1 准备工作
1.1 准备Excel文件
我这边直接使用上一篇导出的excel:file_user.xls
1.2 创建数据库
在mysql中创建数据库

1.3 在kettle中加载MySQL驱动
Kettle要想连接到MySQL,必须要安装一个MySQL的驱动,就好比我们装完操作系统要安装显卡驱动一样。加载MySQL驱动只需以下两步:
- 将资料中的MySQLjdbc驱动包mysql-connector-java-5.1.47.jar和mysql-connector-java-8.0.13.jar导入到data-integration/lib中
- 重启Kettle即可
2 构建Kettle数据流图
2.1 效果图

2.2 开发步骤
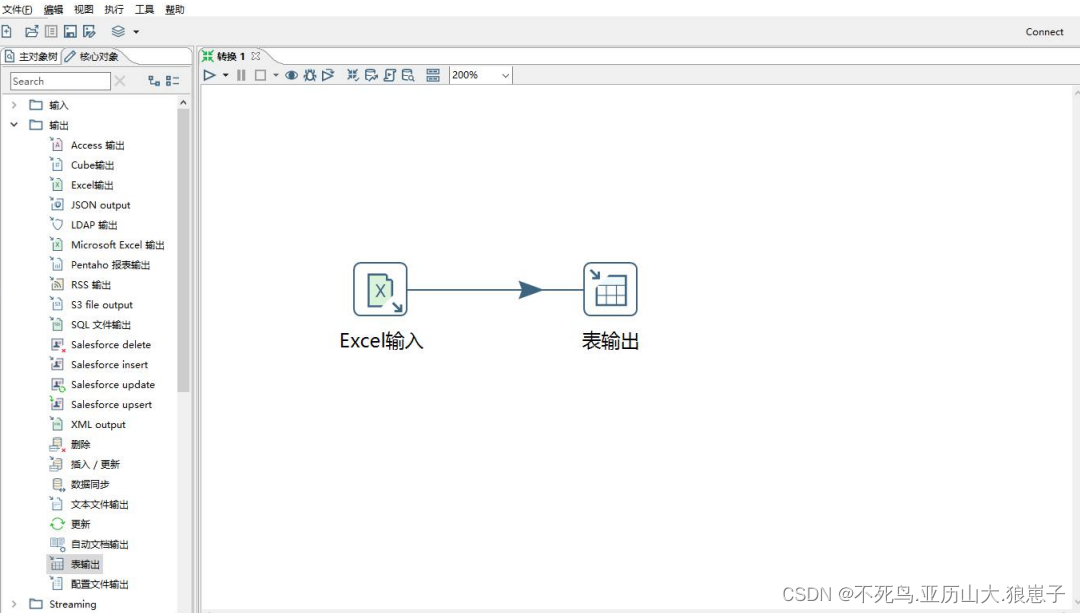
(1)在Kettle中创建一个转换,从左边的核心对象中,分别拖入「输入/Excel输入」、「输出/表输出」两个组件到中间区域

(2)然后按住Shift键,在 「Excel输入」组件上点击鼠标左键,拖动到「表输出」组件上,连接两个组件,这样数据流图就构建好了
3 配置Kettle数据流图中的组件
刚刚已经把数据流图构建好了,那么Kettle就可以将Excel文件中的数据抽取到MySQL中吗?
显然是不行的。Kettle根本不知道要将哪个Excel文件中的数据,抽取到哪个MySQL中。我们需要配置这两个组件,告诉Kettle从哪个Excel文件中抽取,以及将数据装载到哪个MySQL中。
3.1 配置Excel输入组件
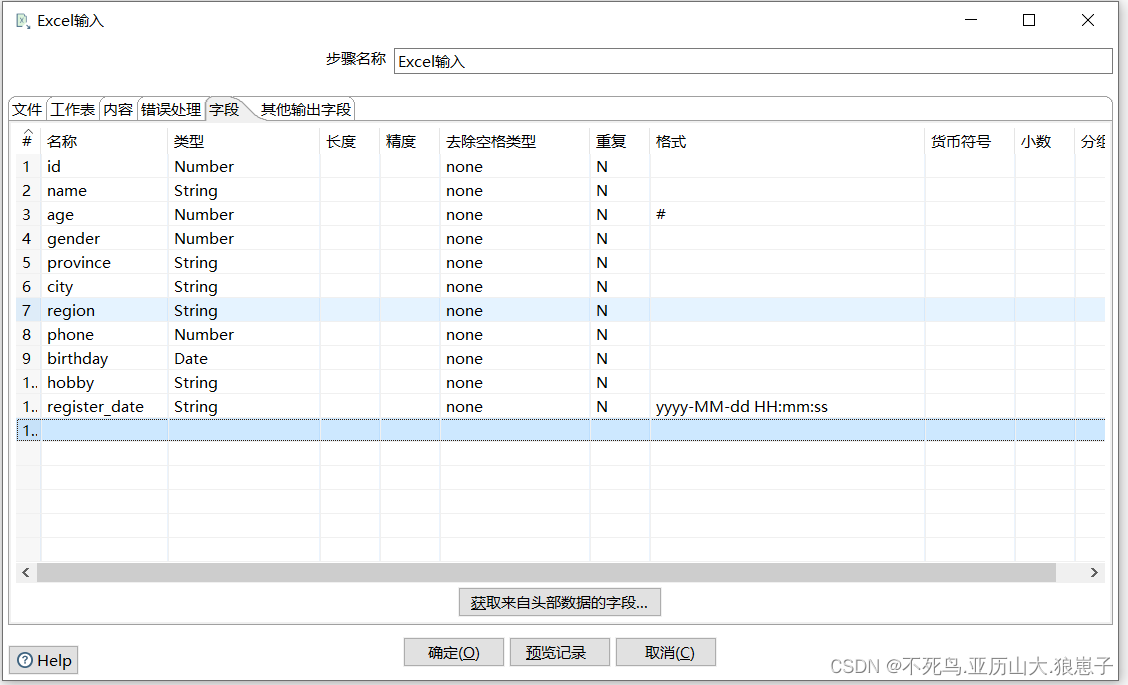
1 双击Excel输入组件,会弹出一个对话框,我们可以再该对话框中配置该组件
此处要抽取的Excel文件为Excel 2007版本,所以指定表格类型为Excel 2007 XLSX
(Apache POI),随后我们需要找到要抽取的那个Excel文件,点击「浏览」按钮,找到excel文件,再点击旁边的「增加」按钮。
切记:一定要点击增加按钮哦!否则没有效果!

