介绍
印尼的一家公司 Gojek 通过移动应用程序提供运输和物流、食品和购物、支付、日常需求、商业、新闻和娱乐等服务,对经济做出了超过70亿美元的贡献。
它拥有 90 万注册商户、超过 1.9 亿次应用下载以及超过 200 万名司机能够在120分钟内完成超过18万个订单。我们将使用商业分析解决一个案例研究。以下是它提供的 20 多项服务中的最后一项:https://www.gojek.io/blog/food-debarkation-tensoba

运输与物流
Go-ride - 你的摩托车出租车,即本地的 Ojek
Go-car - 舒适的出行方式
Go-send - 在几个小时内发送或交付包裹
Go-box - 搬家服务,通过称重计费
Go-bluebird - 专属于Bluebird的乘车服务
Go-transit - 你的通勤助手,有或没有Gojek
美食与购物
Go-mall - 从在线市场购物
Go-mart - 从附近商店送货上门
Go-med - 从持牌药房购买药品、维生素等。
付款
Go-pay – 无现金支付
Go-bills – 快速简单地支付账单
Paylater – 现在下单,之后付款。
Go-pulsa – 数据或通话时间,随时随地充值。
Go-sure – 为你看重的东西投保
Go-give – 为重要的事情捐款
Go-investasi – 明智投资,更好地储蓄。
日常需求
GoFitness – 允许用户进行瑜伽、普拉提和泰拳等运动
商业
Go-biz – 经营和发展业务的商家#SuperApp
新闻与娱乐
Go-tix – 预订节目,免排队
Go-play – 电影和连续剧应用程序
Go-games – 游戏技巧趋势
Go-news – 热门新闻
通过这些服务生成的数据非常庞大,GO 团队拥有解决日常数据工程问题的工程解决方案。中央分析和科学团队(CAST)使 Gojek 生态系统中的多种产品能够有效地使用应用程序工作中涉及的大量数据。
该团队拥有分析师、数据科学家、数据工程师、业务分析师和决策科学家,致力于开发内部深度分析解决方案和其他 ML 系统。
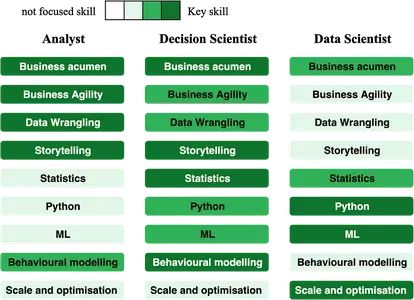
分析师的角色集中于解决日常业务问题、拥有良好的业务知识、创造影响、获得见解、RCA(根本原因分析),并让高层管理人员了解微观和宏观指标以及产品决策来解决业务问题。
学习目标
对组织面临的增长驱动因素和阻力进行根本原因分析
使用 Pandas 进行 EDA、切片和切块
营销预算优化
利润作为北极星指标(L0指标)
使用 Pulp 求解器求解 LP
使用 Pulps 编写 LP 问题
线性回归和交叉验证
使用问卷中提供的步骤进行简单的回归练习。
目录
介绍
问题陈述
第一部分
第二部分
第三部分
数据集
第一部分的解决方案
对组织面临的增长驱动因素和阻力进行根本原因分析
已完成的乘车订单
取消的乘车订单
订单分析
业务分析的调查结果和建议摘要
通过优化预算支出实现利润最大化
了解优化数据集
了解如何编写 LP 问题是解决它的关键
第二部分的解决方案
第三部分的解决方案
有用的资源和参考
结论
问题陈述
第一部分
GOJEK 董事已要求 BI 分析师查看数据,以了解 2016 年第一季度发生的情况,以及他们应该如何做才能最大限度地提高 2016 年第二季度的收入。
鉴于问题 A 中的数据,我们需要关注的主要问题是什么?
根据表 B 中的数据,如果我们只有 40,000,000,000 印尼盾(印度尼西亚的法定货币)的预算,你将如何最大化利润?
在管理会议上展示你的发现和具体解决方案。
第二部分
使用多元线性回归,预测 total_cbv。
为每个服务创建 1 个模型。
预测时期 = 2016-03-30、2016-03-31 和 2016-04-01
训练周期 = 要使用的预测列表:
一个月中的哪一天
月份
一周中的哪一天
周末/工作日标志(周末 = 周六和周日)
预处理(按顺序进行):
删除 GO-TIX
仅保留“已取消”订单状态
确保存在日期和服务的完整组合(笛卡尔积)
用 0 估算缺失值
创建 is_weekend 标志预测器(如果周六/周日则为 1,如果其他日期为 0)
对月份和星期几预测器进行one-hot编码
仅使用训练周期数据的均值和标准差将所有预测变量标准化为 z 分数
评估指标:MAPE 验证:3 折方案。每个验证折的长度与预测时期的长度相同。
问题 1 – 在所有预处理步骤之后,service = GO-FOOD,date = 2016-02-28 的所有预测变量的值是多少?
问题 2 – 显示one-hot编码变量的前 6 行(月份和星期几)
问题 3 – 打印 service = GO-KILAT 预处理后的前 6 行数据。按日期升序排序
问题 4 – 计算每项服务的预测期 MAPE。根据 MAPE 升序显示
问题 5 – 创建图表以显示每个验证折的性能。一图一服务。X = date, y = total_cbv。Color:black = actual total_cbv,other colors = the fold predictions(应该有 3 种其他颜色)。只显示有效期。例如,如果第 11、12 和 13 行用于验证,则不要在图中显示其他行。在 x 轴上清楚地显示月份和日期
第三部分
我们在 Surabaya 的 GO-FOOD 服务上个月表现非常好——他们上个月完成的订单比前一个月多了 20%。Surabaya GO-FOOD 的经理需要了解正在发生的事情,以便在下个月继续保持这种成功。
你会用什么定量方法来评估突然增长?你将如何评估客户的行为?
