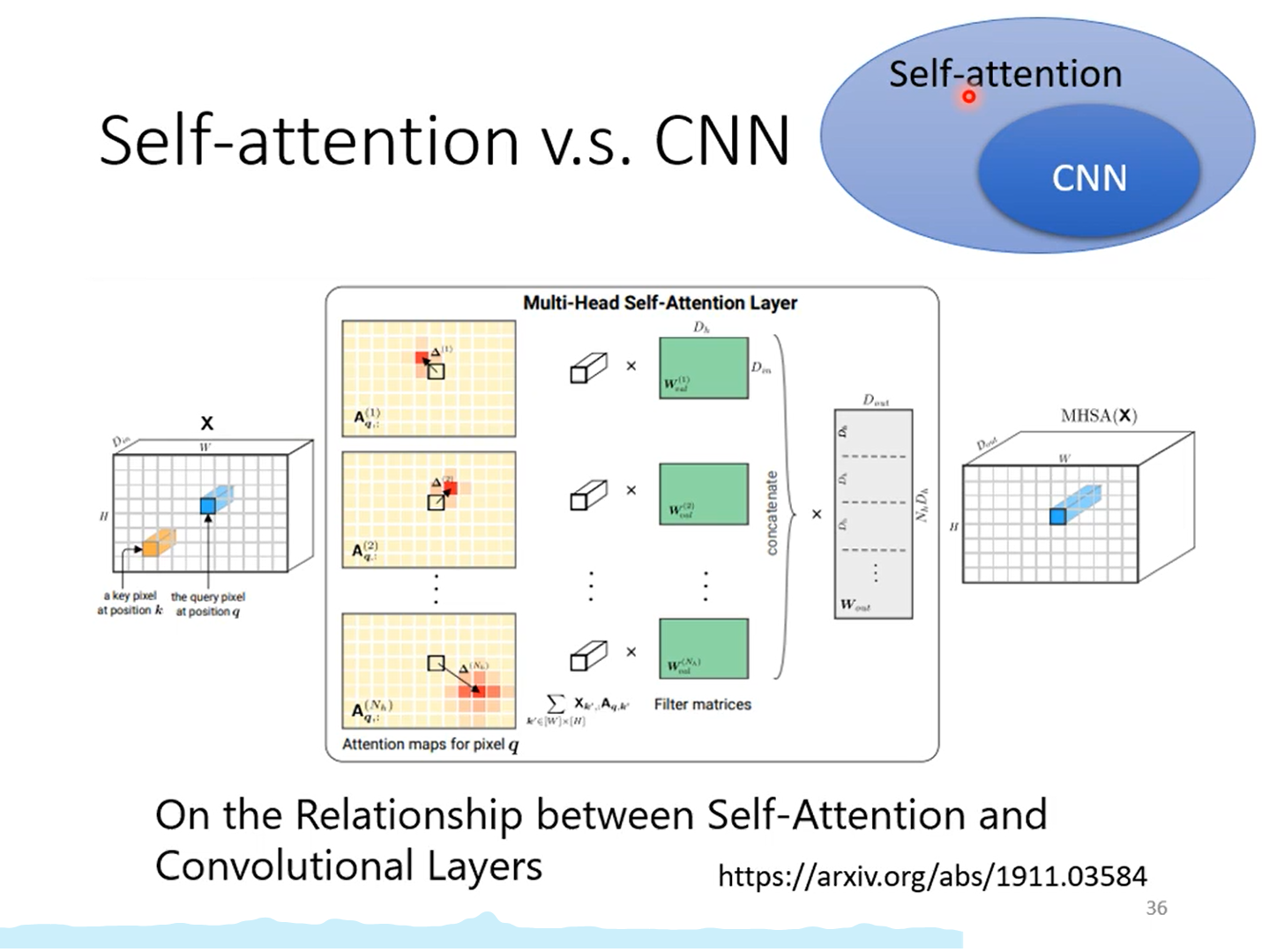
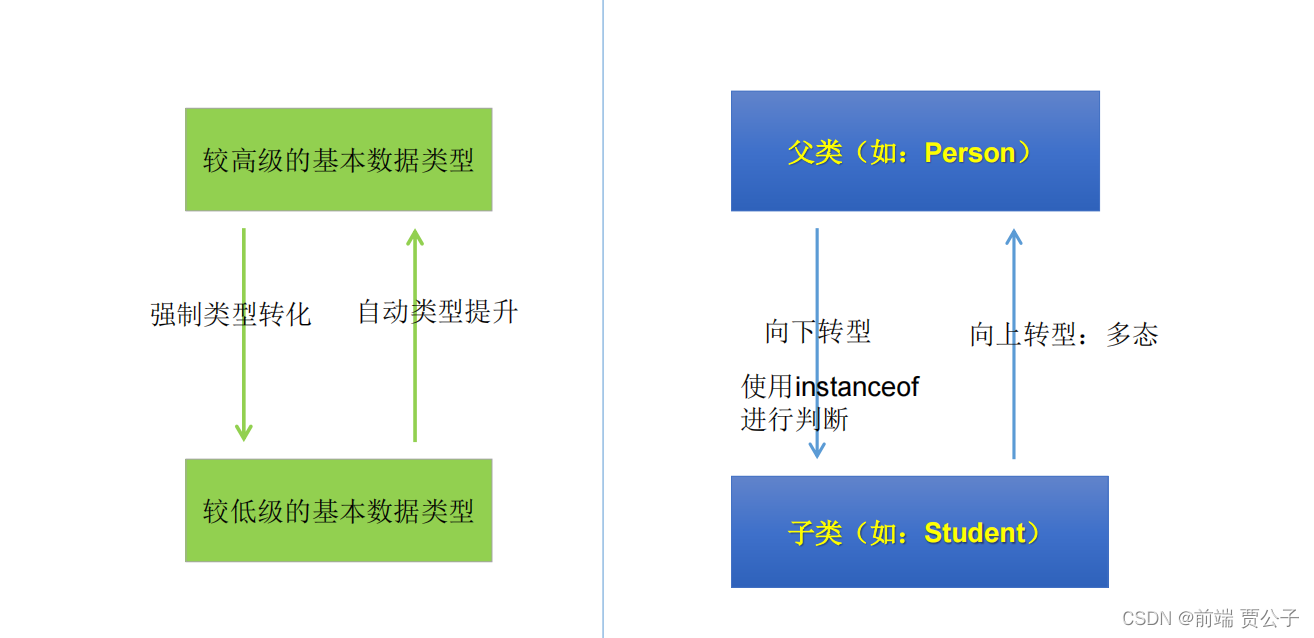
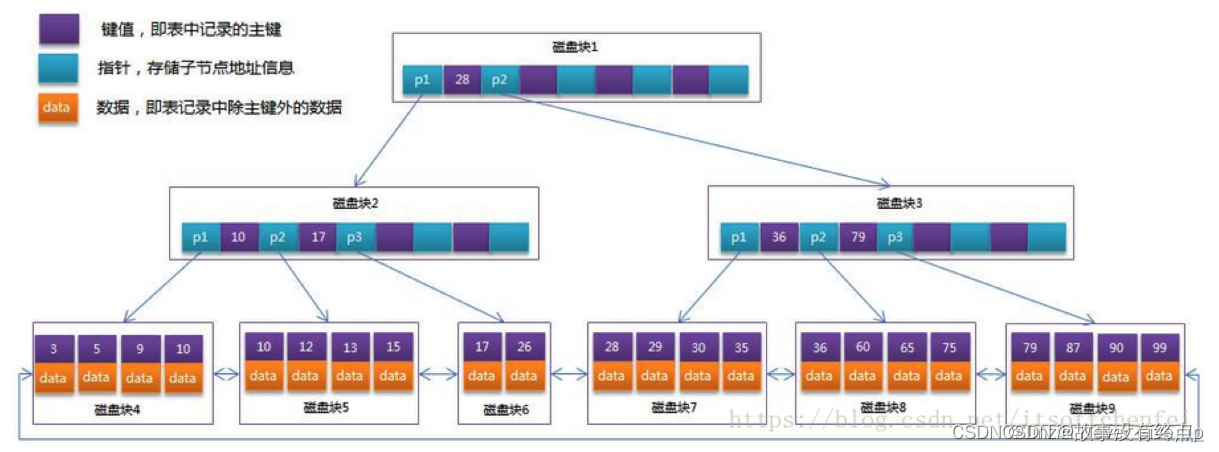
Android之Handler、Message、MessageQueue、Looper详解
- Handler
- Handler的原理
- 线程间通信的实现步骤
- Handler在多线程中的应用
- 如何在子线程中创建Handler
- Hander中removeMessages方法
- Handler内存泄漏
- Handler发生内存泄漏的情况
- 解决内存泄漏
- Handler.post 和 Handler.sendMessage的区别
- Handler.post 和 View.post的区别
- new Handler()和new Handler(Looper.getMainLooper())的区别
- Message
- Message.obtain() 和Handler.obtainMessage()的区别
- message.what、message.arg1、message.arg2、message.obj它们之间有什么区别
- MessageQueue
- MessageQueue的数据结构是什么
- MessageQueue为什么要用这个数据结构
- Looper
- Handler、Looper、Message、MessageQueue关系是什么
Handler
Handler的原理
Handler的原理:
Android中主线程是不能进行耗时操作的,子线程是不能进行更新UI的。所以就有了Handler,它的作用就是实现线程之间的通信。
Handler整个流程中,主要有四个对象,handler,Message,MessageQueue,Looper。当应用创建的时候,就会在主线程中创建handler对象,我们通过要传送的消息保存到Message中,handler通过调用sendMessage方法将Message发送到MessageQueue中,Looper对象就会不断的调用loop()方法 不断的从MessageQueue中取出Message交给handler进行处理。从而实现线程之间的通信。
线程间通信的实现步骤
线程间通信的实现步骤:
- 在主线程中定义Handler的子类
- 重写Handler类的handleMessage()方法
- 用该子类定义全局的Handler对象,以便子线程使用
- 子线程获得handler对象用该对象的sendMessage()方法发送消息
Handler在多线程中的应用
- 发送消息,在不同的线程间发送消息,使用的方法为sendXXX();。
android.os.Handler对象通过下面的方法发送消息的:
- sendEmptyMessage(int):发送一个空的消息;
- sendMessage(Message):发送消息,消息中可以携带参数;
- sendMessageAtTime(Message, long):未来某一时间点发送消息;
- sendMessageDelayed(Message, long):延时Nms发送消息。
- 计划任务,在未来执行某任务,使用的方法为postXXX();。
android.os.Handler对象通过下面的方法执行计划任务:
- post(Runnable):提交计划任务马上执行;
- postAtTime(Runnable, long):提交计划任务在未来的时间点执行;
