文章目录
- 一、缓冲流
- 字节缓冲流
- 字符缓冲流
- 二、转换流
- 字符输入转换流
- 字符输出转换流
- 三、对象序列化
- 对象序列化
- 对象反序列化
- 四、打印流
- PrintStream
- PrintWriter
一、缓冲流
缓冲流:也叫高效流或者高级流,我们之前学的字节流称为原始流,缓冲流自带缓冲区,可以提高原始字节流、字符流读写数据的性能。
原始流:

缓冲流


字节缓冲流

我们可以发现我们的缓冲流BufferedInputStream继承于InputStream.
字节缓冲流性能优化原理:
字节缓冲输入流自带8KB缓冲池,我们直接从缓冲池读取数据,所以性能较好。
字节缓冲输出流自带8KB缓冲池,数据就直接写入到缓冲池中去,写数据性能极高。
| 方法 | 作用 |
|---|---|
| BufferedInputStream(InputStream is) | 可以把一个低级的字节输入流包装成一个高级的缓冲字节输入流管道,从而提高字节输入流读数据的性能 |
| BufferedOutputStream(OutputStream os) | 可以把一个低级的字节输出流包装成一个高级的缓冲字节输出流,从而提高写数据的性能 |

我们查一下缓冲字节输入流的构造方法

我们点进构造方法可以看到第二个参数传了一个8192的缓冲池大小的参数。

我们可以看到创建了一个8KB的字节数组,我们之前一个字节一个字节的读,现在直接一次性加载8KB的数据。
我们再来看一下缓冲字节输出流的构造方法


为什么我们会说缓冲字节输出流效率极高,因为我们直接的原始流是将内存的数据一个字节一个字节写到硬盘上,写到硬盘上的操作是比较慢的,而我们的缓冲字节输出流,是有一个8KB的缓冲池,这个缓冲池是内存的,我们内存写内存的操作是极快的。
我们这里的缓冲流的方法和原始流的方法基本是一致的,我们在这里就不详细介绍了。
我们分别使用初始字节流和缓冲字节流拷贝文件,比较一下性能。

分别使用四种方法:
1.使用初级的字节流按照一个字节一个字节的形式复制文件
2.使用初级的字节流按照一个一个字节数组的形式复制文件
3.使用缓冲字节流按照一个字节一个字节的形式复制文件
4.使用缓冲字节流按照一个一个字节数组的形式复制文件
public class Test {private static final String SRC_FILE = "D:\\workspace\\work.docx";//源文件路径private static final String DEST_FILE = "D:\\workspace1\\";//目的文件路径public static void main(String[] args) throws IOException {copy1();//使用初级的字节流按照一个字节一个字节的形式复制文件copy2();//使用初级的字节流按照一个一个字节数组的形式复制文件copy3();//使用缓冲字节流按照一个字节一个字节的形式复制文件copy4();//使用缓冲字节流按照一个一个字节数组的形式复制文件}private static void copy1() throws IOException {long startTime = System.currentTimeMillis();try(//1.创建初级的字节输入流与源文件接通InputStream inputStream = new FileInputStream(SRC_FILE);//2.创建低级的字节输出流与目标文件接通OutputStream outputStream = new FileOutputStream(DEST_FILE + "work1.docx");//动态定义目标文件名称) {int len;while((len = inputStream.read()) != -1) {outputStream.write(len);}}catch (IOException e) {e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("初级字节流一个一个字节花费: " +(endTime - startTime) + "时间" );}private static void copy2() {long startTime = System.currentTimeMillis();try(//1.创建初级的字节输入流与源文件接通InputStream inputStream = new FileInputStream(SRC_FILE);//2.创建低级的字节输出流与目标文件接通OutputStream outputStream = new FileOutputStream(DEST_FILE + "work2.docx");//动态定义目标文件名称) {byte[] buffer = new byte[1024];int len;while ((len = inputStream.read(buffer)) != -1) {outputStream.write(buffer,0,len);}}catch (IOException e) {e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("初级字节流一个一个字节数组花费: " +(endTime - startTime) + "时间" );}private static void copy3() {long startTime = System.currentTimeMillis();try(//1.创建初级的字节输入流与源文件接通InputStream inputStream = new FileInputStream(SRC_FILE);//a.把原始的字节输入流包装成高级的缓冲字节输入流InputStream bis = new BufferedInputStream(inputStream);//2.创建低级的字节输出流与目标文件接通OutputStream outputStream = new FileOutputStream(DEST_FILE + "work3.docx");//动态定义目标文件名称//b.把字节输出流管道包装成高级的缓冲字节输出流OutputStream bos = new BufferedOutputStream(outputStream);) {int len;while((len = bis.read()) != -1) {bos.write(len);}}catch (IOException e) {e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲字节流一个一个字节花费: " +(endTime - startTime) + "时间" );}private static void copy4() {long startTime = System.currentTimeMillis();try(//1.创建初级的字节输入流与源文件接通InputStream inputStream = new FileInputStream(SRC_FILE);//a.把原始的字节输入流包装成高级的缓冲字节输入流InputStream bis = new BufferedInputStream(inputStream);//2.创建低级的字节输出流与目标文件接通OutputStream outputStream = new FileOutputStream(DEST_FILE + "work3.docx");//动态定义目标文件名称//b.把字节输出流管道包装成高级的缓冲字节输出流OutputStream bos = new BufferedOutputStream(outputStream);) {byte[] buffer = new byte[1024];int len;while ((len = bis.read(buffer)) != -1) {bos.write(buffer,0,len);}}catch (IOException e) {e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲字节流一个一个字节数组花费: " +(endTime - startTime) + "时间" );}
}