数据集
第 1 部分
表 A:https://github.com/chrisdmell/Project_DataScience/blob/working_branch/09_gojek/sales_data_all.csv
表 B:https://github.com/chrisdmell/Project_DataScience/blob/working_branch/09_gojek/optimization_budge.csv
第 2 部分
https://github.com/chrisdmell/Project_DataScience/blob/working_branch/09_gojek/model_analytics__data.csv
第一部分的解决方案
在开始解决之前,需要研究公司网站上的博客和白皮书(链接在下面添加)。公司档案提供了有用的资源,可以作为指南,帮助理解公司的立场。
问题一和问题三可视为开放式问题。第二个问题是关于回归的简单练习,不一定关注最佳模型,但重点是构建模型所涉及的过程。
对组织面临的增长驱动因素和阻力进行根本原因分析
导入数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
#import csvsales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/sales_data_all.csv')print("Shape of the df")
display(sales_df.shape)print("HEAD")
display(sales_df.head())print("NULL CHECK")
display(sales_df.isnull().any().sum())print("NULL CHECK")
display(sales_df.isnull().sum())print("df INFO")
display(sales_df.info())print("DESCRIBE")
display(sales_df.describe())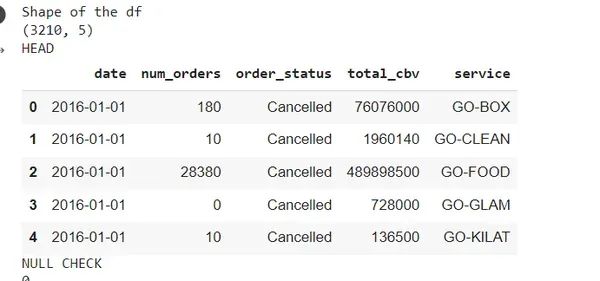
从对象格式创建 Pandas 日期时间。Pandas 日期时间是一种易于处理和操作日期的格式。
从日期时间派生月份列。也过滤掉第 4 个月(4 月)。将月份重命名为一月、二月、三月。
### convert to date time
# convert order_status to strinf
##time_to_pandas_time = ["date"]for cols in time_to_pandas_time:sales_df[cols] = pd.to_datetime(sales_df[cols])sales_df.dtypessales_df['Month'] = sales_df['date'].dt.month
sales_df.head()sales_df['Month'].drop_duplicates()sales_df[sales_df['Month'] !=4]Q1_2016_df = sales_df[sales_df['Month'] !=4]Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr")))print(Q1_2016_df.head(1))display(Q1_2016_df.order_status.unique())display(Q1_2016_df.service.unique())
#import csv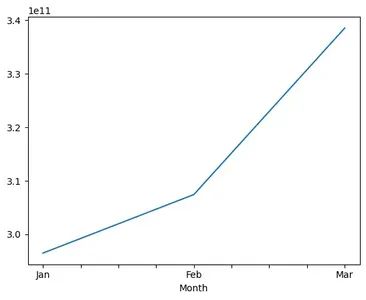

在集团层面,整体收入增长了 14%。这是一个积极的结果。
让我们按各种服务对此进行分解,并确定表现良好的服务。
revenue_total.sort_values(["Jan"], ascending=[False],inplace=True)revenue_total.head()revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum()top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv)top_95_revenue_plot = top_95_revenue[["Jan", "Feb", "Mar"]]
top_95_revenue_plot.index = top_95_revenue.service
top_95_revenue_plot.T.plot.line(figsize=(5,3))### share of revenue is changed but has the overall revenue changed for these top 4 services#import csv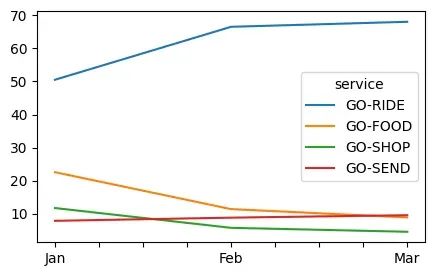

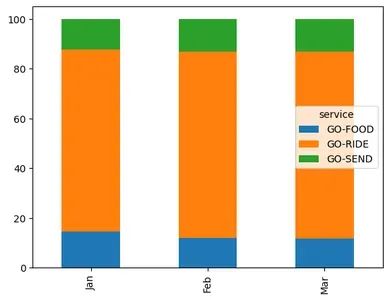
在这三个月中,乘车、美食、购物和网购贡献了超过 90% 的净收入份额。(1 月,乘车贡献了 51% 的净收入。)
因此,根据最近一个月的82原则,我们可以将此分析限制在前 3 项服务,即 - 乘车、食品、网购。
在 11 项可用服务中,只有 3 项贡献了超过 90% 的收入。这是一个令人担忧的问题,其余服务的增长机会巨大。
已完成的乘车订单
### NET - completed rides
Q1_2016_df_pivot_cbv_4 = Q1_2016_df[Q1_2016_df["order_status"] == "Completed"]
Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv_4[Q1_2016_df_pivot_cbv_4.service.isin(ninety_five_perc_gmv)]Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv_4.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
# display(Q1_2016_df_pivot_cbv.head())
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]]for cols in Q1_2016_df_pivot_cbv.columns:Q1_2016_df_pivot_cbv[cols]=(Q1_2016_df_pivot_cbv[cols]/1000000000)display(Q1_2016_df_pivot_cbv)display(Q1_2016_df_pivot_cbv.T.plot())### We see that go shop as reduced its revenue but others the revenue is constant. Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv
Q1_2016_df_pivot_cbv_4.reset_index(inplace = True)Q1_2016_df_pivot_cbv_4["Feb_jan_growth"] = (Q1_2016_df_pivot_cbv_4.Feb / Q1_2016_df_pivot_cbv_4.Jan -1)*100
Q1_2016_df_pivot_cbv_4["Mar_Feb_growth"] = (Q1_2016_df_pivot_cbv_4.Mar / Q1_2016_df_pivot_cbv_4.Feb -1)*100display(Q1_2016_df_pivot_cbv_4)#import csv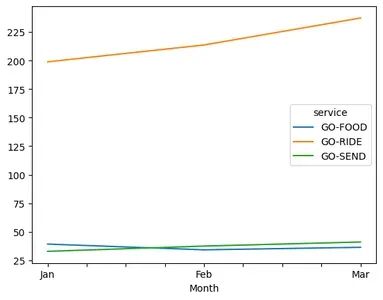