- postDelayed(Runnable, long):提交计划任务延时Nms执行。
如何在子线程中创建Handler
如何在子线程中创建Handler?
- 创建一个 HandlerThread,即创建一个包含 Looper 的线程HandlerThread 的构造函数有两个
- 通过 HandlerThread 的 getLooper 方法可以获取 Looper
- 通过 Looper 我们就可以创建子线程的 handler 了
- 通过该 handler 发送消息,就会在子线程执行;
如果要 handlerThread 停止: handlerThread.quit();
Hander中removeMessages方法
Hander中removeMessages方法
- 这个方法使用的前提是之前调用过sendEmptyMessageDelayed(0, time),意思是延迟time执行handler中msg.what=0的方法;
- 在延迟时间未到的前提下,执行removeMessages(0),则上面的handler中msg.what=0的方法取消执行;
- 在延迟时间已到,handler中msg.what=0的方法已执行,再执行removeMessages(0),不起作用。
- 该方法会将handler对应message队列里的消息清空,通过msg.what来找到对应的message。
- 当队列中没有message则handler会不工作,但并不是handler会停止,当队列中有新的message进来后,会继续处理执行。
Handler内存泄漏
Handler发生内存泄漏的情况
Handler发生内存泄漏的情况:
- 非静态内部类,或者匿名内部类。
使得Handler默认持有外部类的引用。在Activity销毁时,由于Handler可能有未执行完/正在执行的Message。导致Handler持有Activity的引用。进而导致GC无法回收Activity- 发送延迟消息
第一种情况,是通过handler发送延迟消息,我们在HandlerActivity中,发送一个延迟20s的消息。然后打开HandlerActivity后,马上finish。看看会不会内存泄漏。
我们的HandlerActivity发生了内存泄漏,从引用路径来看,是被匿名内部类的实例mHandler持有引用了,而Handler的引用是被Message持有了,Message引用是被MessageQueue持有了…
结合我们所学的Handler知识和这次引用路径分析,这次内存泄漏完整的引用链应该是:
主线程 —> threadlocal —> Looper —> MessageQueue —> Message —> Handler —> Activity
所以这次引用的头头就是主线程,主线程肯定是不会被回收的,只要是运行中的线程都不会被JVM回收,跟静态变量一样被JVM特殊照顾。- 子线程运行没结束
第二个实例,是我们常用到的,在子线程中工作,比如请求网络,然后请求成功后通过Handler进行UI更新运行中的子线程 —> Activity
当然,这里的Handler也是持有了Activity的引用的,但主要引起内存泄漏的原因还是在于子线程本身,就算子线程中不用Handler,而是调用Activity的其他变量或者方法还是会发生内存泄漏。
所以这种情况我觉得不能看作Handler引起内存泄漏的情况,其根本原因是因为子线程引起的,如果解决了子线程的内存泄漏,比如在Activity销毁的时候停止子线程,那么Activity就能正常被回收,那么也不存在Handler的问题了
解决内存泄漏
