目录
1.认识文件
2.文件的类型
3.java对文件的操作
针对文件系统操作
针对文件内容操作
字节流
字符流
字节流的使用
字符流的使用
4.文件IO小程序练习
示例1
示例2
1.认识文件
狭义的文件指的是硬盘上的文件和目录
广义的文件泛指计算机中的很多的软硬件资源,操作系统中,把很多的硬件设备和软件资源抽象成了文件,按照文件的方式来统一管理
这里我们只讨论狭义的文件,就是硬盘上的数据
代码中存储数据是靠变量,变量是存储在内存中的,现在的文件是存储在硬盘上的
树形结构组织和目录
文件很多的情况下,在对文件进行管理的时候,采用了我们学过的数据结构--树形结构.
文件夹(folder)和目录(directory)中保存的就是我们所说的关于文件的元信息,通过一个个文件夹将文件组织起来,方便使用

文件路径
绝对路径
每个文件在硬盘上都有一个具体的"路径",从树型结构的角度来看,树的每个节点都可以从一条根开始,一直到达的节点的路径所描述,这种描述方式就是文件的绝对路径(absolute path)
表示一个文件的具体位置路径,就可以使用 /(斜杠)来分割不同的目录级别

我们查看.png文件的路径
![]()
这里的路径是用\来分割的路径
(/)斜杠和(\)反斜杠有什么区别呢
建议使用斜杠来分割目录级别.String path = "d:\epic",此时\c就会被当成转义字符了,就不是\本身了,得写成"d:\\epic",如果写正斜杠,就不会出现问题,并且各种系统都支持.
![]()
可以用D:/Epic Games来描述位置,能识别出来,但是我们查看路径是反斜杠
![]()
CDE这样的盘符是通过"硬盘分区"来的,每个盘符可以是一个单独的硬盘,也可以是若干个盘符对应一个硬盘
文件的相对路径:以当前所在的目录为基准,以.或者..开头(.有时候省略),找到指定的路径
当前所在的目录称为工作目录,每个程序运行的时候,都有一个工作目录,(在控制台里通过命令操作的时候是很明显的)
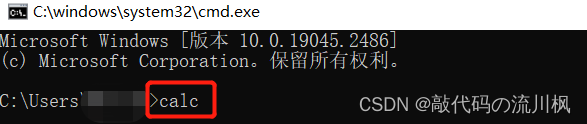
我们在命令行下直接输入某个程序的名字,本质上是操作系统去PATH环境变量里查找的.calc本身就在PATH下,可有直接运行,我们自己装的程序,需要把路径加到PATH中后就可以运行了

现在我们都是使用图形界面,工作目录就不太直观了

这就是默认的工作路径

切换成D盘为工作路径
相对路径就是由工作路径为基准
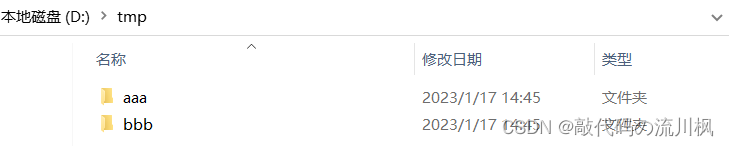
我们假设当前的工作目录为D:/tmp,那么定位到aaa这个目录,就可以表示为./aaa(./就表示当前的目录),定位到bbb就是./bbb
如果工作目录不同,定位到同一个文件,相对路径写法是不同的
同样定位到aaa
如果工作目录是D:/,相对路径写作./tmp/aaa
如果工作目录是D:/tmp,相对路径写作./aaa
如果工作目录是D:/tmp/bbb,相对路径写作../aaa(..表示当前目录的上级目录)
Linux没有盘符的概念,统一使用cd切换.windows需要先定位到盘符,再cd在当前盘符下切换
我们使用的IDEA的工作路径就是当前项目所在的目录,如果代码中写了一些相对路径的代码,工作路径就是以项目路径为基准的