作为收入的驱动——Ride 增长了 19%(1 月至 3 月),而 Send 增长了 25%。
食品销售量下降了7%,考虑到全球餐饮外卖业务的增长,这是一个令人担忧的主要原因。
取消的乘车订单
Q1_2016_df_pivot_cbv = Q1_2016_df[Q1_2016_df["order_status"] != "Completed"]
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]]revenue_total = pd.DataFrame()for cols in Q1_2016_df_pivot_cbv.columns:revenue_total[cols]=(Q1_2016_df_pivot_cbv[cols]/Q1_2016_df_pivot_cbv[cols].sum())*100revenue_total.reset_index(inplace = True)
display(revenue_total.head())overall_cbv = Q1_2016_df_pivot_cbv.sum()
print(overall_cbv)
overall_cbv.plot()
plt.show()overall_cbv = Q1_2016_df_pivot_cbv.sum()
overall_cbv_df = pd.DataFrame(data = overall_cbv).T
display(overall_cbv_df)overall_cbv_df["Feb_jan_growth"] = (overall_cbv_df.Feb / overall_cbv_df.Jan -1)*100
overall_cbv_df["Mar_Feb_growth"] = (overall_cbv_df.Mar / overall_cbv_df.Feb -1)*100display(overall_cbv_df)revenue_total.sort_values(["Jan"], ascending=[False],inplace=True)revenue_total.head()revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum()top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv)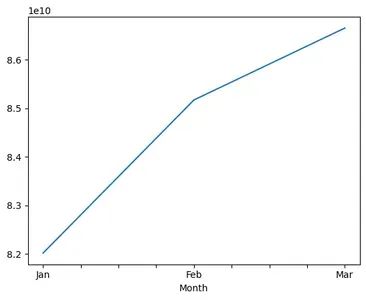

收入损失增长了 6%。
董事们可以加大力度将这一比例降至 5% 以下。
订单分析
Q1_2016_df_can_com = Q1_2016_df[Q1_2016_df.order_status.isin(["Cancelled", "Completed"])]
Q1_2016_df_can_com = Q1_2016_df_can_com[Q1_2016_df_can_com.service.isin(ninety_five_perc_gmv)]Q1_2016_df_pivot = Q1_2016_df_can_com.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum')
Q1_2016_df_pivot.fillna(0, inplace = True)multi_tuples =[('Cancelled', 'Jan'),('Cancelled', 'Feb'),('Cancelled', 'Mar'),('Completed', 'Jan'),('Completed', 'Feb'),('Completed', 'Mar')]multi_cols = pd.MultiIndex.from_tuples(multi_tuples, names=['Experiment', 'Lead Time'])Q1_2016_df_pivot = pd.DataFrame(Q1_2016_df_pivot, columns=multi_cols)display(Q1_2016_df_pivot.columns)
display(Q1_2016_df_pivot.head(3))Q1_2016_df_pivot.columns = ['_'.join(col) for col in Q1_2016_df_pivot.columns.values]display(Q1_2016_df_pivot)
#import csvQ1_2016_df_pivot["jan_total"] = Q1_2016_df_pivot.Cancelled_Jan + Q1_2016_df_pivot.Completed_Jan
Q1_2016_df_pivot["feb_total"] = Q1_2016_df_pivot.Cancelled_Feb + Q1_2016_df_pivot.Completed_Feb
Q1_2016_df_pivot["mar_total"] = Q1_2016_df_pivot.Cancelled_Mar + Q1_2016_df_pivot.Completed_MarQ1_2016_df_pivot[ "Cancelled_Jan_ratio" ] =Q1_2016_df_pivot.Cancelled_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Cancelled_Feb_ratio" ]=Q1_2016_df_pivot.Cancelled_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Cancelled_Mar_ratio" ]=Q1_2016_df_pivot.Cancelled_Mar/Q1_2016_df_pivot.mar_total
Q1_2016_df_pivot[ "Completed_Jan_ratio" ]=Q1_2016_df_pivot.Completed_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Completed_Feb_ratio" ]=Q1_2016_df_pivot.Completed_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Completed_Mar_ratio" ] =Q1_2016_df_pivot.Completed_Mar/Q1_2016_df_pivot.mar_totalQ1_2016_df_pivot_1 = Q1_2016_df_pivot[["Cancelled_Jan_ratio"
,"Cancelled_Feb_ratio"
,"Cancelled_Mar_ratio"
,"Completed_Jan_ratio"
,"Completed_Feb_ratio"
,"Completed_Mar_ratio"]]Q1_2016_df_pivot_1
3月份,Food、Ride、Send的订单取消比例分别为17%、15%和13%。
Food 的订单完成率从 1 月份的 69% 提高到 3 月份的 83%。这是一项重大改进。
### column wise cancellation check if increased
perc_of_cols_orders = pd.DataFrame()for cols in Q1_2016_df_pivot.columns:perc_of_cols_orders[cols]=(Q1_2016_df_pivot[cols]/Q1_2016_df_pivot[cols].sum())*100perc_of_cols_ordersperc_of_cols_cbv.T.plot(kind='bar', stacked=True)
