大数据:spark RDD编程
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
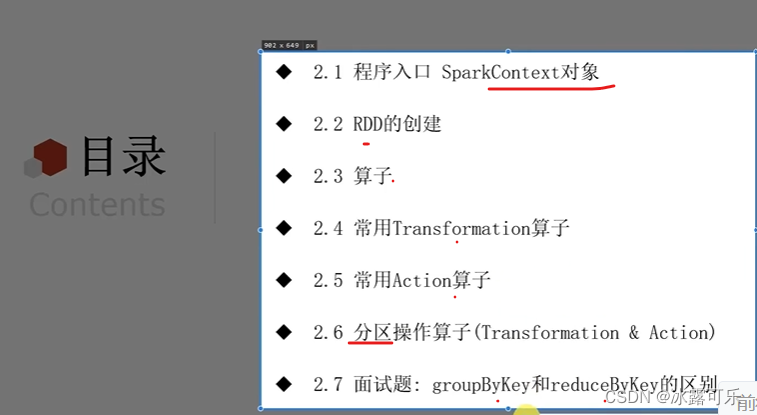
文章目录
- 大数据:spark RDD编程
- @[TOC](文章目录)
- 大数据:spark RDD编程
- RDD算子
- transformation算子
- 总结
文章目录
- 大数据:spark RDD编程
- @[TOC](文章目录)
- 大数据:spark RDD编程
- RDD算子
- transformation算子
- 总结
大数据:spark RDD编程

类似于dataloader一样
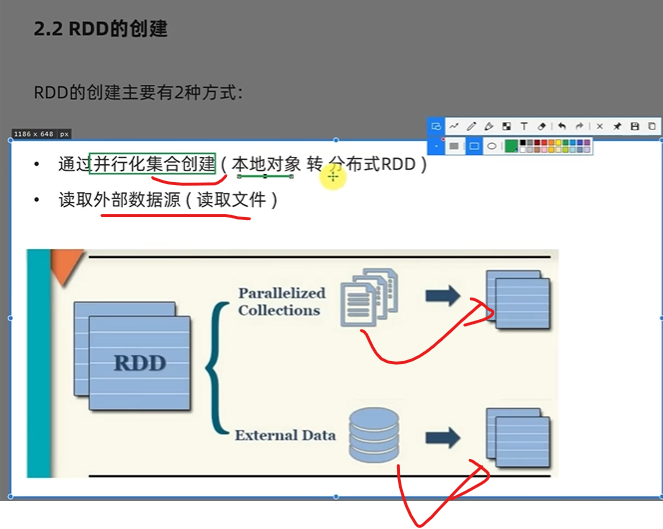

from pyspark import SparkConf, SparkContextsc要通过SparkContext对象构建
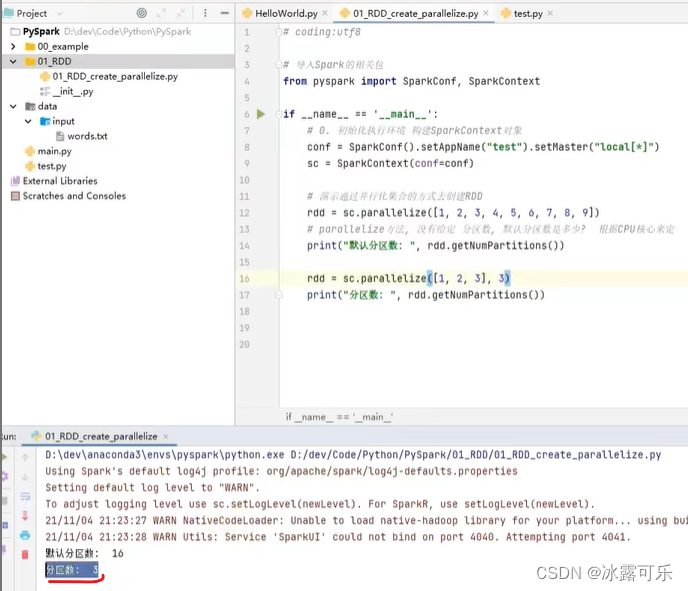
然后sc.parallize(迭代器对象,分区数量)
构建RDD就出来了默认分区会不会是1?