我们首先可以看到使用初级流,一个字节一个字节去操作,真的慢的要死,相比直接我们的缓冲字节流按照字节数组的方式读写是最快的。
字符缓冲流
字符缓冲输入流:BufferedReader,提高字符输入流读取数据的性能,除此之外多了按照行读取数据的功能。
| 方法 | 作用 |
|---|---|
| BufferedReader(Reader r) | 把初级的字符输入流包装成一个缓冲字符输入流 |
| readLine() | 读取一行数据返回,如果读取没有完毕,无行可读返回null |

我们先准备一个出师表的文件,之前按照一个字符一个字符读和一个字符数组的读我们这里就不介绍了。
public static void main(String[] args) {try(//创建一个字符输入流与源文件接通Reader reader = new FileReader("./data.txt");//把初级的字符输入流包装成缓冲字符输入流BufferedReader br = new BufferedReader(reader);) {//使用一次读一行的方式读文件String line;while((line = br.readLine()) != null) {System.out.println(line);}}catch (IOException e) {e.printStackTrace();}}

字符缓冲输出流:BufferedWriter,提高字符输出流写数据的性能,除此之外多了换行功能。
| 方法 | 作用 |
|---|---|
| BufferedWriter(Writer w) | 把初级的字符输出流包装成一个缓冲字符输出流 |
| newLine() | 换行操作 |


这里也是带了一个8KB的缓冲区。

这是我们写数据大概的一个顺序。
public static void main(String[] args) throws IOException {//创建一个字符输出流管道与源文件接通Writer writer = new FileWriter("./data.txt");BufferedWriter bw = new BufferedWriter(writer);//使用newLine实现换行功能bw.write("我是中国人");bw.newLine();bw.write("Chine");bw.newLine();bw.write("哈哈");bw.close();}

二、转换流
之前我们在使用字符流读取中文的时候是没有乱码的,因为我们代码的解码和文件编码的方式都是UTF-8。
但是如果代码和文件编码不一致,使用字符流直接读取就会出现乱码情况。

我们在这里准备一个GBK编码的文件。
public static void main(String[] args) {try(//文件为 GBK 代码UTF-8//创建一个字符输入流与源文件接通Reader reader = new FileReader("D:/workspace/data.txt");//把初级的字符输入流包装成缓冲字符输入流BufferedReader br = new BufferedReader(reader);) {//使用一次读一行的方式读文件String line;while((line = br.readLine()) != null) {System.out.println(line);}}catch (IOException e) {e.printStackTrace();}}

我们会发现中文会出现乱码。
字符输入转换流
字符输入转换流:提取文件(GBK)的原始字节流,原始字节流是不存在问题的,然后把字节流以指定编码转换成字符输入流,这样字符输入流中的字符就不会出现乱码了。

| 方法 | 作用 |
|---|---|
| InputStreamReader(InputStream is) | 可以把原始的字节流按照代码默认编码转换成字符输入流 |
| InputStreamReader(InputStream is,String charset) | 把原始的字节流按照指定编码转换成字符输入流 |

public static void main(String[] args) throws IOException {//文件GBK 代码UTF-8//提取文件的原始字节流InputStream is = new FileInputStream("D:/workspace/data.txt");//原始字节流转换成字符输入流Reader isr = new InputStreamReader(is,"GBK");//以GBK的方式转换为字符输入流BufferedReader br = new BufferedReader(isr);String line;while((line = br.readLine()) != null) {System.out.println(line);}br.close();}

