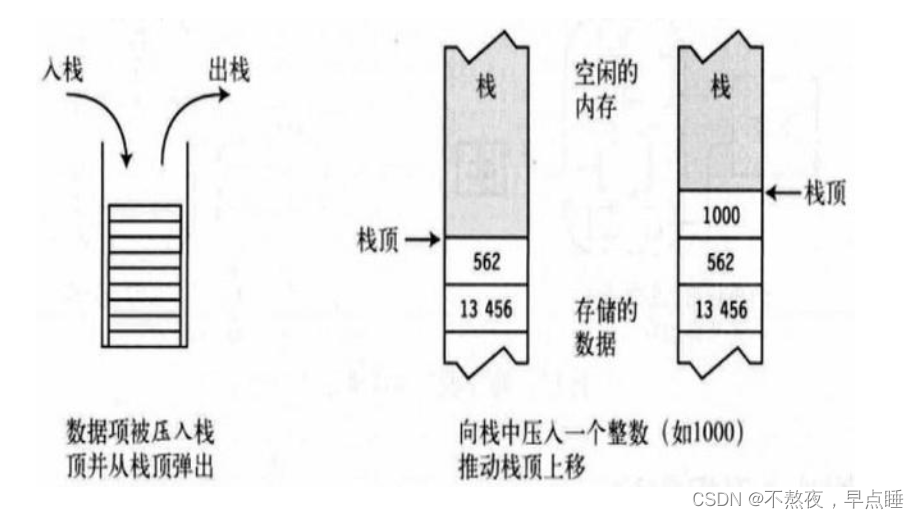
堆栈
在片内RAM中,常常要指定一个专门的区域来存放某些特别的数据
它遵循顺序存取和后进先出(LIFO/FILO)的原则,这个RAM区叫堆栈。
其实堆栈就是单片机中的一些存储单元,这些存储单元被指定保存一些特殊信息,比如地址(保护断点)和数据(保护现场)。
堆栈特点
1、这些存储单元中的内容都是程序执行过程中被中断打断时,事故现场的一些相关参数。如果不保存这些参数,单片机执行完中断函数后就无法回到主程序继续执行了。
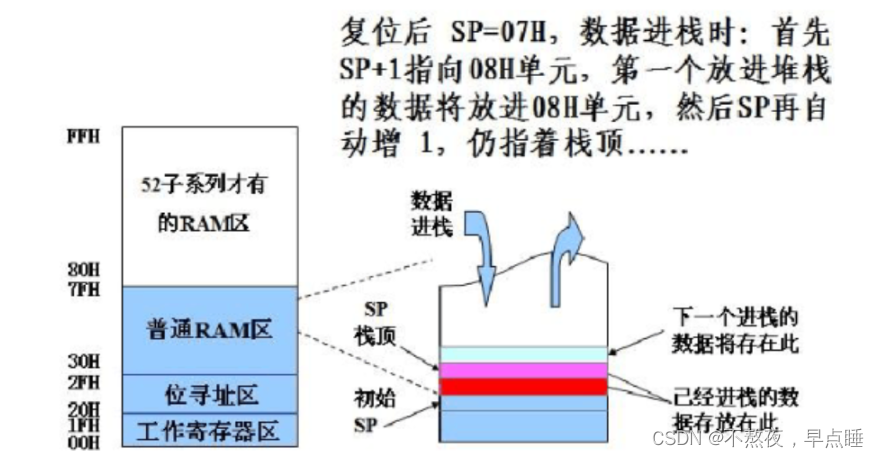
2、这些存储单元的地址被记在了一个叫做堆栈指针(SP)的地方。
3、栈是从高到低分配,堆是从低到高分配。
堆栈分类
我们一般说的堆栈指的栈。堆栈又分硬堆栈和软堆栈,硬堆栈即SP,从片内RAM的顶部向下生长。软堆栈在硬堆栈跟全局变量区之间的空间,C51函数调用通过R0-R7和栈来实现。
堆栈作用
1)子程序调用和中断服务时CPU自动将当前PC值压栈保存,返回时自
动将PC值弹栈。
2)保护现场/恢复现场
3)数据传输
堆栈原理:
由上述可见:SP的内容就是栈顶单元的地址。
堆栈的操作:入栈和出栈
入栈:PUAH DIRECT
功能:先SP+1→SP,(DIRECT)→((SP))
设(SP)-60H,则执行指令PUSH Acc后,·SP)=6H,(61H)=(Acc)
即将累加器A的内容如栈了。
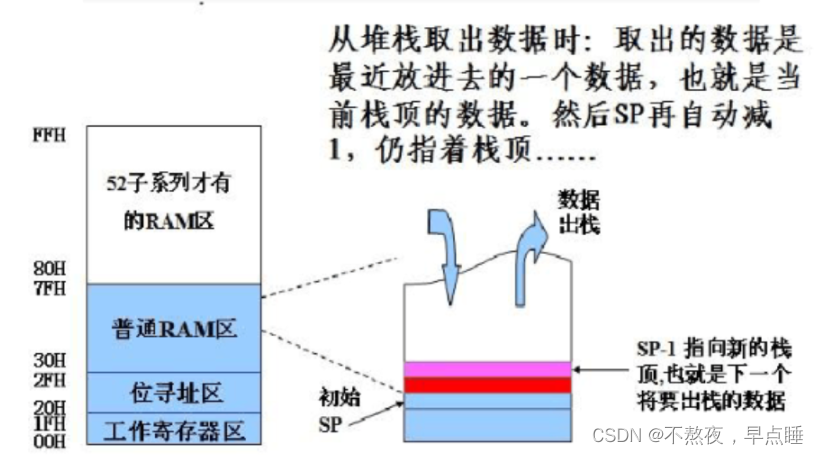
出栈:POP DIRECT
功能:先(DIRECT)→((SP),SP-1→SP
用法同上。
注:上述操作主要用于子程序和中断服务子程序中的现场保护。而断
点保护是由硬件自动完成的。
堆栈操作由PUSH,POP两条指令来完成;
堆栈操作的操作数均为子类型(两个字节)进行操作。