perc_of_cols_orders.T.plot(kind='bar', stacked=True)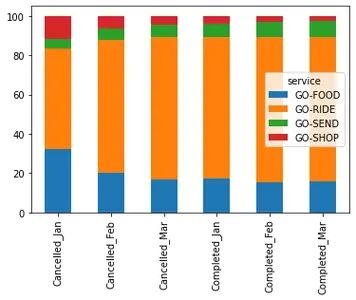

3 月,在所有被取消的订单中,Ride占72%,其次是Food(17%)和send(6%)。
业务分析的调查结果和建议摘要

RIDE:
收入的最大贡献者。
3 月份取消订单(GMV)增长了 42%
通过产品干预和新产品功能减少取消比例。
FOOD:
取消的订单有所增加,但由于成本优化,成功遏制了GMV损失。
通过减少成本和取消量来增加净收入。
获取更多的客户。
SEND:
取消的 GMV 和订单是令人担忧的主要原因。
良好的乘车完成体验可以提高留存率,并通过留存率推动收入增长。
通过优化预算支出实现利润最大化
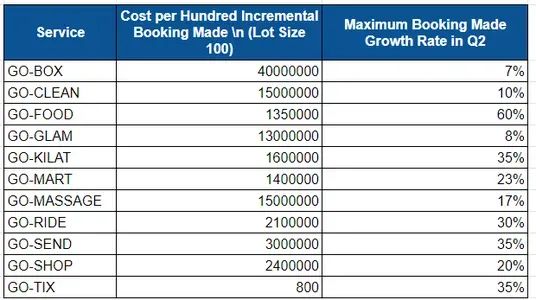
业务团队为第二季度制定了 400 亿美元的预算,并为每项服务设定了增长目标。对于每项服务,增量 100 次乘车的成本和第二季度的最大增长目标如下所示。
对Go-Box来说,再增加100个预订,需要花费40M,Q2的最大增长目标是7%。
从上述分析中导入预算数据并使用销售数据。
budget_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/optimization_budge.csv')print("Shape of the df")
display(budget_df.shape)print("HEAD")
display(budget_df.head())print("NULL CHECK")
display(budget_df.isnull().any().sum())print("NULL CHECK")
display(budget_df.isnull().sum())print("df INFO")
display(budget_df.info())print("DESCRIBE")
display(budget_df.describe())### convert to date time
# convert order_status to string
##time_to_pandas_time = ["date"]for cols in time_to_pandas_time:sales_df[cols] = pd.to_datetime(sales_df[cols])sales_df.dtypessales_df['Month'] = sales_df['date'].dt.month
sales_df.head()sales_df['Month'].drop_duplicates()sales_df_q1 = sales_df[sales_df['Month'] !=4]
### Assumptions
sales_df_q1 = sales_df_q1[sales_df_q1["order_status"] == "Completed"]# Q1_2016_df_pivot = Q1_2016_df.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum')sales_df_q1_pivot = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='total_cbv', aggfunc= 'sum')
sales_df_q1_pivot_orders = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='num_orders', aggfunc= 'sum')sales_df_q1_pivot.reset_index(inplace = True)
sales_df_q1_pivot.columns = ["Service","Q1_revenue_completed"]
sales_df_q1_pivotsales_df_q1_pivot_orders.reset_index(inplace = True)
sales_df_q1_pivot_orders.columns = ["Service","Q1_order_completed"]optimization_Df = pd.merge(sales_df_q1_pivot,budget_df,how="left",on="Service",)optimization_Df = pd.merge(optimization_Df,sales_df_q1_pivot_orders,how="left",on="Service",)optimization_Df.columns = ["Service", "Q1_revenue_completed", "Cost_per_100_inc_booking", "max_q2_growth_rate","Q1_order_completed"]
optimization_Df.head(5)
#import csv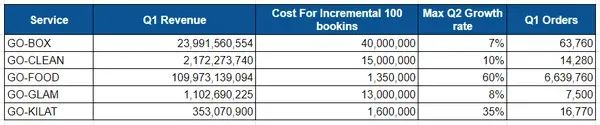
对于 Box,Q1 收入为 23B,增量 100 次乘车的成本为 40M,其最大预期增长率为 7%,总乘车次数为 63K,每笔订单 370K。
是否有可能在可用预算为 40B 的情况下实现所有服务的最大增长率?
### If all service max growth is to be achived what is the budget needed? and whats the deficiet?
optimization_Df["max_q2_growth_rate_upd"] = optimization_Df['max_q2_growth_rate'].str.extract('(\d+)').astype(int) ### extract int from string
optimization_Df["max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/100)) ### Q2 max orders based on Q1 orders
optimization_Df["abs_inc_orders"] = optimization_Df.max_growth_q2_cbv-optimization_Df.Q1_order_completed ### Total increase in orders
optimization_Df["cost_of_max_inc_q2_order"] = optimization_Df.abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ### Total Cost to get maximum growth for each serivcedisplay(optimization_Df)display(budget_df[budget_df["Service"] == "Budget:"].reset_index())
budget_max = budget_df[budget_df["Service"] == "Budget:"].reset_index()
budget_max = budget_max.iloc[:,2:3].values[0][0]
print("Budget difference by")
display(budget_max-optimization_Df.cost_of_max_inc_q2_order.sum() )### Therefore max of the everything cannot be achieved#import csv答案是第 247B(247,244,617,204) 号需要更多预算才能实现所有服务的增长目标。
有没有可能在40B的可用预算下,所有服务都至少达到最大增长率的10%?
