🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
设置工作环境
怎么做...
这个怎么运作...
还有更多...
也可以看看
安装 OpenAI Gym
怎么做...
这个怎么运作...
还有更多...
也可以看看
模拟 Atari 环境
怎么做...
这个怎么运作...
还有更多...
也可以看看
模拟 CartPole 环境
怎么做...
这个怎么运作...
还有更多...
回顾 PyTorch 的基础知识
怎么做...
还有更多...
也可以看看
实施和评估随机搜索策略
怎么做...
这个怎么运作...
还有更多...
开发爬山算法
怎么做...
还有更多...
也可以看看
开发策略梯度算法
怎么做...
这个怎么运作...
还有更多...
也可以看看
我们以基本但重要的强化学习算法(包括随机搜索、爬山和策略梯度)开始我们的实用强化学习和 PyTorch 之旅。我们将从设置工作环境和 OpenAI Gym 开始,您将通过 Atari 和 CartPole 游乐场熟悉强化学习环境。我们还将演示如何逐步开发算法来解决 CartPole 问题。此外,我们将回顾 PyTorch 的基本知识,并为即将到来的学习示例和项目做准备。
本章包含以下配方:
- 设置工作环境
- 安装 OpenAI Gym
- 模拟 Atari 环境
- 模拟 CartPole 环境
- 回顾 PyTorch 的基础知识
- 实施和评估随机搜索策略
- 开发爬山算法
- 开发策略梯度算法
设置工作环境
让我们开始设置工作环境,包括正确版本的 Python 和 Anaconda,以及作为贯穿本书的主要框架的 PyTorch。
Python 是我们用来实现全书所有强化学习算法和技术的语言。在本书中,我们将使用 Python 3,或者更具体地说,3.6 或更高版本。如果你是 Python 2 用户,现在是你切换到 Python 3 的最佳时机,因为 Python 2 将在 2020 年后不再受支持。不过过渡非常顺利,所以不要惊慌。
Anaconda是用于数据科学和机器学习的开源 Python 发行版 ( www.anaconda.com/distribution/ )。我们将使用 Anaconda 的包管理器conda安装 Python 包,以及pip.
PyTorch ( PyTorch ) 主要由 Facebook AI Research (FAIR) Group 开发,是一个基于 Torch ( Torch | Scientific computing for LuaJIT. ) 的流行机器学习库。PyTorch 中的张量取代了 NumPy 中的张量ndarrays,后者提供了更大的灵活性和与 GPU 的兼容性。由于强大的计算图和简单友好的界面,PyTorch 社区每天都在扩大,并被越来越多的科技巨头大量采用。
让我们看看如何正确设置所有这些组件。
怎么做...
我们将从安装 Anaconda 开始。如果您的系统上已经运行了适用于 Python 3.6 或 3.7 的 Anaconda,则可以跳过此步骤。否则,您可以按照适用于您的操作系统 的https://docs.anaconda.com/anaconda/install/上的说明进行操作,如下所示:

设置完成后,请随意使用 PyTorch。要验证您是否正确设置了 Anaconda 和 Python,您可以在 Linux/Mac 的终端或 Windows 的命令提示符中输入以下行(从现在开始,我们将其称为终端):
Python它将显示您的 Python Anaconda 环境。您应该会看到类似于以下屏幕截图的内容:

如果没有提到 Anaconda 和 Python 3.x,请检查系统路径或 Python 运行的路径。
接下来要做的是安装 PyTorch。首先,转到Start Locally | PyTorch并从下表中选择您的环境描述:
这里我们以Mac、Conda、Python 3.7、本地运行(无CUDA)为例,在Terminal中输入结果命令行:
conda install pytorch torchvision -c pytorch要确认 PyTorch 已正确安装,请在 Python 中运行以下代码行:
import torch
x = torch.empty(3, 4)
print(x)Output:
tensor([[ 0.0000e+00, 2.0000e+00, -1.2750e+16, -2.0005e+00],
[ 9.8742e-37, 1.4013e-45, 9.9222e-37, 1.4013e-45],
[ 9.9220e-37, 1.4013e-45, 9.9225e-37, 2.7551e-40]])
如果显示 3 x 4 矩阵,则表示 PyTorch 已正确安装。
现在我们已经成功地设置了工作环境。
这个怎么运作...
我们刚刚在 PyTorch 中创建了一个大小为 3 x 4 的张量。它是一个空矩阵。也就是说empty,这并不意味着所有元素都具有价值Null。相反,它们是一堆无意义的浮点数,被认为是占位符。用户需要稍后设置所有值。这与 NumPy 的空数组非常相似。
还有更多...
有些人可能会质疑安装 Anaconda 并使用conda它来管理包的必要性,因为使用pip. 事实上,conda是一个比pip. 我们主要conda出于以下四个原因使用:
- 它很好地处理库依赖关系:安装一个包conda将自动下载它的所有依赖关系。但是,这样做pip会导致警告,并且安装将中止。
- 它优雅地解决了包的冲突:如果安装一个包需要另一个特定版本的包(比如 2.3 或更高版本),conda将自动更新另一个包的版本。
- 它很容易创建一个虚拟环境:虚拟环境是一个独立的包目录树。不同的应用程序或项目可以使用不同的虚拟环境。所有的虚拟环境都是相互隔离的。建议使用虚拟环境,这样我们对一个应用程序所做的任何事情都不会影响我们的系统环境或任何其他环境。
- 它也与 pip 兼容:我们仍然可以使用pipinconda和以下命令:
conda install pip也可以看看
如果您有兴趣了解有关 的更多信息conda,请随时查看以下资源:
- Conda 用户指南:https ://conda.io/projects/conda/en/latest/user-guide/index.html
- 使用 conda 创建和管理虚拟环境:https ://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html
如果你想更熟悉 PyTorch,可以阅读官方教程中的入门部分,网址为Welcome to PyTorch Tutorials — PyTorch Tutorials 1.13.0+cu117 documentation。我们建议您至少完成以下操作:
- 什么是 PyTorch:https ://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor-tutorial-py
- 通过示例学习 PyTorch:https ://pytorch.org/tutorials/beginner/pytorch_with_examples.html
安装 OpenAI Gym
设置工作环境后,我们现在可以安装 OpenAI Gym。不使用 OpenAI Gym 就无法进行强化学习,OpenAI Gym 为您提供了开发学习算法的各种环境。
OpenAI ( https://openai.com/ ) 是一家非营利性研究公司,专注于构建安全的通用人工智能( AGI ) 并确保其造福人类。OpenAI Gym是一个强大的开源工具包,用于开发和比较强化学习算法。它为各种强化学习模拟和任务提供了一个接口,从步行到登月,从赛车到玩 Atari 游戏。有关环境的完整列表,请参阅https://gym.openai.com/envs/ 。我们可以编写代理以使用任何数值计算库(例如 PyTorch、TensorFlow 或 Keras)与 OpenAI Gym 环境交互。
怎么做...