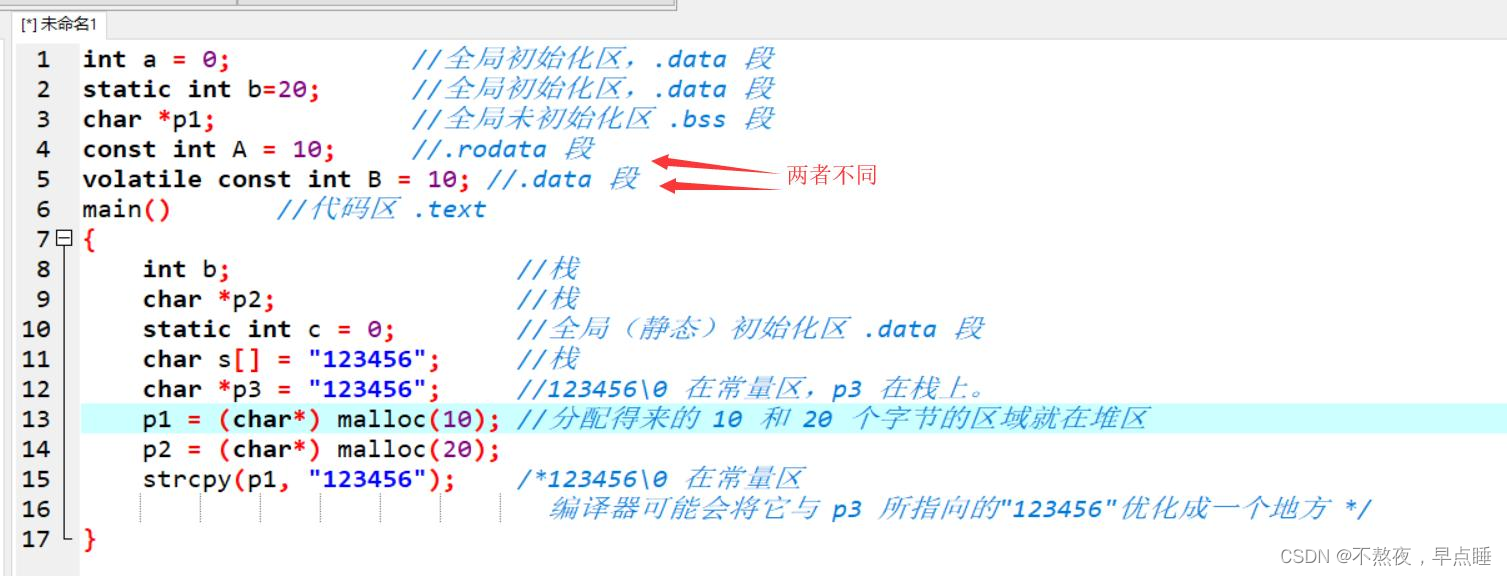
程序内存可以分为几个区,栈区(stack),堆区(Heap),全局区(static),文字常亮区,程序代码区。

一个进程运行时,所占用的内存,可以分为如下几个部分:
1、栈区(stack):由编译器自动分配释放,存放函数的参数值,局部变量的值等。
2、堆区(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS释放。
3、全局变量、静态变量:初始化的全局变量和静态变量放在一块区域,未初始化的全局变量和和未初始化的静态变量在相邻的的另一块区域。程序结束后由系统自动释放。
4、文字常量:常量字符串就是存放在这里的,程序结束后由系统释放。
5、程序代码:存放函数体的二进制代码。
经典例子:
在MDK编译环境下,可在map文件的"Memory Map of the image"–>"Execution Region RW_IRAM1"内容中查看程序的RAM占用及分配情况,如下
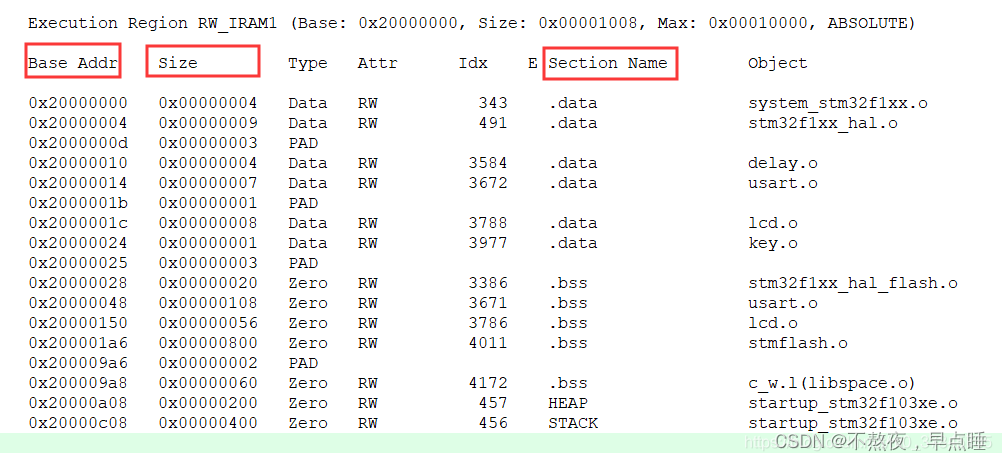
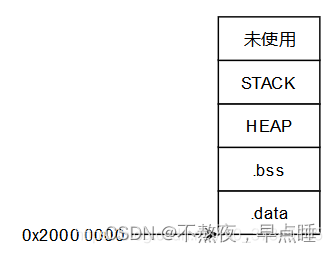
不知道你是否有点明白了,堆和栈的第一个区别就是申请方式不同:栈(英文名称是stack)是系统自动分配空间的,例如我们定义一个 char a;系统会自动在栈上为其开辟空间。而堆(英文名称是heap)则是程序员根据需要自己申请的空间,例如malloc(10);开辟十个字节的空间。由于栈上的空间是自动分配自动回收的,所以栈上的数据的生存周期只是在函数的运行过程中,运行后就释放掉,不可以再访问。而堆上的数据只要程序员不释放空间,就一直可以访问到,不过缺点是一旦忘记释放会造成内存泄露。
网上一个很好的比喻,摘抄下来,以便理解:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
