在本章中,我们重点关注如何使第10章中介绍的通用iostream框架适配特定的需求和偏好。
11.1 规则性和不规则性
C++标准库的输入/输出部分——iostream库为文本的输入和输出提供了一个统一的、可扩展的框架。
到目前为止,我们将所有输入源视为等价的,有时这是不够的。例如,文件与其他输入源(例如网络连接)的区别是可以按单个字节寻址(而网络连接的字节是流式到达的)(类似于向量和迭代器的区别)。另外,我们假设对象的类型完全决定了其输入和输出格式,但这并不完全正确。例如,我们通常希望在输出浮点数时指定数字个数(精度)。本章会提出一些可以按需求定制输入/输出的方法。
作为程序员,我们更喜欢规则性(regularity):一致地处理所有对象、将所有输入源视为等价、对表示对象的方式强制一个单一的标准能够给出最干净、最简单、最可维护以及通常最高效的代码。然而,程序的存在是为了服务人类,而人类有很强的偏好性(不规则性,irregularity)。因此,作为程序员,我们必须争取在程序复杂性和满足用户偏好之间取得平衡。
11.2 输出格式化
11.2.1 整数输出
整数值可以输出为八进制(octal)、十进制(decimal)和十六进制(hexadecimal)。一个十六进制数恰好表示4个二进制位,2个十六进制数可用于表示一个字节。
可以指定(十进制)数1234以十进制、十六进制或八进制输出:
cout << dec << 1234 << " (decimal)\n"<< hex << 1234 << " (hexadecimal)\n"<< oct << 1234 << " (octal)\n";
将输出
1234 (decimal)
4d2 (hexadecimal)
2322 (octal)
即十进制的1234 = 十六进制的4d2 = 八进制的2322。
其中dec、hex和oct并不输出值,而是告诉输出流任何后续整数值应该以十进制/十六进制/八进制输出,如果未指定则默认为dec。这三个操作是持久的(persist)/“有粘性的(sticky)”,即对每个整数值的输出都生效,直到指定其他进制。像hex和oct这种用于改变流的行为的术语称为操纵符(manipulator)。
使用不同进制输出整数
注:
dec、hex和oct相当于C标准库printf的%d、%x和%o,但C++的操纵符是持久的,而printf的格式说明符仅对一个参数生效。- 这三个操纵符实际上是三个函数,分别设置了输出流对应的格式标志位。经常用到的
endl也是这样的函数,其作用就是向输出流写入一个字符'\n'。另外,接受函数指针参数的重载运算符<<就是以流本身为参数调用该函数。其定义大致等价于:
ostream& ostream::operator<<(ios_base& (*pf)(ios_base&)) {pf(*this);return *this;
}ios_base& dec(ios_base& base) {base.setf(ios_base::dec, ios_base::basefield);return base;
}ios_base& hex(ios_base& base) {base.setf(ios_base::hex, ios_base::basefield);return base;
}ios_base& oct(ios_base& base) {base.setf(ios_base::oct, ios_base::basefield);return base;
}ostream& endl(ostream& os) {os.put('\n');return os;
}
因此,以下语句是等价的:
cout << endl;
cout.operator<<(endl);
endl(cout);
cout.put('\n');
cout << hex;
cout.operator<<(hex);
hex(cout);
cout.setf(ios_base::hex, ios_base::basefield);
- 输入/输出流使用位掩码类型ios_base::fmtflags来表示格式标志位,并通过
flags()、setf()和unsetf()三个成员函数来设置或清除格式标志位。hex、showbase、boolalpha等操纵符就是通过调用setf()来设置对应标志位的辅助函数。
使用其他进制输出数值时默认不显示基底(例如1234的十六进制输出为 “4d2” 而不是 “0x4d2”)。可以使用操纵符showbase显示基底:
cout << dec << 1234 << ' ' << hex << 1234 << ' ' << oct << 1234 << '\n';
cout << showbase; // show bases
cout << dec << 1234 << ' ' << hex << 1234 << ' ' << oct << 1234 << '\n';
将输出
1234 4d2 2322
1234 0x4d2 02322
即十进制数没有前缀,八进制数带前缀 “0”,十六进制数带前缀 “0x”。这与C++源代码中整数字面值的表示方式是完全一致的(见《C程序设计语言》笔记 第2章 类型、运算符与表达式 2.3节)。
showbase也是持久的。操纵符noshowbase恢复默认行为,即不显示基底。