有两种安装 Gym 的方法。第一种是使用pip,如下:
pip install gym对于conda用户,请记住pip先conda使用以下命令安装,然后再使用以下命令安装 Gym pip:
conda install pip这是因为conda截至 2019 年初,Gym 尚未正式可用。
另一种方法是从源代码构建:
1.首先,直接从 Git 存储库中克隆包:
git clone https://github.com/openai/gym2.转到下载的文件夹并从那里安装 Gym:
cd gym
pip install -e 现在你可以开始了。随意使用gym.
3.您还可以gym通过键入以下代码行来检查可用环境:
from gym import envs
print(envs.registry.all())
dict_values([EnvSpec(Copy-v0),EnvSpec(RepeatCopy-v0),EnvSpec(ReversedAddition-v0),EnvSpec(ReversedAddition3-v0) , EnvSpec(DuplicatedInput-v0), EnvSpec(Reverse-v0), EnvSpec(CartPole-v0), EnvSpec(CartPole-v1), EnvSpec(MountainCar-v0), EnvSpec(MountainCarContinuous-v0), EnvSpec(Pendulum-v0), EnvSpec(Acrobot-v1),EnvSpec(LunarLander-v2),EnvSpec(LunarLanderContinuous-v2),EnvSpec(BipedalWalker-v2),EnvSpec(BipedalWalkerHardcore-v2),EnvSpec(CarRacing-v0),EnvSpec(Blackjack-v0)
.. ……
_
如果您正确安装了 Gym,这将为您提供一长串环境。我们将在下一个秘籍模拟 Atari 环境中尝试其中的一些。
这个怎么运作...
与pip安装 Gym 的简单方法相比,如果您想添加新环境和修改 Gym 本身,第二种方法提供了更大的灵活性。
还有更多...
你可能想知道为什么我们需要在 Gym 的环境中测试强化学习算法,因为我们工作的实际环境可能有很大不同。你会记得,强化学习不会对环境做出很多假设,但它会通过与环境交互来了解更多关于环境的信息。此外,在比较不同算法的性能时,我们需要将它们应用到标准化环境中。Gym 是一个完美的基准,涵盖了许多多功能且易于使用的环境。这类似于我们在监督和无监督学习中经常用作基准的数据集,例如 MNIST、Imagenet、MovieLens 和 Thomson Reuters News。
也可以看看
查看https://gym.openai.com/docs/上的官方 Gym 文档。
模拟 Atari 环境
要开始使用 Gym,让我们用它玩一些 Atari 游戏。
Atari 环境 ( https://gym.openai.com/envs/#atari ) 是各种Atari 2600视频游戏,例如 Alien、AirRaid、Pong 和 Space Race。如果您曾经玩过 Atari 游戏,这个食谱对您来说应该很有趣,因为您将玩 Atari 游戏 Space Invaders。但是,代理人将代表您行事。
怎么做...
让我们按照以下步骤模拟 Atari 环境:
1.atari要首次运行任何环境,我们需要atari通过在终端中运行此命令来安装依赖项:
pip install gym[atari]或者,如果您使用了上一节中的第二种方法,则install gym可以改为运行以下命令:
pip install -e '.[atari]'2.安装 Atari 依赖项后,我们gym在 Python 中导入库:
import gym3.创建SpaceInvaders环境实例:
env = gym.make('SpaceInvaders-v0')4.重置环境:
env.reset()array([[[ 0, 0, 0], [ 0, 0, 0], [ 0, 0, 0], ..., ..., [80, 89, 22], [80, 89, 22], [80, 89, 22]]], dtype=uint8)
如您所见,这也会返回环境的初始状态。
5.渲染环境:
env.render()True
你会看到弹出一个小窗口,如下:
正如您从游戏窗口中看到的那样,飞船开始时有 3 条生命(红色飞船)。
6.随机选择一个可能的动作并执行动作:
action = env.action_space.sample()
new_state, reward, is_done, info = env.step(action)该step()方法返回执行操作后发生的情况,包括以下内容:
- New state:新观察。
- Reward:与该状态下的该动作相关的奖励。
- Is done:表示游戏是否结束的标志。在一个SpaceInvaders环境中,True如果宇宙飞船没有生命或所有外星人都消失了;否则,它将保留False。
- Info:与环境有关的额外信息。这大约是在这种情况下剩下的生命数。这对于调试很有用。
让我们看一下is_done 标志和info:
print(is_done)False
print(info){'ale.lives': 3}
现在我们渲染环境:
env.render()True
游戏窗口变成如下:

您不会在游戏窗口中注意到太多差异,因为宇宙飞船刚刚移动。
7.现在,让我们做一个while循环,让代理执行尽可能多的操作:
is_done = False
while not is_done:action = env.action_space.sample()new_state, reward, is_done, info = env.step(action)print(info)env.render(){'ale.lives': 3}
True
{'ale.lives': 3}
True
……
……
{'ale.lives': 2}
True
{'ale.lives': 2}
True
……
……
{'ale.lives': 1}
True
{'ale.lives': 1}
True
同时,你会看到游戏在运行,飞船在不停地移动和射击,外星人也是如此。观看也很有趣。最后,当游戏结束时,窗口如下所示:

如您所见,我们在这场比赛中获得了150分。您可能会得到比这更高或更低的分数,因为代理执行的操作都是随机选择的。
我们还确认最后一条信息没有留下任何生命:
print(info){'ale.lives':0}
这个怎么运作...