STM32堆栈位置
此部分引用文章:如有侵权请联系作者删除
https://blog.csdn.net/m0_37845735/article/details/103301528
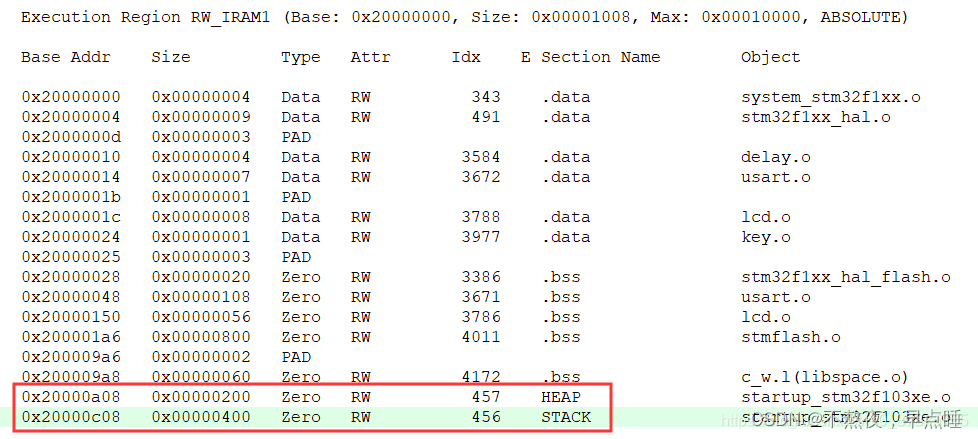
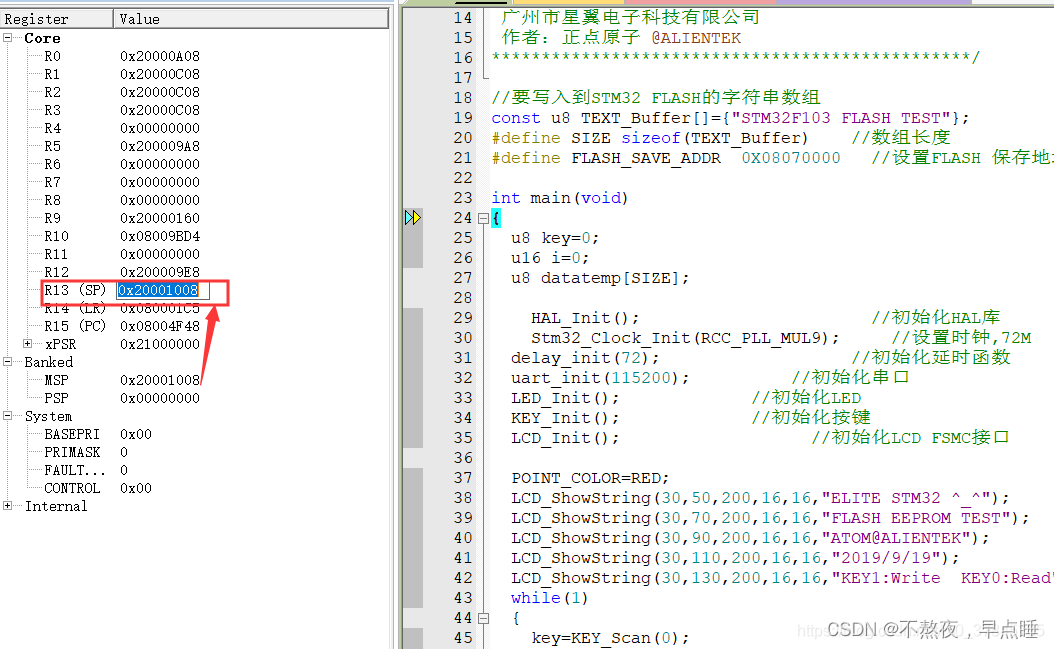
首先看一下STM32的地址空间映射【图三】,STM32的堆栈就是存放在片上静态SRAM中的,地址分配可以见Keil的编译map文件的"Memory Map of the image"【图四】;可见堆的地址为0x20000a08,大小为0x200,栈的地址为 0x20000c08,大小为0x400,可推算栈顶地址为:0x20000c08 + 0x400 = 0x20001008。而程序在刚运行的时候,主堆栈指针MSP指向的是程序所占用内存的最高地址【图五】,也就是栈的栈顶地址。

程序举例
栈是内存中一段连续的物理地址组成的一个后进先出(LF0)的数据结构,这种栈结构大小确定,满了就溢出,所以底部确定,被称为栈底,我们向里边写入数据被称为压栈(PUSH),读取数据被称为出栈(POP),我们每次POP都是拿栈的最后一个数据,被称为栈顶,栈底地址最大,因为每次从栈顶拿数据,可以减少寻址时间。
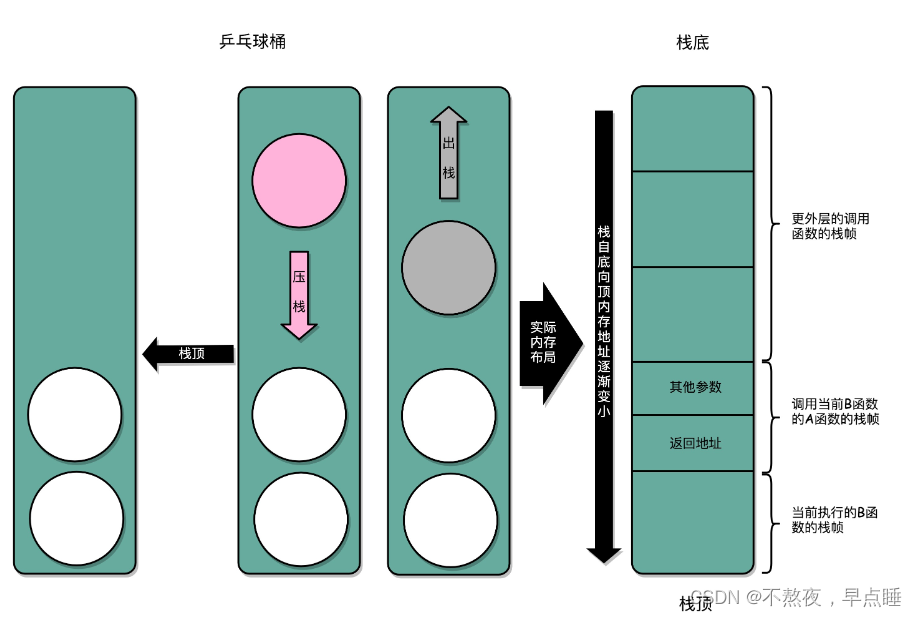
函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧(Stack Frame)。
以一段程序作为举例
int static add(int a, int b)
{return a+b;
}int main()
{int x = 5;int y = 10;int u = add(x, y);
}
汇编为
int static add(int a, int b)
