一. 索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构。
二. 索引的数据结构
- 二叉树
- 红黑树
- Hash表
- BTree
- B+Tree
mysql的索引采用的是B+树的结构
mysql为什么不用二叉树,因为对于单边增长的数据列,二叉树和全表扫描差不多,效率没有什么提升。
mysql为什么不用红黑树,因为使用红黑树,树的高度会比较高,如果要查找的元素在叶子节点比如在20层,就会查询20层,所以对于数据量大的不可控,树的高度越小,效率越高;
mysql为什么不用hash表,因为hash表不支持范围查询
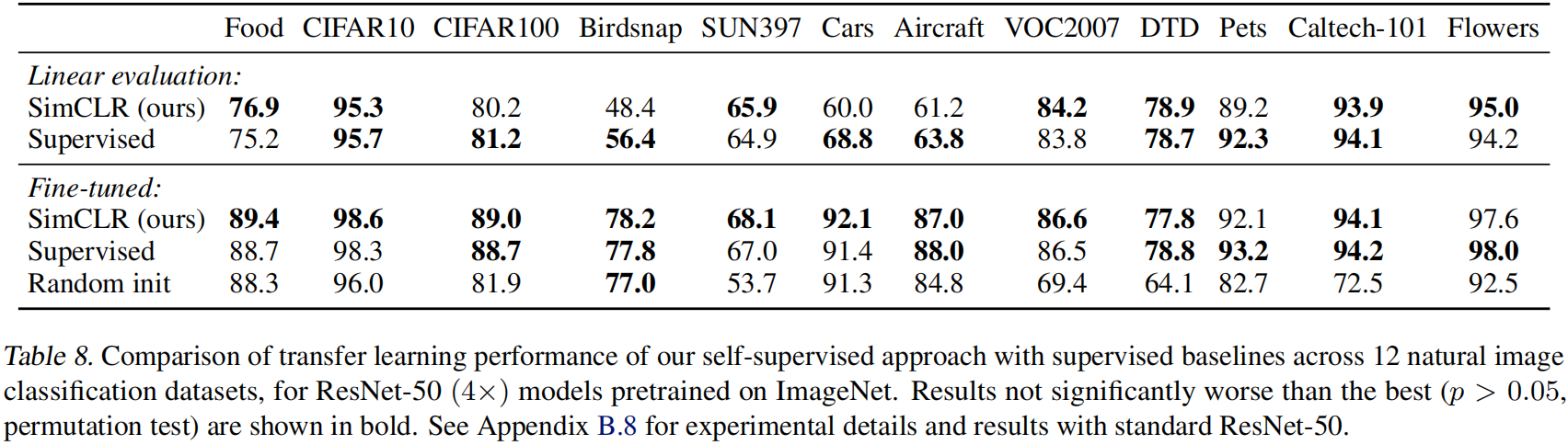
2.1 B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
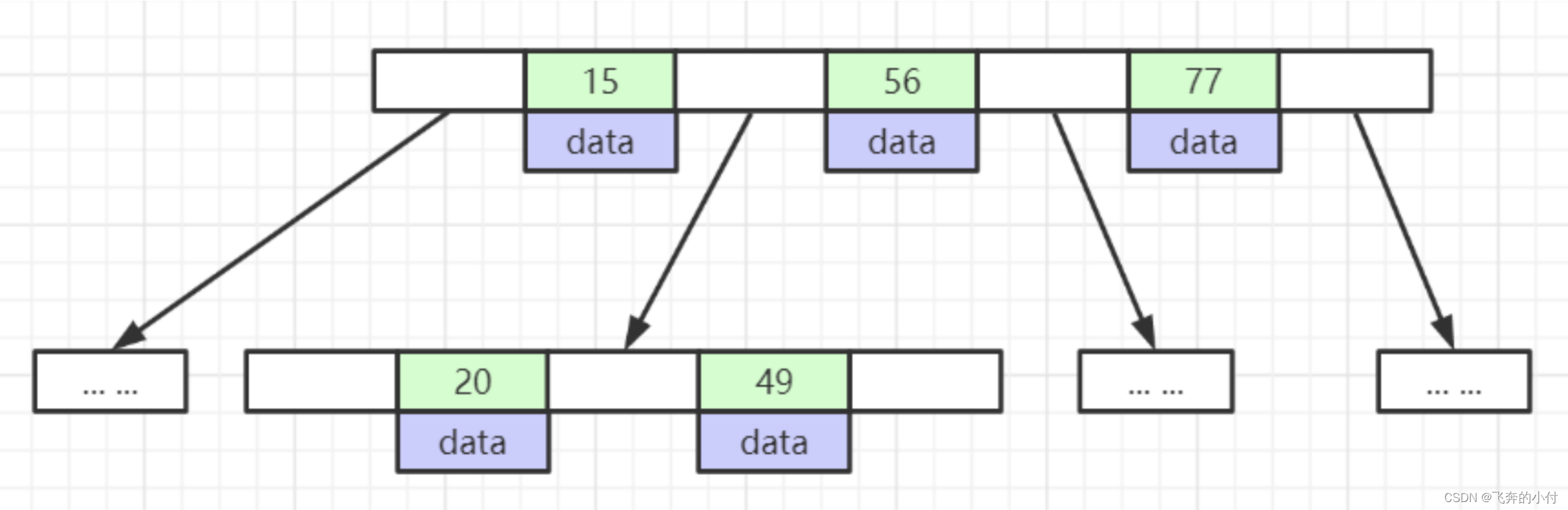
2.2 B+Tree