根据cpu的核数量
collect就是收集结果,展示出来
相当于Tensor.data
转回本地集合打印输出

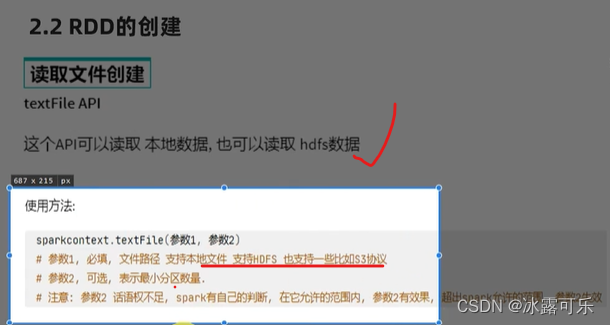
textFile(文件路径,分区数)
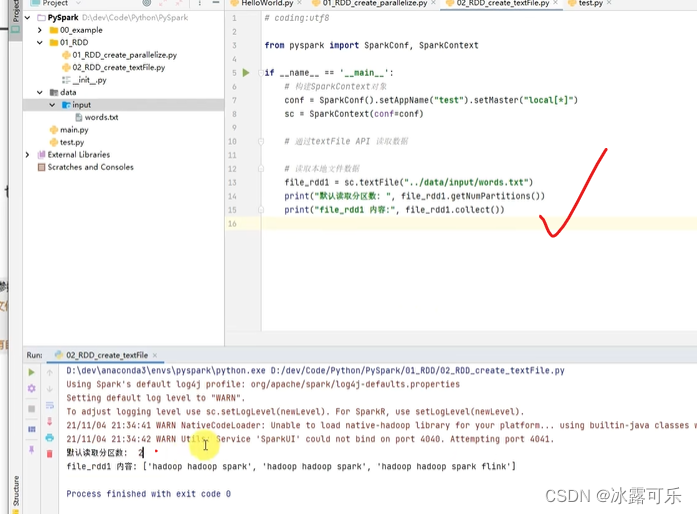
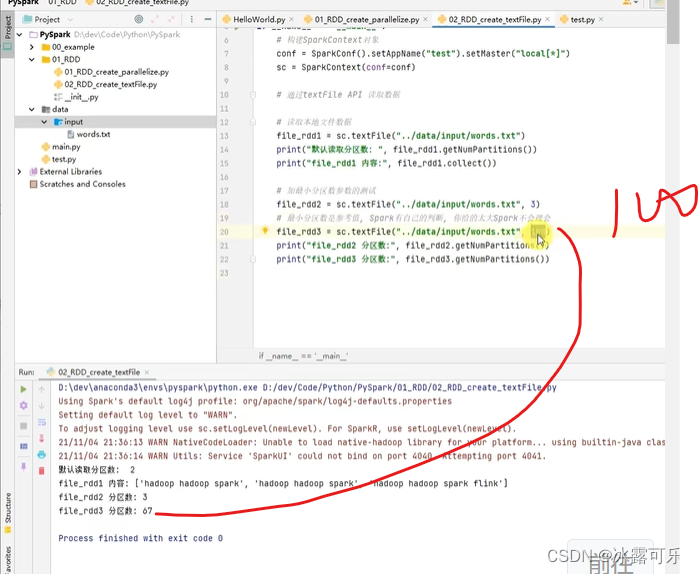
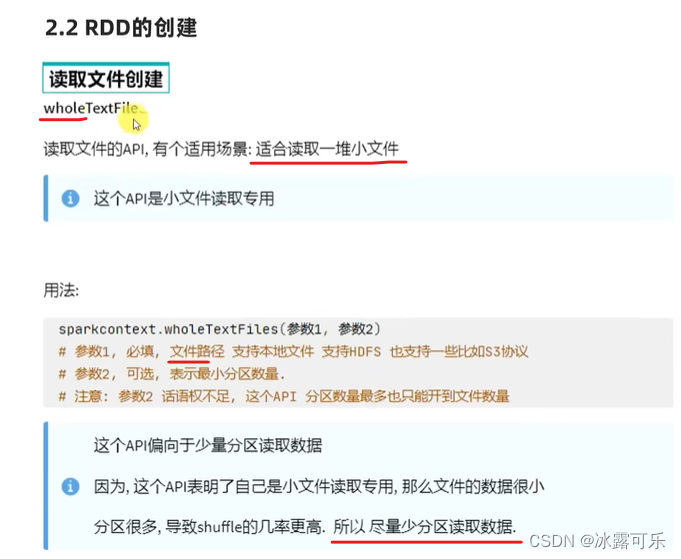
当小文件夹中有一堆小文件
使用wholetextFile
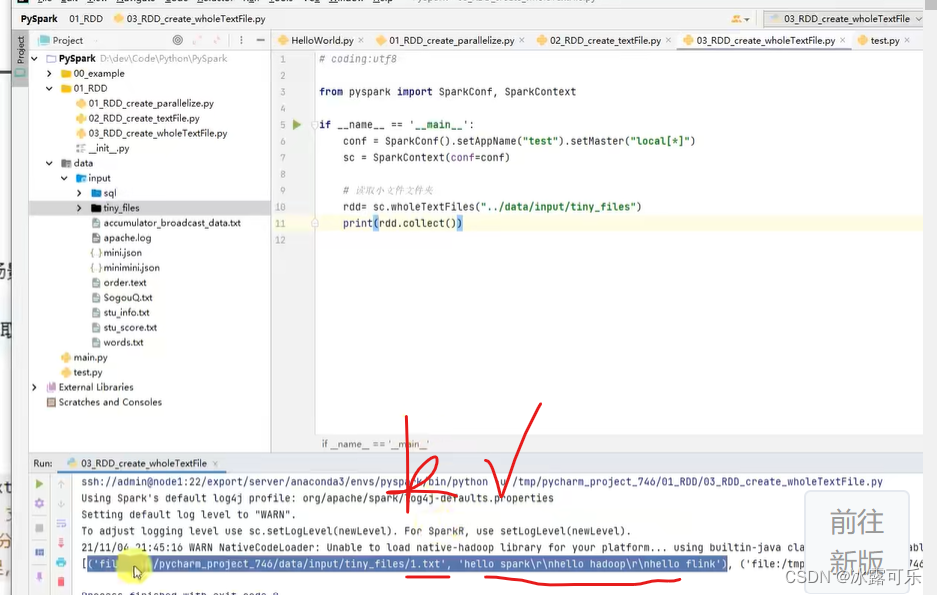
RDD算子
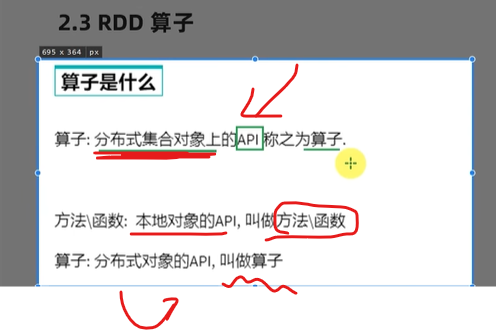
算子,分布式对象的计算子函数

collect是action算子
它转化后不是RDD
collect来了,才开始干上面的transform活
开关一打开,转换工序就开始了
懂了
所以代码不是一步步执行下去,而是要看开关开不开
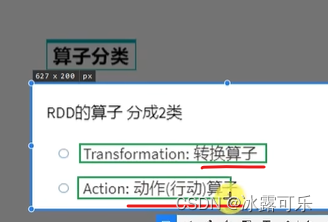
transformation算子

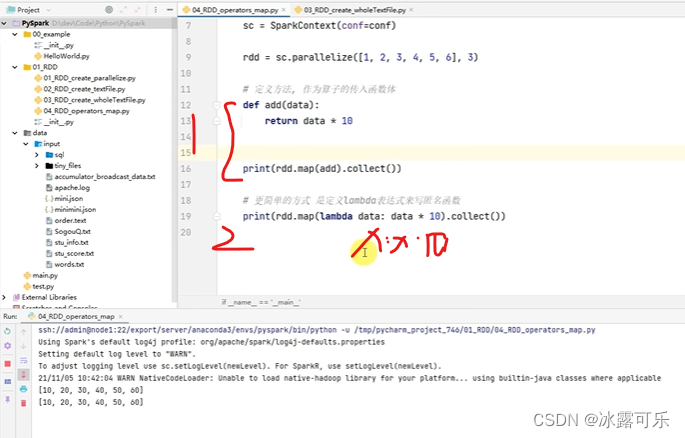
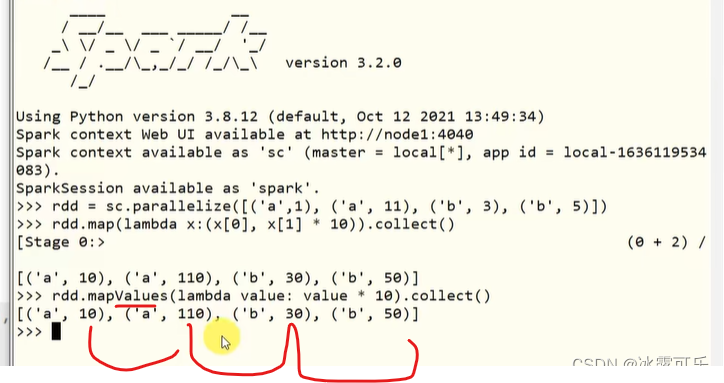
lambda x:x*10
统统乘10

传入的是一个函数

二维数组
变为一维数组
懂?
先map
后flat,放平
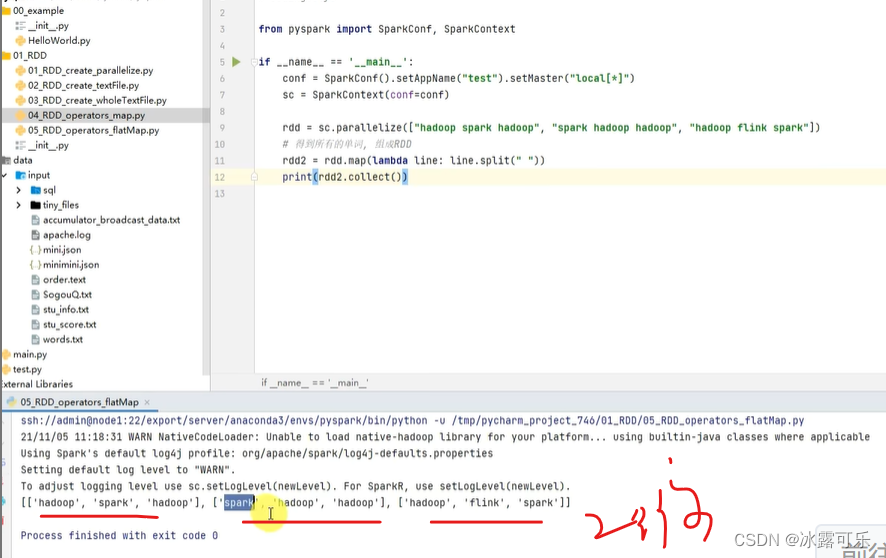
直接放平就行
flat就直接干完事
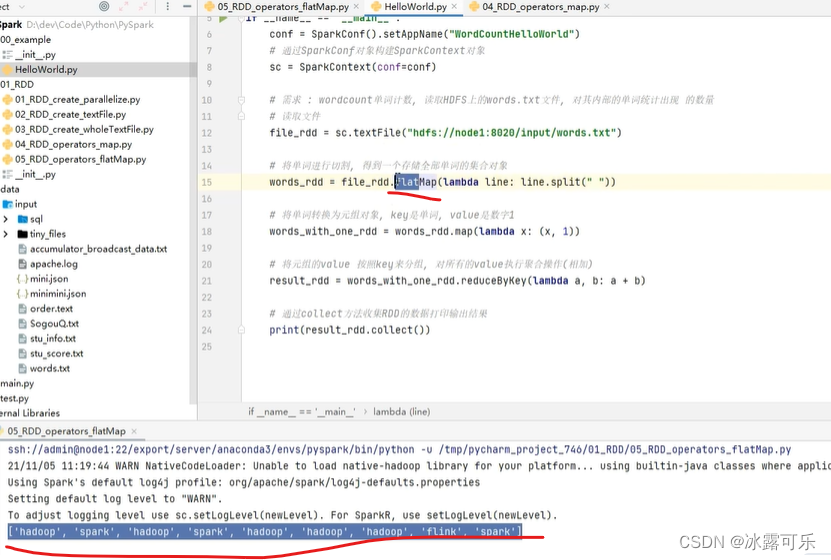

