RocketMQ消息消费示例代码:
public static void main(String[] args) throws InterruptedException, MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");consumer.setNamesrvAddr("127.0.0.1:9876");consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET); //从那里开始消费consumer.subscribe("TopicTest", "*"); //订阅主题//注册并发消费模式监听器consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});//启动消费者consumer.start();System.out.printf("Consumer Started.%n");}这里主要用的就是DefaultMQPushConsumer 这个消息消费推模式的默认实现类,就从这里开始展开介绍,先看一下继承关系:
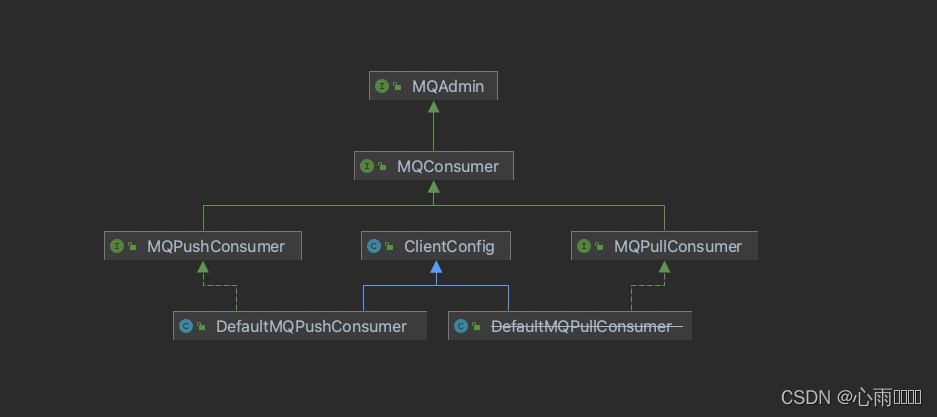
MQPushConsumer:
这是RocketMQ推模式消费组接口,这个接口的几个主要接口如下:
void start() //启动消消费者
void shutdown() //关闭消费者
void registerMessageListener(final MessageListenerConcurrently messageListener); //注册并发消费模式监听器
void registerMessageListener(final MessageListenerOrderly messageListener); //注册顺序消费模式监听器
void subscribe(final String topic, final String subExpression) throws MQClientException; //注册顺序消费模式监听器
void unsubscribe(final String topic); //取消订阅
然后DefaultMQPushConsumer就是MQPushConsumer的一个实现类,可以看到我们示例代码的使用基本就是调用的这几个API。
MQPullConsumer:
这是RocketMQ拉模式消费组接口,这个接口的几个主要接口如下:
void start(); //启动
void shutdown(); //关闭
//注册消息队列变更回调函数,即消费端分配到的队列发发生变化时触发的回调含糊
void registerMessageQueueListener(final String topic, final MessageQueueListener listener);
//拉取消息
PullResult pull(final MessageQueue mq, final String subExpression, final long offset,final int maxNums);
//消息拉取 通过 MessageSelector 构建消息过滤对象
PullResult pull(final MessageQueue mq, final MessageSelector selector, final long offset,final int maxNums)
//异步拉取,调用其异步回调函数 PullCallback
void pull(final MessageQueue mq, final String subExpression, final long offset, final int maxNums,final PullCallback pullCallback)//拉取消息,如果没有拉到则阻塞等待
PullResult pullBlockIfNotFound(final MessageQueue mq, final String subExpression,final long offset, final int maxNums) 这里罗列了一部分,还有一些就不一一罗列了,但是可以简单看一下消息拉模式的代码:
try {DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("dw_pull_consumer");consumer.setNamesrvAddr("127.0.01:9876");consumer.start();Map<MessageQueue, Long> offsetTable = new HashMap<MessageQueue, Long>();Set<MessageQueue> msgQueueList = consumer.fetchSubscribeMessageQueues("TOPIC_TEST"); // 获取该 Topic 的所有队列if(msgQueueList != null && !msgQueueList.isEmpty()) {boolean noFoundFlag = false;while(this.s.running) {if(noFoundFlag) { // 没有找到消息,暂停一下消费Thread.sleep(1000);}for( MessageQueue q : msgQueueList ) {PullResult pullResult = consumer.pull(q, "*",decivedPulloffset(offsetTable, q, consumer) , 3000);System.out.println("pullStatus:" + pullResult.getPullStatus());switch (pullResult.getPullStatus()) {case FOUND:doSomething(pullResult.getMsgFoundList());break;case NO_MATCHED_MSG:break;case NO_NEW_MSG:case OFFSET_ILLEGAL:noFoundFlag = true;break;default:continue ;}//提交位点consumer.updateConsumeOffset(q, pullResult.getNextBeginOffset());}System.out.println("balacne queue is empty: " + consumer.fetchMessageQueuesInBalance("TOPIC_TEST").isEmpty());}} else {System.out.println("end,because queue is enmpty");}consumer.shutdown();System.out.println("consumer shutdown");} catch (Throwable e) {e.printStackTrace();}}-
首先根据 MQConsumer 的 fetchSubscribeMessageQueues 的方法获取 Topic 的所有队列信息。
-
然后遍历所有队列,依次通过 MQConsuemr 的 PULL 方法从 Broker 端拉取消息。
-
对拉取的消息进行消费处理。
-
通过调用 MQConsumer 的 updateConsumeOffset 方法更新位点,但需要注意的是这个方法并不是实时向 Broker 提交,而是客户端会启用以线程,默认每隔 5s 向 Broker 集中上报一次。
这里的拉模式跟最开始的消息推模式比较起来是不是复杂很多?所以现在一般都是使用消息推模式来进行消息消费了。
其实消息推模式就是对消息拉模式的一个封装,也就是说推模式是基于拉模式的,只不过将消息的拉取、消息队列的自动负载、消息进度自动提交,消息消费重试都进行了封装。所以我们一般使用消息推模式比较多。
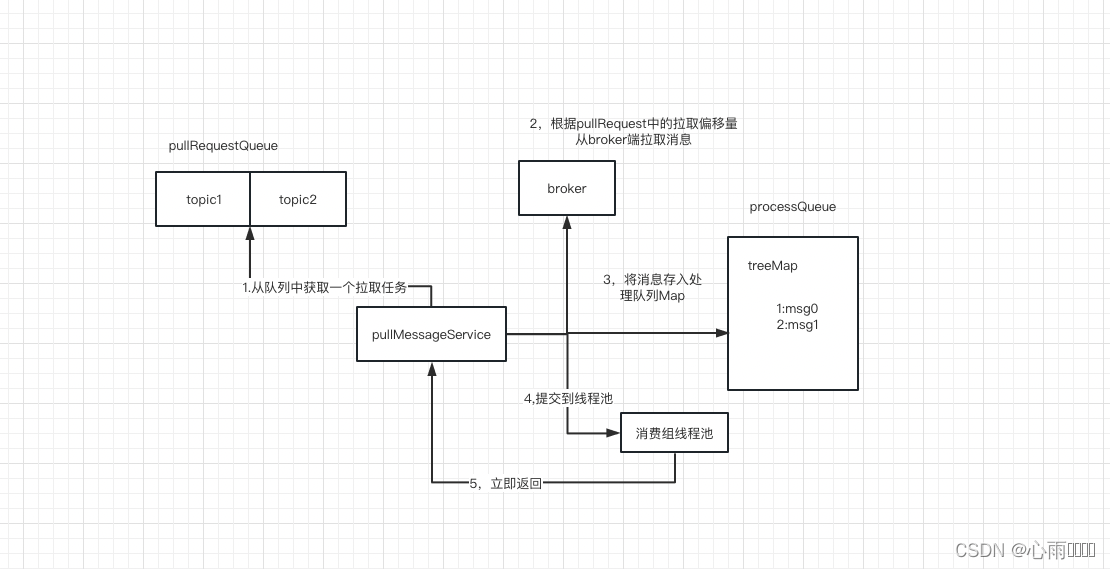
先看下消息消费整体处理流程:
-
从消费者队列pullRequestQueue中取出一个PullRequest对象,根据对象中的拉取偏移量向Broker发起拉取请求,默认一次拉取32条。
-
通过拉取请求向broker发起拉取请求,broker接受到请求后根据拉取偏移量返回消息。
-
接受到Broker的消息后会先将消息存入processQueue,是一个内部结构是一个treeMap,key是消息偏移量,value是消息。
-
然后将拉取到的消息提交到消费组内部的线程池,然后立即返回,并将pullRequest对象放回pullRequestQueue中。
-
消息消费组线程池处理完一条消息后,会将消息从processQueue中移除,然后向broker汇报消息消费进度,以便下次重启能从上一次消费的位置开始消费。
消息推模式的默认实现类DefaultMQPushConsumer核心参数和工作原理:
private String consumerGroup; //消费组
//消息消费组消费模式,模式集群模式,还有广播模式
private MessageModel messageModel = MessageModel.CLUSTERING;
//一个消费组启动时从那个位置开始消费
private ConsumeFromWhere consumeFromWhere = ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET;
//消息队列负载算法
private AllocateMessageQueueStrategy allocateMessageQueueStrategy;
//消费者每一个消费组线程池中最小的线程数量。每个消费者都有一个独立的线程池
private int consumeThreadMin = 20;
//消费者最大线程数量
private int consumeThreadMax = 20;
//允许消息端消息队列最大积压数量
private int pullThresholdForQueue = 1000;
//允许消费端消息队列最大挤压体积单位M
private int pullThresholdSizeForQueue = 100;
//消息重试次数 -1代表最大重试次数16次
private int maxReconsumeTimes = -1;
//消息消费超时时间15分钟
private long consumeTimeout = 15;
消息消费模式,集群模式与广播模式
集群模式:当前主题下的同一条消息只允许被一个消费者消费
广播模式:当前主题下的同一条消息将被所有的消费者消费一次。
消费者启动:
消费者启动的方法是DefaultMQPushConsumerImpl.start()方法。
1.构建要订阅的map,并把订阅信息放到rebalanceImpl的subscriptionInner,还有订阅重试主题
2.创建MQClientInstance实例
3.初始化 RebalanceImpl