make()使用 Gym,我们可以通过调用以环境名称作为参数的方法来轻松创建环境实例。
您可能已经注意到,代理执行的操作是使用该sample()方法随机选择的。
请注意,通常情况下,我们会有一个由强化学习算法引导的更复杂的代理。在这里,我们只是演示了如何模拟环境,以及代理如何采取行动而不考虑结果。
运行几次,看看我们得到了什么:
>>> env.action_space.sample()
0
>>> env.action_space.sample()
3
>>> env.action_space.sample()
0
>>> env.action_space.sample()
4
>>> env.action_space .sample()
2
>>> env.action_space.sample()
1
>>> env.action_space.sample()
4
>>> env.action_space.sample()
5
>>> env.action_space.sample()
1
> >> env.action_space.sample()
0总共有六个可能的动作。我们还可以通过运行以下命令来查看:
env.action_space
Discrete(6)
0到5的动作分别代表No Operation、Fire、Up、Right、Left、Down,这是游戏中飞船可以做的所有动作。
该step()方法将让代理执行指定为其参数的操作。该render()方法将根据对环境的最新观察更新显示窗口。
对环境的观察,new_state用一个 210 x 160 x 3 的矩阵表示,如下:
print(new_state.shape)(210, 160, 3)
这意味着显示屏的每一帧都是大小为 210 x 160 的 RGB 图像。
还有更多...
您可能想知道为什么我们需要安装 Atari 依赖项。事实上,还有一些环境没有安装gymBox2d、Classic control、MuJoCo 和 Robotics。
以Box2d环境为例;在我们第一次运行环境之前,我们需要安装Box2d依赖项。同样,两种安装方法如下:
pip install gym[box2d]
pip install -e '.[box2d]'之后,我们就可以玩转LunarLander环境了,如下:
env = gym.make('LunarLander-v2')
env.reset()array([-5.0468446e-04, 1.4135642e+00, -5.1140346e-02, 1.1751971e-01,
5.9164839e-04, 1.1584054e-02, 0.0000000e+00, 0.0000000e+00],
dtype=float32)
env.render()会弹出一个游戏窗口:
也可以看看
如果您正在寻找模拟环境但不确定您应该在该make()方法中使用的名称,您可以在环境表中找到它,网址为https://github.com/openai/gym/wiki/Table-of-环境。除了用于调用环境的名称外,该表还显示了观察矩阵的大小和可能的操作数。在环境中玩得开心。
模拟 CartPole 环境
在这个秘籍中,我们将努力模拟另一个环境,以便更熟悉 Gym。CartPole 环境是强化学习研究中的经典环境。
CartPole 是一项传统的强化学习任务,其中一根杆子直立放在手推车的顶部。代理在一个时间步内将手推车向左或向右移动 1 个单位。目标是平衡杆子并防止它倒下。如果杆与垂直方向的夹角超过 12 度,或者小车从原点移动 2.4 个单位,则认为杆已经倒下。当发生以下任何情况时,情节终止:
- 杆子倒了
- 时间步数达到200
怎么做...
CartPole让我们按照以下步骤来模拟环境:
1.要运行 CartPole 环境,我们首先在https://github.com/openai/gym/wiki/Table-of-environments, 的环境表中搜索它的名称。我们得到'CartPole-v0'并了解到观察空间以 4 维数组表示,并且有两种可能的操作(这是有道理的)。
2.我们导入 Gym 库并创建CartPole环境实例:
import gym
env = gym.make('CartPole-v0')3.重置环境:
env.reset()array([-0.00153354, 0.01961605, -0.03912845, -0.01850426])
如您所见,这也返回由四个浮点数组成的数组表示的初始状态。
4.渲染环境:
env.render()True
你会看到弹出一个小窗口,如下:

5.现在,让我们做一个while循环,让代理执行尽可能多的随机操作:
is_done = False
while not is_done:action = env.action_space.sample()new_state, reward, is_done, info = env.step(action)print(new_state)env.render()[-0.00114122 -0.17492355 -0.03949854 0.26158095]True[-0.00463969 -0.36946006 -0.03426692 0.54154857]True…………[-0.11973207 -0.41075106 0.19355244 1.11780626]True[-0.12794709 -0.21862176 0.21590856 0.89154351]True
同时,您会看到推车和杆子在移动。最后,你会看到他们都停了下来。窗口如下所示:
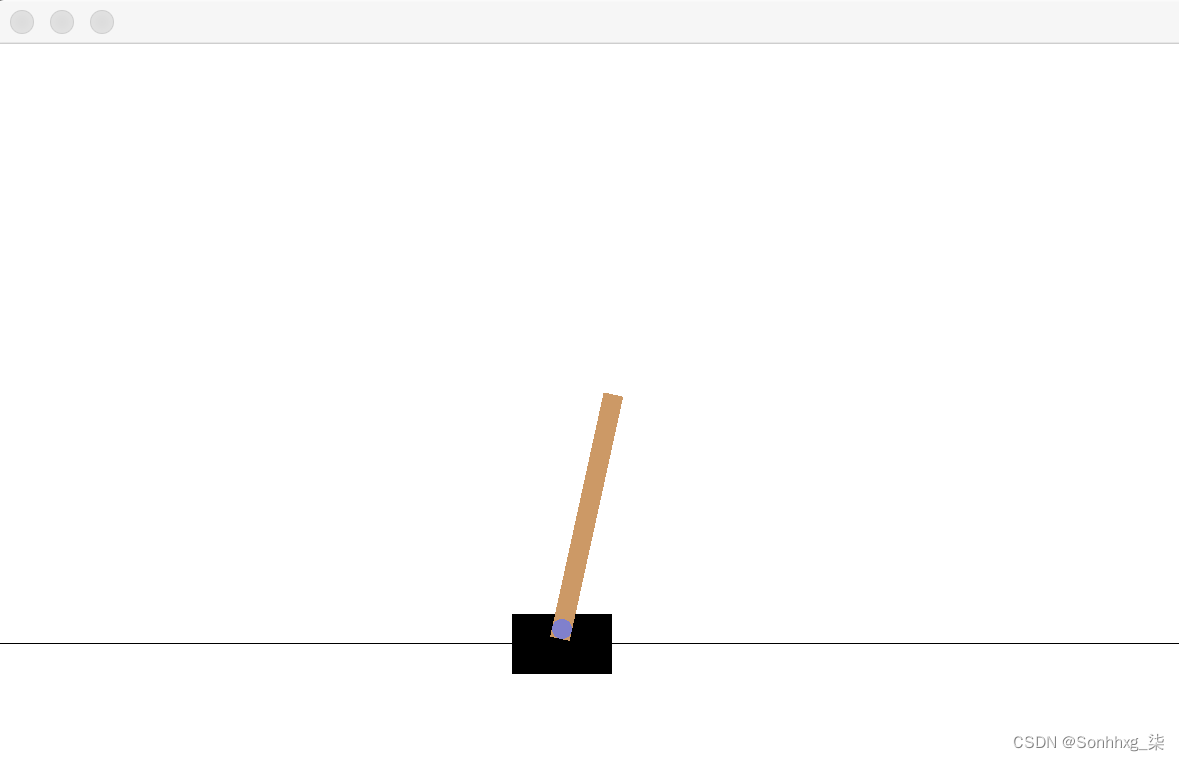
这一集只持续几个步骤,因为左边或右边的动作是随机选择的。我们可以把整个过程录下来以便以后重播吗?我们只需在 Gym 中使用两行代码即可完成此操作,如第 7 步所示。如果您使用的是 Mac 或 Linux 系统,则需要先完成第 6 步;否则,您可以跳转到第 7 步。
