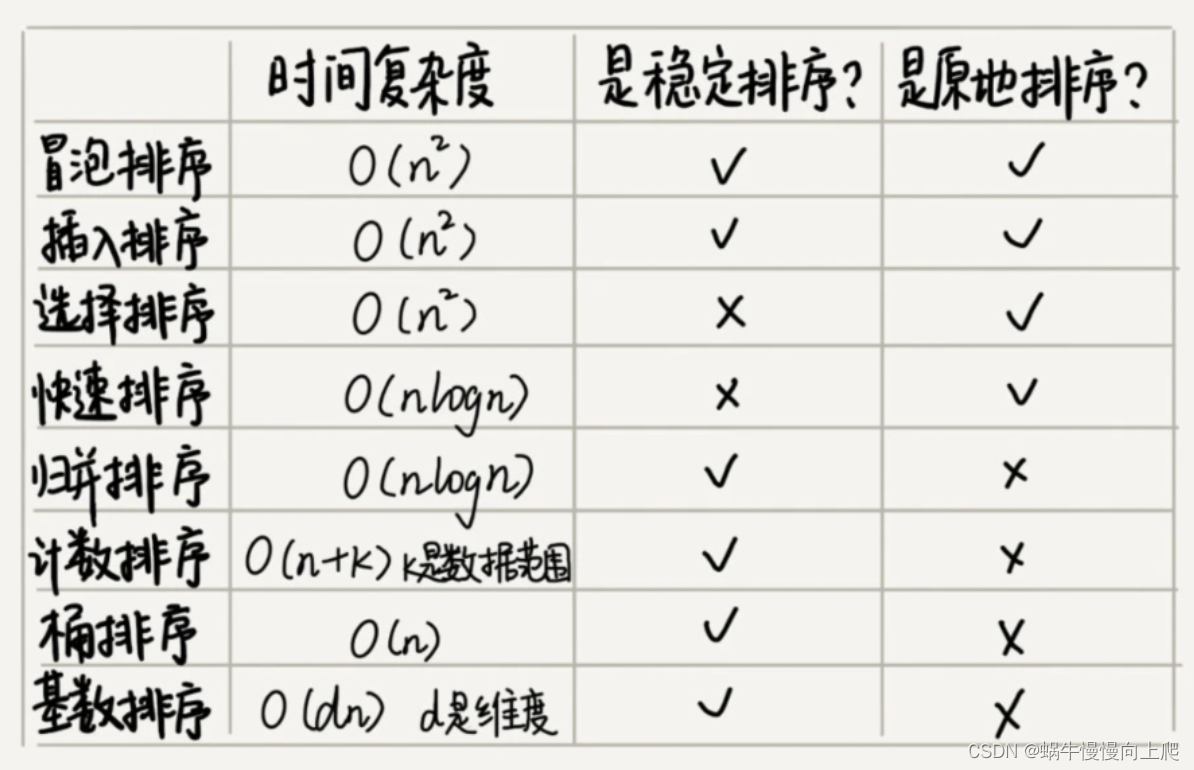
冒泡排序
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
插入排序
首先,我们将数组中的数据分为2个区间,即已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想就是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间中的元素一直有序。重复这个过程,直到未排序中元素为空,算法结束。
选择排序
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。
快速排序是冒泡排序的升级版
数列中挑出一个元素,称为 "基准"(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
递归排序
先把数组从中间分成前后两部分,然后对前后两部分分别进行排序,再将排序好的两部分合并到一起,这样整个数组就有序了。这就是归并排序的核心思想。
桶排序
1.算法原理:
1)将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行快速排序。
2)桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。
计数排序(Counting sort)
1.算法原理
1)计数其实就是桶排序的一种特殊情况。
2)当要排序的n个数据所处范围并不大时,比如最大值为k,则分成k个桶
3)每个桶内的数据值都是相同的,就省掉了桶内排序的时间。
基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。