目录
1.引入 AWS SDK for Java2.x
2.创建 S3Client
3.上传对象
3.1 直接上传对象
3.2 分段上传对象
4.下载对象
4.1 下载对象到指定目录
4.2 完整性验证
4.2.1 未分段对象的验证
4.2.2 分段对象的验证
5.验证对象是否存在
6.风险和优化
1.引入 AWS SDK for Java2.x
通过 Maven 引入依赖,截至 2021 年 12 月 22 日,最新版本:2.17.101
<properties><awssdk.version>2.17.101</awssdk.version> </properties> <dependencyManagement><dependencies>.........<dependency><groupId>software.amazon.awssdk</groupId><artifactId>bom</artifactId><version>${awssdk.version}</version><type>pom</type><scope>import</scope></dependency></dependencies> </dependencyManagement> <dependencies>.........<!-- S3 dependencies start --><dependency><groupId>software.amazon.awssdk</groupId><artifactId>s3</artifactId></dependency><dependency><groupId>software.amazon.awssdk</groupId><artifactId>sts</artifactId></dependency><!-- S3 dependencies end -->.... </dependencies>2.创建 S3Client
- 鉴权问题
- 初始化的时候必须指定区域 Region
- S3Client 使用完毕之后,要调用它的 close 方法,释放资源,推荐使用显式关闭的方式,以免遗漏
/*** @param region 区域* @param roleARN 如果有值,则使用 roleARN 鉴权方式。如果没有,则使用默认鉴权方式* @return S3Client*/public static S3Client createS3Client(String region, String roleARN) {var builder = S3Client.builder().region(Region.of(region));if (StringUtils.isNotBlank(roleARN)) {var assumeRoleRequest = AssumeRoleRequest.builder().roleArn(roleARN).roleSessionName(SESSION_NAME_PREFIX + System.nanoTime()).build();var provider = StsAssumeRoleCredentialsProvider.builder().stsClient(StsClient.create()).refreshRequest(assumeRoleRequest).asyncCredentialUpdateEnabled(true).build();builder.credentialsProvider(provider);}return builder.build();}3.上传对象
- 上传对象的方式分为直接上传,以及,将大文件分段上传。AWS 官方建议超过 100MB 的文件就可以考虑分段上传,请参考分段上传的官方文档。
3.1 直接上传对象
通过
contentMD5()方法应该加入上传对象的 MD5 校验:private static void wholeUpload(String bucketName, String objectKey, File file, S3Client s3Client, FileInputStream fis) throws IOException {String md5 = new String(Base64.encodeBase64(DigestUtils.md5(fis)));PutObjectRequest objectRequest = PutObjectRequest.builder().bucket(bucketName).key(objectKey).contentMD5(md5).build();RequestBody requestBody = RequestBody.fromFile(file);s3Client.putObject(objectRequest, requestBody); }3.2 分段上传对象
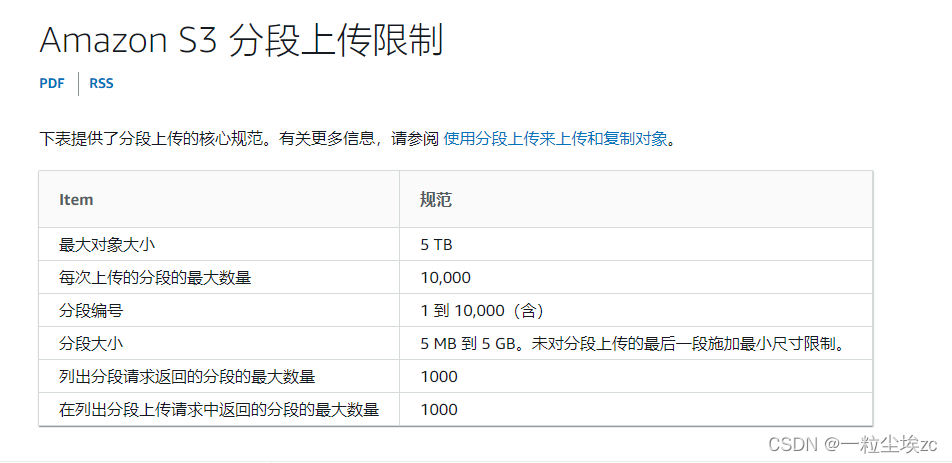
- 分段上传对象,有一定的限制,详细信息请参考分段上传限制的官方文档
- 应该给每一段都加上各自的 md5 校验分段上传的完整性
- 对于一个大文件,如果我们不分段,可以直接使用文件输入流计算 md5 和上传,这样不会有内存压力;但是使用分段上传之后,要计算每一段内容的 md5 值,就不能直接使用文件输入流了,得按照设置的分段大小从文件输入流中读取每一段,再计算每一段的 md5 值,这样就把分段大小的内容读取到了内存中,会对内容增加分段大小这么多的压力。串行的情况下,每次读取一段,只会增加一段内容的内存压力,如果程序串行的话,就相当于把整个文件加载到了内存中,压力会更大
- 如果上传发生异常,应该主动关闭分段上传,尝试重新上传
- 建议对 s3 bucket 启用 AbortIncompleteMultipartUploadAmazon 生命周期规则,该规则指示 S3 中止没有在指定天数内完成的分段上传,并删除未完成的上传数据,参考关于 S3 生命周期的官方文档