解决内存泄漏
- 不要让长生命周期对象持有短生命周期对象的引用,而是用长生命周期对象持有长生命周期对象的引用
比如Glide使用的时候传的上下文不要用Activity而改用Application的上下文(这句有问题,并无此说法,在此修正)。还有单例模式不要传入Activity上下文- 将对象的强引用改成弱引用
强引用就是对象被强引用后,无论如何都不会被回收。 弱引用就是在垃圾回收时,如果这个对象只被弱引用关联(没有任何强引用关联他),那么这个对象就会被回收。 所以我们将对象改成弱引用,就能保证在垃圾回收时被正常回收。软引用就是在系统将发生内存溢出的时候,回进行回收。 虚引用是对象完全不会对其生存时间构成影响,也无法通过虚引用来获取对象实例,用的比较少- 内部类写成静态类或者外部类
跟上面Hanlder情况一样,有时候内部类被不正当使用,容易发生内存泄漏,解决办法就是写成外部类或者静态内部类- 在短周期结束的时候将可能发生内存泄漏的地方移除
比如Handler延迟消息,资源没关闭,集合没清理等等引起的内存泄漏,只要在Activity关闭的时候进行消除即可
Handler.post 和 Handler.sendMessage的区别
handler.post 和 handler.sendMessage本质上是没有区别的,都是发送一个消息到消息队列中,而且消息队列和 handler 都是依赖于同一个线程的
- post和sendMessage本质上是没有区别的,只是实际用法中有一点差别
- post也没有独特的作用,post本质上还是用sendMessage实现的,post只是一种更方便的用法而已
Handler.post 和 View.post的区别
相同点
在与UI线程的通信上,Handler与View,其实最终都做了同样的事情。就是将消息传递在UI线程的消息队列里,执行一些处理操作。
不同
View.post方法想在非UI线程有效工作。如该方法的注释所说,必须保证该View已经被添加至窗口。
This method can be invoked from outside of the UI thread only when this View is attached to a window.另外给一个stackoverflow的例子:
- Handler.post,它的执行时间基本是等同于onCreate里那行代码触达的时间;
- View.post,则不同,它说白了执行时间一定是在Act#onResume发生后才开始算的;或者换句话说它的效果相当于你上面的View.post方法是写在Act#onResume里面的(但只执行一次,因为onCreate不像onResume会被多次触发);
当然,虽然这里说的是post方法,但对应的postDelayed方法区别也是类似的
new Handler()和new Handler(Looper.getMainLooper())的区别
- 如果你不带参数的实例化:Handler handler = new Handler(); 这个会默认用当前线程的looper,一般情况是当前线程的异步线程与当前线程进行消息处理。
- getMainLooper()是获取UI主线程looper,在UI线程中处理消息;如果你的Handler是要用来刷新UI的,那么就需要在主线程下运行。
- 一般而言new Handler(Looper.getMainLooper())用于更新UI
- Handler handler = new Handler()用于当前线程与异步线程的消息处理