### Then what is the budget needed and what will the extra budget at hand??
optimization_Df["min_10_max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/1000)) ### atleast 10% of max if achieved, this is orders
optimization_Df["min_10_abs_inc_orders"] = optimization_Df.min_10_max_growth_q2_cbv-optimization_Df.Q1_order_completed ### what is the increase in orders needed to achieve 10% orders growth
optimization_Df["min_10_cost_of_max_inc_q2_order"] = optimization_Df.min_10_abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ### Cost associatedfor 10% increase in orders display(budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum() ) ### Total budget remainingdisplay((budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum())/budget_max) ### Budget utilization percentage optimization_Df["perc_min_10_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/1000)) ### atleast 10% of max if achieved, 7 to percent divide by 100, 10% of this number. divide by 10, so 1000
optimization_Df["perc_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/100)) ### Max growth to be achievedoptimization_Df["q1_aov"] = optimization_Df.Q1_revenue_completed/optimization_Df.Q1_order_completed ### Q1 average order value
optimization_Df["order_profitability"] = 0.1 ### this is assumption that 10% will be profitoptimization_Df["a_orders_Q2"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.perc_min_10_max_growth_q2_cbv)) ### based on 10% growth, total new orders for qcoptimization_Df["a_abs_inc_orders"] = optimization_Df.a_orders_Q2-optimization_Df.Q1_order_completedoptimization_Df["a_Q2_costs"] = optimization_Df.Cost_per_100_inc_booking* optimization_Df.a_abs_inc_orders/100##There is scope for improvement here, so This can be adjusted based on revenue or ranking from Q1
display(budget_max - optimization_Df.a_Q2_costs.sum())optimization_Df#import csv答案是肯定的。只需可用 40B 预算的 28%,即可实现这一目标。可用预算的未充分利用绝不是一种选择,任何企业领导者都不会只使用可用预算的 28%。
因此,无法实现所有服务的最大增长,实现最大增长率的 10% 将导致预算无法得到充分利用。因此,这里需要优化支出,以便:
整体现金消耗补不超过 40B。
第二季度各服务的整体增长率等于或低于最大增长率。
线性优化中称为约束。
目标是利润最大化。
这里使用的假设:
每项服务都有 10% 的利润。
AOV(收入/订单)将与第一季度保持一致。
预优化数据管道:
### Data prep for pulp optimization
perc_all_df = pd.DataFrame(data = list(range(1,optimization_Df.max_q2_growth_rate_upd.max()+1)), columns = ["growth_perc"])
### create a list of all percentage growth, from 1 to max to growth expected, this is to create simulation for optimization
display(perc_all_df.head(1))optimization_Df_2 = optimization_Df.merge(perc_all_df, how = "cross") ### cross join with opti DF### Filter and keeping all percentgaes upto maximum for each service
### Minimum percentage kept is 1
optimization_Df_2["filter_flag"] = np.where(optimization_Df_2.max_q2_growth_rate_upd >= (optimization_Df_2.growth_perc),1,0)
optimization_Df_2["abs_profit"] = (optimization_Df_2.q1_aov)*(optimization_Df_2.order_profitability)
optimization_Df_3 = optimization_Df_2[optimization_Df_2["filter_flag"] == 1]display(optimization_Df_3.head(1))
display(optimization_Df_3.columns)### Filter columns needed
optimization_Df_4 = optimization_Df_3[['Service', ### services offered'Cost_per_100_inc_booking', ### cost of additional 100 orders'Q1_order_completed', ### to calculate q2 growth based on q1 orders'perc_min_10_max_growth_q2_cbv', ### minimum growth percent need 'perc_max_growth_q2_cbv', ### max growth percent allowed'abs_profit', ### profit per order 'growth_perc' ### to simulative growth percet across]]display(optimization_Df_4.head(2))optimization_Df_4["orders_Q2"] = (optimization_Df_4.Q1_order_completed *(1+ optimization_Df_4.growth_perc/100)) ### based on growth, total new orders for qc
optimization_Df_4["abs_inc_orders"] = optimization_Df_4.orders_Q2-optimization_Df_4.Q1_order_completed
optimization_Df_4["profit_Q2_cbv"] = optimization_Df_4.orders_Q2 * optimization_Df_4.abs_profit
optimization_Df_4["growth_perc"] = optimization_Df_4.growth_perc/100
optimization_Df_4["Q2_costs"] = optimization_Df_4.Cost_per_100_inc_booking* optimization_Df_4.abs_inc_orders/100display(optimization_Df_4.head())optimization_Df_5 = optimization_Df_4[['Service', ### services offered'Q2_costs', ### cost total for the growth expected'perc_min_10_max_growth_q2_cbv', ### minimum growth percent need 'perc_max_growth_q2_cbv', ### max growth percent allowed'profit_Q2_cbv', ### total profit at the assumed order_profitability rate'growth_perc' ### to simulative growth percet across]]optimization_Df_5display(optimization_Df_5.head(10))