6.要录制视频,我们需要安装ffmpeg包。对于 Mac,可以通过以下命令安装:
brew install ffmpeg对于 Linux,应该执行以下命令:
sudo apt-get install ffmpeg7.创建CartPole实例后,添加这两行:
video_dir = './cartpole_video/'
env = gym.wrappers.Monitor(env, video_dir)这将记录窗口中显示的内容并将其存储在指定目录中。
现在重新运行第 3步到第 5步的代码。剧集结束后,我们可以看到.mp4文件夹中创建了一个video_dir文件。视频很短;它可能会持续 1 秒左右。
这个怎么运作...
在这个秘籍中,我们为每个步骤打印出状态数组。但是数组中的每个浮点数是什么意思呢?我们可以在 Gym 的 GitHub wiki 页面上找到有关 CartPole 的更多信息:https ://github.com/openai/gym/wiki/CartPole-v0 。事实证明,这四个浮点数代表以下内容:
- 购物车位置:范围从 -2.4 到 2.4,超出此范围的任何位置都会触发剧集终止。
- 推车速度。
- 极角:任何小于 -0.209(-12 度)或大于 0.209(12 度)的值都会触发剧集终止。
- 尖端的极速。
就动作而言,它要么是 0,要么是 1,分别对应于将小车推向左侧和右侧。
在该环境中,情节结束前的每个时间步的奖励都是 +1。我们还可以通过打印每一步的奖励来验证这一点。总奖励就是时间步数。
还有更多...
到目前为止,我们只播放了一集。为了评估代理的表现如何,我们可以模拟许多情节,然后对单个情节的总奖励进行平均。平均总奖励将告诉我们采取随机行动的代理人的表现。
让我们设置 10,000 集:
n_episode = 10000在每一集中,我们通过累积每一步的奖励来计算总奖励:
total_rewards = []
for episode in range(n_episode):state = env.reset()total_reward = 0is_done = Falsewhile not is_done:action = env.action_space.sample()state, reward, is_done, _ = env.step(action)total_reward += rewardtotal_rewards.append(total_reward)最后,我们计算平均总奖励:
print('Average total reward over {} episodes: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 10000 episodes: 22.2473
平均而言,采取随机行动得分为 22.25。
我们都知道采取随机行动还不够复杂,我们将在接下来的食谱中实施高级政策。但是对于下一个秘诀,让我们休息一下,回顾一下 PyTorch 的基础知识。
回顾 PyTorch 的基础知识
正如我们已经提到的,PyTorch 是我们在本书中用来实现强化学习算法的数值计算库。
PyTorch 是 Facebook 开发的一个新潮的科学计算和机器学习(包括深度学习)库。Tensor 是 PyTorch 中的核心数据结构,类似于 NumPy 的ndarrays. PyTorch 和 NumPy 在科学计算方面不相上下。但是,PyTorch 在数组运算和数组遍历方面比 NumPy 更快。这主要是因为 PyTorch 中数组元素的访问速度更快。因此,越来越多的人认为 PyTorch 将取代 NumPy。
怎么做...
让我们快速回顾一下 PyTorch 中的基本编程以更加熟悉它:
1.我们在之前的秘籍中创建了一个未初始化的矩阵。随机初始化的怎么样?请参阅以下命令:
import torch
x = torch.rand(3, 4)
print(x)tensor([[0.8052, 0.3370, 0.7676, 0.2442],[0.7073, 0.4468, 0.1277, 0.6842],[0.6688, 0.2107, 0.0527, 0.4391]])
生成区间 (0, 1) 中均匀分布的随机浮点数。
2.我们可以指定返回张量的所需数据类型。例如,double 类型 ( float64) 的张量返回如下:
x = torch.rand(3, 4, dtype=torch.double)
print(x)tensor([[0.6848, 0.3155, 0.8413, 0.5387],[0.9517, 0.1657, 0.6056, 0.5794],[0.0351, 0.3801, 0.7837, 0.4883]], dtype=torch.float64)
默认情况下,float是返回的数据类型。
3.接下来,让我们创建一个全为零的矩阵和一个全为 1 的矩阵:
x = torch.zeros(3, 4)
print(x)tensor([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])
x = torch.ones(3, 4)
print(x)tensor([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])
4.要获取张量的大小,请使用以下代码:
print(x.size())torch.Size([3, 4])
torch.Size实际上是一个元组。
5.要重塑张量,我们可以使用以下view()方法:
x_reshaped = x.view(2, 6)
print(x_reshaped)tensor([[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.]])