4.初始化消息消费进度
5.如果是顺序消费,创建消费端线程服务
6.注册消费者并启动MQClientInstance实例
我感觉没必要粘贴代码过来了,因为代码量很多,有兴趣可以点到这个start方法里面去阅读一下
消息拉取:
在上面消费者启动第六步,注册并启动MQClientInstance,在调用它的start方法后,会有这么一行代码:
this.pullMessageService.start();
这就是启动了一个线程,来到PullMessageService的run方法。
@Overridepublic void run() {log.info(this.getServiceName() + " service started");while (!this.isStopped()) {try {PullRequest pullRequest = this.pullRequestQueue.take(); //1this.pullMessage(pullRequest); //2} catch (InterruptedException ignored) {} catch (Exception e) {log.error("Pull Message Service Run Method exception", e);}}log.info(this.getServiceName() + " service end");}上面的注释1:就是从pullRequestQueue获取一个PullRequest对象,这时候上面消费整体流程的流程图对着看了。来看看pullRequestQueue的定义:
那么这里就又个问题,这个队列里面的对象会在那里给他加进去呢?它的创建是在rebalanceImpl中创建的,在后面会说,记住这个地方,待会后面讲的时候记得跳回来。
private final LinkedBlockingQueue<PullRequest> pullRequestQueue = new LinkedBlockingQueue<PullRequest>();上面的注释2处:就是将获取到的PullRequest拿去获取消息。方法如下
private void pullMessage(final PullRequest pullRequest) {final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());if (consumer != null) {DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;impl.pullMessage(pullRequest);} else {log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);}}
//public MQConsumerInner selectConsumer(final String group) {return this.consumerTable.get(group);
}这里面就是根据消费组去获取一个MQConsumerInner对象(他是一个接口,它的实现类有三个,如下图),然后强制转换为DefaultMQPushConsumerImpl,然后去拉取消息消息。
然后来看DefaultMQPushConsumerImpl的pullMessage方法,我省去一下异常处理只留下核心逻辑代码:
//得到当前的出席消息的队列,同样可以对照前面的流程图看,其实就是一个treeMap
final ProcessQueue processQueue = pullRequest.getProcessQueue();
//更新拉取时间为当前时间
pullRequest.getProcessQueue().setLastPullTimestamp(System.currentTimeMillis());
this.makeSureStateOK();
//获取当前缓存中的数量和大小
long cachedMessageCount = processQueue.getMsgCount().get();
long cachedMessageSizeInMiB = processQueue.getMsgSize().get() / (1024 * 1024);
if (cachedMessageCount > this.defaultMQPushConsumer.getPullThresholdForQueue()) { //消息数大于1000,下一次拉取任务50ms后才会加入拉取队列this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
}
if (cachedMessageSizeInMiB > this.defaultMQPushConsumer.getPullThresholdSizeForQueue()) {//缓存的消息体积大于100Mthis.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
}
//是否为顺序消费
if (!this.consumeOrderly) {//不是顺序消费if (processQueue.getMaxSpan() > this.defaultMQPushConsumer.getConsumeConcurrentlyMaxSpan()){// 这是队列中消息偏移量大于2000this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);}
