selenium概述
一个自动化测试工具。它可以让python代码调用浏览器。并获取到浏览器中加载的各种资源
优缺点:
- 优点
- selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易
- 使用难度简单
- 爬取速度慢,爬取频率更像人的行为,天生能够应对一些反爬措施
- 缺点
- 由于selenium操作浏览器,因此会将发送所有的请求,因此占用网络带宽
- 由于操作浏览器,因此占用的内存非常大
- 速度慢,对于效率要求高的话不建议使用
selenium安装
python终端安装selenium
pip install selenium
推荐使用谷歌浏览器,本文以谷歌浏览器为例
1、查看浏览器的版本号
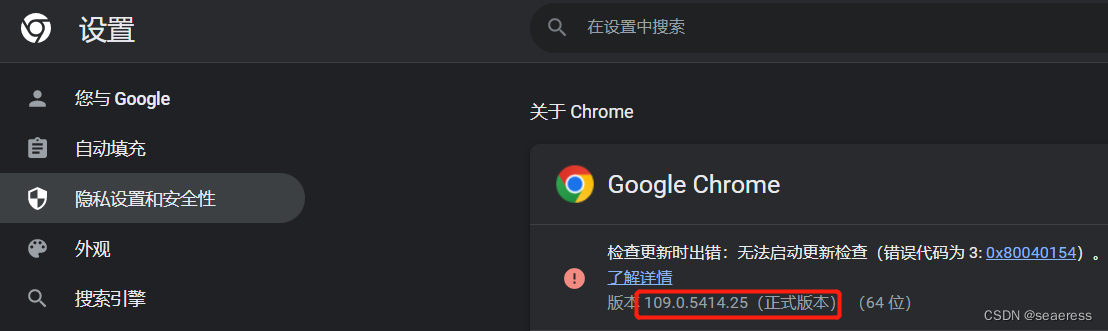
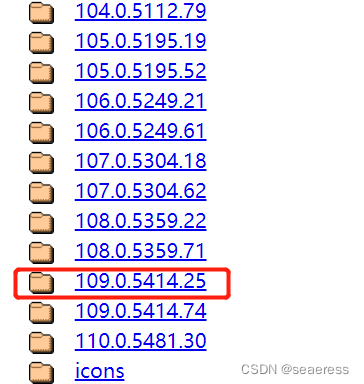
2、下载浏览器对应版本的驱动
chrome驱动地址下载
找到对应的版本号(前三段数字相同即可),下载
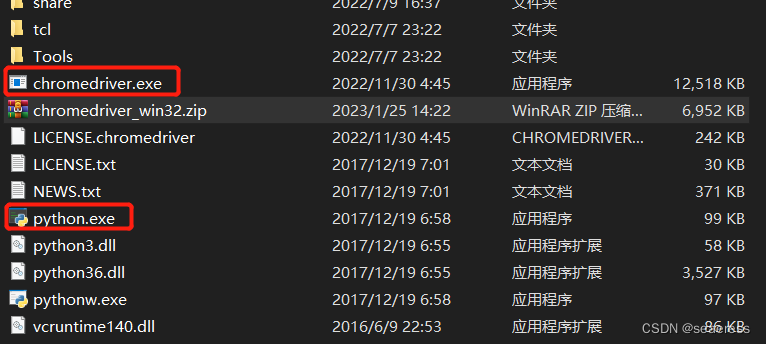
3、驱动配置
将压缩包解压,建议放入与python解释器同一目录(此方式无需配置环境变量)
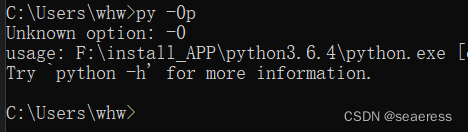
如何查看python解释器位置?
win下输入 py -0p查看(其余操作系统方式请自行查找查看方式)
selenium的基本使用
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.baidu.com/") # 访问百度网(会弹出百度网页)
driver.save_screenshot("baidu.png") # 截图
print(driver.page_source) # 打印源码
print(driver.get_cookies()) # 打印cookies
print(driver.current_url) # 打印当前urldriver.close() # 退出当前页面
driver.quit() # 退出浏览器
cookie的使用
import time
from selenium.webdriver import Chrome
import json# 登录操作 ...#获取cookie
cookies = driver.get_cookies()
json_cookies = json.dumps(cookies) # 使用json进行处理
with open('gsw_cookies.txt', 'w') as f:f.write(json_cookies)with open('gsw_cookies.txt', 'r') as f:cookies = json.loads(f.read()) # 读取所有cookies 转换为列表的cookiefor cookie in cookies:cookie_dict = {}for k,v in cookie.items():cookie_dict[k] = vdriver.add_cookie(cookie_dict) # 设置cookie# 刷新 使我们的cookie生效
driver.refresh() # 此刻重新访
driver.get('https://xxx')
获取懒加载网页的源代码
import random
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydef scroll_windwo(driver, stop_lengt=None, step_length=2000):'''使窗口不断向下滚动:param driver::param stop_lengt::param step_length::return:'''while True:if stop_lengt:if stop_lengt - step_length <= 0:# 使用js实现滚动条自动往下走driver.execute_script(f'window.scrollBy(0, {stop_lengt})')breakprint(stop_lengt)# 使用js实现滚动条自动往下走driver.execute_script(f'window.scrollBy(0, {step_length})')stop_lengt -= step_length # 每次减去滚动的距离time.sleep(0.1)driver = Chrome()
driver.get('https://xxx.com/')
step_length = 2000 # 每次向下滚动的步长
stop_lengt = 30000 # 向下滚动到当前整个值得时候就不滚了
for i in range(1, 6):scroll_windwo(driver, stop_lengt, step_length) # 先滚一些 把异步的分页加载先加载文 直到出现加载更多按钮more = driver.find_element(By.XPATH, '//*[@id="index2016_wrap"]/div[2]/div[2]/div[3]/div[2]/div[5]/div/a[3]')# more.click()# 无法使用more.click 原因上面有我们看不到的覆盖物 点击会报错driver.execute_script('arguments[0].click();', more)print(f'第{i}次点击')print(driver.page_source) # 获取页面最终源代码
selenium的定位操作
1、元素定位的两种方式
- 精确定位一个元素,返回结果为一个element对象,定位不到则报错
driver.find_element(By.xx, value) # 建议使用driver.find_element_by_xxx(value)
- 定位一组元素,返回结果为element对象列表,定位不到返回空列表
driver.find_elements(By.xx, value) # 建议使用driver.find_elements_by_xxx(value)
2、元素定位的八种方法
- By.ID 使用id值定位
el = driver.find_element(By.ID, '')el = driver.find_element_by_id()
- By.XPATH 使用xpath定位
el = driver.find_element(By.XPATH, '')el = driver.find_element_by_xpath()
- By.TAG_NAME. 使用标签名定位