6.我们可以直接从数据创建张量,包括单值、列表和嵌套列表:
>>> x1 = torch.tensor(3)>>> print(x1)tensor(3)>>> x2 = torch.tensor([14.2, 3, 4])>>> print(x2)tensor([14.2000, 3.0000, 4.0000])>>> x3 = torch.tensor([[3, 4, 6], [2, 1.0, 5]])>>> print(x3)tensor([[3., 4., 6.],[2., 1., 5.]])7.要访问包含多个元素的张量中的元素,我们可以使用与 NumPy 类似的方式进行索引:
>>> print(x2[1])tensor(3.)>>> print(x3[1, 0])tensor(2.)>>> print(x3[:, 1])tensor([4., 1.])>>> print(x3[:, 1:])tensor([[4., 6.],[1., 5.]])与单元素张量一样,我们使用以下item()方法来实现:
>>> print(x1.item())38.Tensor 和 NumPy 数组可以相互转换。使用以下方法将张量转换为 NumPy 数组numpy():
>>> x3.numpy()array([[3., 4., 6.],[2., 1., 5.]], dtype=float32)将 NumPy 数组转换为张量from_numpy():
>>> import numpy as np
>>> x_np = np.ones(3)
>>> x_torch = torch.from_numpy(x_np)
>>> print(x_torch)
tensor([1., 1., 1.], dtype=torch.float64)看看下面的例子,其中一个双精度类型的张量被转换为一个float:
>>> print(x_torch.float())tensor([1., 1., 1.])9.PyTorch 中的操作也类似于 NumPy。以加法为例;我们可以简单地执行以下操作:
>>> x4 = torch.tensor([[1, 0, 0], [0, 1.0, 0]])
>>> print(x3 + x4)
tensor([[4., 4., 6.],[2., 2., 5.]])或者我们可以使用add()如下方法:
>>> print(torch.add(x3, x4))tensor([[4., 4., 6.],[2., 2., 5.]])10.PyTorch 支持就地操作,它会改变张量对象。例如,让我们运行这个命令:
>>> x3.add_(x4)tensor([[4., 4., 6.],[2., 2., 5.]])您会看到它x3已更改为原始x3plus的结果x4:
>>> print(x3)tensor([[4., 4., 6.],[2., 2., 5.]])还有更多...
任何带有_的方法 都表示它是一个就地操作,它用结果值更新张量。
也可以看看
有关 PyTorch 中张量运算的完整列表,请访问torch — PyTorch 1.13 documentation上的官方文档。如果您遇到 PyTorch 编程问题,这是搜索信息的最佳位置。
实施和评估随机搜索策略
在使用 PyTorch 编程进行一些练习后,从本秘籍开始,我们将研究比纯随机动作更复杂的策略来解决 CartPole 问题。我们从这个秘籍中的随机搜索策略开始。
一种简单而有效的方法是将观察映射到表示两个动作的两个数字的向量。将选择具有较高价值的行动。线性映射由大小为 4 x 2 的权重矩阵描述,因为在这种情况下观测值是 4 维的。在每一集中,权重是随机生成的,用于计算这一集中每一步的动作。然后计算总奖励。这个过程会重复很多次,最后,能够获得最高总奖励的权重将成为学习策略。这种方法称为随机搜索,因为权重是在每次试验中随机选取的,希望通过大量试验找到最佳权重。
怎么做...
让我们继续使用 PyTorch 实现随机搜索算法:
1.导入 Gym 和 PyTorch 包并创建环境实例:
>>> import gym
>>> import torch
>>> env = gym.make('CartPole-v0')2.获取观察和动作空间的维度:
>>> n_state = env.observation_space.shape[0]
>>> n_state4
>>> n_action = env.action_space.n
>>> n_action2这些将在我们为权重矩阵定义张量时使用,权重矩阵的大小为 4 x 2。
3.定义一个函数,在给定输入权重的情况下模拟情节并返回总奖励:
>>> def run_episode(env, weight):... state = env.reset()... total_reward = 0... is_done = False... while not is_done:... state = torch.from_numpy(state).float()... action = torch.argmax(torch.matmul(state, weight))... state, reward, is_done, _ = env.step(action.item())... total_reward += reward... return total_reward在这里,我们将状态数组转换为 float 类型的张量,因为我们需要计算状态和权重张量的乘积torch.matmul(state, weight),用于线性映射。使用该操作选择具有较高值的torch.argmax()操作。并且不要忘记使用生成的动作张量的值,.item()因为它是一个单元素张量。
3.指定剧集数:
>>> n_episode = 10004.我们需要实时跟踪最佳总奖励以及相应的权重。因此,我们指定它们的起始值:
>>> best_total_reward = 0
>>> best_weight = None我们还会记录每一集的总奖励:
>>> total_rewards = []5.现在,我们可以运行了n_episode。对于每一集,我们执行以下操作:
- 随机选择权重
- 让agent根据线性映射采取行动
- 一个情节终止并返回总奖励
- 必要时更新最佳总奖励和最佳权重
- 另外,记录总奖励
将其放入代码如下:
>>> for episode in range(n_episode):... weight = torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... print('Episode {}: {}'.format(episode+1, total_reward))... if total_reward > best_total_reward:... best_weight = weight... best_total_reward = total_reward... total_rewards.append(total_reward)...Episode 1: 10.0Episode 2: 73.0Episode 3: 86.0Episode 4: 10.0Episode 5: 11.0…………Episode 996: 200.0Episode 997: 11.0Episode 998: 200.0Episode 999: 200.0Episode 1000: 9.0我们通过 1,000 次随机搜索获得了最佳策略。最佳策略由 参数化best_weight。
7.在我们测试出测试集中的最佳策略之前,我们可以计算随机线性映射实现的平均总奖励:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 47.197这是我们从随机操作策略 (22.25) 中得到的两倍多。
8.现在,让我们看看学习到的策略如何在 100 个新剧集中执行:
>>> n_episode_eval = 100>>> total_rewards_eval = []>>> for episode in range(n_episode_eval):... total_reward = run_episode(env, best_weight)... print('Episode {}: {}'.format(episode+1, total_reward))... total_rewards_eval.append(total_reward)...Episode 1: 200.0Episode 2: 200.0Episode 3: 200.0Episode 4: 200.0Episode 5: 200.0…………Episode 96: 200.0Episode 97: 188.0Episode 98: 200.0Episode 99: 200.0Episode 100: 200.0>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards_eval) / n_episode_eval))Average total reward over 1000 episode: 196.72令人惊讶的是,测试集的平均奖励接近学习策略的最大 200 步。请注意,此值可能会有很大差异。它可以在 160 到 200 之间的任何地方。
这个怎么运作...