2.文件的类型
不同的文件整体可以归类为两类:
文本文件
存的是文本,字符串,字符串是由字符构成的,每个字符都是通过一个数字来表示的,这个文本文件里存储的数据,一定是合法字符,都是在指定字符编码的码表之内的数据
二进制文件
没有任何限制,可以存储任何数据
给一个文件,如何区分是文本还是二进制文件呢?
可以使用记事本打开,如果是乱码,就是二进制文件,没乱就是文本文件,因为记事本是默认文本打开的
实际写代码中,这两类文件的处理方式略有差别
3.java对文件的操作
针对文件系统操作
Java提供了一个File类
属性
| 修饰符及类型 | 属性 | 说明 |
| static String | pathSeparator | 依赖于系统的路径分隔符,String 类型的表示 |
| static char | pathSeparator | 依赖于系统的路径分隔符,char 类型的表示 |
pathSeparator是File中的一个静态变量,就是相当于/或者\,用来分割的,方便多平台使用
构造方法
| 签名 | 说明 |
| File(File parent,String child) | 根据父目录+孩子文件路径创建一个新的 File 实例 |
| File(String pathname) | 根据文件路径创建一个新的 File 实例,路径可以是绝对路径或者 相对路径 |
| File(String parent, String child) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例,父目录用 路径表示 |
这里传入绝对路径或者相对路径都可以
parent表示当前文件所在目录,child表示自身的文件名
例如D:/tmp
parent:D:/
child:tmp
第二个比较常用File(String pathname),直接传入路径创建文件
方法
| 修饰符及返回 值类型 | 方法签名 | 说明 |
| String | getParent() | 返回 File 对象的父目录文件路径 |
| String | getName() | 返回 FIle 对象的纯文件名称 |
| String | getPath() | 返回 File 对象的文件路径 |
| String | getAbsolutePath() | 返回 File 对象的绝对路径 |
| String | getCanonicalPath() | 返回 File 对象的修饰过的绝对路径 |
| boolean | exists() | 判断 File 对象描述的文件是否真实存在 |
| boolean | isDirectory() | 判断 File 对象代表的文件是否是一个目录 |
| boolean | isFile() | 判断 File 对象代表的文件是否是一个普通文件 |
| boolean | createNewFile() | 根据 File 对象,自动创建一个空文件。成功创建后返 回 true |
| boolean | delete() | 根据 File 对象,删除该文件。成功删除后返回 true |
| void | deleteOnExit() | 根据 File 对象,标注文件将被删除,删除动作会到 JVM 运行结束时才会进行 |
| String[] | list() | 返回 File 对象代表的目录下的所有文件名 |
| File[] | listFiles() | 返回 File 对象代表的目录下的所有文件,以 File 对象 表示 |
| boolean | mkdir() | 创建 File 对象代表的目录 |
| boolean | mkdirs() | 创建 File 对象代表的目录,如果必要,会创建中间目 录 |
| boolean | renameTo(File dest) | 进行文件改名,也可以视为我们平时的剪切、粘贴操 作 |
| boolean | canRead() | 判断用户是否对文件有可读权限 |
| boolean | canWrite() | 判断用户是否对文件有可写权限 |
我们来看几组方法的使用:
File file = new File("d:/test.txt");构造的这个文件对象的路径不一定要真实存在,不存在,file会有相关方法创建出来(createNewFile)
public static void main(String[] args) throws IOException {File file = new File("d:/test.txt");System.out.println(file.getName());System.out.println(file.getParent());System.out.println(file.getPath());System.out.println(file.getAbsolutePath());System.out.println(file.getCanonicalPath());} 
这里看不出什么差异
将d:/换成./,就不同了.因为./是相对路径,这里的工作路径就是我们IDEA中项目的路径
![]()
看结果

