M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
本文的目标是构建更加高效的特征金字塔,以提高不同尺寸目标的检测准确率。
特征金字塔被广泛应用于目标检测中(one-stage的DSSD、RetinaNet、RefineDet和two-stage的Mask R-CNN、DetNet),主要解决物体检测中的目标多尺度问题,简而言之,特征图的感受野是一定的,在这种感受野下只适合检测对应感受野大小的目标。如果图片中目标比感受野小,则很难被检测到。
传统解决这个问题的思路包括:
(1). 多尺度训练和测试,也称图像金字塔。就是将同一张图片,分成大小不同的图像金字塔,将这些图片喂到同一个网络中,由于图片经历过的网络的步长都是相同的,最终形成的特征图大小也不一样,但是由于步长相同,所以感受野也相同。小图像中的大目标被调整到感受野大小后,其特征图就容易被检测到。同样大图相中的小目标也被调整到感受野大小后,其特征图也容易检测到对应的目标。但是这样的方法成本太高,难以在实际中应用。

(2). 特征分层,即一张图片产生多个特征后,分别在这些特征上进行预测。浅层的特征图相对较大,感受野较小,适合检测小目标。而深层的特征图相对较小,感受野较大,适合检测大目标。SSD框架就采用了类似的思想。但是深层和浅层所学到的信息是不同的,浅层学到的是特征细节,而深层学到的是语义特征。一刀切的从感受野层面解释是欠妥的。

(3). 特征金字塔FPN,将深层的语义信息和浅层的特征细节信息结合(concat),然后对融合信息后的特征图进行预测。一般来说,深层的特征图更适合分类任务,浅层的特征图更适合物体位置的回归,所以将深层的信息融合进浅层特征图中更有利于检测到目标。除此之外,低层特征更适合检测简单外形的目标,深层特征更适合检测复杂外形的目标。即使图片中大小相同的物体,其复杂度都是不一样的(比如近处的红绿灯和远处的行人),所以没有深层语义信息,仅靠浅层特征图检测到复杂物体的难度要较大一些。作者对FPN能提高小物体的准确率的解释为:小物体不仅需要更高分辨率的特征图所对应的感受野,同时还需要深层的全局上下文信息判断目标的存在以及获得目标所在位置。

尽管FPN取得了不错的效果,但是只是简单的进行不同尺度的融合。金字塔结构特征的backbone是专门为分类任务设计的。
针对这个问题,本文作者提出了新的不同尺度融合的方法Multi-Level Feature Pyramid Network (MLFPN)。
首先,融合骨干网络抽取出来的多级特征作为基本特征。
然后,我们将基本特征输入到一组U型模块(TUM)和特征融合模块(FFM),其中U型模块的解码器层作为检测对象的特征。
最后,收集解码器层用于构建特征金字塔。
为了验证MLFPN的效果,作者整合了MLFPN和SSD,构建了one-stage目标检测模型M2Det。
MLFPN由三个模块组成,Feature Fusion Module(FFM)、Thinned U-shape Module(TUM)、Scale-wise Feature Aggregation Module(SFAM)。MLFPN结构如下图所示:

M2Det使用Backbone的多级特征经过FFM1后形成了基本特征,每个U型模块都会产生一组多尺度特征图。然后使用FFMv2将前一层TUM产生的多级特征图中最大输出特征图和基本特征融合,形成的融合特征图作为下一层TUM的输入。最终形成多级多尺度的特征图(本文使用了8级6个尺度)。最后SFAM将特征聚合成多级特征金字塔。
注:第一个TUM并没有其他TUM产生的特征图,所以它的唯一学习来源就是基础特征图。
MLFPN的多级多尺度特征计算过程可用公式来描述:
其中: X b a s e X_{base} Xbase表示基本特征图, x i l x_i^l xil表示第 l l l层TUM的第 i i i大尺寸的特征图(按大小升序)。 L L L表示TUM的数量, T l T_l Tl表示第 l l l个TUM处理过程, F F F表示FFM的处理过程。