- 更新UI界面,handler要用到主线程的looper。那么在主线程 Handler handler = new Handler();如果在其他线程,也要满足这个功能的话,要Handler handler = new Handler(Looper.getMainLooper());
- 只进行处理消息操作。 当前线程如果是主线程的话,使用Handler handler = new Handler();
不是主线程的话,Looper.prepare(); Handler handler = new Handler();Looper.loop();或者Handler handler = new Handler(Looper.getMainLooper());
若是实例化的时候用Looper.getMainLooper()就表示放到主UI线程去处理;如果不是的话,因为只有UI线程默认Loop.prepare();Loop.loop();其他线程需要手动调用这两个,否则会报错。
Message
Message.obtain() 和Handler.obtainMessage()的区别
Message.obtain() 和Handler.obtainMessage()的区别
获取Message对象的最好方法是调用Message.obtain()或者Handler.obtainMessage(),这样是从一个可回收对象池中获取Message对象。
从整个Messge池中返回一个新的Message实例,在许多情况下使用它,因为它能避免分配新的对象,如果是这样的话,那么通过调用obtainMessage方法获取Message对象就能避免创建对象,从而减少内存的开销了
这两种方式都比直接new一个Message对象在性能上更优越
message.what、message.arg1、message.arg2、message.obj它们之间有什么区别
message.what、message.arg1、message.arg2、message.obj 他们之间有什么区别呢
- what就是一般用来区别消息的,比如你传进去的时候msg.what = 3;
然后处理的时候判断msg.what == 3是不是成立的,是的话,表示这个消息是干嘛干嘛的(自己能区别开)- arg1、arg2,其实也就是两个传递数据用的,两个int值,看你自己想要用它做什么了。如果你的数据只是简单的int值,那么用这两个,比较方便。
setData(Bundle),上面两个arg是传递简单int的,这个是传递复杂数据的- msg.obj呢,这个就是传递数据了,msg中能够携带对象,在handleMessage的时候,可以把这个数据取出来做处理了。不过呢,如果是同一个进程,最好用上面的setData就行了,这个一般是Messenger类来用来跨进程传递可序列化的对象的,这个比起上面的来,更消耗性能一些。
MessageQueue
MessageQueue的数据结构是什么
数据结构是单向链表,“先进先出”
MessageQueue为什么要用这个数据结构
- 解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息队列在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束- 冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。在被许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理过程明确的指出该消息已经被处理完毕,确保你的数据被安全的保存直到你使用完毕。- 扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的;只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。- 灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。- 可恢复性