我们可以看出来绝对路径是在相对路径的基础上拼接了工作路径
getCanonicalPath()得到的是化简后的绝对路径,./省略了
public class IO2 {public static void main(String[] args) {File file = new File("d:/test.txt");//文件是否存在System.out.println(file.exists());//是否是文件System.out.println(file.isFile());//判断 File 对象代表的文件是否是一个目录System.out.println(file.isDirectory());}
}
我们在D盘下创建test文件后运行程序
将d:/换成./,就不同了.因为该项目路径下没有这个文件,既不是文件也没有目录
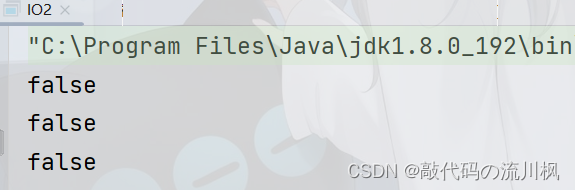
但是我们可以创建文件,创建文件后执行程序
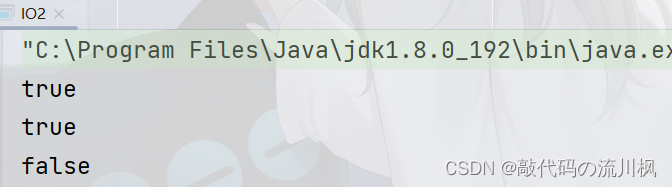
在项目目录下也能找到我们创建的文件
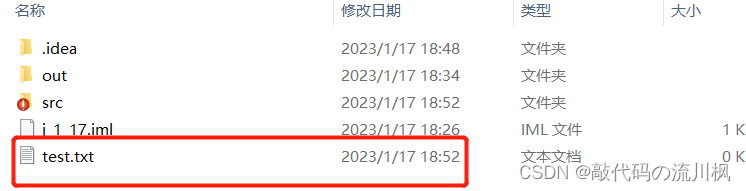
我们使用方法删除test文件
public class IO3 {public static void main(String[] args) {File file = new File("./test.txt");file.delete();}
}
删除成功

deleteOnExit()这个方法是程序退出后删除
适用于临时文件,程序退出后就删除了
public class IO4 {public static void main(String[] args) {File file = new File("./test");//创建目录file.mkdir();//创建多级目录//file.mkdirs();}
}
file.mkdirs()创建多级目录,mkdir只能创建一级目录
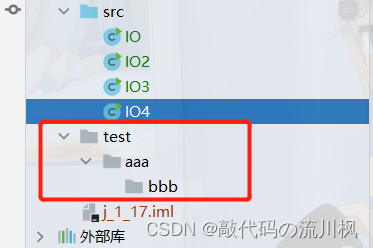
public class IO5 {public static void main(String[] args) {File file = new File("./test");File dest = new File("./testAA");file.renameTo(dest);}
} 
renameTo更改了文件名
针对文件内容操作
针对文件内容,我们使用"流对象"进行操作的,这个比喻并非是Java独有的,操作系统api就是这样设定的,进一步的各种编程语言,操作文件也继承了这个概念
Java标准库的流对象从类型上分为两类,每个类又有几个不同的功能的类
字节流
字节流是操作二进制文件的
InputStream
FileInputStream
OutputStream
FileOutputStream
字符流
字符流是操作文本文件的
Reader FileReader
Writer FileWriter
这些类的使用方式非常固定
核心有四个操作
1.打开文件(构造对象)
2.关闭文件(close)
3.读文件(read)针对InputStream /Reader
4.写文件(writer)针对OutputStream /Writer
字节流的使用
我们来看这个代码,使用字节流读取文本文件:
public class IO6 {public static void main(String[] args) throws IOException {//绝对路径,相对路径,File对象都可以//FileNotFoundException是IOException的子类,如果想要打开一个文件去读//但是必须保证这个文件是存在的,否则会出异常InputStream inputStream = new FileInputStream("d:test.txt");//进行操作while(true){int b = inputStream.read();if(b == -1){//读取完毕break;}System.out.println(""+(byte)b);}inputStream.close();}
}

InputStream /OutputStream /Reader/Writer 这几个类都是抽象类,不能直接实例化
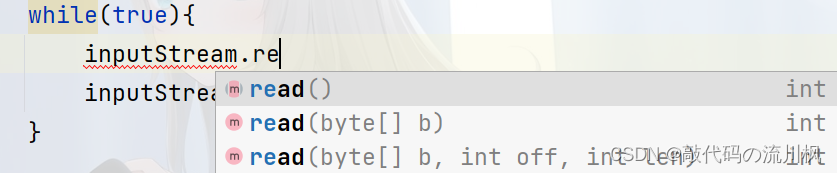
read有三个版本,无参版本一次读一个字节.一个参数版本:把读到的内容填充到参数的这个字节数组中(此处的参数是输出型参数,返回值是实际读取的字节数)
三个参数版本:和一个参数版本类似,只不过往数组的一部分区间里尽可能填充