}else {if (processQueue.isLocked()) {final long offset = this.rebalanceImpl.computePullFromWhere(pullRequest.getMessageQueue());boolean brokerBusy = offset < pullRequest.getNextOffset();pullRequest.setLockedFirst(true);pullRequest.setNextOffset(offset);} else {this.executePullRequestLater(pullRequest, pullTimeDelayMillsWhenException);}
}
//拉取该主题的订阅信息
final SubscriptionData subscriptionData = this.rebalanceImpl.getSubscriptionInner().get(pullRequest.getMessageQueue().getTopic());
final long beginTimestamp = System.currentTimeMillis();//回调函数
PullCallback pullCallback = new PullCallback() {//拉取到了消息
onSuccess
//消息拉取为空则3s后下一次拉取将在3s执行
onException
}
//执行消息拉取,从broker拉取消息
this.pullAPIWrapper.pullKernelImpl(pullRequest.getMessageQueue(),subExpression,subscriptionData.getExpressionType(),subscriptionData.getSubVersion(),pullRequest.getNextOffset(),this.defaultMQPushConsumer.getPullBatchSize(),sysFlag,commitOffsetValue,BROKER_SUSPEND_MAX_TIME_MILLIS,CONSUMER_TIMEOUT_MILLIS_WHEN_SUSPEND,CommunicationMode.ASYNC,pullCallback
);
//如果拉取成功,就会执行上面定义的 回调函数onSuccess
服务端broker组装消息:
服务端处理消息的地方是:
org.apache.rocketmq.broker.processor.PullMessageProcessor#processRequest(final Channel channel, RemotingCommand request, boolean brokerAllowSuspend);
在里面对请求进行解析,然后去查找消息,查找消息代码:
final GetMessageResult getMessageResult =this.brokerController.getMessageStore().getMessage(requestHeader.getConsumerGroup(), requestHeader.getTopic(),requestHeader.getQueueId(), requestHeader.getQueueOffset(), requestHeader.getMaxMsgNums(), messageFilter);在这个方法里面会根据topic和queueId去获取一个消费队列,然后根据这个消费队列的最大偏移量与最小偏移量来校对下一次拉取偏移量,然后根据偏移量去commitLog里面去查找到消息,然后把它添加到返回结果里面返回。最后返回结果。
消息拉取客户端处理消息:
又回到客户端,来看看客户端拉取到消息后是做了些什么,下面是部分代码
private void pullMessageAsync(final String addr,final RemotingCommand request,final long timeoutMillis,final PullCallback pullCallback) throws RemotingException, InterruptedException {//1.通过netty发送网络请求,然后调用回调函数this.remotingClient.invokeAsync(addr, request, timeoutMillis, new InvokeCallback() {@Overridepublic void operationComplete(ResponseFuture responseFuture) {RemotingCommand response = responseFuture.getResponseCommand();if (response != null) {try {2.解析请求结果,并且将拉取的数据解码成PullResultExt对象PullResult pullResult = MQClientAPIImpl.this.processPullResponse(response);assert pullResult != null;//调用回调函数,这个回调函数就是前面在看DefaultMQPushConsumerImpl的pullMessage方法里面定义的,没印象前去看一下pullCallback.onSuccess(pullResult);} catch (Exception e) {pullCallback.onException(e);}//省略...然后看看pullCallback.onSuccess(pullResult) 回调函数。
