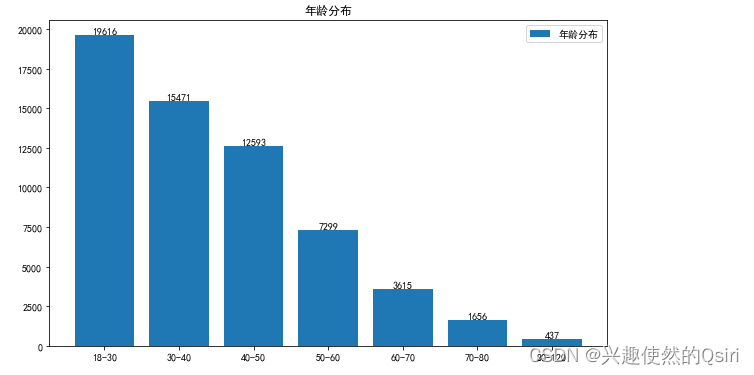
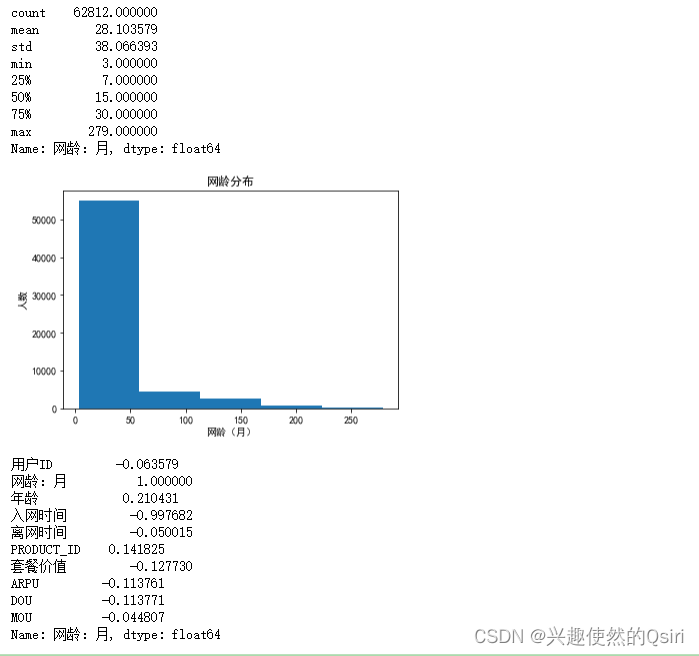
网龄分布
# 数据清理:将网龄这一列数据转换为整数类型,并处理缺失值
df['网龄:月'] = df['网龄:月'].astype(int)
df['网龄:月'].fillna(df['网龄:月'].mean(), inplace=True)# 数据统计:获得网龄这一列数据的基本情况
net_age_describe = df['网龄:月'].describe()
print(net_age_describe)# 数据可视化:绘制网龄的直方图或密度图
plt.hist(df['网龄:月'], bins=5)
plt.title('网龄分布')
plt.xlabel('网龄(月)')
plt.ylabel('人数')
plt.show()# 相关性分析:计算网龄与其他列数据之间的相关系数
correlations = df.corr()
print(correlations['网龄:月'])
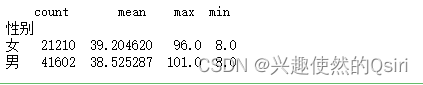
性别与年龄分布
# 数据分析:使用Pandas库中的groupby函数对性别列进行分组,并用agg函数对年龄列进行统计分析
age_grouped = df.groupby('性别')['年龄'].agg(['count', 'mean', 'max', 'min'])# 输出统计结果
print(age_grouped)
融合类型
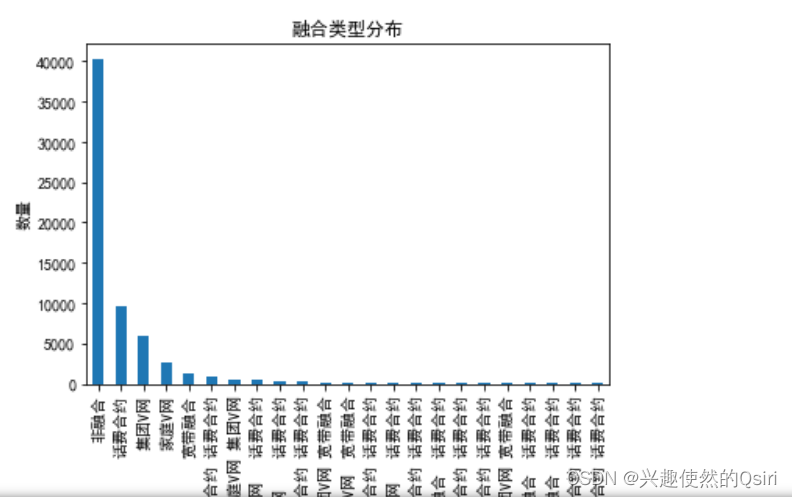
# 数据统计:计算每个融合类型出现的次数
counts = df['融合类型'].value_counts()
print(counts)# 数据可视化:绘制融合类型的柱状图