注:showbase相当于printf格式说明符中的#,即%#x和%#o,区别在于showbase是持久的。
小结:整数输出操纵符
| 操纵符 | 作用 |
|---|---|
dec | 使用十进制(默认) |
hex | 使用十六进制 |
oct | 使用八进制 |
showbase | 显示基底前缀 |
noshowbase | 不显示基底前缀(默认) |
注:所有的位开关操纵符都定义在头文件<ios>中(包含<iostream>即可自动包含该头文件),完整列表见ios - cplusplus.com和ios - cppreference.com,参数化操纵符定义在头文件<iomanip>中(见11.2.4节)。
11.2.2 整数输入
默认情况下,>>假设数值是十进制表示,也可以使用hex或oct指定按十六进制或八进制读取:
使用不同进制输入整数
如果输入
1234 4d2 2322 2322
将输出
1234 1234 1234 1234
在读取整数时,dec不接受前缀,hex接受可选的 “0x” 前缀,oct接受可选的 “0” 前缀(三个操纵符都接受可选的前导0)。例如:
| 操纵符 | 输入 | 读取的整数值(十进制) |
|---|---|---|
dec | “1234”, “01234”, “00001234” | 1234 |
hex | “4d2”, “0x4d2”, “04d2”, “0x04d2” | 1234 |
oct | “2322”, “02322”, “00002322” | 1234 |
可以使用流的成员函数unsetf()将dec、hex和oct对应的标志位全部清除:cin.unsetf(ios_base::basefield),此时输入流处于同时接受三种进制的状态。现在,对于代码
cin >> a >> b >> c >> d;
如果输入
1234 0x4d2 02322 02322
将输出
1234 1234 1234 1234
如果不调用unsetf()函数,则b的输入将会失败,因为 “0x4d2” 不是一个合法的十进制数。
11.2.3 浮点数输出
浮点数输出格式操纵符如下:
| 操纵符 | 作用 |
|---|---|
fixed | 使用固定浮点表示 |
scientific | 使用科学记数法表示 |
defaultfloat | 选择fixed和scientific中更精确的表示(默认) |
注:这三个操纵符都是持久的,分别类似于printf的%f、%e和%g。
例如:
cout << 1234.56789 << " (defaultfloat)\n"<< fixed << 1234.56789 << " (fixed)\n"<< scientific << 1234.56789 << " (scientific)\n";
将输出
1234.57 (defaultfloat)
1234.567890 (fixed)
1.234568e+03 (scientific)
11.2.4 精度
默认情况下,defaultfloat格式使用6位有效数字打印浮点值,选择最合适的格式,并按四舍五入规则进行舍入。例如,1234.5678打印为 “1234.57”,1.2345678打印为 “1.23457”,1234567.0打印为 “1.23457e+06”。
使用不同格式输出浮点数
可以使用操纵符setprecision(n)来设置精度(precision):对于defaultfloat是指有效数字位数,对于fixed和scientific是指小数点后的数字位数,默认为6。例如:
设置精度
将打印(注意舍入)
1234.57 1234.567890 1.234568e+03
1234.6 1234.56789 1.23457e+03
1234.5679 1234.56789000 1.23456789e+03
注:
setprecision()是持久的。- 对于
fixed格式的浮点数,setprecision(n)相当于printf格式说明符%m.nd中的n;对整数和字符串无效(printf格式说明符中的精度对整数和字符串有效,见《C程序设计语言》笔记 第7章 输入与输出 7.2节)。 setprecision()和其他参数化操纵符定义在头文件<iomanip> (I/O manipulators)中,与hex、showbase等位开关操纵符的区别是这些操纵符需要指定一个参数。os << setprecision(n)等价于os.precision(n)
11.2.5 域
对于整数、浮点数和字符串,可以使用操纵符setw(n)精确指定一个值在输出中所占的宽度,这种机制称为域(field)。这对于打印表格很有用。例如:
设置域宽度
将打印
12345|12345| 12345|12345|
1234.5|1234.5| 1234.5|1234.5|
abcde|abcde| abcde|abcde|
注意:
setw()不是持久的。setw(n)相当于printf格式说明符%nd中的n。- 当域宽度小于实际宽度时不会截断,域宽度无效;当域宽度大于实际宽度时填充空格,默认右对齐。可以使用操纵符
setfill(c)指定填充字符,left和right指定对齐方式。
打印联系方式表格
11.3 文件打开和定位