随机搜索算法运行良好主要是因为我们的 CartPole 环境非常简单。它的观察状态仅由四个变量组成。你会记得 Atari Space Invaders 游戏中的观察值超过 100,000(即 210 * 160 * 3)。CartPole 中动作状态的维数是 Space Invaders 的三分之一。一般来说,简单的算法适用于简单的问题。在我们的例子中,我们只是从随机池中搜索从观察到动作的最佳线性映射。
我们注意到的另一件有趣的事情是,在我们选择和部署最佳策略(最佳线性映射)之前,随机搜索也优于随机动作。这是因为随机线性映射确实考虑了观察结果。随着来自环境的更多信息,随机搜索策略做出的决策比完全随机的决策更智能。
还有更多...
我们还可以绘制训练阶段每一集的总奖励:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_rewards)
>>> plt.xlabel('Episode')
>>> plt.ylabel('Reward')
>>> plt.show()这将生成以下图:
如果您尚未安装 matplotlib,则可以通过以下命令进行安装:
conda install matplotlib我们可以看到每一集的奖励都是随机的,并且在我们经历每一集的过程中没有改善的趋势。这基本上是我们所期望的。
在 reward vs episode 图中,我们可以看到有一些 episode 的 reward 达到了 200。只要出现这种情况,我们就可以结束训练阶段,因为没有改进的余地。结合这一变化,我们现在在训练阶段有以下内容:
>>> n_episode = 1000>>> best_total_reward = 0>>> best_weight = None>>> total_rewards = []>>> for episode in range(n_episode):... weight = torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... print('Episode {}: {}'.format(episode+1, total_reward))... if total_reward > best_total_reward:... best_weight = weight... best_total_reward = total_reward... total_rewards.append(total_reward)... if best_total_reward == 200:... breakEpisode 1: 9.0Episode 2: 8.0Episode 3: 10.0Episode 4: 10.0Episode 5: 10.0Episode 6: 9.0Episode 7: 17.0Episode 8: 10.0Episode 9: 43.0Episode 10: 10.0Episode 11: 10.0Episode 12: 106.0Episode 13: 8.0Episode 14: 32.0Episode 15: 98.0Episode 16: 10.0Episode 17: 200.0实现最大奖励的策略在第 17 集中找到。同样,这可能会有很大差异,因为权重是为每一集随机生成的。为了计算所需训练集的期望,我们可以重复前面的训练过程 1,000 次并取训练集的平均值:
>>> n_training = 1000>>> n_episode_training = []>>> for _ in range(n_training):... for episode in range(n_episode):... weight = torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... if total_reward == 200:... n_episode_training.append(episode+1)... break>>> print('Expectation of training episodes needed: ',sum(n_episode_training) / n_training)Expectation of training episodes needed: 13.442平均而言,我们预计需要大约 13 集才能找到最佳策略。
开发爬山算法
正如我们在随机搜索策略中看到的,每一集都是独立的。实际上,随机搜索中的所有episode都可以并行运行,最终会选出性能最好的权重。我们还通过奖励与情节的关系图验证了这一点,其中没有上升趋势。在这个秘籍中,我们将开发一种不同的算法,一种爬山算法,将在一集中获得的知识转移到下一集中。
在爬山算法中,我们也从随机选择的权重开始。但是在这里,对于每一集,我们都会在权重上添加一些噪音。如果总奖励提高,我们用新的更新权重;否则,我们保持旧的重量。在这种方法中,随着情节的进展,权重会逐渐提高,而不是在每一集中跳来跳去。
怎么做...
让我们继续使用 PyTorch 实现爬山算法:
1.和以前一样,导入必要的包,创建环境实例,并获取观察和动作空间的维度:
>>> import gym
>>> import torch
>>> env = gym.make('CartPole-v0')
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n2.我们会复用上一run_episode节中定义的函数,这里不再赘述。同样,给定输入权重,它模拟一个情节并返回总奖励。
3.现在让我们制作 1,000 集:
>>> n_episode = 10004.我们需要实时跟踪最佳总奖励以及相应的权重。因此,让我们指定它们的起始值:
>>> best_total_reward = 0
>>> best_weight = torch.rand(n_state, n_action)我们还会记录每一集的总奖励:
>>> total_rewards = []5.正如我们所提到的,我们将为每一集的权重添加一些噪声。事实上,我们将对噪音应用一个比例,这样噪音就不会压倒权重。在这里,我们将选择 0.01 作为噪声标度:
>>> noise_scale = 0.016.现在,我们可以运行这个n_episode函数了。在我们随机选择初始权重后,对于每一集,我们执行以下操作:
- 为权重添加随机噪声
- 让agent根据线性映射采取行动
- 一个情节终止并返回总奖励
- 如果当前奖励大于目前为止获得的最佳奖励,则更新最佳奖励和权重
- 否则,最佳奖励和权重保持不变
- 另外,记录总奖励
将其放入代码如下:
>>> for episode in range(n_episode):... weight = best_weight +noise_scale * torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... if total_reward >= best_total_reward:... best_total_reward = total_reward... best_weight = weight... total_rewards.append(total_reward)... print('Episode {}: {}'.format(episode + 1, total_reward))...Episode 1: 56.0Episode 2: 52.0Episode 3: 85.0Episode 4: 106.0Episode 5: 41.0…………Episode 996: 39.0Episode 997: 51.0Episode 998: 49.0Episode 999: 54.0Episode 1000: 41.0我们还计算了线性映射的爬山版本获得的平均总奖励:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 50.0247.为了评估使用爬山算法的训练,我们多次重复训练过程(通过多次运行第 4步到第 6步的代码)。我们观察到平均总奖励波动很大。以下是我们运行 10 次后得到的结果:
Average total reward over 1000 episode: 9.261
Average total reward over 1000 episode: 88.565