counts.plot(kind='bar')#kind='bar' 表示绘制垂直柱状图
plt.title('融合类型分布')
plt.xlabel('融合类型')
plt.ylabel('数量')
plt.show()# 相关性分析:生成交叉表并计算相关系数
cross_table = pd.crosstab(df['融合类型'], df['套餐价值'])
corr = cross_table.corr()
print(corr)

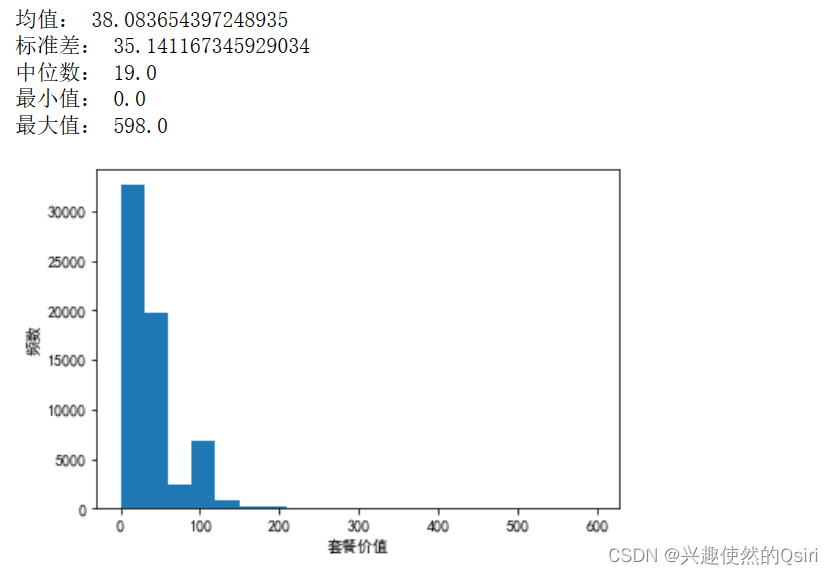
套餐分布
mean = df['套餐价值'].mean()
std = df['套餐价值'].std()
median = df['套餐价值'].median()
min_val = df['套餐价值'].min()
max_val = df['套餐价值'].max()print('均值:', mean)
print('标准差:', std)
print('中位数:', median)
print('最小值:', min_val)
print('最大值:', max_val)
#这段代码计算了套餐价值这一列的均值、标准差、中位数、最小值和最大值,并将这些结果打印输出#绘制直方图
plt.hist(df['套餐价值'], bins=20)
plt.xlabel('套餐价值')
plt.ylabel('频数')
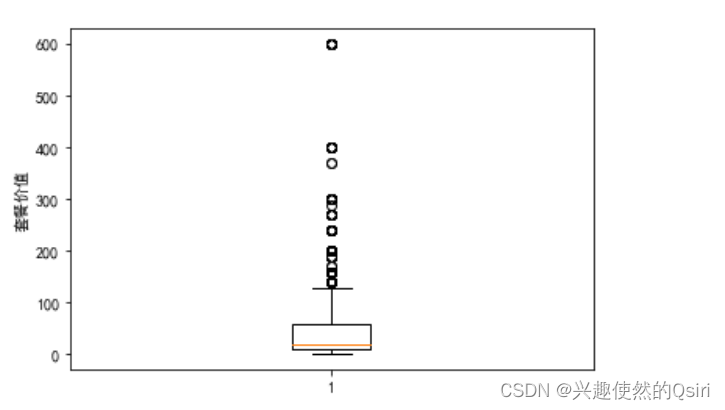
plt.show()# 绘制箱线图
plt.boxplot(df['套餐价值'])
plt.ylabel('套餐价值')
plt.show()
#箱子的中间一条线,是数据的中位数,代表了样本数据的平均水平
#箱子被压得很扁,甚至只剩下一条线,同时还存在着很多刺眼的异常值。