从C++的角度,文件是操作系统提供的一个抽象。如10.3节所述,文件就是一个从0开始编号的字节序列。流的属性决定了打开文件后可以执行什么操作,以及操作的含义。
11.3.1 文件打开模式
有多种文件打开模式。默认情况下,ifstream打开的文件用于读,ofstream打开的文件用于写,这满足的大多数常见需求。但是,也可以选择其他打开模式,使用位掩码类型ios_base::openmode表示:
| 打开模式 | 含义 |
|---|---|
app | (append) 追加模式 |
ate | (at end) 文件尾模式 |
binary | 二进制模式 |
in | (input) 读模式 |
out | (output) 写模式 |
trunc | (truncate) 覆盖原有内容 |
可以在文件流构造函数的文件名参数之后指定打开模式:
ofstream ofs(name1); // defaults to ios_base::out
ifstream ifs(name2); // defaults to ios_base::in
ofstream ofs2(name, ios_base::app); // ofstreams by default include io_base::out
fstream fs(name, ios_base::in | ios_base::out); // both in and out
其中|是按位或(bitwise OR)运算符,可用于组合多个模式。
打开文件的具体效果取决于操作系统。如果操作系统不能使用某种特定模式打开文件,结果将使流进入非good()状态。以读模式打开文件失败最常见的原因是文件不存在。
注意,如果以写模式打开一个不存在的文件,操作系统会创建一个新文件;而以读模式打开一个不存在的文件则会失败。
注:
ifstream和ofstream的默认打开模式分别是in和out,即使指定了其他模式,也会分别自动添加in和out。app与ate的区别:app在每次写操作前都定位到文件尾部,因此只能在文件尾部写数据;ate在打开文件后立即定位到文件尾部,但之后可以定位到文件的其他位置(见11.3.3节)。- C++文件流的打开模式与C标准库
fopen()函数的打开模式对应关系如下:
| C++模式 | C模式 | 含义 |
|---|---|---|
in | r | 读 |
out 或 out | trunc | w | 写(覆盖原有内容) |
app 或 out | app | a | 追加 |
in | out | r+ | 读或写 |
in | out | trunc | w+ | 读或写(覆盖原有内容) |
in | out | app | a+ | 读或追加 |
in | binary | rb | 读二进制文件 |
out | binary 或 out | trunc | binary | wb | 写二进制文件(覆盖原有内容) |
app | binary 或 out | app | binary | ab | 追加二进制文件 |
in | out | binary | r+b 或 rb+ | 读或写二进制文件 |
in | out | trunc | binary | w+b 或 wb+ | 读或写二进制文件(覆盖原有内容) |
in | out | app | binary | a+b 或 ab+ | 读或追加二进制文件 |
来源:https://timsong-cpp.github.io/cppwp/n3337/input.output#tab:iostreams.file.open.modes
11.3.2 二进制文件
默认情况下,iostream以文本模式读写文件,即读写字符序列(将字节按照特定字符集的编码转换为字符)。但是,也可以让istream和ostream直接读写字节。这称为二进制I/O (binary I/O),通过以binary模式打开文件实现。
例如,下图是12345分别在文本文件和二进制文件中的表示方式:

在文本文件中,使用31 32 33 34 35五个字节来表示 “12345” 这个字符串(字符 ‘1’ 的ASCII码是49,等于十六进制的0x31,以此类推);在二进制文件中,则使用四个字节39 30 00 00来表示4字节整数0x00003039(小端顺序),等于十进制的12345。
注:磁盘上只能保存由0和1组成的二进制数据,但通常用十六进制作为简便表示,与二进制的对应关系是:每个十六进制数对应4个二进制位,如下表所示
| 十六进制数 | 二进制数 | 十六进制数 | 二进制数 |
|---|---|---|---|
| 0 | 0000 | 8 | 1000 |
| 1 | 0001 | 9 | 1001 |
| 2 | 0010 | A | 1010 |
| 3 | 0011 | B | 1011 |
| 4 | 0100 | C | 1100 |
| 5 | 0101 | D | 1101 |
| 6 | 0110 | E | 1110 |
| 7 | 0111 | F | 1111 |
因此,上图所示的两个文件在磁盘上保存的实际数据分别为
31 32 33 34 35 = 00110001 00110010 00110011 00110100 0011010139 30 00 00 = 00111001 00110000 00000000 00000000
