目录
基本概念
基本操作
redis的五个基本类型
Redis-key(不区分大小写)
字符串 string
Redis的特殊类型
geospatial地理空间
事务
Redis的持久化
RDB(.rdb)
触发机制
优点
缺点
AOF(.aof)
优点
缺点
Redis发布订阅
相关命令
Redis主从复制
哨兵模式
哨兵在做什么?
Redis缓存穿透和雪崩
缓存穿透
解决办法
缓存击穿
解决办法
缓存雪崩
解决办法
基本概念
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。(使用内存存储的非关系型数据库)
默认有16个数据库
核心:单线程操作很快,Redis是将所有数据全部放在内存中的,所以说使用单线程去操作,效率就是最高的,相比于多线程,减少了CPU上下文切换的耗时。对于内存系统来说,没有上下文切换效率就是最高的,多次读写都是在一个CPU上的。
Redis是C语言实现的,官方数据:读:110000/s 写: 80000/s,完全不比同样使用key-value的Memcached差,速度与内存和网络带宽有关
基本操作
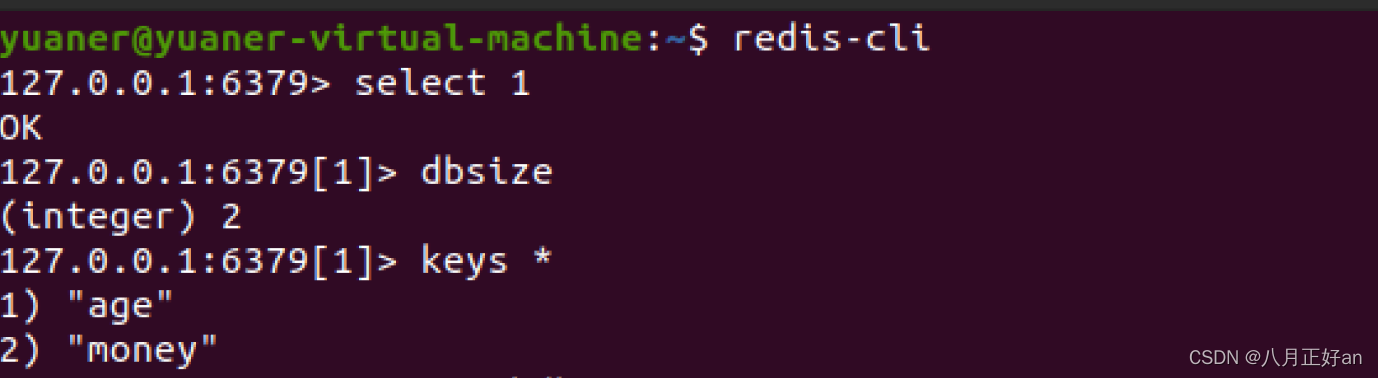
select 切换数据库
dasize 查看数据大小
keys * 查看所有的key值
flushdb flushall 清空当前数据库和清空所有数据库
redis的五个基本类型
Redis-key(不区分大小写)
SET 设置key
GET 查看key的值
EXPIRE 设置过期时间(实时刷新返回量较高的数据)
TTL 查询过期时间
EXISTS 判断当前的key是否存在
KEYS * 查看当前所有的key
DEL KEY 删除当前的key
TYPE 查看key存储的value的类型
字符串 string
列表 list
集合 set
srandmember set value 做抽奖很容易
Redis的特殊类型
geospatial地理空间
geoadd 添加地理位置
geopos 返回给定名称和经纬度
geodist 返回给定的两个位置之间的距离
geohash 返回一个11个字符的geohash字符串
georadius 以给定的经纬度为中心,寻找某一半径内的元素
事务
- 开启事务···multi
- 命令入队···...
- 执行事务···exec
Redis的持久化
redis是内存数据库,如果不将内存中的数据保存到磁盘中,一旦服务器进程退出,服务器中的数据库状态就会消失,所以redis提出了持久化功能。
RDB(.rdb)
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是快照,恢复时将快照文件直接读到内存中。单独创建一个子进程,先将数据写入到一个临时文件中,等到持久化结束,再用这个新的临时文件替换上一次的持久化好的文件。
就是在做文件复制
触发机制
- 保存时
- flushall
- 退出redis
优点
- 适合大规模的数据恢复
- 对数据的完整性要求不高
缺点
- 需要一定的时间间隔,如果redis宕机,最后一次保存的持久化文件之后的数据都没有了
- fork进程的时候,需要占用一定的内存空间
AOF(.aof)
将所有的写操作的命令都记录下来,在回复的时候将所有的命令都执行一遍
也就是保存命令
优点
- 每一次修改都会同步,文件的完整性比较好
- 每秒同步一次,可能只会丢失1s的数据
缺点
- 相对于数据文件,aof远远大于rdb(因为aof要保存整条命令,然后重新运行,rdb只需要保存已经运行好的临时文件)
- 修复速度慢
- 运行效率慢
Redis发布订阅
类似一种消息队列
- 订阅者订阅通道
- 发布者发布
- 订阅者接收
相关命令

Redis主从复制
将一个Redis服务器的数据复制到其他的redis服务器。前面的是主节点,后面的是从节点。
主节点写数据,从节点读数据,从节点每次从主节点处更新所读数据
作用
- 数据冗余:实现了数据的热备份
- 故障恢复:主节点出现问题,从节点便可转变为服务的提供者,从节点提供主节点的数据备份
- 负载均衡:读写分离,写场景连接主节点,读场景连接从节点,分担服务器负载
- 高可用的基石:是哨兵和集群的实现基础
默认下,每台Redis服务器都是主机,只需要配置从机和从库
哨兵模式
自动投票选举主机:当主服务器宕机后,需要把从服务器切换为主服务器,优先考虑哨兵模式,自动版本的从库切换主库模式。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个单独的进程,作为进程,他会独立运行。哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
哨兵在做什么?
- 发送命令
- 切换主机
- 注:多个哨兵监控Redis服务器(怕误判)
Redis缓存穿透和雪崩
缓存穿透
缓存中没有查到,向持久层(数据库)发出查询请求,发送请求的太多了就会给数据库造成很大的压力,这时候就相当于缓存穿透。
解决办法
- 布隆过滤器···布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合的则丢弃,从而避免持久层数据库的查询压力
- 缓存空对象···当存储层不命中后,及时返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护后端数据源(第二次以及后几次查询时,直接返回第一次保存的查询返回)
缓存击穿
一个key非常热点,在不断扛着大量并发,大并发集中对这个点进行访问,在这个key失效的瞬间,持续的大并发穿破缓存,直接请求数据库
解决办法
- 热点数据永不过期···不设置过期时间,就不会出现热点key过期后产生的问题
- 加互斥锁···使用分布式锁,保证对于每一个key来说同时只有一个线程去查询后端服务,等于把高并发的压力转移给了分布式锁,对于分布式锁的要求比较高
缓存雪崩
指在某一时间段内,缓存集中过期失效,或者Redis宕机,造成数据库的周期性压力波峰。
致命的雪崩是缓存服务器的某个节点宕机或断网,对数据库服务器造成的压力是不可预估的,很有可能就把数据库压宕机
解决办法
- Redis高可用···多增设几台Redis,搭建缓存服务器集群
- 限流降级···加锁或者队列,转移压力
- 数据预热···给不同的key设置不同的过期时间,让缓存失效的时间点尽量均匀。