# 这种情况的出现是样本数据中,存在特别大或者特别小的异常值,这种离群的表现,导致箱子整体被压缩,反而凸显出来这些异常
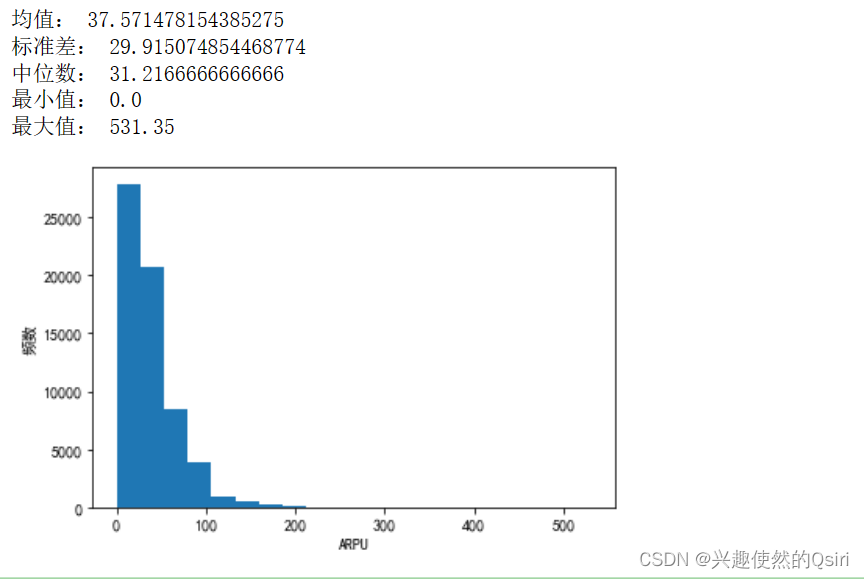
用户价值(ARPU)
mean = df['ARPU'].mean()
std = df['ARPU'].std()
median = df['ARPU'].median()
min_val = df['ARPU'].min()
max_val = df['ARPU'].max()print('均值:', mean)
print('标准差:', std)
print('中位数:', median)
print('最小值:', min_val)
print('最大值:', max_val)plt.hist(df['ARPU'], bins=20)
plt.xlabel('ARPU')
plt.ylabel('频数')
plt.show()
MOU(每用户每月平均通话时长)
# 计算基本统计量
mean = df['MOU'].mean()
std = df['MOU'].std()
median = df['MOU'].median()
min_val = df['MOU'].min()
max_val = df['MOU'].max()print('均值:', mean)
print('标准差:', std)
print('中位数:', median)
print('最小值:', min_val)
print('最大值:', max_val)# 绘制直方图
plt.hist(df['MOU'], bins=20)
plt.xlabel('MOU')
plt.ylabel('频数')
plt.show()# 绘制箱线图
plt.boxplot(df['MOU'])
plt.ylabel('MOU')