当体系的一部分组件失效,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。而这种允许重试或者延后处理请求的能力通常是造就一个略感不便的用户和一个沮丧透顶的用户之间的区别。- 送达保证
消息队列提供的冗余机制保证了消息能被实际的处理,只要一个进程读取了该队列即可。在此基础上, IronMQ 提供了一个”只送达一次”保证。无论有多少进程在从队列中领取数据,每一个消息只能被处理一次。这之所以成为可能,是因为获取一个消息只是”预定”了这个消息,暂时把它移出了队列。除非客户端明确的表示已经处理完了这个消息,否则这个消息会被放回队列中去,在一段可配置的时间之后可再次被处理。- 顺序保证
在大多使用场景下,数据处理的顺序都很重要。消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。 IronMO 保证消息通过 FIFO(先进先出)的顺序来处理,因此消息在队列中的位置就是从队列中检索他们的位置。- 缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行—写入队列的处理会尽可能的快速,而不受从队列读的预备处理的约束。该缓冲有助于控制和优化数据流经过系统的速度。- 理解数据流
在一个分布式系统里,要得到一个关于用户操作会用多长时间及其原因的总体印象,是个巨大的挑战。消息系列通过消息被处理的频率,来方便的辅助确定那些表现不佳的处理过程或领域,这些地方的数据流都不够优化。- 异步通信
很多时候,你不想也不需要立即处理消息。消息队列提供了异步处理机制,允许你把一个消息放入队列,但并不立即处理它。你想向队列中放入多少消息就放多少,然后在你乐意的时候再去处理它们。
Looper
Handler、Looper、Message、MessageQueue关系是什么
Handler、Looper(轮循器)、MessageQueue(消息队列)、Message(消息)
- Message:Handler接收和处理的消息对象。
- MessageQueue:消息队列,他采用先进先出的方式来管理Message。Handler发送消息时先把消息发送到消息队列中。
- Looper:每个线程最多拥有一个Looper。他的Loop方法负责读取MessageQueue队列中的消息,读到信息之后就把信息交给发送该消息的Handler进行处理。程序在创建Looper对象的时候,会自动在Looper的构造器中自动创建一个MessageQueue队列对象。
- 注意:Handler发送的消息时先放入MessageQueue,所以handler要正常工作,必须当前线程先有MessageQueue
而MessageQueue是由Looper管理的,所以换句话说,Handler要正常工作必须先有Looper。
为了保证线程中有Looper,分两种情况。总结:
- 主线程中使用Handler直接创建即可以使用。
- 子线程中使用Handler的步骤:
- a:调用Loop.prepare();
- b:创建Handler对象;
- c:调用Looper.loop();