从这个角度看,文本文件和二进制文件本质上并没有区别,都是二进制字节数据,字节的含义完全是由文件格式人为定义的(如10.3节所述)。
下面是一个读写二进制整数文件的例子:
读写二进制整数文件
这里使用模式ios_base::binary打开二进制文件:
ifstream ifs(iname, ios_base::binary);
ofstream ofs(oname, ios_base::binary);
当我们从面向字符的I/O转向二进制I/O时,不能使用>>和<<运算符,因为这两个运算符按默认规则将值转换为字符序列(例如,字符串"asdf"转换为字符 ‘a’, ‘s’, ‘d’, ‘f’,整数123转换为字符 ‘1’, ‘2’, ‘3’)。而binary模式告诉流不要试图对字节做任何“聪明”的处理。
在这个例子中,对于int的“聪明”的处理是指用4个字节存储一个int(就像在内存中的表示方式一样),并直接将这些字节写入文件。之后,可以用相同的方式读回这些字节并重组出int:
ifs.read(as_bytes(x), sizeof(int));
ofs.write(as_bytes(x), sizeof(int));
istream的read()和ostream的write()都接受一个地址(这里由as_bytes()函数提供)和字节(字符)数量(这里使用运算符sizeof获得),其中地址指向保存要读/写的值的内存区域的第一个字节。例如,有一个int变量i,其值为1234(用十六进制表示为0x000004d2)则将其写入二进制文件的过程如下图所示:
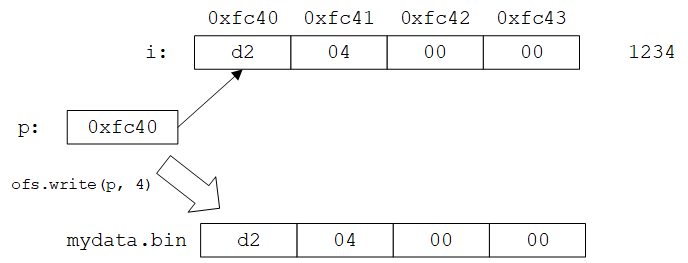
首先,通过as_bytes(i)获得指向i的第一个字节的地址p(假设为0xfc40),之后调用ofs.write(p, 4)将从该地址开始的4个字节写入ofs,即write()所做的事仅仅是简单的字节拷贝,read()同理。
注:
- 从上图中可以看出,内存在本质上与文件一样,都是编号的字节序列。这里的编号叫做地址(address),通过取地址运算符
&获得,例如&i;保存地址的变量叫做指针(pointer),例如p。详见17.3节和《C程序设计语言》笔记 第5章 指针与数组。 - 由于
read()和write()函数的第一个参数类型是char*,而i的地址&i的类型是int*,因此as_bytes()函数使用reinterpret_cast将其强制转换为char*类型(但指针的值不变),从而将一个int的4个字节视为4个char,见17.8节。
二进制I/O复杂、容易出错。然而,对于某些文件格式必须使用二进制I/O,典型的例子是图片或声音文件。iostream库默认提供的字符I/O可移植、人类可读,而且被类型系统所支持。如果可以选择,尽量使用字符I/O(文本格式)。
11.3.3 在文件中定位
只要可以,最好使用从头到尾读写文件的方式,这是最简单、最不容易出错的方式。很多时候,当你需要修改一个文件,更好的方式是生成一个新的文件。
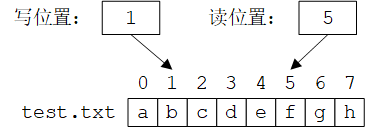
但是,如果必须“原地”修改文件,可以使用定位(positioning/seek)功能:在文件中选择一个特定的位置(字节编号)进行读写。每个以读模式打开的文件都有一个读位置(read/get position),每个以写模式打开的文件都有一个写位置(write/put position),如下如所示。
可以使用istream和ostream的以下函数定位读/写位置:
| 函数 | 作用 |
|---|---|
tellg() | 获取当前读位置 |
seekg() | 设置读位置(g = “get”) |
tellp() | 获取当前写位置 |
seekp() | 设置写位置(p = “put”) |
例如:
fstream fs(name); // open for input and output
if (!fs) error("can't open ", name);fs.seekg(5); // move reading position to 5 (the 6th character)
char ch;
fs >> ch; // read and increment reading position
cout << "character[5] is " << ch << ' (' << int(ch) << ")\n";fs.seekp(1); // move writing position to 1
fs << 'y'; // write and increment writing position
假设文件test.txt的原始内容为 “abcdefgh”,如上图所示,则上面的程序执行后文件的读写位置如下图所示:
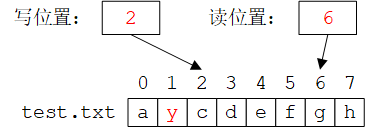
其中,运算符>>会使读位置增加读取的字符数,运算符<<会使写位置增加写入的字符数。
注意,如果试图定位到文件结尾之后的位置,结果是未定义的,不同操作系统可能会表现出不同的行为。
11.4 字符串流