返回值为int, read读的是一个字节,返回一个byte就可以,但是实际上返回的是int,除了要表示byte的0~255(-128~127)这样的情况,还要表示一个特殊情况,-1表示读取文件结束了(读到文件末尾了),但是byte就没有多余空间表示这个非法值了,所以需要用int作为返回值,拿到的int可以强转byte
运行程序,结果

可以看到读的每个字节都是数字,这些数字就是美国信息交换标准代码(ASCII),对照后就是hello .
如果将test中内容改为中文

这些数字就表示"你好"这两个字的编码方式,如果按十六进制打印,
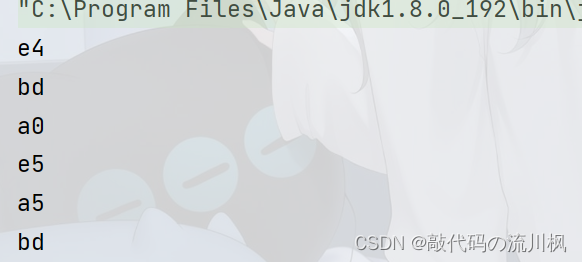
这里使用的是utf8的,对照utf8码表

这里的txt文件是文本文件,使用字节流也能读,但是不方便,更希望使用字符流读,就更方便了
上述使用的是read的第一个版本,无参的.接下来使用一个参数的版本
while(true){byte[] buffer = new byte[1024];int len = inputStream.read(buffer);System.out.println("len = "+len);if(len == -1){break;}for (int i = 0; i < len; i++) {System.out.printf("%x\n",buffer[i]);}}
read的第二个版本需要提前准备一个数组,传参操作就相当于把刚才准备好的数组交给read来填充,此处参数相当于"输出型参数",Java中习惯使用输入的信息作为参数,输出的信息作为返回值,但是也有少数情况,使用参数来返回内容.
要注意理解read的行为和返回值.read会尽可能的把传进来的数组给填满,上面给到的数组是1024,read就会尽可能的读取1024个字节,如果文件的剩余长度超过1024,此时1024个字节都会被填满,返回值就是1024,如果当前的文件不足1024,那么读取多少就会返回多少.read方法就是返回当前实际读取的长度.
如果超过1024了,就会循环下一轮继续读,我们把test文件中多放点内容然后运行程序
![]()

整个文件是13k,因此需要多次循环read,由于数组长度是1024,所以前面每次read读到的长度都是1024,最后一轮只剩122字节了.数据不足1024了,实际能读到多少字节,就读多少字节,不同的文件最后一次剩余的也不同,读完122就是文件末尾了,再下一轮循环,没有内容可读,返回-1,循环结束.
文件是在磁盘上的,有的文件内容可能会很多,甚至超出内存的上限,有时想把整个文件读取到内存在处理不一定行,一般都是一边读一边处理,处理好了一部分,再处理下一个部分..
再来看一个问题
byte[] buffer
我们为啥起名叫buffer
buffer叫做"缓冲区",存在的意义就是提高IO的效率,单次IO操作,是要访问硬盘/IO设备,单次操作是比较消耗时间的,如果频繁的IO操作,耗时肯定就多了.
单次IO时间是一定的,如果能缩短IO的次数,此时就可以提高程序整体的效率了,第一个版本的代码是一次读一个字节,循环次数比较多,read次数也多,第二个版本是一次读1024个字节,循环次数降低很多,read次数也变少了..缓冲区就是缓和了冲突,减小访问的次数.
使用了InputStream来读文件 ,还可以使用OutputStream 写文件.
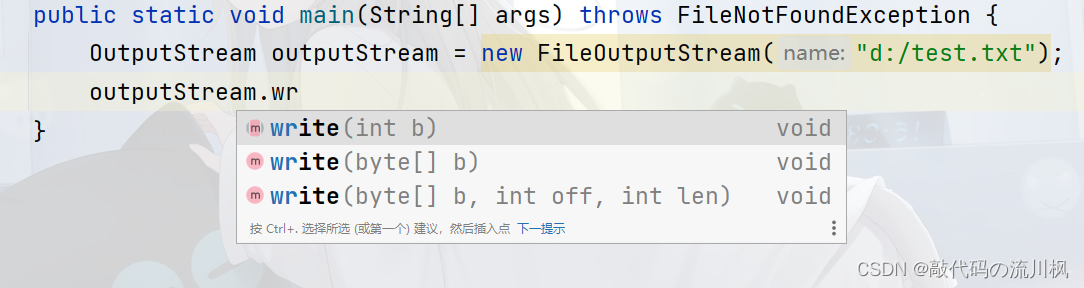
写方法有三个版本,第一个版本是一次写一个字节,范围是0~255,和read是相同的.
第二个版本是准备一个数组,然后一次写到数组中去
第三个版本是从数组的off下标开始写到len结束
public class IO7 {public static void main(String[] args) throws IOException {OutputStream outputStream = new FileOutputStream("d:/test.txt");outputStream.write(97);outputStream.write(98);outputStream.write(99);outputStream.write(100);outputStream.close();}
}执行程序后打开文件