字符输出转换流
如何控制写出去字符使用的编码?
- 可以把字符以指定的编码获取字节后在使用字节输出流写出去,“我是中国人”.getBytes(编码)
- 使用字符输出转换流
| 方法 | 作用 |
|---|---|
| OutputStreamWriter(OutputStream(os) | 将初级的字节输出流转换为代码默认字符的字符输出流 |
| OutputStreamWriter(OutputStream os,String charset) | 将原始字节输出流转换为指定字符的字符输出流 |
public static void main(String[] args) throws IOException{//定义一个字节输出流OutputStream outputStream = new FileOutputStream("D:/workspace/data.txt");//将字节输出流转换为字符输出流Writer writer = new OutputStreamWriter(outputStream,"GBK");BufferedWriter bw = new BufferedWriter(writer);bw.write("我在试转换字符输出流");bw.newLine();bw.write("成功了吗?");bw.newLine();bw.write("成功了");bw.close();}

三、对象序列化
对象序列化
对象序列化:使用对象字节输出流(ObjectOutputStream)以内存为基准,把内存的对象存储到磁盘文件中,称为对象序列化


这是API文档为我们介绍的对象序列化的使用方式,我们来具体学习一下。
| 方法 | 作用 |
|---|---|
| ObjectOutputStream(OutputStream out) | 将初级字节输出流包装成高级的对象字节输出流 |
| writeObject(Object obj) | 将对象写道对象序列化流的文件中去 |

在这里我们准备了一个Student类。
public static void main(String[] args) throws IOException {//创建一个学生对象Student student = new Student("张三",18,001);//对象序列化,使用对象字节输出流包装字节输出流管道ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./data.txt"));//调用序列化方法oos.writeObject(student);oos.close();}

这里报了一个不可序列化异常,原因很简单因为我们的对象没有实现序列化接口,我们的对象要存到硬盘要遵守一定的规则,那么这个规则由谁来制定,肯定是由我们的java来制定。


看到这里,我们就序列化成功了,这里不是乱码,只供系统能够看懂。
对象反序列化
对象字节输入流(ObjectInputStream):将硬盘中的对象数据按照字节流到内存中的java对象

| 方法 | 作用 |
|---|---|
| ObjectInputStream(InputStream out) | 将低级的字节流输入流包装成对象字节输入流 |
| readObject() | 将存储到磁盘文件中的对象数据恢复到内存中的对象返回 |
public static void main(String[] args) throws IOException, ClassNotFoundException {//创建对象字节输入流管道包装初级的字节输入流管道ObjectInputStream is = new ObjectInputStream(new FileInputStream("./data.txt"));Student stu = (Student)is.readObject();System.out.println(stu);}

我们在有些序列化的时候并不想将某些对象的部分信息序列化。


我们在进行序列化反序列化,我们transient修饰的变量是默认值。
我们一般也会申明序列化的版本号,只有我们的序列化和反序列化的版本号一致才不会出错,避免我们在反序列化之前对对象的一些属性进行了修改。


当我们在序列化版本号为1时序列化,序列化版本号为2时反序列化就会报一个无效类的异常,提醒我们重新序列化然后再进行反序列化。
四、打印流
打印流可以实现更方便,高效的打印数据到文件中去
PrintStream
| 方法 | 作用 |
|---|---|
| PrintStream(OutputStream os) | 打印流直接通向字节输出流管道 |
| PrintStream(File f) | 打印流通向文件对象 |
| PrintStream(String filepath) | 打印流通向文件路径 |
| print(Xxx xxx) | 打印任意类型的数据 |
public static void main(String[] args) throws FileNotFoundException {PrintStream ps = new PrintStream("./data.txt");ps.println(1);ps.println(true);ps.println(10.5);ps.println("helloworld!");ps.close();}


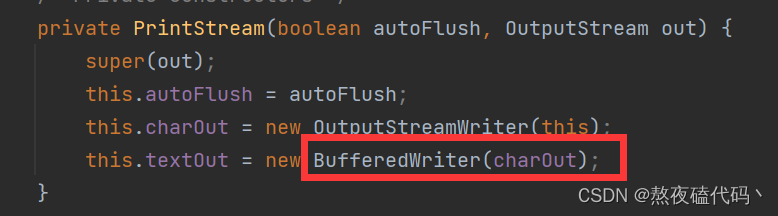
我们可以顺着构造方法看些源码,是有包装缓冲字符输出流的,所以效率是比较高的。
PrintWriter
| 方法 | 作用 |
|---|---|
| PrintWriter(OutputStream os) | 打印流通向字节输出流管道 |
| PrintWriter(Writer w) | 打印流通向字符输出流管道 |
| PrintWriter(File f) | 打印流通向文件对象 |
| PrintWriter(String filepath) | 打印流通向文件路径 |
| print(Xxx xxx) | 打印任意类型数据 |
我们PrintWriter 和 PrintStream打印数据的方式是一样的,我们就不过多介绍了。
PrintWriter 和 PrintStream的区别
1.打印数据功能一模一样,使用方便,性能高效
2.PrintStream继承字节输出流OutputStream,支持写字节数据的方法
3.PrintWriter继承字符输出流Writer,支持写字符数据的方法