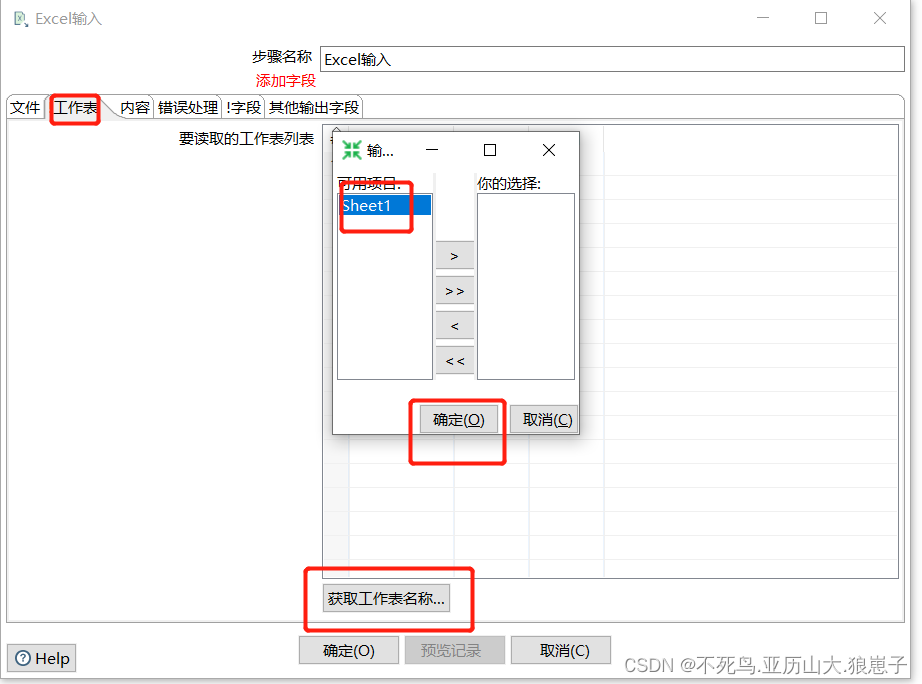
2 在弹出菜单中,点击「Sheet1」工作簿,并点击 「>」 按钮移动到右边
3 点击「字段」选项卡,点击「获取来自头部数据的字段...」按钮,Kettle会从Excel中读取第一行字段名称。

4 将 age 字段的格式设置为#,register_date的格式设置为 yyyy-MM-dd HH:mm:ss。
5 点击「预览记录」按钮查看抽取到的数据

6 点击确定保存
3.2 配置MySQL组件
3.2.1 创建数据库连接
要使用Kettle操作MySQL,必须要建立Kettle与MySQL的连接,否则Kettle也不知道操作哪个MySQL库。
1 双击「表输入」组件,会自动弹出配置窗口,点击「新建」按钮

2 配置MySQL连接
(1) 输入连接名称,此处用mysql_开头,数据库名称kettle_demo为结尾
(2) 在连接类型列表中,选择MySQL
(3) 输入连接方式:
(4) 输入MySQL的连接参数

