一、概念
1. 什么是线程安全
当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象是线程安全的。
通俗来说就是:不管业务中遇到怎么的多个线程访问某个对象或某个方法的情况,而在编写这个业务逻辑的时候,都不需要额外做任何额外的处理(也就是可以像单线程编程一样),程序也可以正常运行(不会因为多线程而出错),就可以称为线程安全。
2. 什么是线程不安全:
多个线程同时做一个操作时,如使用 set 设置一个对象的值时,如果同时有另一个线程使用 get 方法取该对象的值,就有可能取到不正确的值,这种情况就需要我们进行额外的操作保证结果正确,如Synchronized关键词修饰做同步
3. 那为什么不全部设计为线程安全:
主要考虑到运行速度、设计成本等因素。
二、出现线程安全的案例
什么情况下会出现线程安全问题,怎么避免?
- 运行
结果错误:a++多线程下出现消失的请求现象。 - 线程的
活跃性问题:死锁、活锁、饥饿 - 对象
发布和初始化的时候的安全问题
1. a++ 在多线程下出现的数据运算出错
代码演示:
public class MultiThreadsError implements Runnable {static MultiThreadsError multiThreadsError = new MultiThreadsError();int index = 0;public static void main(String[] args) throws InterruptedException {Thread thread1 = new Thread(multiThreadsError);Thread thread2 = new Thread(multiThreadsError);thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(multiThreadsError.index);}@Overridepublic void run() {for (int i = 0; i < 10000; i++) {index++;}}
}
结果如下:
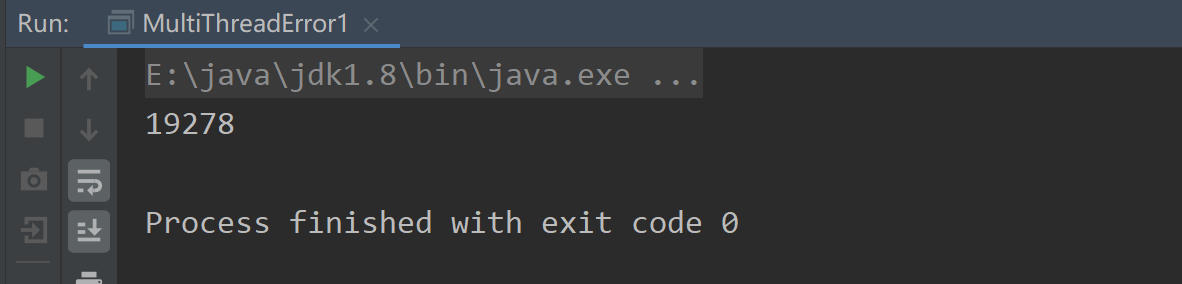
两个线换各执行 10000 次 +1,结果却不是20000,运行过程中出现了什么问题呢?分析如下:
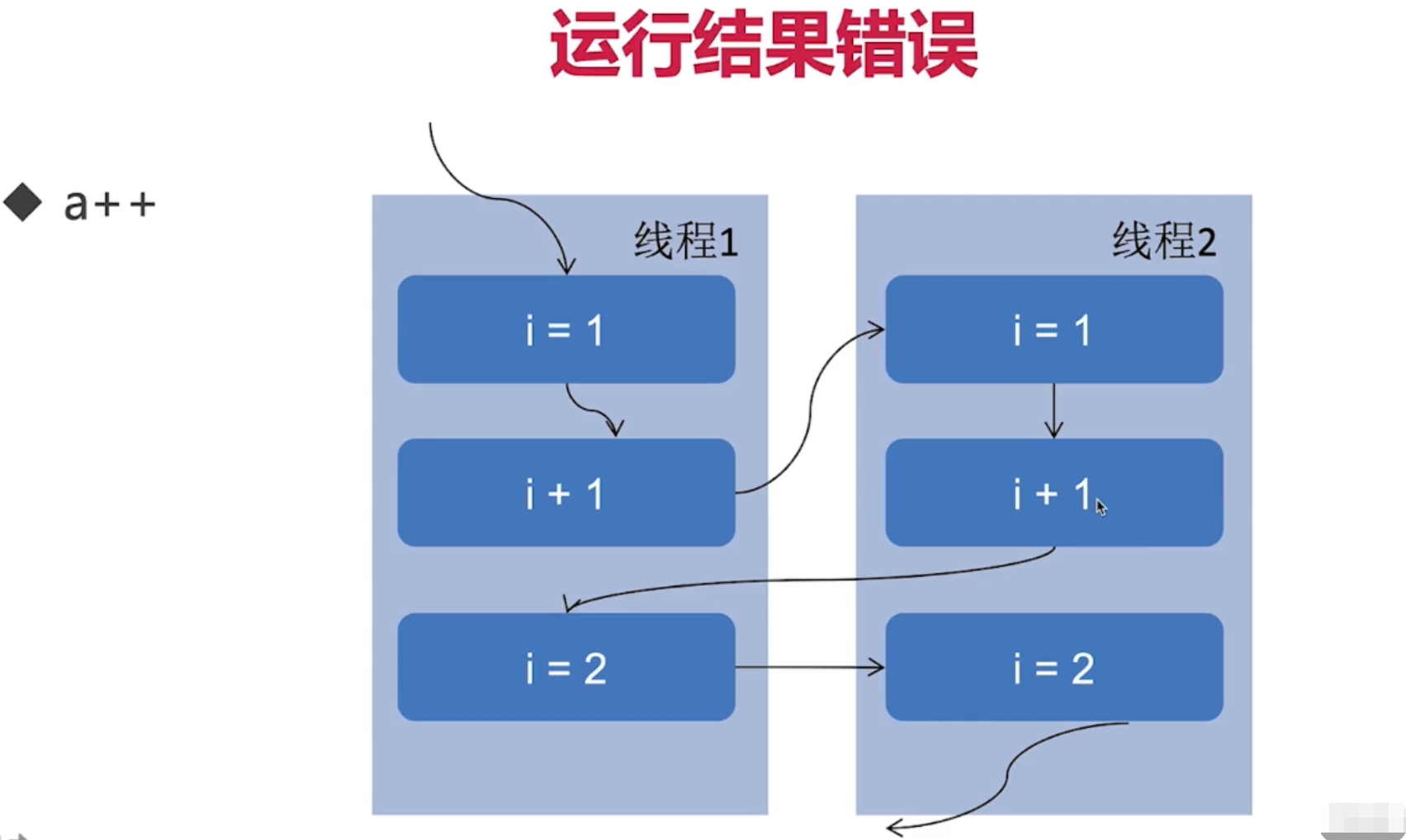
如上图,对于i++这一步,两个线程之间会获取 i 的值然后去执行 ++,比如线程1 拿到i时i=1,在执行 i+1时,线程2又拿到了i,这时依然是 i=1(因为线程1还没有运算结束),线程2也进行i+1,这就导致两个线程都计算的结果都是2,然后都给i赋值,最终i=2,但其实是i+1执行了两次,结果应该是i=3,运算结果不符合预期;结果也就导致上面代码中的打印结果。
那么 a++ 具体在哪里冲突了?又冲突了几次??我们可以尝试作如下改进,打印出出错的地方