el = driver.find_element(By.TAG_NAME, '')el = driver.find_element_by_tag_name()
- By.LINK_TEXT使用超链接文本定位
el = driver.find_element(By.LINK_TEXT, '')el = driver.find_element_by_link_text()
- By.PARTIAL_LINK_TEXT 使用部分超链接文本定位
el = driver.find_element(By.PARTIAL_LINK_TEXT , '')el = driver.find_element_by_partial_link_text()
- By.NAME 使用name属性值定位
el = driver.find_element(By.NAME, '')el = driver.find_element_by_name()
- By.CLASS_NAME 使用class属性值定位
el = driver.find_element(By.CLASS_NAME, '') el = driver.find_element_by_class_name()
- By.CSS_SELECTOR 使用css选择器定位
el = driver.find_element(By.CSS_SELECTOR, '') el = driver.find_element_by_css_selector()
3、元素的操作
- 从定位到的元素中获取数据
el.get_attribute(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容
- 对定位到的元素的操作
el.click() # 对元素执行点击操作el.submit() # 对元素执行提交操作el.clear() # 清空可输入元素中的数据el.send_keys(data) # 向可输入元素输入数据
4、使用案例
import timefrom selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydriver = Chrome() # 实例化
driver.get('https://www.gushiwen.cn/') # 访问古诗文网站# 使用id查找节点
# txtKey = driver.find_element(By.ID, 'txtKey')
# print(txtKey) #<selenium.webdriver.remote.webelement.WebElement (session="953d50dc821197e9bd2ce97a7ab66045", element="9f422884-c998-45f2-8274-3414bd3c50db")>
# time.sleep(1)
# 向搜索框中输入数据
# txtKey.send_keys('唐诗')
# 点击搜索
# submit = driver.find_element(By.XPATH, '/html/body/div[1]/div/div[2]/div[2]/div[1]/form/input[3]')
# submit.click() # 点击搜索按钮# 使用xpath
# txtKey = driver.find_element(By.XPATH, '//*[@id="txtKey"]')
# txtKey.send_keys('唐诗')
# 点击搜索
# submit = driver.find_element(By.XPATH, '/html/body/div[1]/div/div[2]/div[2]/div[1]/form/input[3]')
# submit.click() # 点击搜索按钮# 匹配所有超链接
# a_list = driver.find_elements(By.TAG_NAME, 'a')
# a_list = driver.find_elements_by_tag_name('a') # 老版本的写法 作为了解
# print(a_list)
# for a in a_list:# 获取href属性# print(a.get_attribute('href'))# 通过超链接的内容进行节点获取
# res = driver.find_elements(By.LINK_TEXT, '唐诗三百')
# print(res)# 通过class进行查找 只要是是cont值 就都会返回
# res = driver.find_elements(By.CLASS_NAME, 'cont')
# print(res)# print(driver.page_source) # 获取页面源代码
selenium的其他操作
1、无头浏览器
无头即不显示网页
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") # 设置窗口大小web = Chrome(options=opt)
web.get('https://news.163.com/')
print(web.page_source)
2、switch方法切换的操作
2.1 一个浏览器肯定会有很多窗口,切换窗口的方法如下:
# 可以使用 window_handles 方法来获取每个窗口的操作对象。例如:
# 1. 获取当前所有的窗口
current_windows = driver.window_handles# 2. 根据窗口索引进行切换
driver.switch_to.window(current_windows[1])driver.switch_to.window(web.window_handles[-1]) # 跳转到最后一个窗口
driver.switch_to.window(current_windows[0]) # 回到第一个窗口
2.2 iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是
driver.switch_to.frame(name/el/id)
# 传入的参数可以使iframe对应的id值,也可以是用元素定位之后的元素对象
2.3 当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
2.4. 页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
2.5、设置浏览器最大窗口
driver.maximize_window() # 最大化浏览器窗口


![[数据结构基础]排序算法第一弹 -- 直接插入排序和希尔排序](https://img-blog.csdnimg.cn/5b9c5b2825d646fbaf8eb464fa599050.png)