三大核心模块的介绍:
FFM:
Feature Fusion Module特征融合模块,用于融合多层特征图。FFMv1和FFMv2的参与对象和操作都不同。FFMv1的输入是backbone产生的多个不同大小的特征图,不同大小的两个特征图经FFMv1融合流程如下图所示:
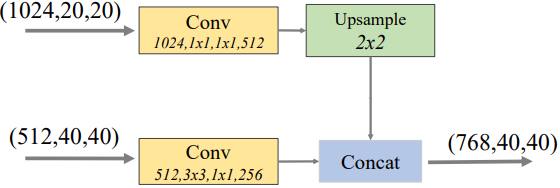
解释:上面的特征图通道数为1024,长和宽为2020。下面的特征图通道数为512,长和宽为4040。经过11的卷积层改变特征图的通道数。上面的特征图通道数改为512,下面的特征图通道数改为256. 将较小的特征图上采样后变为与较大特征图同样长宽。然后进行concat操作后变成了通道数为512+256=768,长宽为4040的特征图。
FFMv2的操作流程如下图所示:

解释:FFMv2的输入是基础特征图(768通道,长宽4040)和上一层TUM中最大尺寸的特征图(128通道,长宽4040)。基础特征图经11的卷积层改变通道数为128,然后和上一层TUM中最大尺寸的特征图进行concat操作,形成通道数为256,长宽4040的特征图。
TUM:
Thinned U-shape Module(TUM),U型模块。结构如下图所示:

绿色框是编码器,是一系列33步长是22的卷积层。红色框是解码器,是一系列33步长为11的卷积层。由于编码器的步长比解码器的大,所以编码器的输出长宽比解码器的输出长宽大。所以先对编码器内容上采样后再按元素位置相加。按元素相加后是有信息损失的,所以这里可以改成concat操作。然后接1*1的卷积层改变通道数。TUM所在层次越深,则其输出的特征图信息也越深。
SFAM:
Scale-wise Feature Aggregation Module(SFAM),SFAM的结构如下图所示:

SFAM分两个阶段,第一个阶段是将相同大小的特征图concat,第一阶段的输出可以表示成 X = [ X 1 , X 2 , … , X i ] X=[X_1,X_2,\dots ,X_i] X=[X1,X2,…,Xi],表示不同大小的特征图组,其中 i i i表示第i大的特征图, X i = C o n c a t ( x i 1 , x i 2 , … , x i L ) X_i=Concat(x_i^1,x_i^2,\dots,x_i^L) Xi=Concat(xi1,xi2,…,xiL),表示所有L层中第i大的特征图的concat。第二阶段是对特征图通道采用SE注意力机制。SE注意力模块简而言之就是为特征图的通道附加权重。SE注意力模块可由下图来表示:

输入的特征图大小为W*H通道数为C,先经过压缩操作(全局平均池化)变成了1*1*C的特征图 z ∈ R C z\in R^C z∈RC。然后经过激励操作得到各个通道的权重。激励操作具体如下图所示:

即通过一个(全连接层1,激活函数1,全连接层2,激活函数2)。其中SERadio是个调整通道数量以对应全连接层的神经元个数的比例。 s = σ ( W 2 δ ( W 1 z ) ) s=\sigma (W_2\delta(W_1z)) s=σ(W2δ(W1z))其中 σ \sigma σ表示ReLU激活函数, δ \delta δ表示sigmoid激活函数。
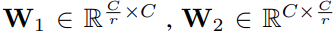
其中,r表示缩放比例,本文r=16。
然后利用权重 s s s对输入 X X X附加权重。

c表示第c个通道,最终附加权重的特征图组

作者的检测器采用的是SSD架构,即为特征图的每个像素点产生密集锚框,每个像素点对应原图中的感受野,如果感受野内有目标,则取置信度最大的锚框和置信度超0.7的锚框作为候选框。SSD架构的运行效率并不比YOLOv3的高,所以这里可以作为改进点,将检测器改成YOLOv3的框架。
讨论:
作者认为,M2Det能够超过SOTA的原因是MLFPN。一方面融合backbone中多层特征图作为基本特征,然后从基本特征中抽取出多层多级特征图用于目标检测比起FPN仅利用单层特征进行目标检测更具有代表性。既考虑到了特征图的感受野,也考虑到了不同层的语义信息。
作者还做了特征的可视化实验,如下图所示:

比起图像金字塔仅考虑scale层面,和比起特征分层仅考虑level层面,FPN和MLFPN要更加合理,但是FPN主要还是考虑scale层面,MLFPN兼顾了两者。
参考文献:
1. Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.