public class MultiThreadsError implements Runnable {static MultiThreadsError multiThreadsError = new MultiThreadsError();// 通过一个boolean数组来标记已经++了的下标为true值,若如果已经为true,那么打印下标为越界线程错误的话;final boolean[] marked = new boolean[100000];int index = 0;// AtomicInteger为细化步骤,就会让这次操作不会出现线程不安全操作,这里用他记录错误/正确次数static AtomicInteger realInt = new AtomicInteger();//正确次数static AtomicInteger errorInt = new AtomicInteger();//错误次数//有参构造参数为2,代表需要等待两个线程经过,再放行static volatile CyclicBarrier cyclicBarrier1 = new CyclicBarrier(2);static volatile CyclicBarrier cyclicBarrier2 = new CyclicBarrier(2);public static void main(String[] args) throws InterruptedException {Thread thread1 = new Thread(multiThreadsError);Thread thread2 = new Thread(multiThreadsError);thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(multiThreadsError.index);System.out.println("正确次数为:"+realInt);System.out.println("错误次数为:"+errorInt);}@Overridepublic void run() {marked[0] = true;for (int i = 0; i < 10000; i++) {//设置栅栏try {cyclicBarrier2.reset();cyclicBarrier1.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}index++;try {cyclicBarrier1.reset();cyclicBarrier2.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}// 原子整数,是线程安全的,用来计数 ++ 执行的次数realInt.incrementAndGet();synchronized (multiThreadsError){// 如果已经为true,说明此时的index所在的位置已经执行过一次 ++ 了,那么打印下标为越界线程错误的话;// if (marked[index]){if (marked[index] && marked[index-1]){// 原子整数,是线程安全的,用来失败的次数errorInt.incrementAndGet();System.out.println("该下标【"+index+"】越界被标记过了");}marked[index] = true;}}}
}(1)定义 boolean[] marked 数组和 marked[index] = true 的作用?