private static void multipartUpload(String bucketName, String objectKey, File file, S3Client s3Client, FileInputStream fis) {CreateMultipartUploadRequest createMultipartUploadRequest = CreateMultipartUploadRequest.builder().bucket(bucketName).key(objectKey).build();CreateMultipartUploadResponse response = s3Client.createMultipartUpload(createMultipartUploadRequest);String uploadId = response.uploadId();try {List<CompletedPart> completedParts = new ArrayList<>();final long fileLength = file.length();final long partNumber = getPartNumber(fileLength);log.info("multipartUpload fileLength={}, partNumber={},uploadId={}", fileLength, partNumber, uploadId);for (int i = 1; i <= partNumber; i++) {final byte[] bytes = fis.readNBytes((int) PART_SIZE);String md5 = new String(Base64.encodeBase64(DigestUtils.md5(bytes)));UploadPartRequest uploadPartRequest = UploadPartRequest.builder().bucket(bucketName).key(objectKey).uploadId(uploadId).partNumber(i).contentMD5(md5).build();final RequestBody requestBody = RequestBody.fromBytes(bytes);UploadPartResponse uploadPartResponse = s3Client.uploadPart(uploadPartRequest, requestBody);String eTag = uploadPartResponse.eTag();CompletedPart part = CompletedPart.builder().partNumber(i).eTag(eTag).build();completedParts.add(part);}CompletedMultipartUpload completedMultipartUpload = CompletedMultipartUpload.builder().parts(completedParts).build();CompleteMultipartUploadRequest completeMultipartUploadRequest =CompleteMultipartUploadRequest.builder().bucket(bucketName).key(objectKey).uploadId(uploadId).multipartUpload(completedMultipartUpload).build();s3Client.completeMultipartUpload(completeMultipartUploadRequest);} catch (Exception e) {log.error("S3 multipartUpload fail!", e);// 停止正在进行的分段上传,清理已上传分段s3Client.abortMultipartUpload(AbortMultipartUploadRequest.builder().bucket(bucketName).key(objectKey).uploadId(uploadId).build());}}4.下载对象
- 下载对象到指定的临时目录,在根据返回的 eTag 值校验文件的完整性
- 如果验证失败,删除已下载的缺损文件
4.1 下载对象到指定目录
public static boolean getObjectByKey(String bucketName, String objectKey, String path) {log.info("S3Utils getObjectByKey key={}", objectKey);// 1.从 S3 获取文件GetObjectRequest objectRequest = GetObjectRequest.builder().key(objectKey).bucket(bucketName).build();try (S3Client s3Client = S3Utils.createS3Client(S3Utils.REGION, null);ResponseInputStream<GetObjectResponse> responseInputStream = s3Client.getObject(objectRequest);FileOutputStream fileOutputStream = new FileOutputStream(path)) {String eTag = responseInputStream.response().eTag().replaceAll("\"", "");log.info("eTag={}", eTag);// 2.下载文件到临时目录byte[] bufferByte = new byte[STREAM_BUFFER_LENGTH];int len;while ((len = responseInputStream.read(bufferByte)) != -1) {fileOutputStream.write(bufferByte, 0, len);}fileOutputStream.flush();// 3.验证文件的完整性boolean validateResult = validateFile(path, eTag);if (validateResult) {return true;}} catch (Exception e) {log.error("deleteObjectByKey error", e);}// 4.如果验证失败,删除文件FileUtils.deleteFile(path);return false; }4.2 完整性验证
验证方法,根据返回对象的 eTag 进行验证
4.2.1 未分段对象的验证
未分段对象的 eTag = DigestUtils.md5Hex(inputStream) 示例:
"ETag": "\"f7225931e6cc461dd14879fd340aba44\""只需要 eTag 与 DigestUtils.md5Hex(inputStream) 的值相等即可