可以将一个string作为istream的源或ostream的目标。从字符串读取的istream叫做istringstream,向字符串写入的ostream叫做ostringstream,这两个类定义在头文件 <sstream> 中。例如,istringstream可用于从字符串中提取数值:
字符串转浮点数
如果试图从istringstream的字符串结尾之后读取,istringstream将进入eof()状态。这意味着可以将“标准输入循环”用于istringstream。
ostringstream可用于生成格式化字符串(类似于Java的StringBuilder):
ostringstream os; // stream for composing a message
os << setw(8) << label << ": "<< fixed << setprecision(5) << temp << unit;
someobject.display(Point(100, 100), os.str());
ostringstream的成员函数str()返回结果字符串。
ostringstream的一个简单应用是拼接字符串:
int seq_no = get_next_number(); // get the number of a log file
ostringstream name;
name << "myfile" << seq_no << ".log"; // e.g., myfile17.log
ofstream logfile(name.str()); // e.g., open myfile17.log
istringstream和ostringstream均支持以下操作:
| 成员函数 | 作用 |
|---|---|
| 默认构造函数 | 使用空字符串初始化字符串流 |
| 构造函数(s) | 使用字符串s的拷贝初始化字符串流 |
str() | 返回当前内容的拷贝 |
str(s) | 将字符串s设置为当前内容,覆盖原有内容 |
通常情况下,我们用一个字符串来初始化istringstream,然后使用>>从字符串中读取字符。相反,通常用一个空字符串初始化ostringstream,然后用<<向其中填入字符,并使用str()获取结果。
11.5 面向行的输入
运算符>>按照对象类型的标准格式读取输入。例如,在读取一个int时,会读取到非数字字符为止;在读取一个string时,会跳过空白符,并读取到下一个空白符为止;在读取一个char时,会跳过空白符,并读取下一个非空白字符。例如:
string name;
cin >> name; // input: Dennis Ritchie
cout << name << '\n'; // output: Dennis
istream也提供了读取单个字符和整行的功能:
| 成员函数 | 作用 |
|---|---|
get() | 读取一个字符并返回 |
get(c) | 读取一个字符并赋值给c,返回输入流对象 |
getline(s, n) | 读取字符并保存到C风格字符串s中,直到遇到换行符或已读取n个字符(包括结尾的空字符) |
头文件<string>还提供了一个非成员函数版本getline(is, s),用于从输入流is读取一行内容到字符串s中(丢弃换行符)。例如:
string name;
getline(cin, name); // input: Dennis Ritchie
cout << name << '\n'; // output: Dennis Ritchie
需要读取一整行的一个常见原因是:空白符的定义不合适。例如,需要将换行符与其他空白符区别对待。例如,游戏中的文本交互可能将一行视为一句话,此时需要先读取一整行,然后从中提取各个单词:
string command;
getline(cin, command); // read the linestringstream ss(command);
vector<string> words;
for (string s; ss >> s;)words.push_back(s); // extract the individual words
但是,只要可以选择,还是尽量使用>>而不是getline()。
11.6 字符分类
通常,我们按习惯格式读取整数、浮点数、字符串等。然而,有时必须读取单个字符并判断字符种类(例如7.8.2节词法分析器读取标识符)。
标准库头文件<cctype>定义了一组字符分类和转换函数,例如判断一个字符是否是数字、是否是大写字母,转换大小写等。
11.7 使用非标准分隔符
本节提供一个接近真实的例子:使用自定义的分隔符读取字符串。istream的运算符>>读取字符串时以默认空白符作为分隔符,而并没有提供自定义分隔符的功能。因此,在4.6.4节的例子中,如果输入
As planned, the guests arrived; then,
将会得到这些“单词”:
As
arrived;
guests
planned,
the
then,
为了去掉这些标点符号,可以直接读取一整行,将标点符号删除或替换为空白符,之后再次读取处理后的输入:
string line;
getline(cin,line); // read into line