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
使用B+树结构 :一页数据大概16k,第一层大概16k/(8+6)=1170,第二层1170,第三层16k/1k=16,三层1170117016~2千多万;
使用B树结构:一页数据大概16k,第一层大概16k/1k=16,第二层也是16…相同数据量如果使用B-tree则层数会很多,层数越少,遍历越少,I/O操作越少,效率越高,所以使用B+树效率更高
2.3 Hash结构
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+ 树索引更高效
- 仅能满足 “=”,“IN”,不支持范围查询
- hash冲突问题
三.存储引擎
3.1 MylSAM存储引擎索引实现
MyISAM索引文件和数据文件是分离的(非聚集), 数据在MYD文件,索引在MYI文件
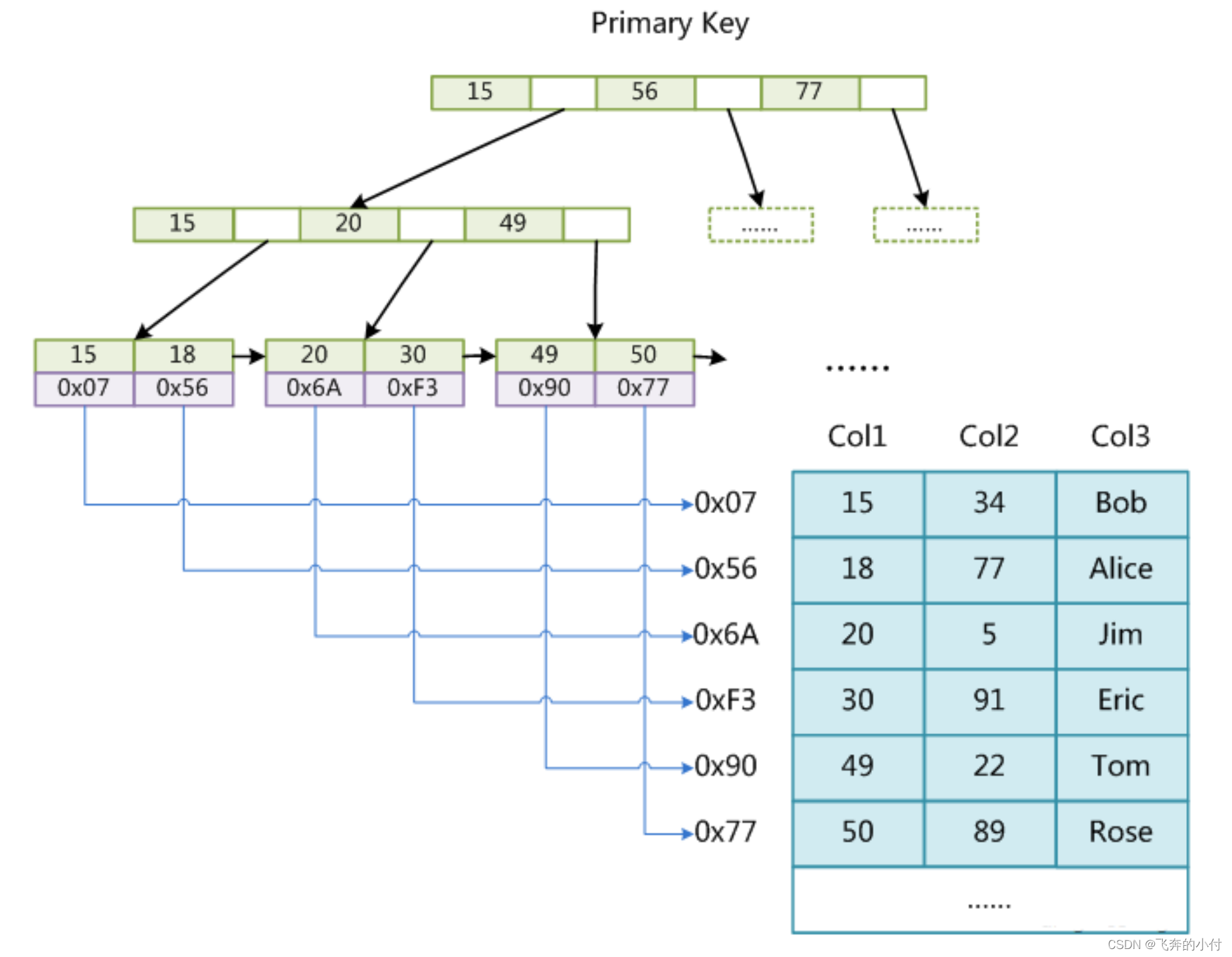