display(optimization_Df_5.shape)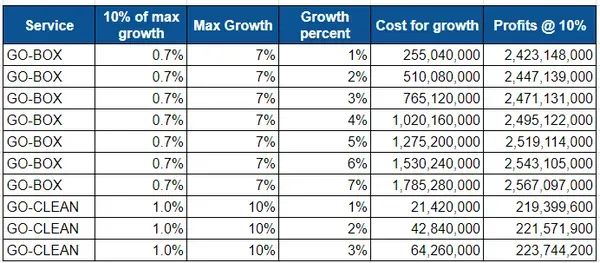
了解优化数据集
Service – Go product
最大增长的 10%,是每个服务应该达到的最小增长。所以 Box 至少应该实现 0.7% 的增长。
这是一个约束。
业务领导者为 Box 决定的最大增长是 7%。
这是一个约束。
对于Box,1%到7%是增长的范围。1%超过0.7%,7%是最大值。优化器将根据约束选择最佳增长率。
这是一个决策变量。该算法将从 7 个中选择一个。
对于 1% 的增长(增量),现金消耗为 2.55 亿。
这是一个约束。
如果增量增长率为 1%,则总体利润(有机 + 无机)为 2.4B。
这是目标。
### Best optimization for our case case. This is good. prob = LpProblem("growth_maximize", LpMaximize) ### Initialize optimization problem - Maximization problemoptimization_Df_5.reset_index(inplace = True, drop = True)
markdowns = list(optimization_Df_5['growth_perc'].unique()) ### List of all growth percentages
cost_v = list(optimization_Df_5['Q2_costs']) ### List of all incremental cost to achieve the growth % neededperc_min_10_max_growth_q2_cbv = list(optimization_Df_5['perc_min_10_max_growth_q2_cbv'])
growth_perc = list(optimization_Df_5['growth_perc'])### lp variables
low = LpVariable.dicts("l_", perc_min_10_max_growth_q2_cbv, lowBound = 0, cat = "Continuous")
growth = LpVariable.dicts("g_", growth_perc, lowBound = 0, cat = "Continuous")
delta = LpVariable.dicts ("d", markdowns, 0, 1, LpBinary)
x = LpVariable.dicts ("x", range(0, len(optimization_Df_5)), 0, 1, LpBinary)### objective function - Maximise profit, column name - profit_Q2_cbv
### Assign value for each of the rows -
### For all rows in the table each row will be assidned x_0, x_1, x_2 etc etc
### This is later used to filter the optimal growth percent
prob += lpSum(x[i] * optimization_Df_5.loc[i, 'profit_Q2_cbv'] for i in range(0, len(optimization_Df_5)))### one unique growth percentahe for each service
### Constraint one
for i in optimization_Df_5['Service'].unique():prob += lpSum([x[idx] for idx in optimization_Df_5[(optimization_Df_5['Service'] == i) ].index]) == 1### Do not cross total budget
### Constraint two
prob += (lpSum(x[i] * optimization_Df_5.loc[i, 'Q2_costs'] for i in range(0, len(optimization_Df_5))) - budget_max) <= 0 ### constraint to say minimum should be achived
for i in range(0, len(optimization_Df_5)):prob += lpSum(x[i] * optimization_Df_5.loc[i, 'growth_perc'] ) >= lpSum(x[i] * optimization_Df_5.loc[i, 'perc_min_10_max_growth_q2_cbv'] )prob.writeLP('markdown_problem') ### Write Problem name
prob.solve() ### Solve Problem
display(LpStatus[prob.status]) ### Problem status - Optimal, if problem solved successfully
display(value(prob.objective)) ### Objective, in this case what is the maximized profit with availble budget - 98731060158.842 @ 10% profit per order #import csv
print(prob)
print(growth)了解如何编写 LP 问题是解决它的关键
初始化问题
prob = LpProblem(“growth_maximize”, LpMaximize)
问题的名称是 growth_maximize
LpMaximize 让求解器知道这是一个最大化问题。
创建决策函数的变量
growth = LpVariable.dicts(“g_”, growth_perc, lowBound = 0, cat = “连续”)
对于 Pulp,需要创建 pulp dicts
g_ 是变量的前缀
growth_perc 是列表的名称
low bound是最小增长百分比,可以从0开始。
变量是连续的。
有 60 个独特的增长百分比,从 1%(最小值)到 60%(最大值)。(食物的最大增长率为 60%)。
变量 – 0 <= x_0 <= 1行0 到 0 <= x_279 <= 1行 279 的整数。
为问题添加目标函数
prob += lpSum(x[i] * optimization_Df_5.loc[i, 'profit_Q2_cbv'] for i in range(0, len(optimization_Df_5)))
创建了一个等式: pulp -> 2423147615.954*x_0 + 2447139176.5080004*x_1 + 225916468.96*x_3+ … + 8576395.965000002*x_279。数据集中有 280 行,因此为每个利润值创建一个变量。
添加约束:
display(LpStatus[prob.status])
for i in range(0, len(optimization_Df_5)): prob += lpSum(x[i] * optimization_Df_5.loc[i, 'growth_perc'] ) >= lpSum(x[i] * optimization_Df_5.loc[i, ' perc_min_10_max_growth_q2_cbv'] )
对于每一行,创建最小增长百分比约束方程。有 279 行,因此创建了 279 个约束。
_C13:0.003 x_0 >= 0 从第 0 行到 _C292:0.315 x_279 >= 0 到第 279 行。
prob += (lpSum(x[i] * optimization_Df_5.loc[i, 'Q2_costs'] for i inrange(0, len(optimization_Df_5))) – budget_max) <= 0
所有成本减去总预算的总和应小于或等于零。
方程式 _C12:255040000 x_0 + 510080000 x_1 + …. + 16604 x_279 <= 0
_C12:是这里唯一的约束,因为有一个总预算为 40B,并且没有限制每个服务可以花费多少。
对于 optimization_Df_5['Service'].unique() 中的 i: prob += lpSum([x[idx] for idx in optimization_Df_5[(optimization_Df_5['Service'] == i) ].index]) == 1
对于每项服务,只选择一个增长百分比。
从 1 到 7 个 Box 中只选择 1。
方框的方程 – _C1:x_0 + x_1 + x_2 + x_3 + x_4 + x_5 + x_6 = 1
GLAM – _C2 的等式:x_10 + x_11 + x_12 + x_13 + x_14 + x_15 + x_16 + x_7 + x_8 + x_9 = 1
由于有 11 个服务,因此创建了 11 个约束,每个服务一个约束。
每项服务的一个增长百分比
不要超过 40B 的总预算