Average total reward over 1000 episode: 51.796
Average total reward over 1000 episode: 9.41
Average total reward over 1000 episode: 109.758
Average total reward over 1000 episode: 55.787
Average total reward over 1000 episode: 189.251
Average total reward over 1000 episode: 177.624
Average total reward over 1000 episode: 9.146
Average total reward over 1000 episode: 102.311什么会导致这种差异?事实证明,如果初始权重不好,在小范围内添加噪声对提高性能影响不大。这将导致收敛性差。另一方面,如果初始权重很好,则大规模添加噪声可能会使权重偏离最佳权重并危及性能。如何让爬山模型的训练更加稳定可靠呢?我们实际上可以让噪声尺度自适应性能,就像梯度下降中的自适应学习率一样。让我们查看步骤 8了解更多详细信息。
8.为了使噪声具有自适应性,我们执行以下操作:
- 指定起始噪声标度。
- 如果情节中的表现有所改善,请降低噪声等级。在我们的例子中,我们取比例的一半,但设置0.0001为下限。
- 如果情节中的表现下降,请增加噪声标度。在我们的例子中,我们将比例加倍,但设置2为上限。
将其放入代码中:
>>> noise_scale = 0.01>>> best_total_reward = 0>>> total_rewards = []>>> for episode in range(n_episode):... weight = best_weight +noise_scale * torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... if total_reward >= best_total_reward:... best_total_reward = total_reward... best_weight = weight... noise_scale = max(noise_scale / 2, 1e-4)... else:... noise_scale = min(noise_scale * 2, 2)... print('Episode {}: {}'.format(episode + 1, total_reward))... total_rewards.append(total_reward)...Episode 1: 9.0Episode 2: 9.0Episode 3: 9.0Episode 4: 10.0Episode 5: 10.0…………Episode 996: 200.0Episode 997: 200.0Episode 998: 200.0Episode 999: 200.0Episode 1000: 200.0随着情节的进展,奖励会增加。它在前 100 集中达到最大值 200 并保持在那里。平均总奖励也看起来很有希望:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 186.11我们还绘制了每一集的总奖励,如下所示:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_rewards)
>>> plt.xlabel('Episode')
>>> plt.ylabel('Reward')
>>> plt.show()在结果图中,我们可以看到一个明显的上升趋势,然后在最大值处稳定下来:
9.随意运行几次新的训练过程。与使用恒定噪声标度学习相比,结果非常稳定。
现在,让我们看看学习到的策略如何在 100 个新剧集中执行:
>>> n_episode_eval = 100>>> total_rewards_eval = []>>> for episode in range(n_episode_eval):... total_reward = run_episode(env, best_weight)... print('Episode {}: {}'.format(episode+1, total_reward))... total_rewards_eval.append(total_reward)...Episode 1: 200.0Episode 2: 200.0Episode 3: 200.0Episode 4: 200.0Episode 5: 200.0…………Episode 96: 200.0Episode 97: 200.0Episode 98: 200.0Episode 99: 200.0Episode 100: 200.0让我们看看平均表现:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 199.94测试情节的平均奖励接近我们通过学习策略获得的最大值 200。您可以多次重新运行评估。结果非常一致。
还有更多...
我们可以观察到奖励可以在前 100 集中达到最大值。当奖励达到 200 时,我们可以停止训练吗,就像我们对随机搜索策略所做的那样?这可能不是一个好主意。请记住,智能体在爬山方面不断改进。即使它找到了一个产生最大奖励的权重,它仍然可以围绕这个权重搜索最优点。在这里,我们将最优策略定义为可以解决 CartPole 问题的策略。根据以下 wiki 页面CartPole v0 · openai/gym Wiki · GitHub,“已解决”意味着连续 100 集的平均奖励不少于 195。
我们相应地细化停止标准:
>>> noise_scale = 0.01>>> best_total_reward = 0>>> total_rewards = []>>> for episode in range(n_episode):... weight = best_weight + noise_scale * torch.rand(n_state, n_action)... total_reward = run_episode(env, weight)... if total_reward >= best_total_reward:... best_total_reward = total_reward... best_weight = weight... noise_scale = max(noise_scale / 2, 1e-4)... else:... noise_scale = min(noise_scale * 2, 2)... print('Episode {}: {}'.format(episode + 1, total_reward))... total_rewards.append(total_reward)... if episode >= 99 and sum(total_rewards[-100:]) >= 19500:... break...Episode 1: 9.0Episode 2: 9.0Episode 3: 10.0Episode 4: 10.0Episode 5: 9.0…………Episode 133: 200.0Episode 134: 200.0Episode 135: 200.0Episode 136: 200.0在第 137 集,问题被认为已经解决。
也可以看看
如果您有兴趣了解有关爬山算法的更多信息,以下资源很有用:
- https://en.wikipedia.org/wiki/Hill_climbing
- Introduction to Hill Climbing | Artificial Intelligence - GeeksforGeeks
开发策略梯度算法
第一章的最后一个食谱是关于用策略梯度算法解决 CartPole 环境的。对于这个简单的问题,这可能比我们需要的更复杂,其中随机搜索和爬山算法就足够了。然而,这是一个很好学习的算法,我们将在本书后面的更复杂的环境中使用它。
在策略梯度算法中,模型权重在每一集结束时沿着梯度的方向移动。我们将在下一节中解释梯度的计算。此外,在每个步骤中,它都会根据使用状态和权重计算的概率从策略中采样一个动作。与随机搜索和爬山(通过采取行动获得更高分数)相比,它不再采取确定性的行动。因此,政策从确定性转变为随机性。
怎么做...