plt.show()
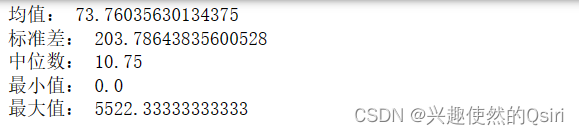
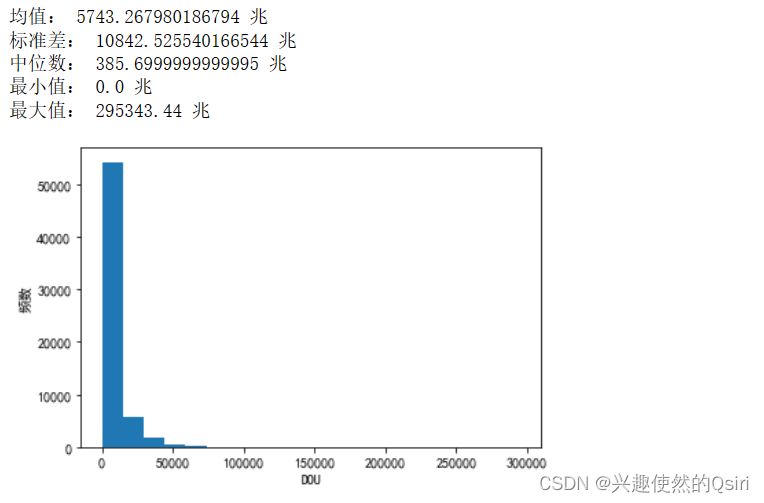
DOU(平均每户每月上网流量 单位:兆(M))
mean = df['DOU'].mean()
std = df['DOU'].std()
median = df['DOU'].median()
min_val = df['DOU'].min()
max_val = df['DOU'].max()print('均值:', mean,'兆')
print('标准差:', std,'兆')
print('中位数:', median,'兆')
print('最小值:', min_val,'兆')
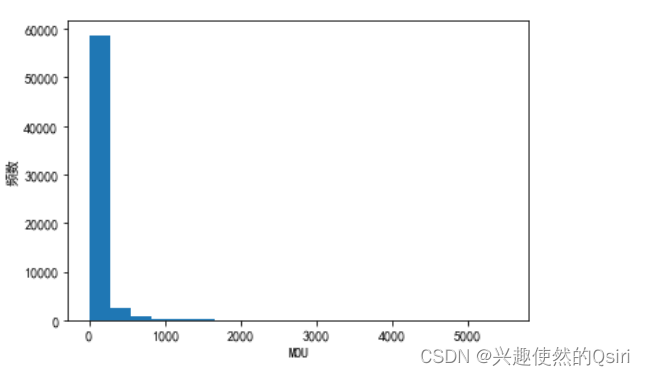
print('最大值:', max_val,'兆')plt.hist(df['DOU'], bins=20)
plt.xlabel('DOU')
plt.ylabel('频数')
plt.show()plt.boxplot(df['DOU'])
plt.ylabel('DOU')
plt.show()
箱线图更有效的使用方法,是作比较。 假设我现在要比较男女教师的教学评估得分,用什么工具最好。答案是箱线图。没有比较就没有伤害,大家看图能够明显感觉到箱线图是更有效的工具,能够从平均水平(中位数),波动程度(箱子宽度)以及异常值对男女教师的教学评估得分进行比较,而直方图却做不到。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nKuktiuF-1685884359795)(attachment:image.png)]
2.分析离网用户网龄和年龄之间是否存在一定的关系?