我们之前写进去的内容已经被清空了,然后写入了abcd
对于OutputStream默认情况下,打开一个文件,会先清空文件原有的内容,这样的话,之前我们放进去的内容就没有了
如果不希望清空,流对象还提供了一个"追加写"对象,通过这个对象可以不清空文件,把新内容追加到后面
还要注意:input和output的方向,input不应该是输入的意思吗,那应该对应的是写文件啊,为什么是读文件呢..
这里input和output是基于CPU的方向

内存更接近CPU,硬盘离CPU更远,CPU是一台计算机最核心的部分,相当于人的大脑
以CPU为中心,朝着CPU的方向流向,就是输入.所以把数据从硬盘到内存这个过程称为读,input
数据远离CPU方向流向,就是输出,所以把数据从CPU到硬盘这个过程称为写,output.
outputStream.close();
这里的close操作,含义是关闭文件
之前所说的进程,在内核里,使用PCB这样的数据结构来表示进程,一个线程对应一个PCB,一个进程可以对应一个或多个PCB
PCB中有一个重要的属性,文件描述符表(相当于一个数组)记录了该进程打开了哪些文件
即使一个进程有多个线程,多个PCB,这些PCB还是共用一个文件描述符表
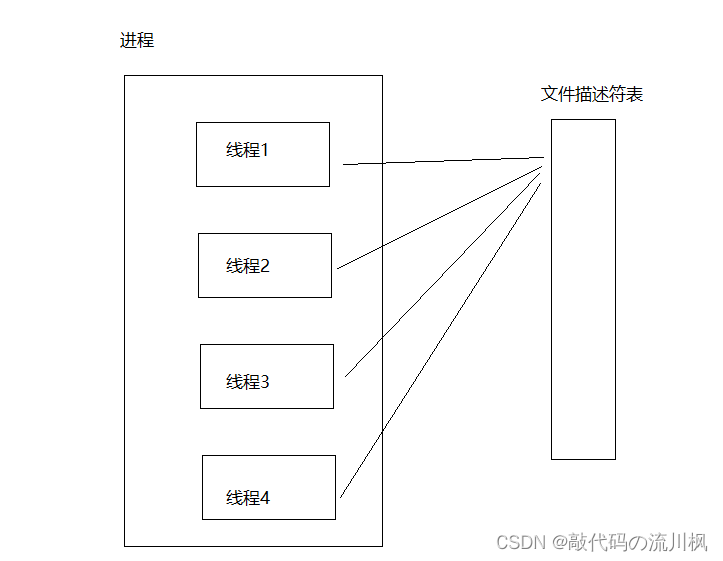
文件描述符表中的每个元素,都是内核里的一个file_struct对象,这个对象就表示一个打开了的文件
每次打开文件操作,就会在文件描述符表中申请一个位置,把这个信息记录进去,每次关闭文件,就会把这个文件描述符表对应的表项给释放掉
outputStream.close();起到的作用就是释放对应的表项,如果这个代码没写或者没执行到
那么文件描述符表中的表项就没有及时释放,GC操作会在回收这个outputStream对象的时候去完成这个释放操作,虽然GC会完成操作,但是不一定及时释放,因此如果不手动释放,当使用文件很多的情况下,文件描述符表会很快被占满,这个数组是不能扩容,存在上限的,如果被占满了,再次打开文件,就会打开失败!!文件描述符表最大长度对于不同的系统不太一样,但是基本都是几百至几千左右
close一般来说是要执行的,但是如果一个程序,这里的文件自始至终都要用,不关闭问题也不大,因为程序一结束,整个进程都会结束,对应的资源都会被操作系统回收了,也就是说,如果close之后程序就结束了,那么不手动释放资源也没事!
当然我们一般写代码中还是要close的,那么如何保证close一定被执行呢?
这是推荐写法
public static void main(String[] args) throws IOException {try(OutputStream outputStream = new FileOutputStream("d:/test.txt");){outputStream.write(97);outputStream.write(98);outputStream.write(99);outputStream.write(100);}}这个写法虽然没有显式的写close.但是实际上是会执行的,只要try语句执行完毕,就可以自动执行到close!!
这个语法叫做:try with resources
那么这个语法能针对锁执行完了就释放吗?显然不是的,这个语法不是随便一个对象放到try()中就可以自动释放的!需要满足一定的要求
![]()
可以看到这个outputstream实现了closeable类,所以只有实现了这个接口的类才能自动释放,这个接口提供的方法就是close方法
以上是关于字节流的使用
字符流的使用
字符流的使用和字节流是相似的,我们演示一下方法
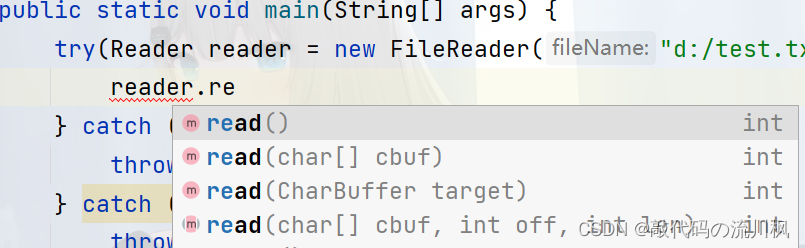
第一个版本是一次返回一个char类型字符,第二个版本是返回一个字符数组,第三个版本是相当于对第二个字符数组封装了,最后一个版本是返回一个从off到len 的字符数组
public static void main(String[] args) {try(Reader reader = new FileReader("d:/test.txt")){while(true){int ch = reader.read();if(ch ==-1){break;}System.out.println(""+(char) ch);}} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}结果:

我们把test内容换成中文"你好"后运行程序
也是一次打印一个字符
写操作也是类似的
public class IO9 {public static void main(String[] args) {try(Writer writer = new FileWriter("d:/test.txt")){writer.write("hello");} catch (IOException e) {throw new RuntimeException(e);}}
}
有时候我们发现写的内容没在真的文件中存在,很大可能是缓冲区的问题
writer.write("hello");
像这样的写操作是先写到缓冲区,缓冲区是有很多的形态(代码中,操作系统内核,标准库),写操作执行完了,内容可能在缓冲区里,还没真正进入硬盘,close操作就会触发缓冲区的冲刷(flush),刷新操作其实就是把缓冲区的操作写到硬盘中..除了close之外,还能通过flush方法,也能起到刷新缓冲区的效果
Scanner也是搭配流对象使用的
Scanner scanner = new Scanner(System.in);System.in
其实就是一个输入流对象,字节流,看看源码

这里Scanner scanner = new Scanner(System.in);的System.in是指向标准输入的流对象,就从键盘读取,如果指向的是一个文件流对象,就从文件读
public class IO10 {public static void main(String[] args) {//Scanner scanner = new Scanner(System.in);try(InputStream inputStream = new FileInputStream("d:test.txt")){Scanner scanner = new Scanner(inputStream);//这里读取的内容就是从文件进行读取了scanner.next();} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}
}
Scanner的close本质上是要关闭内部包含的这个流对象,此时,内部的inputStream对象已经被try()关闭了,里面的Scanner不关闭也没事,但是如果 内部的inputStream对象没有关闭,那么就要关闭内部包含的这个流对象
4.文件IO小程序练习
接下来我们写几个小程序,练习文件的基本操作 + 文件内容读写操作
示例1
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要 删除该文件
也就是给定一个目录,目录里包含很多的文件和子目录,用户输入一个要查询的词,如果目录下(包含子目录)有匹配的结果(文件名)就进行删除
import java.io.File;
import java.util.Scanner;public class IO11 {private static Scanner scanner = new Scanner(System.in);public static void main(String[] args) {//输入目录//Scanner scanner = new Scanner(System.in);System.out.println("请输入要搜索的路径");String basePath = scanner.next();//针对输入进行判定File root = new File(basePath);if(!root.isDirectory()){//如果路径不存在,或者只有一个普通文件,此时无法进行搜索System.out.println("输入的路径有误");return;}//再让用户输入一个要删除的文件名System.out.println("请输入要删除的文件名:");//此处用next,不用nextLineString nameToDelete = scanner.next();/*针对指定的路径进行扫描.