现在,是时候用 PyTorch 实现策略梯度算法了:
1.和以前一样,导入必要的包,创建环境实例,并获取观察和动作空间的维度:
>>> import gym
>>> import torch
>>> env = gym.make('CartPole-v0')
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n2.我们定义run_episode函数,它模拟给定输入权重的情节并返回总奖励和计算的梯度。更具体地说,它在每个步骤中执行以下任务:
- probs根据当前状态和输入权重计算两个动作的概率
- action根据结果概率采样一个动作,
- 以概率作为输入计算函数的导d_softmax数softmax
- 将生成的导数d_softmax除以概率 probs,得到对d_log数项关于策略的导数
- 应用链式法则计算grad权重的梯度 ,
- 记录产生的梯度,grad
- 执行动作,累积奖励,并更新状态
将所有这些放入代码中,我们有以下内容:
>>> def run_episode(env, weight):... state = env.reset()... grads = []... total_reward = 0... is_done = False... while not is_done:... state = torch.from_numpy(state).float()... z = torch.matmul(state, weight)... probs = torch.nn.Softmax()(z)... action = int(torch.bernoulli(probs[1]).item())... d_softmax = torch.diag(probs) -probs.view(-1, 1) * probs... d_log = d_softmax[action] / probs[action]... grad = state.view(-1, 1) * d_log... grads.append(grad)... state, reward, is_done, _ = env.step(action)... total_reward += reward... if is_done:... break... return total_reward, grads在一个 episode 结束后,它返回在这个 episode 中获得的总奖励和为各个步骤计算的梯度。这两个输出将用于更新权重。
3.现在让我们制作 1,000 集:
>>> n_episode = 1000这意味着我们将运行run_episode和n_episode时间。
4.启动权重:
>>> weight = torch.rand(n_state, n_action)我们还会记录每一集的总奖励:
>>> total_rewards = []5.在每一集结束时,我们需要使用计算出的梯度来更新权重。对于情节的每一步,权重移动的幅度为学习率 *此步骤中计算的梯度* 其余步骤中的总奖励。在这里,我们选择0.001作为学习率:
>>> learning_rate = 0.001现在,我们可以运行n_episode剧集:
>>> for episode in range(n_episode):... total_reward, gradients = run_episode(env, weight)... print('Episode {}: {}'.format(episode + 1, total_reward))... for i, gradient in enumerate(gradients):... weight += learning_rate * gradient * (total_reward - i)... total_rewards.append(total_reward)…………Episode 101: 200.0Episode 102: 200.0Episode 103: 200.0Episode 104: 190.0Episode 105: 133.0…………Episode 996: 200.0Episode 997: 200.0Episode 998: 200.0Episode 999: 200.0Episode 1000: 200.06.现在,我们计算策略梯度算法实现的平均总奖励:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 179.7287.我们还绘制了每一集的总奖励,如下所示:
>>> import matplotlib.pyplot as plt>>> plt.plot(total_rewards)>>> plt.xlabel('Episode')>>> plt.ylabel('Reward')>>> plt.show()在结果图中,我们可以看到在保持最大值之前有明显的上升趋势:
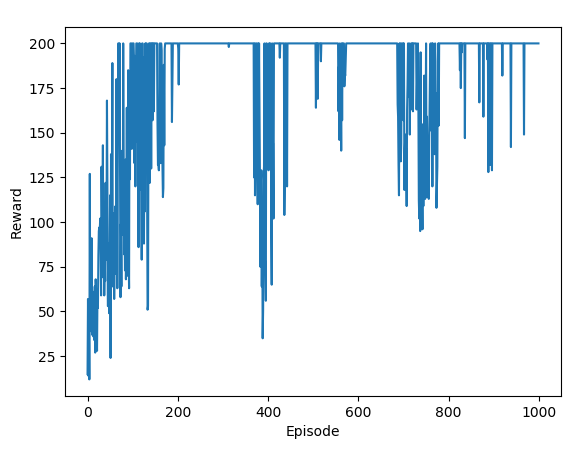
我们还可以看到,即使在收敛之后,奖励也会振荡。这是因为策略梯度算法是一种随机策略。
8.现在,让我们看看学习到的策略如何在 100 个新剧集中执行:
>>> n_episode_eval = 100>>> total_rewards_eval = []>>> for episode in range(n_episode_eval):... total_reward, _ = run_episode(env, weight)... print('Episode {}: {}'.format(episode+1, total_reward))... total_rewards_eval.append(total_reward)...Episode 1: 200.0Episode 2: 200.0Episode 3: 200.0Episode 4: 200.0Episode 5: 200.0…………Episode 96: 200.0Episode 97: 200.0Episode 98: 200.0Episode 99: 200.0Episode 100: 200.0让我们看看平均表现:
>>> print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))Average total reward over 1000 episode: 199.78测试集的平均奖励接近学习策略的最大值 200。您可以多次重新运行评估。结果非常一致。
这个怎么运作...
策略梯度算法通过采取小步骤并根据与情节结束时与这些步骤相关的奖励更新权重来训练代理。让代理运行整个事件然后根据获得的奖励更新策略的技术称为蒙特卡罗策略梯度。
根据基于当前状态和模型权重计算的概率分布来选择动作。例如,如果左动作和右动作的概率是 [0.6, 0.4],这意味着有 60% 的时间选择了左动作;这并不意味着选择了左边的动作,就像在随机搜索和爬山算法中那样。
我们知道在 episode 结束之前,每一步的奖励都是 1。因此,我们用来计算每一步策略梯度的未来奖励是剩余的步数。在每一集之后,我们将梯度历史乘以未来奖励,以使用随机梯度上升法更新权重。这样一个episode越长,权重的更新越大。这最终会增加获得更大总奖励的机会。
正如我们在本节开头提到的,策略梯度算法对于像 CartPole 这样的简单环境来说可能有点矫枉过正,但它应该让我们为更复杂的问题做好准备。
还有更多...
如果我们检查奖励/情节图,似乎我们也可以在解决问题后在训练期间提前停止——连续 100 集的平均奖励不低于 195。我们只需将以下代码行添加到训练会话中:
>>> if episode >= 99 and sum(total_rewards[-100:]) >= 19500:... break重新运行培训课程。你应该得到类似下面的东西,它在几百集后停止:
Episode 1: 10.0
Episode 2: 27.0
Episode 3: 28.0
Episode 4: 15.0
Episode 5: 12.0
……
……
Episode 549: 200.0
Episode 550: 200.0
Episode 551: 200.0
Episode 552: 200.0
Episode 553: 200.0也可以看看
查看Policy gradient methods - Scholarpedia了解有关策略梯度方法的更多信息。