3.2 InnoDB存储引擎索引实现
- InnoDB索引实现(聚集) 索引和数据在一起存储在IBD文件
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
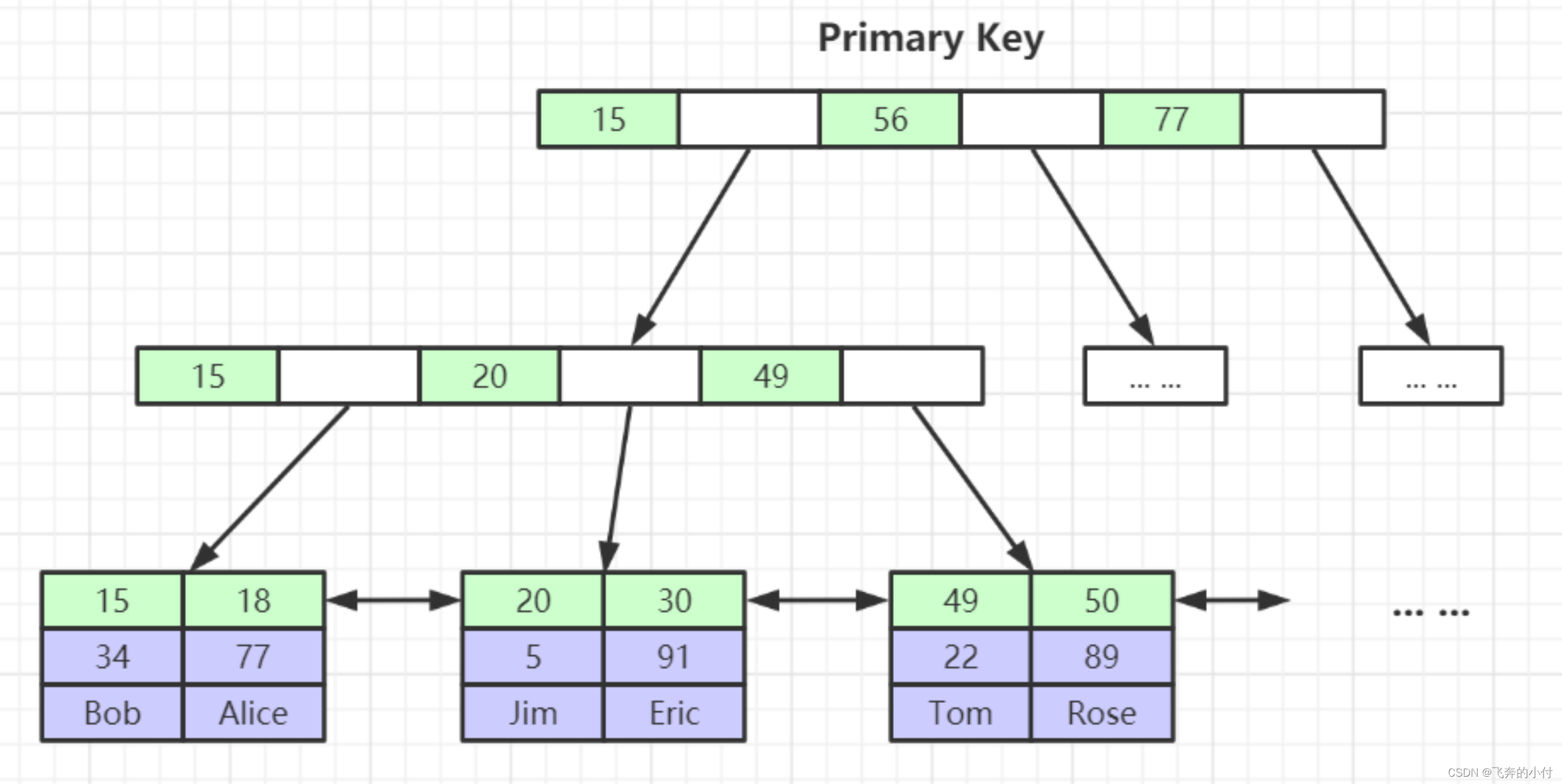
二级索引里数据存放的是主键索引中的聚集索引(有主键就是主键id,没主键就是rowId)
四.联合索引
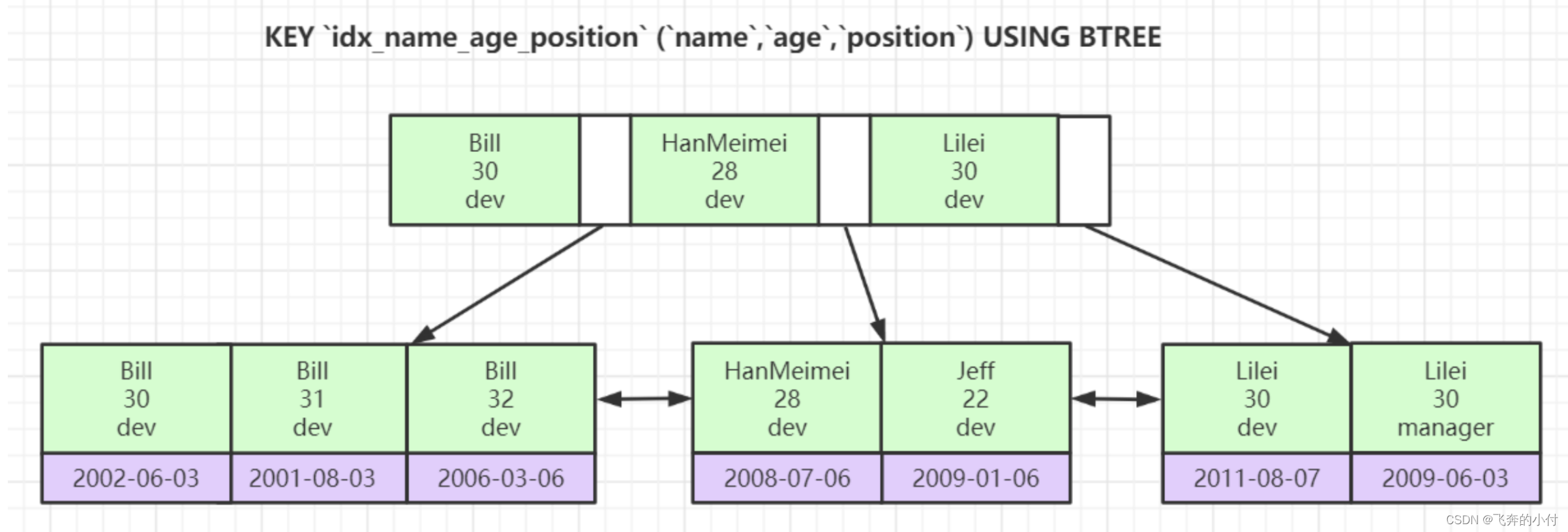
联合索引是按照索引字段排序的,先根据第一个元素查找,再根据第二个元素查找… 最左匹配原则,只有从左到右索引都匹配时才会执行右边的索引。
加入index(a,b,c)
| where语句 | 索引是否被使用 |
|---|---|
| where a=3 | Y,使用到a |
| where a=3 and b=5 | Y,使用到a,b |
| where a=3 and b=5 and c=4 | Y,使用到a,b,c |