public void onSuccess(PullResult pullResult) {if (pullResult != null) {//1.将返回的消息字节数组转换为消息集合,对消息进行过滤pullResult = DefaultMQPushConsumerImpl.this.pullAPIWrapper.processPullResult(pullRequest.getMessageQueue(), pullResult,subscriptionData);//2.正常情况下就是会返回foundswitch (pullResult.getPullStatus()) {case FOUND://3.更新pullRequest的下一次拉取偏移量long prevRequestOffset = pullRequest.getNextOffset();pullRequest.setNextOffset(pullResult.getNextBeginOffset());long pullRT = System.currentTimeMillis() - beginTimestamp;DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullRT(pullRequest.getConsumerGroup(),pullRequest.getMessageQueue().getTopic(), pullRT);long firstMsgOffset = Long.MAX_VALUE;//4.如果拉取到的消息列表为空 则立即将pullRequest放到pullRequestQueueif (pullResult.getMsgFoundList() == null || pullResult.getMsgFoundList().isEmpty()) {DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);} else {firstMsgOffset = pullResult.getMsgFoundList().get(0).getQueueOffset();DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullTPS(pullRequest.getConsumerGroup(),pullRequest.getMessageQueue().getTopic(), pullResult.getMsgFoundList().size());//5.将拉取到的消息列表放到processQueue消息队列(是一个map)boolean dispatchToConsume = processQueue.putMessage(pullResult.getMsgFoundList());//6.将消息提交到consumeMessageService供消费者消费,实际是提交到了一个线程池DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(),processQueue,pullRequest.getMessageQueue(),dispatchToConsume);//7.如果消息拉取间隔大于0,则延迟一行再去进行下次消息拉取if (DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval() > 0) {DefaultMQPushConsumerImpl.this.executePullRequestLater(pullRequest,DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval());} else {//8.立即进行下一次消息拉取DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);}}break;//省略....可以看看上面代码的第七八两步,那么我们是分析所谓的推模式,其实就是在执行一次消息拉取之后,在进行下一次的消息拉取,并不是真正意义上的消息推模式。
那么消息拉取流程到这里总算就是顺利完成啦!
到这里我还想说一下消息的消费队列的负载算法。
消息消费队列的负载算法
我们前面说完了消息的拉取是在MQClientInstance的start方法里面的,在消息拉取后面紧接着启动的就是rebalanceService的start方法。
// 消息拉取,也就是上面讲的那一堆东西
this.pullMessageService.start();
// 消息负载均衡算法选择与启动
this.rebalanceService.start();
它启动的就是一个线程,来看看这个run方法
@Override
public void run() {log.info(this.getServiceName() + " service started");while (!this.isStopped()) {//每隔20s执行一次this.waitForRunning(waitInterval);this.mqClientFactory.doRebalance();}log.info(this.getServiceName() + " service end");
}