注意:以下两步操作是为了防止乱码的
(5)高级添加 set names utf8;
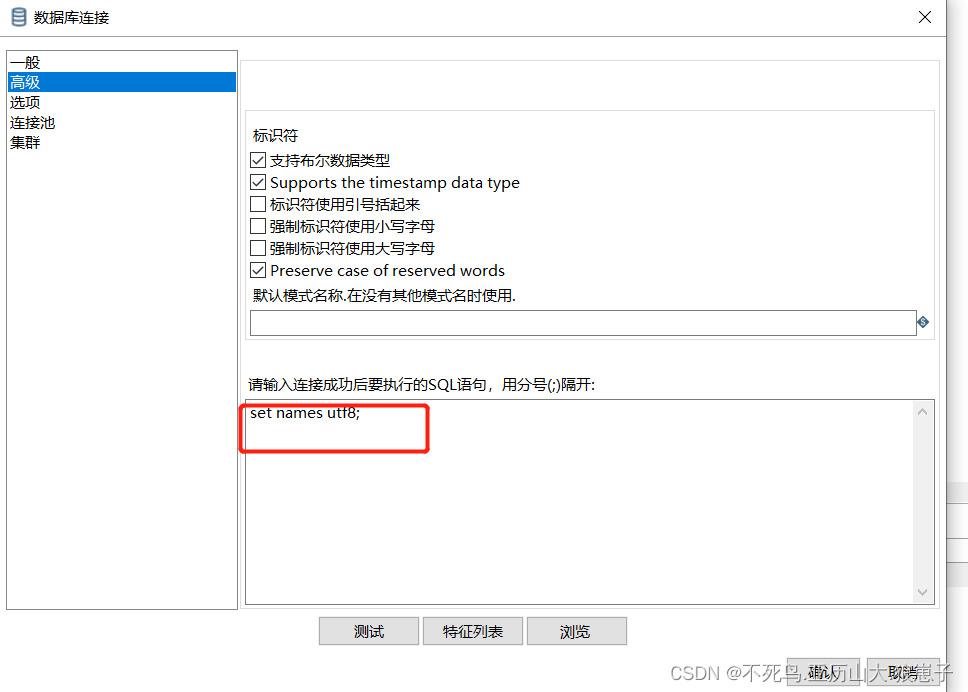
(6)选项添加characterEncoding utf8

3 点击测试按钮,测试Kettle是否能够正确连接到MySQL
4 点击确认保存,到这里数据库连接就应该创建好了。

3.2.2 使用Kettle在MySQL中自动创建表
要保存数据到MySQL,必须先要创建好表。那么,我们是否需要自己手动在MySQL中创建一个表,用来保存Excel中抽取过来的数据呢?
答案是:不需要。Kettke可以自动为我们在MySQL中创建表。
1 输入目标表的名称为:t_user,后续Kettle将在MySQL中创建一张名为 t_user 的表格。

2 点击下方的「SQL」按钮,可以看到Kettle会自动帮助我们生成MySQL创建表的SQL语句


将age、gender字段类型设置为INT

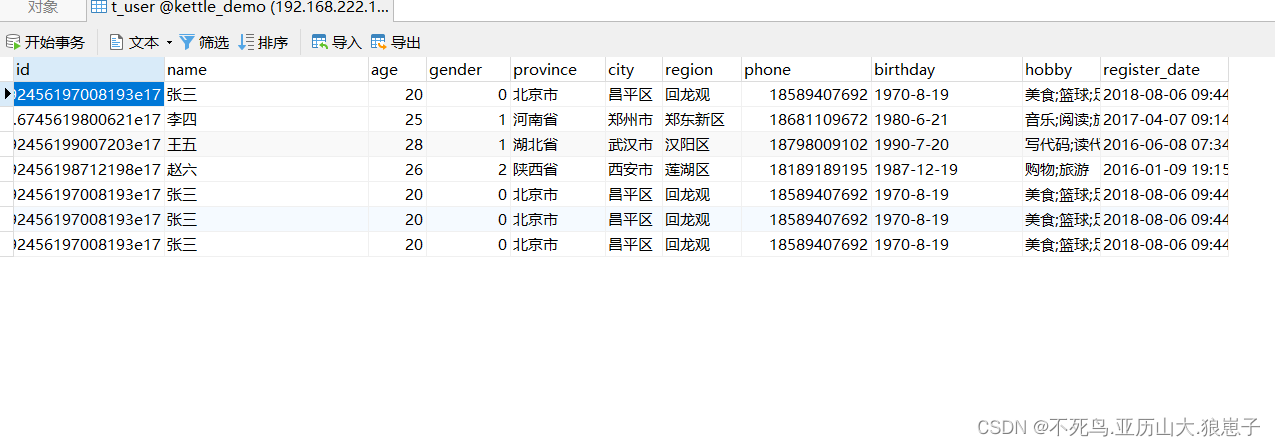
3 点击执行按钮。Kettle将会让MySQL执行该SQL脚本。执行完后,可以在navicat中刷新在数据库,可以查看到Kettle帮助我们创建的t_user表。

4 点击「确定」按钮,保存配置
3.3 保存并启动执行Kettle转换

查看数据库