4.2.2 分段对象的验证
分段对象的 eTag = DigestUtils.md5Hex((DigestUtils.md5(part1) + DigestUtils.md5(part2) + ........+ DigestUtils.md5(partn))) + "-n" ,示例:
"ETag": "\"6be8dea194cee773daf9f07446f3a520-3\"",”-3“ 表示这个对象分了三段
4.2.1 和 4.2.2 的验证示例代码
private static boolean validateFile(String path, String eTag) throws IOException {try (InputStream inputStream = new FileInputStream(path);ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()) {String localMd5Hex;final String[] eTags = eTag.split(S3_ETAG_SEPARATOR);if (eTags.length > 1) { // 分段上传的文件int parts = Integer.parseInt(eTags[1]);for (int i = 0; i < parts; i++) {byte[] bytes = inputStream.readNBytes((int) PART_SIZE);byte[] md5Bytes = DigestUtils.md5(bytes);byteArrayOutputStream.write(md5Bytes);}localMd5Hex = DigestUtils.md5Hex(byteArrayOutputStream.toByteArray());}else{localMd5Hex = DigestUtils.md5Hex(inputStream);}log.info("localMd5Hex={}", localMd5Hex);if (eTags[0].equals(localMd5Hex)) { // 文件完整性校验return true;}} catch (Exception e) {log.error("validateFile error", e);}return false; }5.验证对象是否存在
- sdk-java v1 版本可以用
s3Client.doesObjectExist(),但是 sdk-java v2 里取消了这个方法,建议使用s3Client.headObject(),如果对象不存在,会报 NoSuchKeyException。更多 sdk 服务变更请参考 S3 sdk Service Changes- 示例代码
public static boolean doesObjectExist(String bucketName, String objectKey) {if (StringUtils.isAnyBlank(bucketName, objectKey)) {return false;}S3Client s3Client = null;try {s3Client = createS3Client(REGION, null);HeadObjectRequest objectRequest = HeadObjectRequest.builder().key(objectKey).bucket(bucketName).build();s3Client.headObject(objectRequest);return true;} catch (NoSuchKeyException e) {// 如果 key 不存在,会报 NoSuchKeyExceptionlog.error("noSuchKey bucketName={}, objectKey={}", bucketName, objectKey);} catch (S3Exception e) {log.error("S3Exception", e);} finally {if(s3Client != null){s3Client.close();}}return false; }6.风险和优化
- 分段上传的完整性校验和分段对象下载的完整性校验,存在内存方面的忧虑,可以改良代码,以一种比较平滑的方式来计算
- 分段上传可以并行进行,这样可以充分利用带宽,加快对象上传速度。但在内存压力问题没有解决之前还是不要这么做
- 校验时无法知道它以前是按多大分段的,如果程序内分段大小参数改变了,再下载以前上传的分段对象,校验的时候肯定要出错了
S3 文件操作使用实践
news/2025/2/22 16:13:19/
相关文章


夏普GP2Y1010AU0F灰尘传感器使用
夏普GP2Y1010AU0F灰尘传感器在STM32平台上的使用 一、传感器的概述 GP2Y1010AUOF是日本夏普公司开发的一款光学灰尘浓度检测传感器。此传感器内部成对角分布的红外发光二极管和光电晶体管,利用光敏原理来工作。用于检测特别细微的颗粒,如香烟颗粒、细微灰…

Amazon S3 功能介绍
Amazon S3 功能介绍 1 存储过程 创建用于存储数据元的桶,可以选择数据元所驻留的地区(目前来说,选择东京、新加坡会快些,美国本土更便宜),上传数据元到桶,进行持久化存储。另外,可以…
spark对接aws s3以及兼容s3接口的对象存储
之前写了一篇如何让spark使用阿里云oss对象存储替代本地存储或者hdfs存储jar包,日志等,文章链接:spark对接oss对象存储 今天写一篇比较通用的,即spark对接aws s3或者其他厂商兼容s3接口的对象存储。
环境
spark环境:…
华为现在打败爱立信了么?
华为现在打败了爱立信了么?
我现在一直搞不明白华为是怎么打败爱立信的。
我刚问L一下同事,他们说华为是做手机的,没有电脑。
华为哪里有笔记本,又骗我
华为为啥要做笔记本电脑
华为成第二了,如果荣耀第一的话
华…

设计模式-责任链模式
责任链模式 问题背景解决方案:传统方法责任链模式基本介绍UML类图 解决方案:责任链模式UML类图代码示例 注意事项和细节 问题背景
学校OA系统采购审批项目:需求时 1)采购员采购教学器材 2)如果金额小于等于5000&#…

javaScript蓝桥杯-----芝麻开门
目录 一、介绍二、准备三、目标四、代码五、完成 一、介绍
在阿里巴巴和四十大盗的故事中,阿里巴巴因为无意中知道了开门的咒语人生发生了翻天覆地的变化,四十大盗也因为咒语的泄露最终丧命。芝麻开门的咒语作为重要的信息推动着故事的发展。下面由你来…