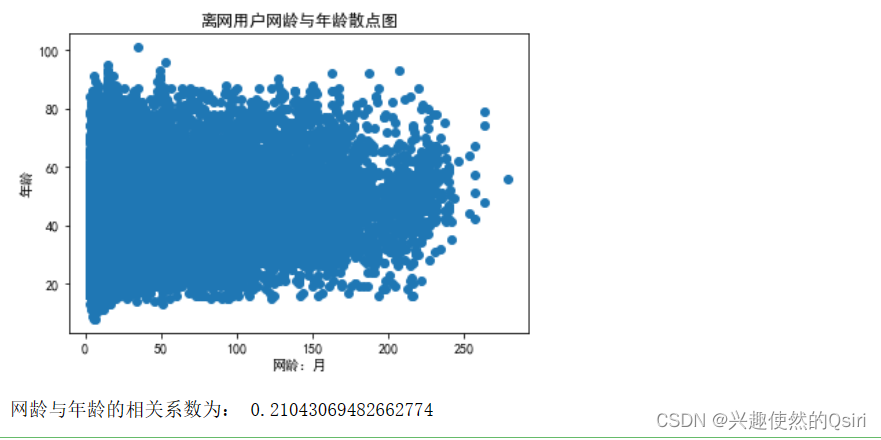
plt.scatter(df['网龄:月'], df['年龄'])
plt.title('离网用户网龄与年龄散点图')
plt.xlabel('网龄:月')
plt.ylabel('年龄')
plt.show()corr = np.corrcoef(df['网龄:月'], df['年龄'])[0, 1]
print('网龄与年龄的相关系数为:', corr)# 这行代码的作用是计算离网用户的DataFrame中,网龄和年龄两列的皮尔逊相关系数。
# np.corrcoef函数返回的是一个矩阵,其中第 i 行第 j 列的值表示第 i 个变量与第 j 个变量之间的相关系数。
# 因为 np.corrcoef(df['网龄'], df['年龄']) 返回的是一个 2x2 的矩阵,
# 因此 [0, 1] 表示取第 0 行第 1 列,也就是网龄和年龄的相关系数。
3.分析离网用户离网是否与拥有多个其他号码有关系?
# 统计各个区县在数据集中出现的次数
district_count = df['TONG_YI_CERT_NO'].value_counts()# 绘制柱状图
plt.bar(district_count.index, district_count.values)
plt.ylabel('出现次数')
plt.xticks(rotation=14,fontsize=14)for x, y in zip(district_count.index, district_count.values):plt.text(x, y+0.2, '%d' % y, ha='center', fontsize=16)
plt.show()
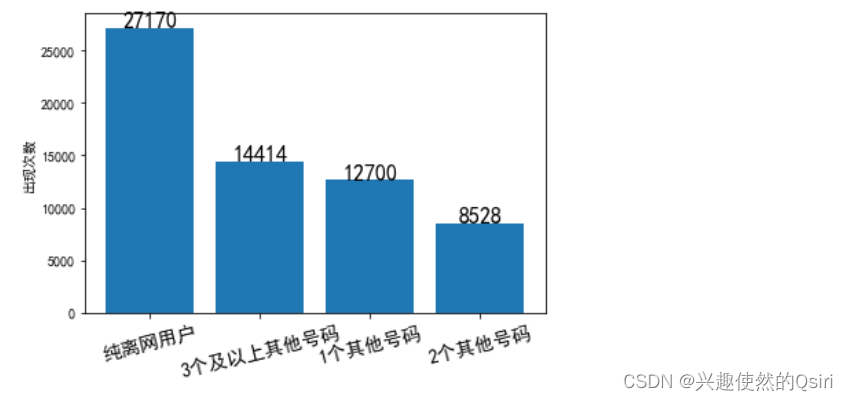
# 统计各个区县在数据集中出现的次数
district_count = df['离网类型'].value_counts()# 绘制柱状图
plt.bar(district_count.index, district_count.values)
plt.ylabel('出现次数')