递归操作先从根目录出发(root)先制定一下,当前这个目录里看看是否有要删除的文件,如果是就删除,如果不是就跳过下一个如果这里包含了一些目录,在针对子目录进行递归*/scanDir(root,nameToDelete);}private static void scanDir(File root, String nameToDelete) {//列出当前目录包含的内容File[] f = root.listFiles();//相当于打开文件资源管理器,打开了一个目录一样if(f == null){//空目录return;}//遍历当前的列出结果for (File files: f) {if(files.isDirectory()){//是目录就进一步递归scanDir(files,nameToDelete);}else {//不是目录,判定是否删除if(files.getName().contains(nameToDelete)){System.out.println("是否要删除: "+files.getName()+"?");String choice = scanner.next();if(choice.equals("y")||choice.equals("Y")){files.delete();System.out.println("删除成功");}else {System.out.println("删除取消");}}}}}
}

执行程序后
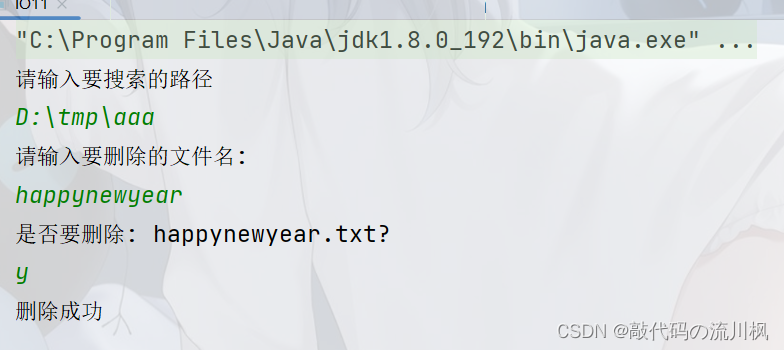

在函数中加上扫描路径的打印


示例2
进行普通文件的复制
把一个文件拷贝成另一个文件
import java.io.*;
import java.util.Scanner;public class IO12 {public static void main(String[] args) {Scanner sc = new Scanner(System.in);//输入两个路径System.out.println("输入要拷贝的文件:");String srcPath = sc.next();System.out.println("输入要拷贝的路径:");String destPath = sc.next();File srcFile = new File(srcPath);if(!srcFile.isFile()){//不是一个文件(是个目录或不存在),不做操作System.out.println("输入的源路径有误");return;}File destFile = new File(destPath);if(destFile.isFile()){//如果目标文件已经存在,不能拷贝System.out.println("输入的目标路径有误");return;}//进行拷贝try(InputStream inputStream = new FileInputStream(srcFile);OutputStream outputStream = new FileOutputStream(destFile)) {while(true){int b = inputStream.read();if(b ==-1){return;}outputStream.write(b);}} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}
}

try with resources语法支持包含多个流对象,多个流对象之间用分号隔开就行
我们将d:/tmp/aaa的文件111拷贝到d:/tmp/bbb中去
源路径
 目标路径
目标路径

执行程序后
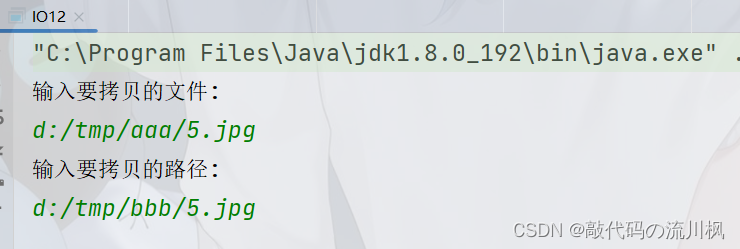
拷贝成功
文件章节到这里就结束了
祝各位大佬新年快乐!新年胜旧年,兔年"兔飞猛进"~~