通过一个boolean数组来标记已经++了的下标为true值,若如果已经为true,那么说明此时的 index 的当前值已经执行过一次 ++ 了,那就说明遇到了 index++ 冲突;
(1) 这里使用到了 CyclicBarrier 类,原因如下:
假设i=4时,线程1和2遇到冲突,计算之后都给i赋值了5,本该是一次错误运算,但是如果遇到下面的情景会将其认为是正确运算:此时的i=5,线程1先拿到锁后设置 marked[5]=true,然后线程1释放锁,此时线程1执行特别快,在线程2拿到锁时,线程1已经又执行了一次index++,此时的 index=6,线程2运行 if (marked[index])时,即 marked[6]明显还没设置,就不会认为是已经失败了。所以为了避免这种场景,保证线程1和2在交换锁期间,两个线程都只有一次 index++ 运算,就用到了 CyclicBarrier 类。
(2) 上面代码中为什么使用 if (marked[index] && marked[index-1]),而不是使用if (marked[index]),来作为失败运算的标记呢?
因为如果两个线程的 index++ 如果没有冲突的话,上个循环中的 index,和本次循环中的 index 应该是相差2,也就表示中间会少设置一个 marked[index],但是如果 marked[index-1] 已经被设置了,那就说明本次循环,两个线程的 index++ 冲突了,但是有一个特殊 marked[0],该值无论成功与否,都不会设置,所以需要在 run() 方法开头加上 marked[0] = true;
打印结果如下:
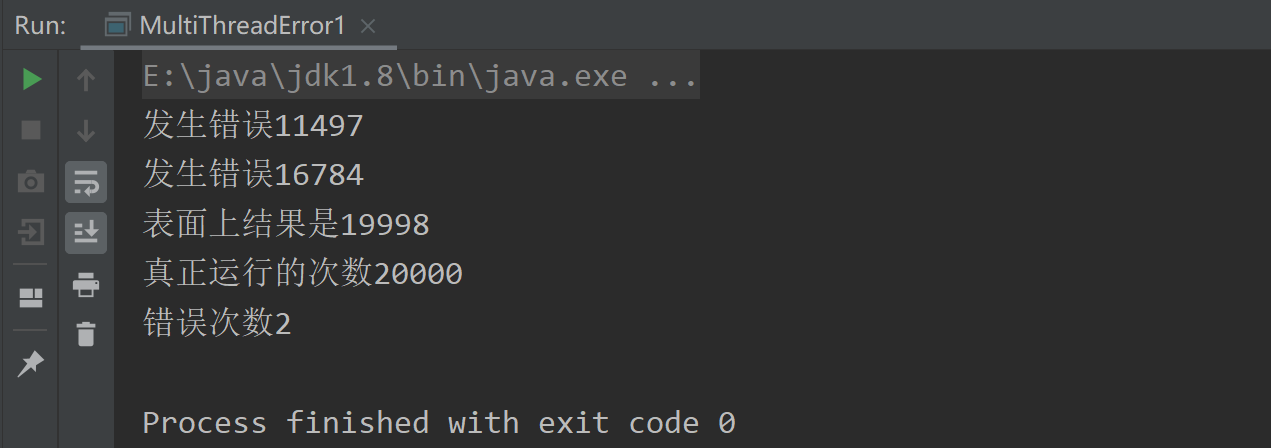
可以看到错误的次数和 表面上结果相加刚好是20000,同时也打印了发生错误的位置是19143,从而更清晰地知道哪里发生了 index++ 冲突。
2. 线程的活跃性问题:死锁、活锁、饥饿
这里以死锁为例,代码展示如下:
public class MultiThreadError implements Runnable {int flag = 1;static Object o1 = new Object();static Object o2 = new Object();public static void main(String[] args) {MultiThreadError r1 = new MultiThreadError();MultiThreadError r2 = new MultiThreadError();r1.flag=1;r2.flag=0;Thread thread1 = new Thread(r1);Thread thread2 = new Thread(r2);thread1.start();thread2.start();}@Overridepublic void run() {System.out.println("flag: "+flag);if (flag==1){synchronized (o1){try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}synchronized (o2){System.out.println("1");}}}if (flag==0){synchronized (o2){try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}synchronized (o1){System.out.println("1");}}}}
}结果如下:
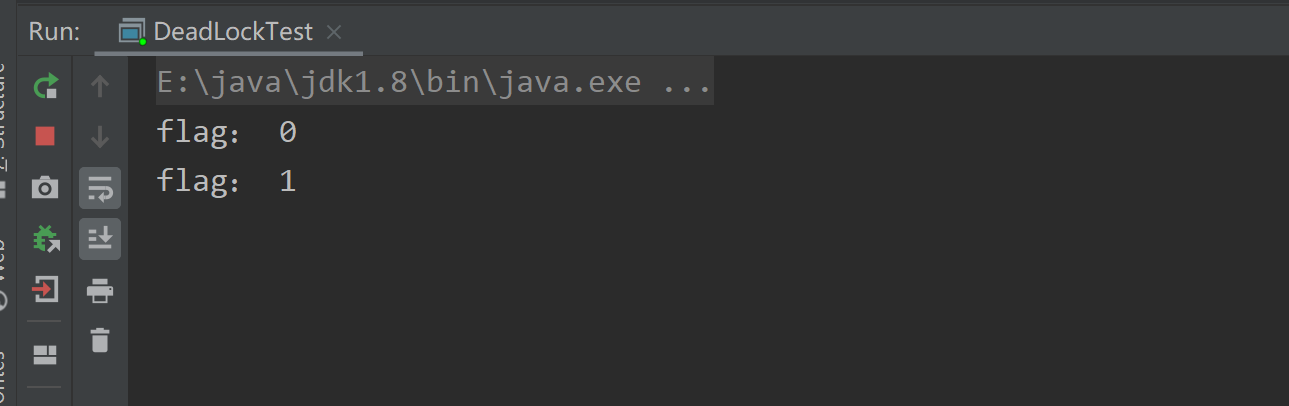
在打印出上面两行之后,便不会再进行打印,而且程序也不会终止,这就是死锁。两个线程首先都各自持有一个锁,然后去抢夺另一把锁,但是要抢夺的锁都已经心有所属,分别就是所属于对方,于是两个线程就一直干耗着,进退两难,成了死局。
3. 对象发布和初始化的时候的安全问题
什么是对象发布:
让这个对象在超过这个类的范围去使用。比如先使用 public 声明这个类,那么这个类就是被发布出去了,那怎么超过这个类的范围去使用呢,如下:
- 如果一个方法内 return 返回了一个对象的话,任何调用这个方法的类,都会获取到这个对象
- 将某类的对象作为参数传递到其他类中,也是该类的对象脱离了本类,进入其他对象中
什么是逸出:
某个被发布到不该发布的地方,比如:
- 方法返回一个private对象(private对象本身是不让外部访问)
- 还未完成初始化(构造函数没完全执行完毕)就把对象提供给外界,比如以下几种情况:
- 在构造函数中未初始化完毕就给外部对象赋值this实例
- 隐式逸出——注册监听事件
- 在构造函数中运行子线程
3.1 方法返回一个private对象
(1) 代码展示:
public class MultiThreadError3 {private Map<String,String> states;public MultiThreadError3(){states=new HashMap<>();states.put("1","周一");states.put("2","周二");states.put("3","周三");states.put("4","周四");states.put("5","周五");states.put("6","周六");states.put("7","周七");}//这里逸出了public Map<String,String> getStates(){return states;}//导致下面可以获取修改states对象的内容public static void main(String[] args) {MultiThreadError3 multiThreadError3 = new MultiThreadError3();Map<String, String> states = multiThreadError3.getStates();System.out.println(states.get("1"));states.remove("1");System.out.println(states.get("1"));}
}打印结果如下:
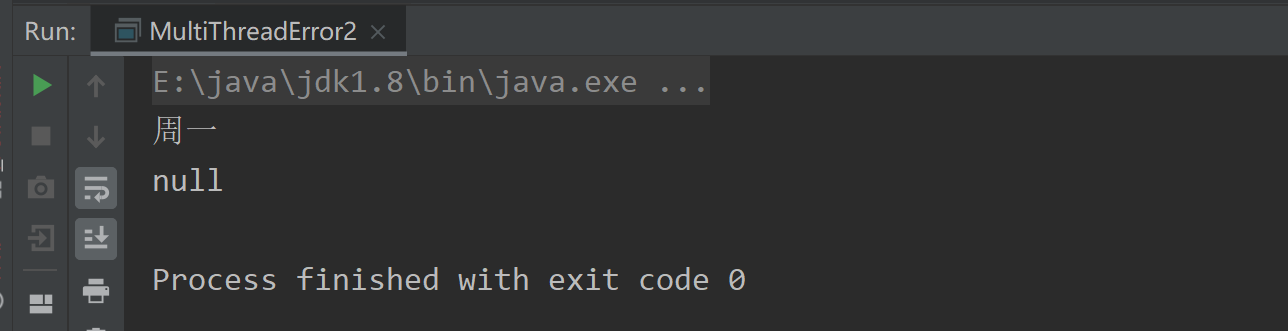
states这个Map 对象 本来是 MultiThreadError3类私有的,但是在 getStates() 方法中被 return 出去了,那么外部就能拿到这个states ,而且甚至能对它进行操作,修改里面的值,这就可能造成很严重的安全问题。
解决方案:
通过返回副本的方式,避免直接让这个对象暴露给外界。
/*** 描述: 返回副本,解决逸出*/
public class MultiThreadsError3 {private Map<String, String> states;public MultiThreadsError3() {states = new HashMap<>();states.put("1", "周一");states.put("2", "周二");states.put("3", "周三");states.put("4", "周四");}public Map<String, String> getStates() {return states;}public Map<String, String> getStatesImproved() {return new HashMap<>(states);}public static void main(String[] args) {MultiThreadsError3 multiThreadsError3 = new MultiThreadsError3();Map<String, String> states = multiThreadsError3.getStates();
// System.out.println(states.get("1"));
// states.remove("1");
// System.out.println(states.get("1"));System.out.println(multiThreadsError3.getStatesImproved().get("1"));multiThreadsError3.getStatesImproved().remove("1");System.out.println(multiThreadsError3.getStatesImproved().get("1"));}