约束最低应该达到
“ Optimal” 是期望的输出
98731060158.842 利润最大化
display(value(prob.objective))
var_name = []
var_values = []
for variable in prob.variables():if 'x' in variable.name:var_name.append(variable.name)var_values.append(variable.varValue)results = pd.DataFrame()results['variable_name'] = var_name
results['variable_values'] = var_values
results['variable_name_1'] = results['variable_name'].apply(lambda x: x.split('_')[0])
results['variable_name_2'] = results['variable_name'].apply(lambda x: x.split('_')[1])
results['variable_name_2'] = results['variable_name_2'].astype(int)
results.sort_values(by='variable_name_2', inplace=True)
results.drop(columns=['variable_name_1', 'variable_name_2'], inplace=True)
results.reset_index(inplace=True)
results.drop(columns='index', axis=1, inplace=True)# results.head()optimization_Df_5['variable_name'] = results['variable_name'].copy()
optimization_Df_5['variable_values'] = results['variable_values'].copy()
optimization_Df_5['variable_values'] = optimization_Df_5['variable_values'].astype(int)# optimization_Df_6.head()#import csv### with no budget contraint
optimization_Df_10 = optimization_Df_5[optimization_Df_5['variable_values'] == 1].reset_index()optimization_Df_10["flag"] = np.where(optimization_Df_10.growth_perc >= optimization_Df_10.perc_min_10_max_growth_q2_cbv,1,0)display(optimization_Df_10)display(budget_max - optimization_Df_10.Q2_costs.sum())
display( optimization_Df_10.Q2_costs.sum())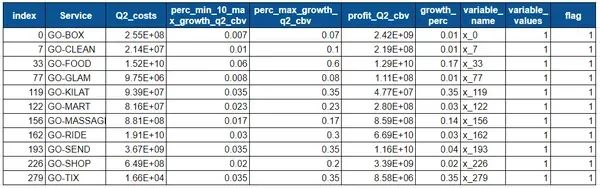
各服务的最大增长率见上表。对于 Box,它是 1%,对于 Clean,它是 1%,对于 Food,它是 17%,等等。
现金消耗总额为 – 39999532404.0
未充分利用的预算 – 467596.0
利润最大化 – 98731060158.0
第二部分的解决方案
sales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/model_analytics__data.csv')time_to_pandas_time = ["date"]for cols in time_to_pandas_time:sales_df[cols] = pd.to_datetime(sales_df[cols])sales_df['Month'] = sales_df['date'].dt.month Q1_2016_df = sales_df[sales_df['Month'] !=900]Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr")))Q1_2016_df['test_control'] = np.where(Q1_2016_df['date'] <= "2016-03-30","train", "test")display(Q1_2016_df.head(5))display(Q1_2016_df.order_status.unique())display(Q1_2016_df.service.unique())display(Q1_2016_df.date.max())
#import csv导入数据集
将日期转换为 pandas 日期时间
导出月份列
导出训练和测试列
display(Q1_2016_df.head())
display(Q1_2016_df.date.max())Q1_2016_df_2 = Q1_2016_df[Q1_2016_df["date"] <= "2016-04-01"]
display(Q1_2016_df_2.date.max())Q1_2016_df_2 = Q1_2016_df_2[Q1_2016_df["order_status"] == "Cancelled"] Q1_2016_df_date_unique = Q1_2016_df_2[["date"]].drop_duplicates()
Q1_2016_df_date_service = Q1_2016_df_2[["service"]].drop_duplicates()Q1_2016_df_CJ = Q1_2016_df_date_unique.merge(Q1_2016_df_date_service, how = "cross") ### cross join with opti DFdisplay(Q1_2016_df_date_unique.head())
display(Q1_2016_df_date_unique.shape)
display(Q1_2016_df_date_unique.max())
display(Q1_2016_df_date_unique.min())display(Q1_2016_df_2.shape)
Q1_2016_df_3 = Q1_2016_df_CJ.merge(Q1_2016_df_2, on=['date','service'], how='left', suffixes=('_x', '_y'))display(Q1_2016_df_3.head())
display(Q1_2016_df_3.shape)
display(Q1_2016_df_CJ.shape)Q1_2016_df_3["total_cbv"].fillna(0, inplace = True)
print("Null check ",Q1_2016_df_3.isnull().values.any())nan_rows = Q1_2016_df_3[Q1_2016_df_3['total_cbv'].isnull()]
nan_rowsdisplay(Q1_2016_df_3[Q1_2016_df_3.isnull().any(axis=1)])Q1_2016_df_3["dayofweek"] = Q1_2016_df_3["date"].dt.dayofweek
Q1_2016_df_3["dayofmonth"] = Q1_2016_df_3["date"].dt.dayQ1_2016_df_3["Is_Weekend"] = Q1_2016_df_3["date"].dt.day_name().isin(['Saturday', 'Sunday'])Q1_2016_df_3.head()仅过滤已取消的订单
对于所有服务,交叉连接从 1 月 1 日到 4 月 1 日的日期,以便所有日期的预测都可用
将 NULL 替换为 0
导出月份中的某天
导出一周中的某天
创建二进制周末/工作日列

Q1_2016_df_4 = Q1_2016_df_3[Q1_2016_df_3["service"] != "GO-TIX"]Q1_2016_df_5 = pd.get_dummies(Q1_2016_df_4, columns=["Month","dayofweek"])display(Q1_2016_df_5.head())import numpy as np
import pandas as pd
# from sklearn.datasets import load_boston
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from numpy import mean
from numpy import std