for (char& ch : line) // replace each punctuation character by a spaceswitch(ch) {case ';': case '.': case ',': case '?': case '!':ch = ' ';}stringstream ss(line); // make an istream ss reading from linevector<string> vs;for (string word; ss >> word;) // read words without punctuation charactersvs.push_back(word);
然而,这段代码有些混乱,并且是非通用的,改变“标点”的定义就无法使用了。下面提出一种更为通用的从输入流中删除不需要的字符的方法。基本思想是:先从一个普通的输入流读取单词,之后将用户指定的分隔符视为空白符,用来分隔单词。例如,“as.not” 应该是两个单词 “as not”。
我们可以定义一个类Punct_stream来实现上述功能。该类必须从一个istream读取字符,要有读取字符串的>>运算符,并且允许用户指定分隔符。
Punct_stream类
和上面的示例一样,基本思想是每次从istream读取一行,将“空白符”(分隔符)转换为空格,然后使用istringstream的>>运算符读取字符串,当这一行的字符全部读取完后再读取下一行。另外,可以通过case_sensitive()指定是否大小写敏感。
最有趣的、也是最难实现的操作是运算符>>,下面逐行分析。
首先,while (!(buffer >> s))尝试从名为buffer的istringstream中读取(真正的)空白符分隔的字符串。只要buffer中还有字符,buffer >> s就会成功,之后就没什么可做的了,直接返回;当buffer中的字符被消耗完时,buffer >> s会失败,即!(buffer >> s)为true,则进入循环体,此时必须从source读取一行,将buffer重新填满。注意,buffer >> s是在一个循环中,因此重新填充buffer后会再次尝试这个操作(第二次读取仍然有可能失败,因为下一行可能是个空行)。
接下来,if (buffer.bad() || !source.good())判断如果buffer处于bad()状态(一般不会发生)或者source不是good()状态(例如到达输入结尾)则放弃,直接返回。否则,清除buffer的错误状态(因为进入循环的原因通常是buffer遇到eof(),即上一行字符被消耗完)。处理流状态总是很麻烦的,而且常常是微妙错误的根源,需要冗长的调试来消除。
循环的剩余部分很简单。getline(source, line)从source读取一行到line,然后检查每个字符看是否需要改变:如果是自定义的“空白符”则替换为空格,如果大小写不敏感则转换为小写。最后buffer.str(line)将处理完的内容存入buffer。
注意,调用getline()后没有检测source的状态,这里不需要,因为最终会到达循环顶部的!source.good()。
最后,将流自身的引用*this作为>>的返回值(见17.10节)。
is_whitespace()的实现很简单,使用string的成员函数find()即可:在字符串中查找指定的字符,如果存在则返回第一次出现的索引,否则返回string::npos。
只剩下一个神秘的函数operator bool。operator T是一种特殊的重载运算符,叫做类型转换运算符,用于将对象转换为T类型,必须定义为成员函数。
istream的一种习惯用法是测试>>的结果,例如if (is >> s)。而is >> s的结果是一个istream(的引用),这意味着我们需要一种将istream隐式转换为bool值的方法,这就是istream::operator bool()所做的事情(见10.6节):
if (is >> s)等价于if ((is >> s).operator bool())if (!(is >> s))等价于if ((is >> s).operator!())
Punct_stream也支持这种操作,因此定义了operator bool函数。
注:由basic_ios::good()和10.6节中的表格可以推出以下逻辑蕴涵关系:
is.bad()→is.fail()is.good()→!is.fail()
从而书中代码给出的Punct_stream::operator bool()的实现可以简化为return source.good();。
现在可以编写程序:
自定义分隔符的字典
注意:Punct_stream在很多重要的方面都与istream相似(支持>>和operator bool),但它并不是真的istream(不是继承自istream)。例如,它没有eof()等状态,也没有提供读取整数的>>。重要的是,不能将一个Punct_stream对象传递给一个期望istream参数的函数。
11.8 还有很多
- 本地化(locale)
- 缓冲机制(buffering):streambuf
- C标准库的
printf()和scanf()
简单练习
- 11-1~11-7
- 11-8
- 11-9
- 11-10