//mqClientFactory.doRebalance();
//遍历所有消费者,对消费者执行负载均衡
public void doRebalance() {for (Map.Entry<String, MQConsumerInner> entry : this.consumerTable.entrySet()) {MQConsumerInner impl = entry.getValue();if (impl != null) {try {impl.doRebalance();} catch (Throwable e) {log.error("doRebalance exception", e);}}}
}继续往下跟就会发现最后调的是RebalanceImpl的doRebalance,就是对每个主题的队列进行负载
public void doRebalance(final boolean isOrder) {Map<String, SubscriptionData> subTable = this.getSubscriptionInner();if (subTable != null) {for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {final String topic = entry.getKey();try {//在这个方法里面对集群模式执行负载算法this.rebalanceByTopic(topic, isOrder);} catch (Throwable e) {if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {log.warn("rebalanceByTopic Exception", e);}}}}this.truncateMessageQueueNotMyTopic();
}来看下吧:
case CLUSTERING: {//获取该主题的队列信息Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);//...if (mqSet != null && cidAll != null) {List<MessageQueue> mqAll = new ArrayList<MessageQueue>();mqAll.addAll(mqSet);//排序Collections.sort(mqAll);Collections.sort(cidAll);//获取负载分配算法AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;List<MessageQueue> allocateResult = null;try {//执行分配算法allocateResult = strategy.allocate(this.consumerGroup,this.mQClientFactory.getClientId(),mqAll,cidAll);} catch (Throwable e) {//...}Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();if (allocateResult != null) {allocateResultSet.addAll(allocateResult);}boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);if (changed) {this.messageQueueChanged(topic, mqSet, allocateResultSet);}}break;
}
消息消费队列负载算法:
AllocateMessageQueueStrategy是一个接口它的实现类有下面这些:
AllocateMachineRoomNearby
AllocateMessageQueueAveragely
AllocateMessageQueueByConfig
AllocateMessageQueueAveragelyByCircle
AllocateMessageQueueByMachineRoom
AllocateMessageQueueConsistentHash
这里说一下常用的算法AllocateMessageQueueAveragely和AllocateMessageQueueAveragelyByCircle。
AllocateMessageQueueAveragely:它翻译过来激素平均分配消息队列。

如上图所示,假如说有八个消息消费队列的话,使用平均分配算法就会连续平均给每个消费者分配消费队列。
AllocateMessageQueueAveragelyByCircle:循环平均的分配消息队列。
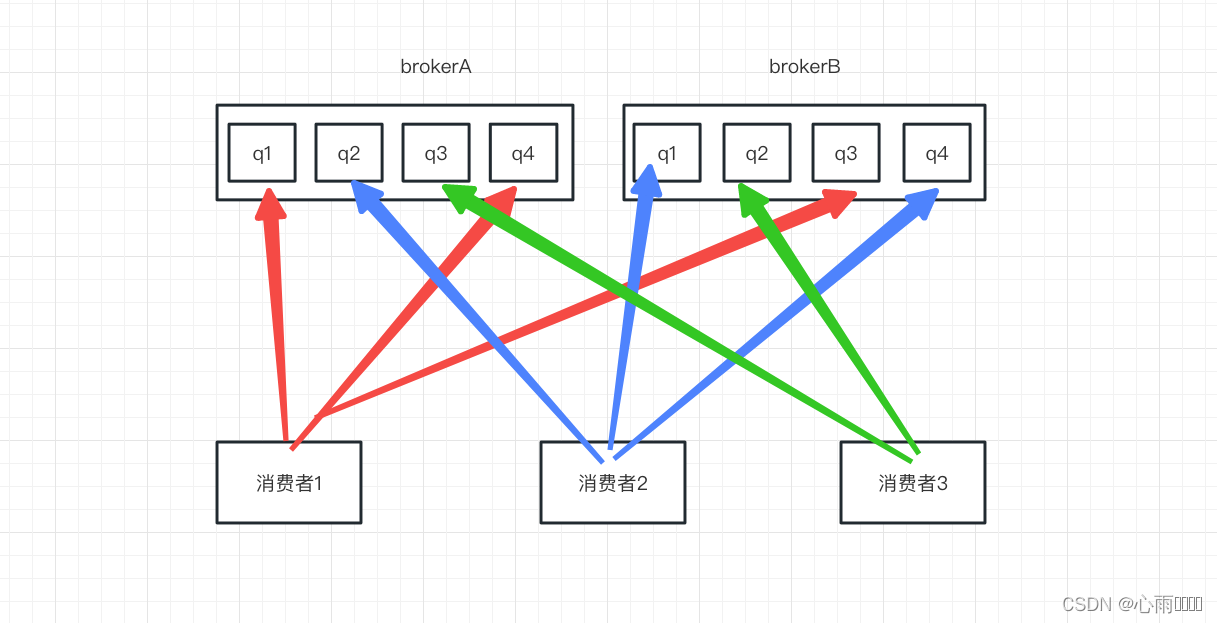
如图所示,这个算法就是轮流平均分配。
在上面代码有updateProcessQueueTableInRebalance这个方法,就是遍历已经分配的队列,如果队列不在队列负载中,就创建拉取任务,如果新队列集合不包含原来的集合就停止原队列的消息消费并移除。
消息消费进度提交:
如果说processQueue有五条消息(1,2,3,4,5),如果是1,3,4这几条消息被消费,那么processQueue的这几条消息会被移除也就是剩(2,5)这两条消息,那么想broker汇报的消息进度是取2(processQueue最小的偏移量为标准的)。所以Rocket是不保证消息重复消费的。