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_predictQ1_2016_df_5.columnsall_columns = ['date', 'service', 'num_orders', 'order_status', 'total_cbv','test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb','Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2','dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6']model_variables = [ 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb','Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2','dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6']target_Variable = ["total_cbv"]all_columns = ['service', 'test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb','Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2','dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6']过滤掉 GO-TIX
one-hot 编码——月份和星期几
导入所有必要的库
创建columns、train_predict 等列表。
model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] =="GO-FOOD"]test = model_1[model_1["test_control"]!="train"]
train = model_1[model_1["test_control"]=="train"]X = train[model_variables]
y = train[target_Variable]train_predict = model_1[model_1["test_control"]=="train"]
x_ = X[model_variables]sc = StandardScaler()
X_train = sc.fit_transform(X)
X_test = sc.transform(x_)为一项服务过滤数据 – GO-FOOD
创建训练和测试数据框
创建 X – 使用训练列,使用预测列创建 y。
使用 Standardscalar 进行 z 分数转换。
#define custom function which returns single output as metric score
def NMAPE(y_true, y_pred): return 1 - np.mean(np.abs((y_true - y_pred) / y_true)) * 100#make scorer from custome function
nmape_scorer = make_scorer(NMAPE)# prepare the cross-validation procedure
cv = KFold(n_splits=3, random_state=1, shuffle=True)
# create model
model = LinearRegression()
# evaluate model
scores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))y_pred = cross_val_predict(model, X, y, cv=cv)cross_val_score 没有 MAPE 作为内置记分器,因此定义 MAPE。
创建 CV 实例
创建 LR 实例
使用 cross_val_score 获取 GO-Foods 跨 CV 折的平均 MAPE 分数。
对于每一个服务,这段代码都可以循环使用,创建一个函数:
def go_model(Q1_2016_df_5, go_service,model_variables,target_Variable):"""Q1_2016_df_5go_servicemodel_variablestarget_Variable"""model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] ==go_service]test = model_1[model_1["test_control"]!="train"]train = model_1[model_1["test_control"]=="train"]X = train[model_variables]y = train[target_Variable]train_predict = model_1[model_1["test_control"]=="train"]x_ = X[model_variables]X_train = sc.fit_transform(X)X_test = sc.transform(x_)# prepare the cross-validation procedurecv = KFold(n_splits=3, random_state=1, shuffle=True)# create modelmodel = LinearRegression()# evaluate modelscores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1)# report performanceprint('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))y_pred = cross_val_predict(model, X, y, cv=cv)return y_pred,mean(scores), std(scores)a,b,c = go_model(Q1_2016_df_5, "GO-FOOD",model_variables,target_Variable)b转换为函数的建模步骤:
Q1_2016_df_5 – 基础数据
go_service – go-tix、go-send 等
model_variables – 用于训练模型的变量
target_Variable – 预测变量(total_cbv)。
对于每项服务,可以运行该方法以获得所有 11 项服务的平均预测 MAPE。
第三部分的解决方案
问题 3 是一个开放式问题,鼓励读者自行解决。一些假设是:
由于这是特定于一个粒子区域和地理位置的,因此可以安全地假设 APP 或多或少保持不变,并且产品干预可能只起到了次要作用。如果有产品干预,它只是特定于这个特定领域。
优质/著名的餐厅和食品连锁店已经上线,用户现在可以从熟悉的餐厅或熟悉的餐厅订购很多不错的选择。
通过加入更多的送货代理,送货速度得到了显着提高。
重新培训送货代理以减少取消的订单数目。
与餐厅合作,以更好的方式处理高峰时段的混乱情况。
有用的资源和参考
在“中央分析和科学团队”工作:https://www.gojek.io/blog/working-in-the-central-analytics-and-science-team
如何使用“Tensoba”估算食物的送达时间:https://www.gojek.io/blog/food-debarkation-tensoba
入门级数据分析师的商业案例研究任务:https://www.analyticsvidhya.com/blog/2023/02/business-case-study-assignments-for-entry-level-data-analysts/
解决数据科学家的商业案例研究任务:https://www.analyticsvidhya.com/blog/2022/05/solving-business-case-study-assignments-for-data-scientists/
使用数据来分析客户:https://www.gojek.io/blog/using-data-to-appreciate-our-customers
Gojek 自动预测工具的工作原理:https://www.gojek.io/blog/under-the-hood-of-gojeks-automated-forecasting-tool
Gojek 的实验:https://www.gojek.io/blog/beast-moving-data-from-kafka-to-bigquery
GO-JEK 对印度尼西亚的影响:https://www.gojek.io/blog/go-jeks-impact-for-indonesia
GO-FAST:Ramadan 背后的数据
https://www.gojek.io/blog/go-fast-the-data-behind-ramadan
PuLP 优化:https://medium.com/ro-co/optimization-with-pulp-in-python-getting-started-f6c5b678bf15
使用 PuLP 的线性规划:https://towardsdatascience.com/basic-linear-programming-in-python-with-pulp-d398d144802b
营销活动优化:https://www.kaggle.com/code/mozturkmen/replication-of-marketing-campaign-optimization
使用 python 优化某些东西的简单方法:https://towardsdatascience.com/a-simple-way-to-optimize-something-in-python-740cda7fd3e0
结论
如果按照上述步骤正确完成案例研究,将对业务产生积极影响。招聘人员不是在寻找答案,而是在寻找获得这些答案的方法、遵循的结构、使用的推理以及使用业务分析的业务和实践知识。
本文以真实的业务案例研究为例,为数据分析师提供了一个易于遵循的框架。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓





