目录
赛题背景
赛题数据
1、导入数据分组
2、文本清洗
3、绘制词云
4、情感分析 (SnowNLP计算情感得分)
5、绘制不同情感值的柱形图
6、不同主题下的情感得分柱形图
7、绘制不同情感词下的频数条形图
8、绘制相关系数热力图
赛题背景
赛题以网络舆情分析为背景,要求选手根据用户的评论来对品牌的议题进行数据分析与可视化。通过这道赛题来引导常用的数据可视化图表,以及数据分析方法,对感兴趣的内容进行探索性数据分析。
赛题数据
数据源: earphone_sentiment.csv,为10000+条行业用户关于耳机的评论
链接:https://pan.baidu.com/s/1wlHzYVi2QO9xGfisD-al8A?pwd=myfb
提取码:myfb
1、导入数据分组
#导入模块
# _*_ coding:utf-8 _*_
import pandas as pd
import numpy as np
from collections import defaultdict
import os
import re
import jieba
import codecsdata=pd.read_csv("earphone_sentiment.csv")
data.head(10)s1 = data[data['sentiment_value']==1]
s2 = data[data['sentiment_value']==0]
s3 = data[data['sentiment_value']==-1]print(s2['content'])
1 这只HD650在1k的失真左声道是右声道的6倍左右,也超出官方规格参数范围(0.05%),看... 3 bose,beats,apple的消費者根本不知道有曲線的存在 5 我觉得任何人都可以明确分别高端耳机之间的区别,不用出声都可以,毕竟佩戴感不一样,这还没法做到盲听 6 听出区别是一方面,听出高低的层次要求就更高了。 7 有没有人能从10条电源线里,听出最贵的是哪条?... 17170 能把HD650推的高频刺耳,这得是什么奇葩系统,按说不至于啊 17172 hd800爆皮正常,换根线就没这种忧虑了 17173 自己焊接一下就行了,话说我820原线全新,800s原线99新,放盒子里没动了 17174 所以趁着还没爆,赶紧出手。 17175 sommer黑参考自己diy两米线,成本600左右,吊打原线 Name: content, Length: 12210, dtype: object
2、文本清洗
停顿词文档下载链接:
链接:https://pan.baidu.com/s/1jXV_aHcbQrWES78FoIhU-g?pwd=bceb
提取码:bceb
with open('stop_word/HGD_StopWords.txt','r',encoding='utf-8') as f:stopwords=set([line.replace('\n','')for line in f])
f.close()#加载用户自定义词典
segs=data['content']
def clean_data(content):words =' 'for seg_text in content:seg_text=jieba.cut(seg_text)for seg in seg_text:if seg not in stopwords and seg!=" " and len(seg)!=1: # #文本清洗 words = words + seg + ' 'return words
print(clean_data(s1['content']))3、绘制词云
import wordcloud as wc
import matplotlib.pyplot as plt
# from scipy.misc import imread
from imageio import imread
from PIL import Imagedef Cloud_words(s,words):# 引入字体font=r"C:/Windows/Fonts/simhei.ttf"mask = np.array(Image.open('词云2.png'))image_colors =wc.ImageColorGenerator(mask)#从文本中生成词云图cloud = wc.WordCloud(font_path=font,#设置字体 background_color='black', # 背景色为白色height=600, # 高度设置为400width=900, # 宽度设置为800scale=20, # 长宽拉伸程度程度设置为20prefer_horizontal=0.2, # 调整水平显示倾向程度为0.2mask=mask, # 添加蒙版max_font_size=100, #字体最大值 max_words=2000, # 设置最大显示字数为1000relative_scaling=0.3, # 设置字体大小与词频的关联程度为0.3)# 绘制词云图mywc = cloud.generate(words)plt.imshow(mywc)mywc.to_file(str(s)+'.png')s=[s1,s2,s3]
for i in range(len(s)):Cloud_words(i,clean_data(s[i]['content']))#绘制不同类型的词云图
import stylecloud
clouds=stylecloud.gen_stylecloud(text=clean_data(s1['content']), # 上面分词的结果作为文本传给text参数size=512,font_path='C:/Windows/Fonts/msyh.ttc', # 字体设置palette='cartocolors.qualitative.Pastel_7', # 调色方案选取,从palettable里选择gradient='horizontal', # 渐变色方向选了垂直方向icon_name='fab fa-weixin', # 蒙版选取,从Font Awesome里选output_name='test_ciyun.png') # 输出词云图

- 这里我的词云形状没有跟着背景图片的形状走sos,可能是素材找的有问题吧,回头再说
4、情感分析 (SnowNLP计算情感得分)
# 情感分析的结果是一个小数,越接近1,说明越偏向积极;越接近0,说明越偏向消极。
# SnowNLP计算情感得分
from snownlp import SnowNLP
# 评论情感分析
# f = open('earphone_sentiment.csv',encoding='gbk')
# line = f.readline()
with open('stop_word/HGD_StopWords.txt','r',encoding='utf-8') as f:stopwords=set([line.replace('\n','')for line in f])
f.close()
sum=0
count=0
for i in range(len(data['content'])):line=jieba.cut(data.loc[i,'content']) #分词words=''for seg in line:if seg not in stopwords and seg!=" ": #文本清洗 words=words+seg+' 'if len(words)!=0:print(words) #输出每一段评论的情感得分d=SnowNLP(words)print('{}'.format(d.sentiments))data.loc[i,'sentiment_score']=float(d.sentiments) #原数据框中增加情感得分列sum+=d.sentimentscount+=1
score=sum/count
print('finalscore={}'.format(score)) #输出最终情感得分#将情感得分结果保存为新的csv文件
data.to_csv('result.csv',encoding='gbk',header=True)#情感值以方法一计算的作为值
#获取同一列中不重复的值
a=list(data['subject'].unique())
sum_scores=dict()
#求对应主题的情感均值
for r in range(len(a)):de=data.loc[data['subject']==a[r]]sum_scores[a[r]]=round(de['sentiment_score'].mean(),2)
print(sum_scores)5、绘制不同主题下的情感值柱形图
#不同主题下的情感得分柱形图
import seaborn as sns
import matplotlib.pyplot as plt
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#数据可视化
sns.barplot(x=list(sum_scores.values()),y=list(sum_scores.keys()))
plt.xlabel('情感值')
plt.ylabel('主题')
plt.title('不同主题下的情感得分柱形图')
for x,y in enumerate(list(sum_scores.values())): plt.text(y,x,y,va='center')
plt.show()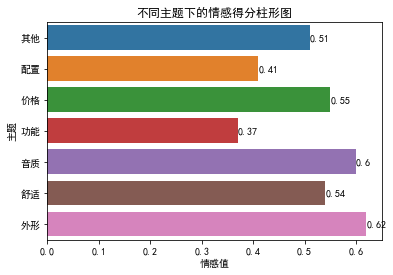
6、不同情感词下的情感得分柱形图
#绘制不同情感词下的频数条形图
bar= data['sentiment_word'].value_counts().head(10)
print(bar)
labels = bar.index
sns.barplot(bar.values,labels)
plt.xlabel('频数')
plt.ylabel('情感词')
plt.title('不同情感词下Top10频数柱形图')
for x,y in enumerate(bar.values): plt.text(y+0.2,x,y,va='center')#在每个柱子上标注频数
plt.show()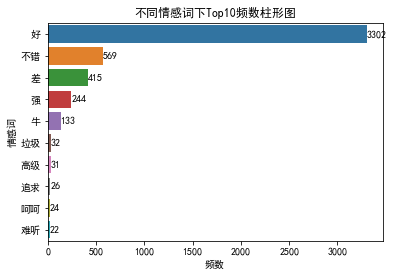
7、绘制不同情感值下的频数条形图
#获绘制不同情感值的柱形图
# bar包括index和values
bar= data['sentiment_value'].value_counts()sentiment_score=dict(bar)
print(sentiment_score)sns.barplot(x=list(sentiment_score.keys()),y=list(sentiment_score.values()))
plt.xlabel('情感值')
plt.ylabel('频数')
plt.title('不同情感值下的频数柱形图')
for x,y in zip(sentiment_score.keys(),sentiment_score.values()): plt.text(x+1,y,y,ha='center',va='baseline',fontsize=12)
plt.show()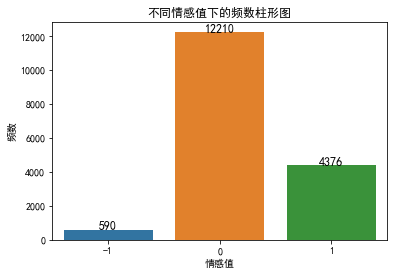
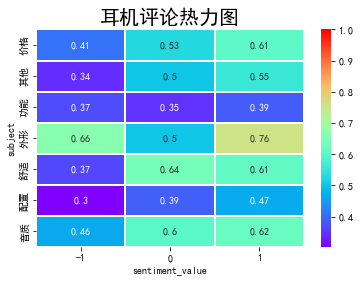
8、绘制相关系数热力图
#绘制相关系数热力图
import seaborn as sns
from matplotlib import font_manager
#按不同主题不同情感值进行分组,求不同主题不同情感值对应的情感得分均值
w=data.groupby(['subject','sentiment_value'],as_index=False)['sentiment_score'].mean()
print(w)
print('****************')
print(data_heatmap)data_heatmap = w.pivot(index = 'subject', columns = 'sentiment_value', values = 'sentiment_score')
ax = sns.heatmap(data_heatmap,vmax = 1,cmap='rainbow', annot=True,linewidths=0.05)
ax.set_title('耳机评论热力图', fontsize = 20)