| where b=3 或者 b=3 and c=4 或者c=4 | N |
| where a=3 and c=4 或者c=4 | Y,使用到a,不可以使用c |
| where a=3 and b>4 and c=5 | Y,使用到a和b,不可以使用c,因为b断了,c不可使用在范围后 |
| where a=3 and b like ‘kk%’ and c=4 | Y,使用到a,b,c |
| where a=3 and b like ‘%kk’ and c=4 | Y,使用到a |
| where a=3 and b like ‘%kk%’ and c=4 | Y,使用到a |
| where a=3 and b like ‘k%kk%’ and c=4 | Y,使用到a,b,c |
五.相关问题
5.1 为什么建议InnoDB表必须建主键?
如果不建主键,innodb就没有聚簇索引去组织数据,数据怎么存放没办法管理,如果没有建主键,mysql会主动去查找一个所有值都是唯一的列字段作为唯一索引。如果遍历完没有找到可以适合做主键的列,mysql就会创建隐藏的列rowId,作为唯一索引来维护整个表。如果你自己创建了主键索引,mysql就不用去查找唯一列,mysql资源比较紧张。
5.2 推荐使用整型的自增主键?
- 查找效率高。查询数据时会逐位比对,如果是顺序递增的话,速度比较快;
- 节省空间。整型要比字符串省空间;
- 非自增主键,如果插入中间的数据 就可能会导致分裂,分裂之后再重新平衡树,如果是自增主键,就会一直只在后面插入就行。
5.3 为什么非主键索引结构叶子节点存储的是主键值?
主要是为了节省存储空间,不用把整条数据都存储起来。
5.4 MylSAM存储引擎和innodb存储引擎是形容数据库还是形容数据库表呢?
是形容数据库表的


![[LeetCode周赛复盘] 第 329 场周赛20230122](https://img-blog.csdnimg.cn/b66cc45759404ae0976081c19c9c3e77.png)