{0: 55 push rbp1: 48 89 e5 mov rbp,rsp4: 89 7d fc mov DWORD PTR [rbp-0x4],edi7: 89 75 f8 mov DWORD PTR [rbp-0x8],esireturn a+b;a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]10: 01 d0 add eax,edx
}12: 5d pop rbp13: c3 ret
0000000000000014 <main>:
int main()
{14: 55 push rbp15: 48 89 e5 mov rbp,rsp18: 48 83 ec 10 sub rsp,0x10int x = 5;1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5int y = 10;23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xaint u = add(x, y);2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]30: 89 d6 mov esi,edx32: 89 c7 mov edi,eax34: e8 c7 ff ff ff call 0 <add>39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax3c: b8 00 00 00 00 mov eax,0x0
}41: c9 leave 42: c3 ret
这里需要先介绍几个专用的寄存器,简要介绍如下:
·ax(accumulator):可用于存放函数返回值
·bp(base pointer):用于存放执行中的函数对应的栈帧的栈底地址
·sp(stack poinger)):用于存放执行中的函数对应的栈帧的栈顶地址
·ip(instruction pointer):指向当前执行指令的下一条指令
从汇编代码中可以看出一个函数被c调用,首先默认要完成以下动作:
push rbpmov rbp,rsp
1将调用函数的栈帧栈底地址入栈,即保存调用函数的栈帧的栈底地址
2.建立新的栈帧,把rsp这个栈指针(Stack Pointer)的值复制到rbp里,并保存rsp的值,而
sp始终会指向栈顶。这个命令意味着,rbp这个栈帧指针指向的地址,变成当前最新的栈顶。
而调用结束栈帧出栈,跳转到方法调用方的调用位置的下一个位置,即call的下一行继续执行。
//以下两步等同于leave
mov rsp,rbp
pop rbp
//以下两步等同于ret
pop rip
jmp rip
所以一个完整的方法调用过程
调用方使用call指令调用方法,此时rip中存放的是call的下一条指令的地址,将rip压栈到栈底,生成新的栈帧,将栈帧压栈,执行方法,栈帧弹出,弹出rip,跳转到rip继续运行调用方的方法。
已知入栈顺序,总结出栈顺序的规律
引用文章https://blog.csdn.net/tiansheshouzuo/article/details/86604600
规律:
出栈的每一个元素的后面,其中比该元素先入栈的一定按照入栈逆顺序排列。
举例说明:
已知入栈顺序: 1 2 3 4 5
判断出栈顺序: 4 3 5 1 2
结果:不合理,原因是出栈元素3之后有 5 1 2 这三个元素,其中1 2 是比3先入栈的,根据规律,这两个出栈的顺序必须和入栈顺序相反,也就是 2 1 出栈,不可能按照1 2 顺序出栈。
已知入栈顺序: 1 2 3 4 5
判断出栈顺序: 2 1 3 5 4
结果:合理,逐个判断,2后面比它先入栈的是“1”,单个元素当然可以;1后面无比它先入栈的,故不需要比较;3后面无比它先入栈的,故不需要比较;5后面比它先入栈的是“4”,单个元素当然可以,4后面没有元素,不需要比较。