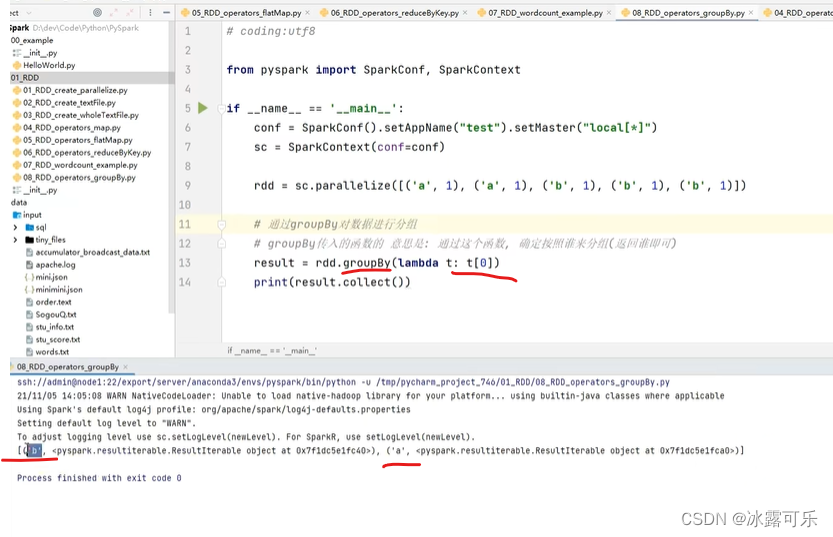
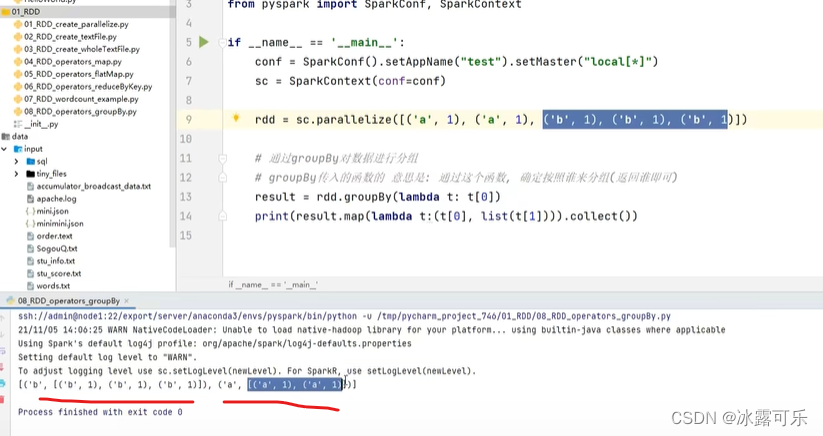
根据key分组
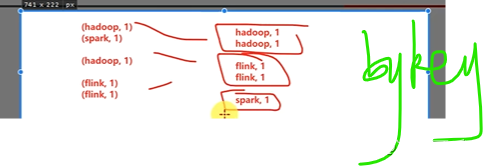
然后根据value聚合
如果只有12345呢?
那就根据数字直接分组
然后22相加,叠加式相加聚合
最后相当于求和

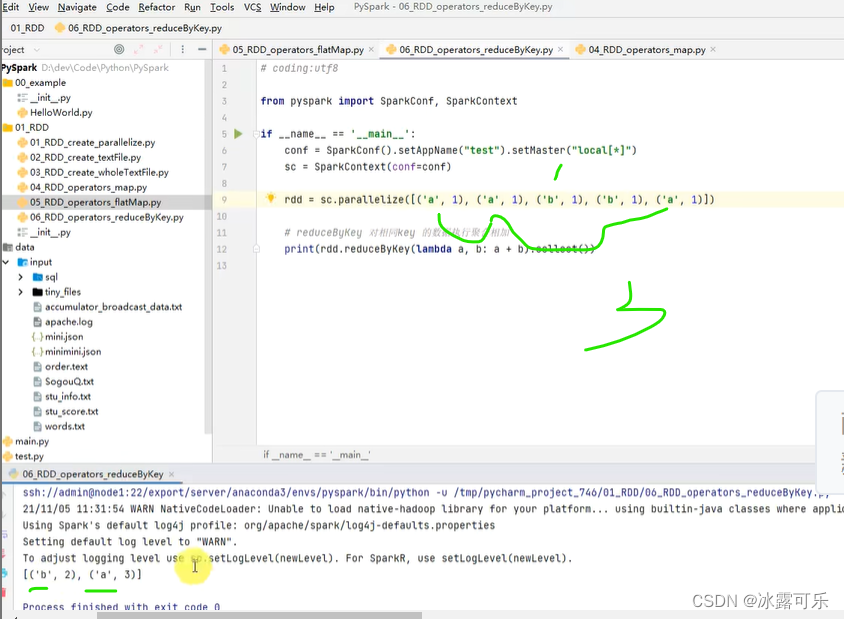


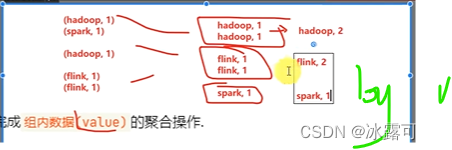
统计单词,然后聚合
收集打印输出

总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。