}
打印结果:
3.2 还未完成初始化(构造函数没完全执行完毕)就把this对象提供给外界
(1)代码演示:在构造函数中未初始化完毕就给外界对象赋值
public class MultiThreadsError4 {static Point point;public static void main(String[] args) throws InterruptedException {new PointMaker().start();Thread.sleep(10);if (point != null) {System.out.println(point);}Thread.sleep(105);if (point != null) {System.out.println(point);}}
}class Point {private final int x, y;public Point(int x, int y) throws InterruptedException {this.x = x;MultiThreadsError4.point = this;Thread.sleep(100);this.y = y;}@Overridepublic String toString() {return x + "," + y;}
}class PointMaker extends Thread {@Overridepublic void run() {try {new Point(1, 1);} catch (InterruptedException e) {e.printStackTrace();}}
}打印结果:

因为x的初始化比 y 要早一点,并且在构造函数中有线程睡眠,就可能导致在 main 函数中不同的时间输出的结果不一样,比如上图在main 函数中 Thread.sleep(10) 之后打印出的结果,和 Thread.sleep(105)之后打印出的结果不一样
(2) 代码演示:隐式逸出——注册监听事件
/*** 观察者模式*/
public class MultiThreadsError5 {private int count;public MultiThreadsError5(MySource source) {source.registerListener(new EventListener() {@Overridepublic void onEvent(Event e) {System.out.println("\n我得到的数字是" + count);}});//模拟业务操作for (int i = 0; i < 10000; i++) {System.out.print(i);}count = 100;}public static void main(String[] args) {MySource mySource = new MySource();new Thread(() -> {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}mySource.eventCome(new Event() {});}).start();new MultiThreadsError5(mySource);}static class MySource {private EventListener listener;void registerListener(EventListener eventListener) {this.listener = eventListener;}void eventCome(Event e) {if (listener != null) {listener.onEvent(e);} else {System.out.println("还未初始化完毕");}}}interface EventListener {void onEvent(Event e);}interface Event {}
}结果如下:

结果为什么是0而不是100呢?
在 new EventListener()这个匿名内部类中,引用了外部类的 count变量,这个匿名内部类就可以对它进行操作,如果 count 的值在构造函数中还没有初始化完成,就对该 count 进行操作,就导致count的值不准确。、
解决方案:
使用工厂模式,将构造器私有化不对外暴露,对外暴露一个方法:等做完所需的操作之后再 return 发布出去,就不会有实例过早被暴露的问题了。
/*** 描述: 用工厂模式修复刚才的初始化问题*/
public class MultiThreadsError7 {int count;private EventListener listener;private MultiThreadsError7(MySource source) {listener = new EventListener() {@Overridepublic void onEvent(MultiThreadsError5.Event e) {System.out.println("\n我得到的数字是" + count);}};for (int i = 0; i < 10000; i++) {System.out.print(i);}count = 100;}public static MultiThreadsError7 getInstance(MySource source) {MultiThreadsError7 safeListener = new MultiThreadsError7(source);source.registerListener(safeListener.listener);return safeListener;}public static void main(String[] args) {MySource mySource = new MySource();new Thread(new Runnable() {@Overridepublic void run() {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}mySource.eventCome(new MultiThreadsError5.Event() {});}}).start();MultiThreadsError7 multiThreadsError7 = new MultiThreadsError7(mySource);}static class MySource {private EventListener listener;void registerListener(EventListener eventListener) {this.listener = eventListener;}void eventCome(MultiThreadsError5.Event e) {if (listener != null) {listener.onEvent(e);} else {System.out.println("还未初始化完毕");}}}interface EventListener {void onEvent(MultiThreadsError5.Event e);}interface Event {}
}
打印结果:

(3) 在构造函数中新建线程
/*** 构造函数中新建线程*/
public class MultiThreadError6 {private Map<String,String> states;public MultiThreadError6(){new Thread(new Runnable() {@Overridepublic void run() {states=new HashMap<>();states.put("1","周一");states.put("2","周二");states.put("3","周三");states.put("4","周四");states.put("5","周五");states.put("6","周六");states.put("7","周七");}}).start();}public Map<String,String> getStates(){return states;}public static void main(String[] args) {MultiThreadError6 multiThreadError6 = new MultiThreadError6();System.out.println(multiThreadError6.states.get("1"));}
}打印结果:

上图所示:出现了空指针的情况 ,因为初始化的操作在另外一个线程中,可能那个线程没有执行完毕,就会出现空指针,假如在 System.out.println(multiThreadError6.states.get("1"));之前 加入 Thread.sleep(1000)休眠一段时间后等另外一个线程执行完,就不会出现这个问题了。
三、总结
1. 各种需要考虑线程安全的情况,如下:
-
访问共享的变量或资源,会有并发风险,这里的共享变量或资源指的是:对象的属性,静态变量,共享缓存,数据库等等。
-
所有依赖时序的操作,即可以拆分成多个步骤的操作,即使每一步操作都是线程安全的,但是如果存在操作时序不对,还是存在并发问题,比如:read-modify-write(先读取再修改最后写入)、 check-then-act(先检查再操作)
-
不同的数据之间存在捆绑关系的时候,那就要么把这些捆绑的数据全部修改,要么都不修改
-
在使用其他类的时候,如果该类没有声明自己是线程安全的,那就要注意该类可能是线程不安全的
2. 多线程除了安全问题,还可能会导致性能问题:
从某种程度上来讲,多线程可以提高复杂的运算效率,但是一定程度上多线程可能会带来性能提交,比如多线程间的调度和协作带来的性能开销。
(1)调度:上下文切换
线程运行个数超过CPU核心数的时候,CPU就需要对线程进行调度,线程调度中就涉及线程切换,线程的切换的开销是很大的,CPU需要保存当前线程的运行场景,将当前线程的当前运行状态保存好,为载入新的运行线程做准备。这样来来回回其实是很耗费性能的。而引起密集的上下文切换的操作就包括抢锁和IO操作。
(2)协作:内存同步
多个线程之间,针对数据的同步其实大部分是基于 JMM 模型的,这种需要我们后续详细学习并总结,这里只是需要知道,多个线程之间,同步数据也是多线程消耗性能的一个原因。