plt.xticks(rotation=14,fontsize=14)for x, y in zip(district_count.index, district_count.values):plt.text(x, y+0.2, '%d' % y, ha='center', fontsize=16)
plt.show()
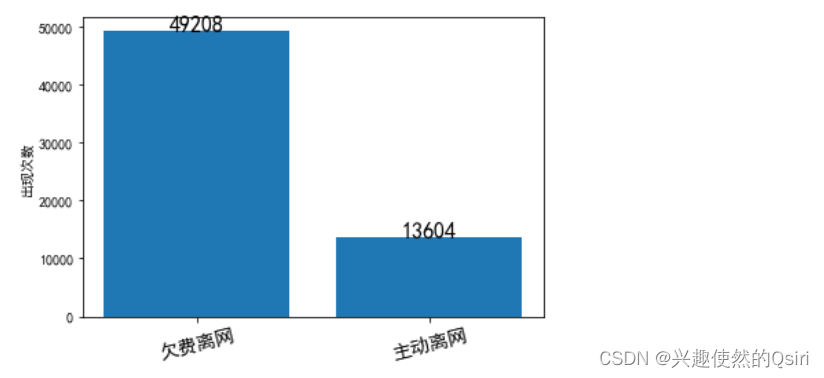
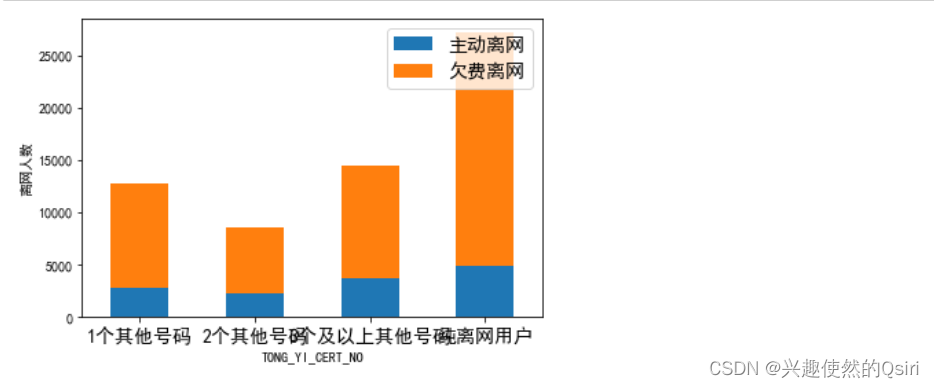
# 统计各个的离网人数,并按照不同离网类型进行分类
district_count = df.groupby(['TONG_YI_CERT_NO', '离网类型'])['离网类型'].count().unstack()# 绘制堆叠式柱状图
district_count.plot(kind='bar', stacked=True)#kind='bar' 表示绘制柱形图, stacked=True 表示相同离网类型的数据将会以堆叠的形式展示在同一列中。
#格式设置
plt.rcParams['font.sans-serif']=['SimHei']#解决中文乱码
plt.ylabel('离网人数')
plt.xticks(rotation=0, fontsize=14)#设置 x 轴刻度的旋转角度和字体大小
plt.legend(fontsize=14, loc='upper right')#添加图例并设置字体大小和位置plt.show()# 按照 'TONG_YI_CERT_NO' 和 '离网类型' 两列进行分组,统计每个 'TONG_YI_CERT_NO' 对应不同 '离网类型' 的出现次数。其中:# groupby(['TONG_YI_CERT_NO', '离网类型']) 将 DataFrame 根据指定的列名进行分组,这里指定了两列 'TONG_YI_CERT_NO' 和 '离网类型' 进行分组。
# ['离网类型'].count() 对每组数据中的 '离网类型' 列进行计数。
# .unstack() 将结果展开为一个二维表格,其中行索引为 'TONG_YI_CERT_NO',列索引为 '离网类型'。